代码
import requests
import re
import os
if __name__ == "__main__":
if not os.path.exists("./haha"):
os.makedirs('./haha')
url = 'https://mlol.qt.qq.com/go/mlol_news/varcache_article?docid=6321992422382570537&gameid=3&zone=plat&webview=cc'
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36'
}
page_text = requests.get(url=url,headers=headers).text
# print(page_text)
#聚焦
ex = r'<img\s+src="([^"]+)"'
img_src_list = re.findall(ex,page_text,re.S)
# print(img_src_list)
for src in img_src_list:
#请求到了图片的二进制数据
img_data = requests.get(url=src,headers=headers).content
#生成图片名称
img_name = src.split('/')[-1]
#图片存储路径
imgPath = './haha/'+img_name
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!')
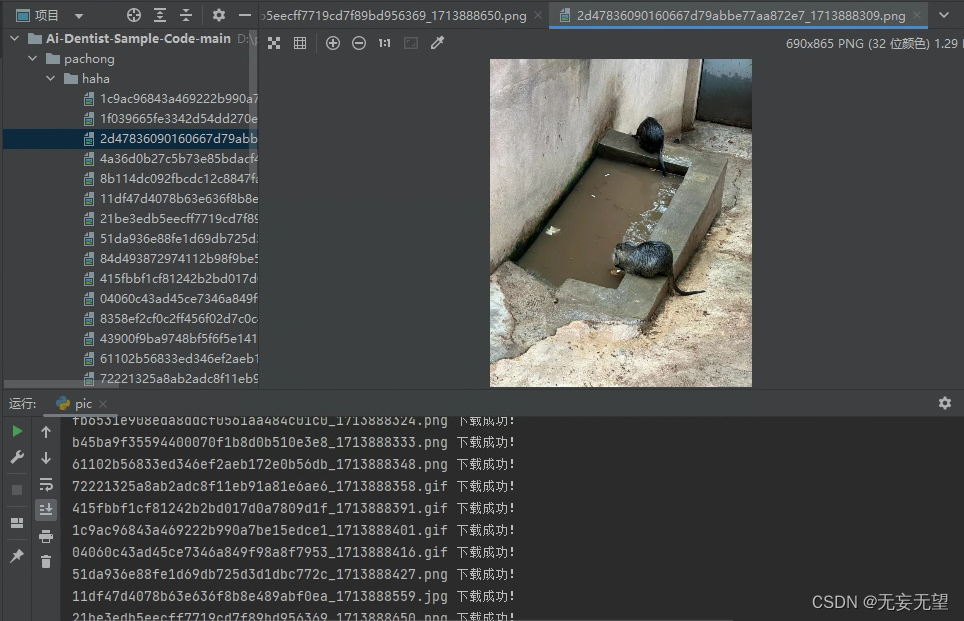
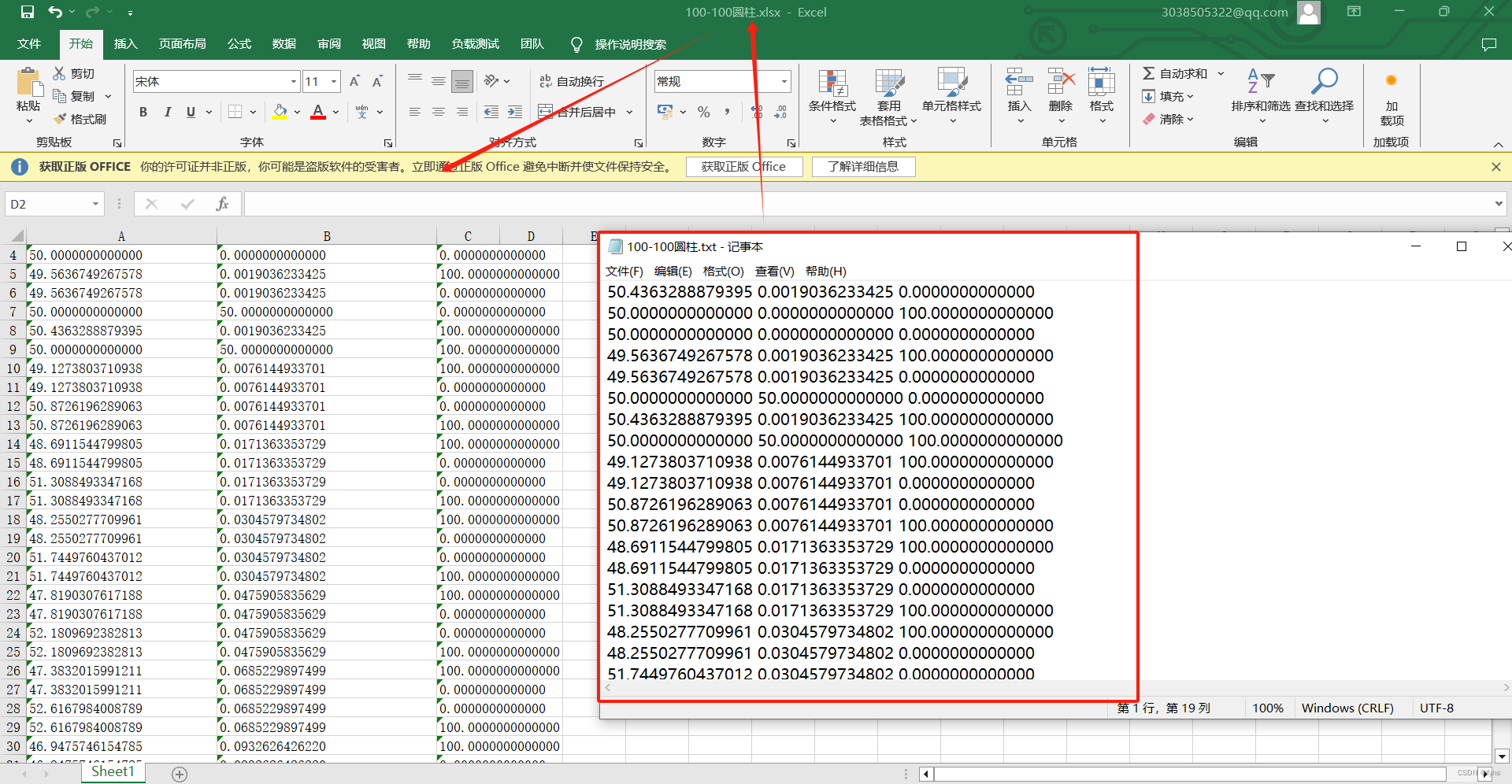
1.先从目标网站获取相应的图片地址,再遍历这些地址来搜集图像
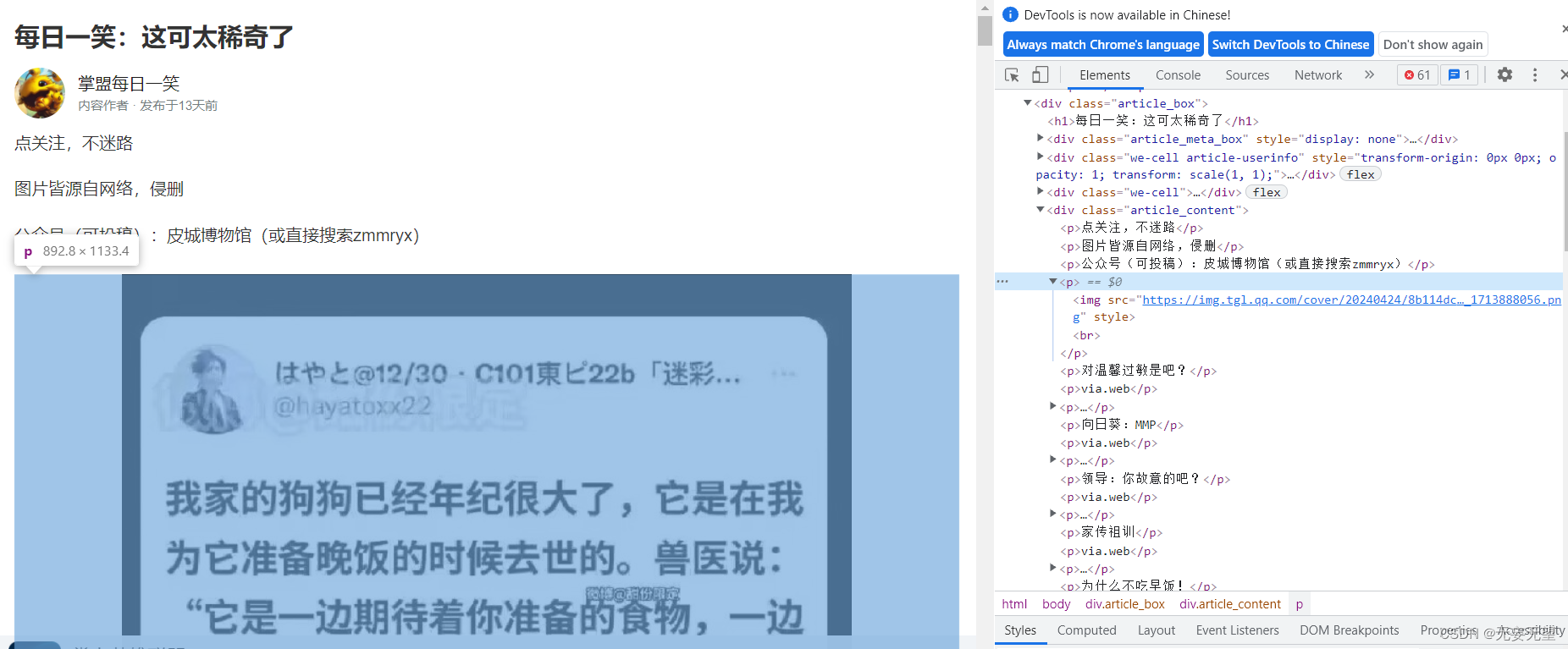
可以看到图片是在acticle_content下的图片,所有的图片地址都在。
2.使用正则化来表示
由于我不会写,所以将图片地址所在的前端代码交给ChatGPT,让它帮我生成正则化表达式
<div class="article_content"><p>点关注,不迷路</p><p>图片皆源自网络,侵删</p><p>公众号(可投稿):皮城博物馆(或直接搜索zmmryx)</p><p><img src="https://img.tgl.qq.com/cover/20240424/8b114dc092fbcdc12c8847fa578933c4_1713888056.png" style=""><br></p><p>对温馨过敏是吧?</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/84d493872974112b98f9be55d0acd562_1713888068.png" style=""><br></p><p>向日葵:MMP</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/4a36d0b27c5b73e85bdacf4b4e6cc795_1713888077.gif" style=""><br></p><p>领导:你故意的吧?