聚类分析 | 基于DTW距离测度的Kmeans时间序列聚类算法(Matlab)
目录
- 聚类分析 | 基于DTW距离测度的Kmeans时间序列聚类算法(Matlab)
- 效果一览
- 基本介绍
- 程序设计
- 参考资料
效果一览
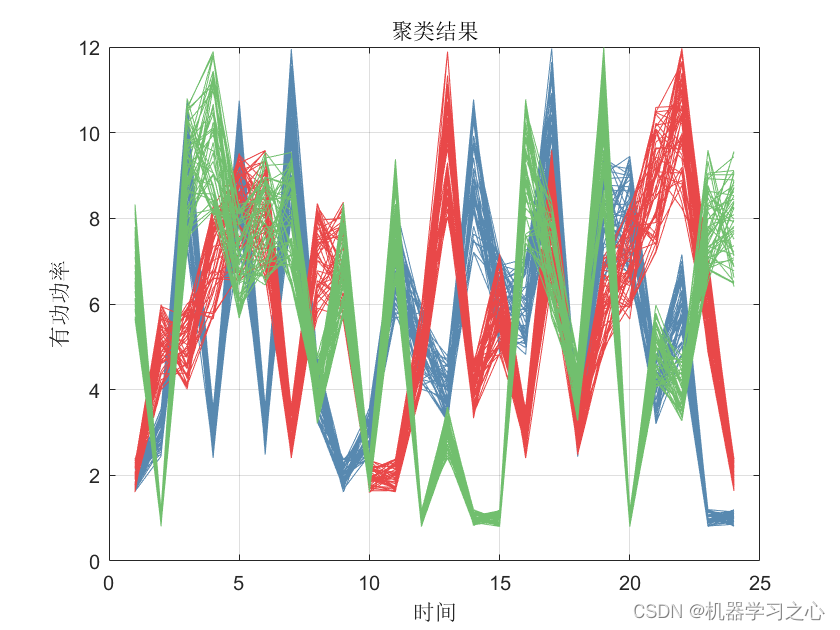
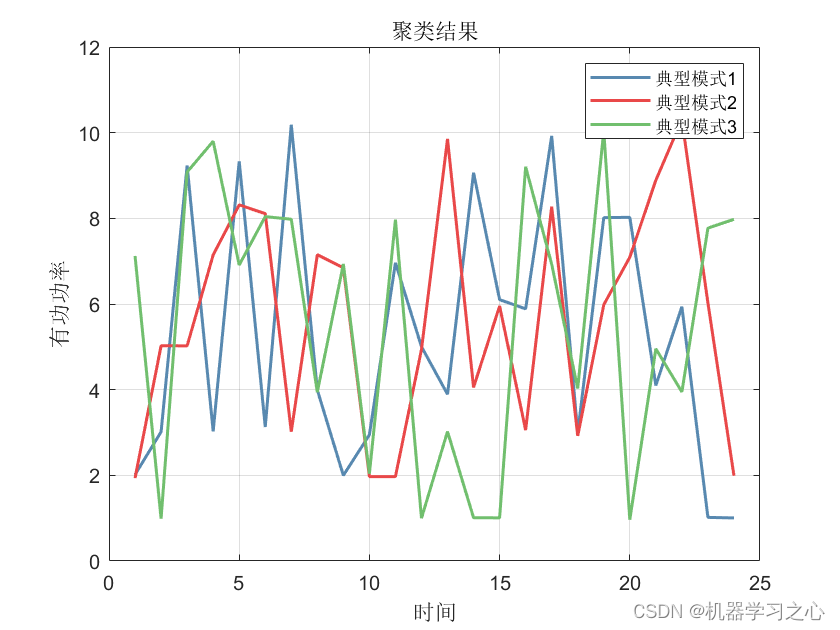
基本介绍
基于DTW距离测度的Kmeans时间序列聚类算法
基于动态时间规整(DTW)的kmeans序列聚类算法,将DTW算法求得的距离取代欧式距离衡量不同长度的阵列或时间序列之间的相似性或距离,实现时间序列的聚类。算法为Matlab编写,注释清晰,逻辑详细,可以方便地替换数据。初始聚类误差为2.361143e+03.
第1轮聚类误差为1.888321e+03.
第2轮聚类误差为1.888321e+03.
聚类完成,一共进行了2轮.
程序设计
- 完整源码和数据获取方式私信博主回复基于DTW距离测度的Kmeans时间序列聚类算法(Matlab)。
%% ==========================清空工作区==============================
clc;
clear;
close all;
addpath(genpath(pwd));
%% ============================导入数据=============================
data = xlsread('序列数据.xlsx');
X = data; % 特征序列
%% ============================kmeans聚类===========================
K = 3;
[idx,C] = mykmeans(X,K,[],[],[],'sqEuclidean','sample'); % 'plus'\'sample'
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/129215161
[2] https://blog.csdn.net/kjm13182345320/article/details/128105718