文章目录
- 介绍
- 原理
- 整体方案
- 实现步骤
- 示例代码
- 总结
- 其他:Kafka 重试策略配置
- 1. 生产者重试策略配置
- 2. 消费者重试策略配置
介绍
在分布式系统中,保持 MySQL 和 Redis 之间的数据一致性是至关重要的。为了确保数据的一致性,我们通常采取先更新数据库,再删除缓存的方案。然而,在实际应用中,由于网络问题、服务故障等原因,可能会导致数据库更新成功而缓存删除失败,进而导致数据不一致。为了解决这个问题,我们可以引入消息队列的重试机制,以确保缓存删除成功。
原理
重试机制是一种容错机制,用于在消息发送失败或者处理失败时进行重试。通过将数据更新操作封装成消息,并发送到消息队列中,在消费者处理消息时进行重试,可以提高系统的可靠性和稳定性。我们将使用消息队列的重试机制来实现 MySQL 和 Redis 的数据一致性。
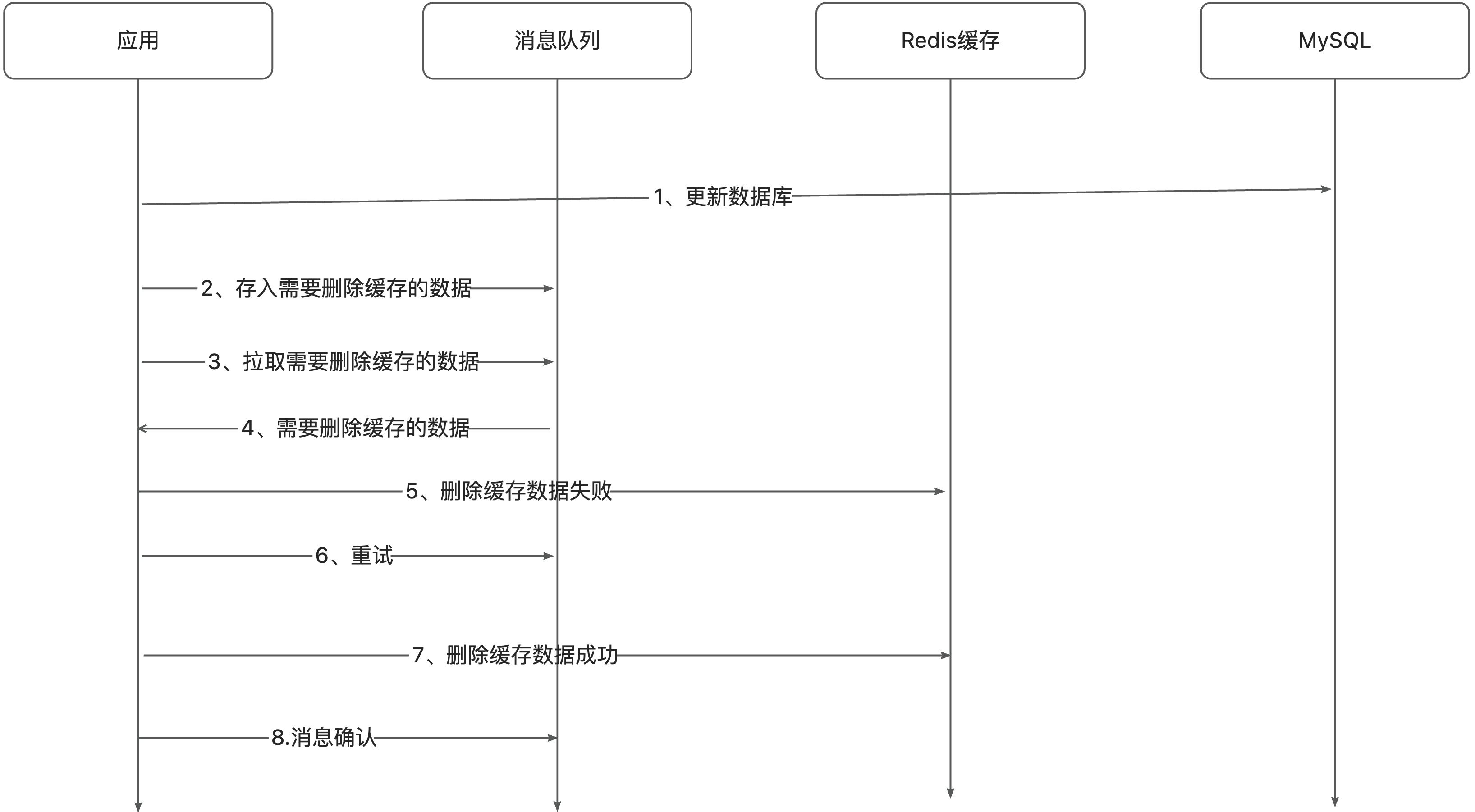
整体方案
整体方案如下:
- 应用程序首先将数据更新操作发送到消息队列中。
- 消费者从消息队列中获取消息,并根据消息中的数据删除 Redis 中的缓存数据。
- 如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,就需要向业务层发送报错信息了。
- 如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
实现步骤
以下是使用消息队列的重试机制实现 MySQL 和 Redis 数据一致性的基本步骤:
- 将数据更新操作封装成消息:在应用程序中,将数据更新操作封装成消息,并发送到消息队列中。消息中应包含数据更新操作的类型(如插入、更新或删除)以及相关的数据。
- 消费者消息处理和失败重试:消费者从消息队列中获取消息,并根据消息中的数据更新操作来删除 Redis 中的缓存数据。消息消费失败后自动进行重试。可以根据重试次数和重试间隔来配置重试机制,例如指数退避策略。
- 消息确认机制:消费者在成功处理消息后,需要发送确认消息给消息队列,告知消息队列可以删除或标记消息为已处理。这样可以确保消息在成功处理后不会被重新处理,避免重复处理的情况。
示例代码
以下是一个简单的示例代码,演示了如何使用 Java 实现消息队列的重试机制,以确保 MySQL 和 Redis 的数据一致性:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class MySQLToKafka {
private static final String TOPIC_NAME = "mysql_updates";
private static final String BOOTSTRAP_SERVERS = "localhost:9092";
private static final String GROUP_ID = "cache-deletion-group";
public static void main(String[] args) {
// 模拟 MySQL 更新后发送消息到 Kafka
sendMySQLUpdateToKafka("data_update");
// 模拟从 Kafka 拉取消息删除 Redis 缓存
pullMessageFromKafkaAndDeleteCache();
}
// 发送 MySQL 更新消息到 Kafka
private static void sendMySQLUpdateToKafka(String message) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC_NAME, message);
try {
producer.send(record).get();
System.out.println("Message sent to Kafka successfully: " + message);
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
}
// 从 Kafka 拉取消息并删除 Redis 缓存
private static void pullMessageFromKafkaAndDeleteCache() {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList(TOPIC_NAME));
try {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Received message: offset = %d, key = %s, value = %s%n",
