什么是注意力机制
生物学中的注意力机制是指人类或动物能够选择性地将感知和认知资源集中到某些信息或任务上的能力。这种能力允许我们在众多信息的背景中过滤出重要的信息,并将这些信息传递给相应的神经元进行处理。
本质:能从中抓住重点,不丢失重要信息
我们的视觉系统就是一种 Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。

简单且直观的理解,机器学习中注意力机制跟人的注意力类似,一张图片的信息量很多,大部分人只会注意**“锦江饭店**”四个字,招牌后面的电话号码和汽车就不是关注的重点。
原理
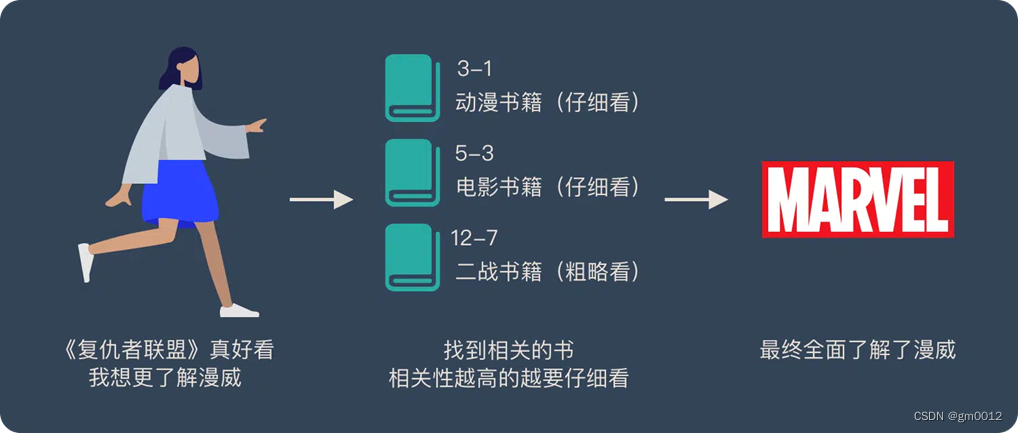
- Attention机制好比在图书馆中有大量的书籍,每本书都有特定的编号和内容。当想要了解某个主题(比如“漫威”)时,会查找与这个主题相关的书籍。
- 与“漫威”直接相关的动漫、电影书籍会仔细地阅读(权重高),而与“漫威”间接相关的二战书籍只需要简单浏览一下(权重低)。
- 这个过程就体现了Attention机制的核心思想:根据信息的重要性来分配注意力。
Transformer经典架构
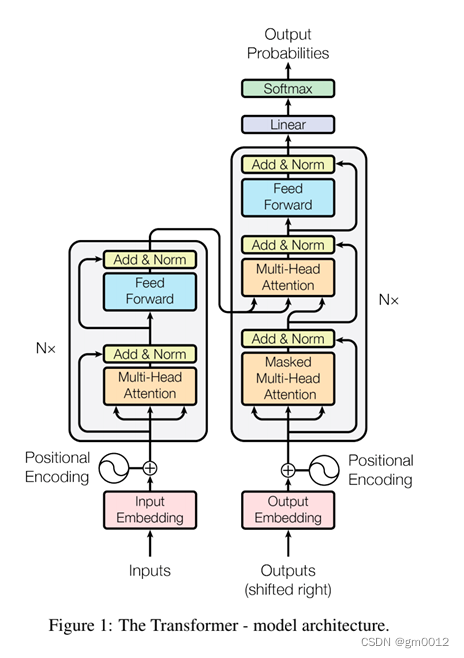
Transformer架构中有两个核心的组件Encoder和Decoder,左边的这张图是Transformer架构的一个简单表示形式,右边的这张图是Transformer架构的一个完整表示形式,其中有一个重要的Multi-Head Attention组件,称为注意力层。
Transformer架构中的两个核心的组件Encoder和Decoder,每个组件都可以单独使用,具体取决于任务的类型:
- 编码器(Encoder):它负责提取信息,通过细致分析输入文本,理解文本中各个元素的含义,并发现它们之间的隐藏联系。
- 解码器(Decoder):依托编码器提供的深入洞察,解码器负责生成所需的输出,无论是将句子翻译成另一种语言、生成一个精确的摘要,还是创作一首全新的诗歌。
- Encoder-decoder models 或者 sequence-to-sequence models: 适用于需要根据输入进行生成的任务,如翻译或摘要。
transformer流程

Encoder过程
每一层的Encoder由2个子组件组成:自注意力层和前馈网络层,其中文本的输入会先流入自注意力层,正是由于自注意力层的存在,帮助Encoder在对特定文本进行遍历时,能够让Encoder观察到文本中的其他单词。然后自注意力层的结果被输出到前馈网络层。
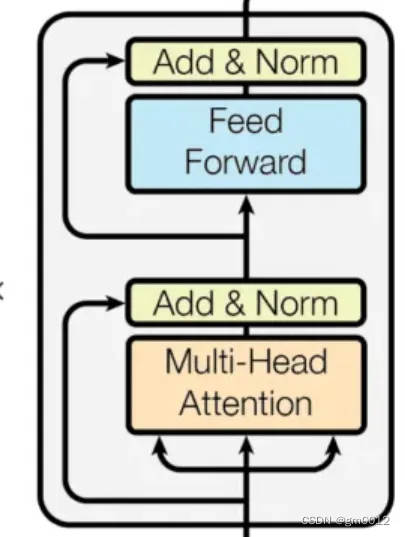
编码器的旅程从 “输入嵌入” 开始,此过程中,每个单词都从文本形态转换为数值向量,就好像给每个单词配上了一个独一无二的身份证。
以这个例子为例:
输入文本:例如,“The cat sat on the mat.”