</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/8358ef2cf0c2ff456f02d7c0c482b8c2_1713888089.png" style=""><br></p><p>家传祖训</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/b3071165ab494e702963d094d6f00416_1713888124.png" style=""><br></p><p>为什么不吃早饭!</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/43900f9ba9748bf5f6f5e141125af6d7_1713888140.png" style=""><br></p><p><img src="https://img.tgl.qq.com/cover/20240424/2d47836090160667d79abbe77aa872e7_1713888309.png" style=""><br></p><p>这可太稀奇了</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/fb6531e908eda8ddcf0561aa484c01c0_1713888324.png" style=""><br></p><p>6啊</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/b45ba9f35594400070f1b8d0b510e3e8_1713888333.png" style=""><br></p><p>这个江涛是老板吗?</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/61102b56833ed346ef2aeb172e0b56db_1713888348.png" style=""><br></p><p>老板好实诚</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/72221325a8ab2adc8f11eb91a81e6ae6_1713888358.gif" style=""><br></p><p>太险了吧</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/415fbbf1cf81242b2bd017d0a7809d1f_1713888391.gif" style=""><br></p><p>别说,还挺合适</p><p>via.web</p><p><img src="https://img.tgl.qq.com/cover/20240424/1c9ac96843a469222b990a7be15edce1_1713888401.gif" style=""><br></p><p>宝宝有什么错?他只是在打坏蛋</p><p>via.web</p><p><span>五杀时刻:</span></p><p><img src="https://img.tgl.qq.com/cover/20240424/04060c43ad45ce7346a849f98a8f7953_1713888416.gif" style=""><br></p><p><span>福利:</span></p><p><img src="https://img.tgl.qq.com/cover/20240424/51da936e88fe1d69db725d3d1dbc772c_1713888427.png" style=""><br></p><p>画师: / N_24</p><p>侵删</p><p><img src="https://img.tgl.qq.com/cover/20240424/11df47d4078b63e636f8b8e489abf0ea_1713888559.jpg" style=""><br></p><p>画师:辰叔</p><p>侵删</p><p><br></p><p><br></p><p><br></p><p><span>联盟猜猜猜:</span></p><p><span>上期:</span></p><p><img src="https://img.tgl.qq.com/cover/20240424/21be3edb5eecff7719cd7f89bd956369_1713888650.png" style=""><br></p><p><img src="https://img.tgl.qq.com/cover/20240424/1f039665fe3342d54dd270e4d16dae6e_1713888632.png" style=""><br></p><p><span>本期:</span></p><p><img src="https://img.tgl.qq.com/cover/20240424/cfb00fad69c756931506de6832bb602f_1713888657.png" style=""><br></p><p style="color:#757E7F !important">来自: 江西</p></div>
则正则化表达式为
pattern = r'<img\s+src="([^"]+)"'
当你编写正则表达式时,需要考虑到你想要匹配的文本模式。让我解释一下这个正则表达式:
1.pattern = r'<img\s+src="([^"]+)"':
2.pattern = r'...':这一行代码创建了一个名为 pattern 的字符串,其中 r 前缀告诉Python解释器这是一个“原始”字符串,也就是说,反斜杠不会被转义。这是为了避免在正则表达式中使用反斜杠时出现意外的行为。
3.'<img\s+src="([^"]+)"':这个字符串是我们的正则表达式模式。
4.<img:匹配文本中的 <img 字符串。
5.\s+:匹配一个或多个空白字符(空格、制表符、换行符等)。
6.src=":匹配文本中的 src=" 字符串。
7.([^"]+):这是一个捕获组,匹配任意数量的非双引号字符,并将其捕获为一个组。[^"] 表示不匹配双引号的任何字符,+ 表示匹配一个或多个这样的字符。
8.":匹配一个双引号字符。所以,这个正则表达式的目的是匹配 <img> 标签中的 src 属性值,并将这个值捕获为一个组,从而提取图片的地址。
3.遍历这些图片地址,并下载保存
for src in img_src_list:
#请求到了图片的二进制数据
img_data = requests.get(url=src,headers=headers).content
#生成图像名称
img_name = src.split('/')[-1]
#图片存储路径
imgPath = './haha/'+img_name
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!')
成功下载图片,但是gif的也只是静态的