record.offset(), record.key(), record.value());
if (deleteCacheFromRedis(record.value())) {
System.out.println("Cache deleted from Redis successfully.");
// 处理消息成功后手动提交偏移量
consumer.commitAsync();
} else {
System.out.println("Cache deletion from Redis failed. Kafka will retry.");
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
// 模拟删除 Redis 缓存
private static boolean deleteCacheFromRedis(String message) {
// 这里省略删除 Redis 缓存的逻辑,直接模拟删除成功和失败
// 模拟删除成功的概率为 0.7
if (Math.random() < 0.7) {
return true;
}
return false;
}
}
以上代码完成了以下几个功能:
- 发送 MySQL 更新消息到 Kafka:
sendMySQLUpdateToKafka方法模拟了 MySQL 更新后发送消息到 Kafka 的过程。它使用 Kafka 生产者将消息发送到指定的 Kafka 主题中。 - 从 Kafka 拉取消息并删除 Redis 缓存:
pullMessageFromKafkaAndDeleteCache方法模拟了从 Kafka 拉取消息并删除 Redis 缓存的过程。它使用 Kafka 消费者订阅指定的 Kafka 主题,并轮询获取消息。对于每条消息,它尝试删除对应的 Redis 缓存。如果删除失败,就会打印一条消息表示失败,然后 Kafka 将自动重试该消息。只有在成功删除缓存后,才会手动提交偏移量。 - 模拟删除 Redis 缓存:
deleteCacheFromRedis方法用于模拟删除 Redis 缓存的过程。它返回一个布尔值,表示缓存删除操作的成功或失败。在实际应用中,这个方法应该被替换为真正的删除 Redis 缓存的逻辑。
通过这样的流程,模拟了一个简单的数据更新、消息发送、消息消费、缓存删除的完整流程,并且在处理消息失败时利用 Kafka 的自动重试机制进行了处理。
总结
通过引入消息队列的重试机制,可以有效地实现 MySQL 和 Redis 的数据一致性。使用重试机制,可以确保数据在 MySQL 更新后 Redis 的对应缓存能够成功删除,从而保持数据的一致性。这种方法适用于需要处理大量数据更新和异步消息传输的场景,同时也提高了系统的可靠性和稳定性。
其他:Kafka 重试策略配置
1. 生产者重试策略配置
对于 Kafka 生产者,可以通过配置以下参数来定义重试策略:
retries: 设置生产者在发生可重试的异常时重试的最大次数。默认值为 2147483647(即最大整数)。retry.backoff.ms: 设置生产者在重试之间等待的时间。默认值为 100 毫秒。
示例配置:
# 设置最大重试次数为 3 次
retries=3
# 设置重试之间的等待时间为 500 毫秒
retry.backoff.ms=500
2. 消费者重试策略配置
对于 Kafka 消费者,可以通过以下参数来定义重试策略:
enable.auto.commit: 指定消费者是否自动提交偏移量。默认为 true,表示自动提交。auto.commit.interval.ms: 如果启用了自动提交偏移量,可以通过该参数设置自动提交的间隔时间。默认值为 5000 毫秒。max.poll.interval.ms: 设置消费者在拉取消息之间的最大时间间隔。如果消费者在此间隔内没有发送心跳,将被认为失败,并且将其分区重新分配给其他消费者。默认值为 300000 毫秒(5 分钟)。max.poll.records: 设置消费者在单次调用 poll 方法中拉取的最大记录数。默认值为 500 条。
示例配置:
# 禁用自动提交偏移量
enable.auto.commit=false
# 设置自动提交偏移量的间隔时间为 1000 毫秒
auto.commit.interval.ms=1000
# 设置拉取消息之间的最大时间间隔为 10 秒
max.poll.interval.ms=10000
# 设置单次 poll 方法拉取的最大记录数为 100 条
max.poll.records=100
通过以上配置,可以定制 Kafka 生产者和消费者的重试策略,以适应不同的业务需求和性能要求。