在输入嵌入层,每个单词都被翻译成一个数值向量,就像在一个庞大的字典里,每个单词都有一个对应的 “向量地址”。
这些向量不仅捕捉了单词的含义,还包括:
- 语义关系(比如,“cat” 和 “pet” 更近,而不是和 “chair”);
- 句法角色(比如,“cat” 通常作为名词,“sat” 作为动词);
- 句中上下文(比如,这里的 “mat” 很可能是指地垫)。
向量表示如下:
- “The” -> [0.2, 0.5, -0.1, …]
- “cat” -> [0.8, -0.3, 0.4, …]
- “sat” -> [-0.1, 0.7, 0.2, …]
首先,每个单词都转换成了一个数值表示,称为 “词嵌入”,就像在一个巨大的词库地图上给每个单词定位。
接下来,自注意力机制为每个单词生成了三个特殊的向量:“查询(Query)”(询问我需要什么信息)、“键(Key)”(标示我有什么信息)和 “值(Value)”(实际的含义和上下文)。
然后,通过比较每个单词的 “查询” 向量与其他所有单词的 “键” 向量,自注意力层评估了各个单词之间的相关性,并计算出注意力得分。这个得分越高,表示两个单词之间的联系越紧密。
最后,自注意力层根据注意力得分加权处理 “值” 向量,这就像根据每个单词与当前单词的相关度,取了一个加权平均值。
Tansformer公式:
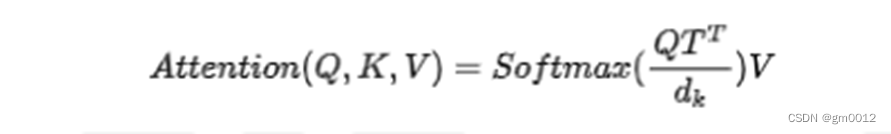

想必各位都用过各大招聘网站投过简历,在这里把公司 HR 招聘过程比做一个注意力计算过程,HR 拿到了甲乙丙丁 4 人的简历,4 人都有自己的擅长,甲擅长 IT,乙擅长跑步,丙擅长游泳,丁擅长演讲,IT、跑步、游泳和演讲就是 key,将这些 key 在每人身上拉平,并赋予能力值,例如甲擅长 IT,乙不擅长 IT,则甲IT的能力值为 0.9,乙IT的能力值为 0.1,这些能力值就是 value。
HR 要找一个 IT 能力强的人,HR 的需求就是 query,query 与 key 求点积相似度(再除以根下 dk,mask、softmax、dropout),再与能力值 value 矩阵计算,最终就是公司得到的这 4 人的 JD 匹配值。这就是整个当前大模型注意力机制数学原理!
自注意力机制
通过考虑句中其他单词提供的上下文,自注意力机制为每个单词创建了一个新的、更丰富的表示。这种表示不仅包含了单词本身的含义,还有它如何与句中其他单词关联和受到影响。
多头自注意力机制
多头注意力机制(Multi-Head Attention)可以被理解为有多个分析小组,每个小组关注于词与词之间联系的不同层面。这使得编码器能够全面捕获词义之间的多元关系,从而深化其对语句的理解。
在多头注意力机制中,不同于只使用一个自我关注机制,我们有多个独立的 “头部”(通常是 4 到 8 个)。每个头部都针对每个词分别维护一套查询(Query)、键(Key)和值(Value)向量。
这种机制下的注意力是多样化的:每个头部根据不同的逻辑计算注意力得分,聚焦于词间关系的不同方面:
- 一个头部可能专注分析语法角色,比如 “fox” 和 “jumps” 之间的关系。
- 另一个可能关注词序,比如 “the” 和 “quick” 之间的顺序。
- 还有的头部可能识别同义词或相关概念,例如将 “quick” 和 “fast” 视为相近的词。
通过结合这些不同头部的观点,每个头部的输出被汇总,综合不同的洞察力
位置编码
位置编码(Positional Encoding)是为了补充 Transformer 无法直接处理词序的不足,加入了每个词在句中位置的信息。可以想象成给每个分析员一张地图,指示他们应该如何按顺序审视词汇
学习词之间的关系:
-
低频波动揭示词之间的长距离关系。
-
高频波动则关注紧密相连的词。
即便句子的顺序变化,位置向量也能保持词之间的相对位置关系,使得模型能准确理解词与词之间的连接
FFN
前馈网络(FFN,Feed Forward Network)为模型增添了一层非线性处理,使其能够学习到更为复杂的单词间关系,这些关系可能单凭注意力机制难以捕捉。
通过前面几层的分析,你已经深入理解了句中单词的含义、它们之间的联系以及它们的位置。现在,FFN 就像是一只侦探用的放大镜,准备揭示那些不立即显现的复杂细节
Decoder
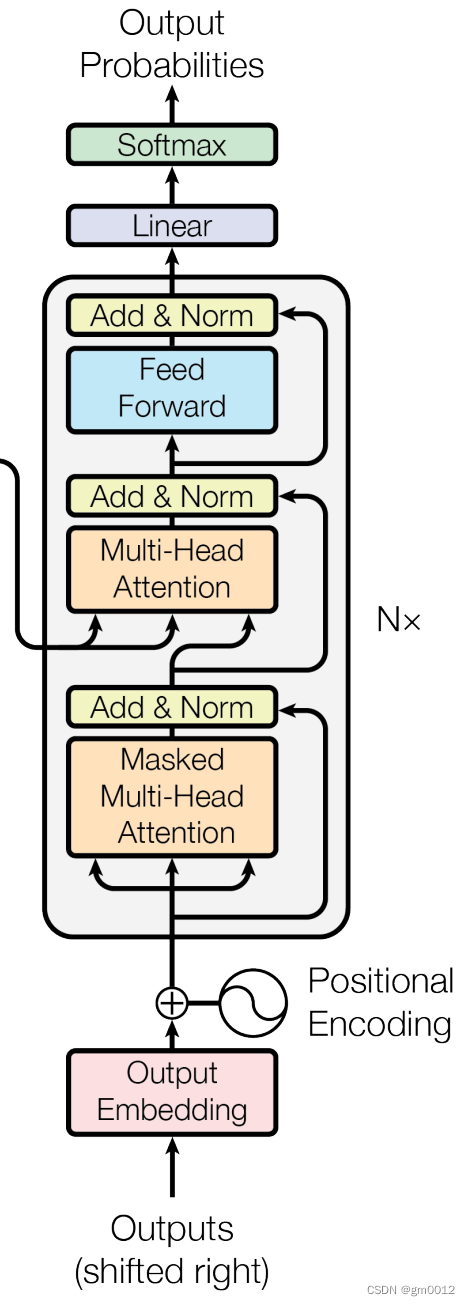
现在,轮到解码器承担任务。与编码器不同的是,解码器面临着额外的挑战:在不预见未来的情况下,逐字生成输出。为此,它采用了以下策略:
- 掩蔽自注意力:类似于编码器的自注意力机制,但有所调整。解码器仅关注之前已生成的单词,确保不会利用到未来的信息。这就像是一次只写出一个句子的故事,而不知道故事的结局。
- 编码器 - 解码器注意力:这一机制允许解码器参考编码好的输入,就像写作时回头查看参考资料一样。这确保了生成的输出与原始文本保持一致性和连贯性。
- 多头注意力和前馈网络:与编码器相同,这些层帮助解码器深化对文本中上下文和关系的理解。
- 输出层:最终,解码器将其内部表征逐一转化为实际的输出单词。这就像是最后的装配线,把所有部件组合起来,形成期望的结果。









![[嵌入式系统-69]:RT-Thread-组件:网络组件“组”,RT-Thread系统通向外部网络世界的入口](https://img-blog.csdnimg.cn/img_convert/bc33299a6eb2590862c29f084372eff3.png)