(BIGRU、CNN-BIGRU、CNN-BIGRU-ATTENTION、TCN-BIGRU、TCN-BIGRU-ATTENTION)时,我们可以从它们的基本结构、工作原理、应用场景以及优缺点等方面进行详细介绍和分析。

1. BIGRU
基本结构:
BIGRU是双向门控循环单元(Bidirectional Gated Recurrent Unit)的缩写,是循环神经网络(RNN)的一种变体。它通过两个并行的GRU网络(一个正向,一个反向)来捕捉序列数据中的双向信息。
工作原理:
BIGRU在每个时间步上都会接收输入并更新其内部状态,同时产生输出。正向GRU从左到右读取序列,而反向GRU从右到左读取序列。这两个GRU的输出被合并以产生最终的输出。
优点:
- 能够捕捉序列数据中的双向依赖关系。
- 相较于传统的RNN,对长期依赖关系有更好的处理能力。
缺点:
- 仍然可能面临梯度消失或梯度爆炸的问题,尤其是在处理非常长的序列时。
- 参数量较大,可能导致训练速度较慢和过拟合风险增加。
2. CNN-BIGRU
基本结构:
CNN-BIGRU结合了卷积神经网络(CNN)和双向门控循环单元(BIGRU)。CNN首先用于从输入序列中提取局部特征,然后将这些特征输入到BIGRU中进行进一步处理。
优点:
- CNN可以提取输入序列中的局部特征,为BIGRU提供更有意义的输入。
- BIGRU可以捕捉这些特征之间的长期依赖关系。
缺点:
- 增加了模型的复杂性,可能导致训练难度增加和过拟合风险提高。
- 需要仔细调整CNN和BIGRU的参数以获得最佳性能。
3. CNN-BIGRU-ATTENTION
基本结构:
CNN-BIGRU-ATTENTION在CNN-BIGRU的基础上引入了注意力机制(Attention)。注意力机制允许模型在预测时关注输入序列中的重要部分。
优点:
- 可以帮助模型更准确地捕捉输入序列中的关键信息。
- 提高了模型对输入序列中不同部分的关注程度,从而提升了预测的准确性。
缺点:
- 进一步增加了模型的复杂性,可能导致训练难度和计算成本增加。
- 注意力机制的设计和实现需要仔细考虑,以避免引入不必要的噪声或偏见。
4. TCN-BIGRU
基本结构:
TCN-BIGRU结合了时间卷积网络(Temporal Convolutional Network, TCN)和双向门控循环单元(BIGRU)。TCN是一种用于处理序列数据的特殊卷积神经网络,它可以捕捉序列中的长期依赖关系。
优点:
- TCN可以捕捉输入序列中的长期依赖关系,为BIGRU提供更有意义的输入。
- 相较于传统的RNN,TCN具有更好的并行性和更少的计算成本。
缺点:
- 同样增加了模型的复杂性,可能导致训练难度和过拟合风险提高。
- 需要仔细调整TCN和BIGRU的参数以获得最佳性能。
5. TCN-BIGRU-ATTENTION
基本结构:
TCN-BIGRU-ATTENTION在TCN-BIGRU的基础上引入了注意力机制。这允许模型在预测时更加关注输入序列中的关键部分。
优点:
- 综合了TCN、BIGRU和Attention的优点,能够同时捕捉输入序列中的局部特征、长期依赖关系和关键信息。
- 提高了模型对输入序列中不同部分的关注程度,从而进一步提升了预测的准确性。
缺点:
- 模型的复杂性最高,可能导致训练难度、计算成本和过拟合风险都达到最高水平。
- 需要仔细设计和调整模型的各个部分以获得最佳性能。
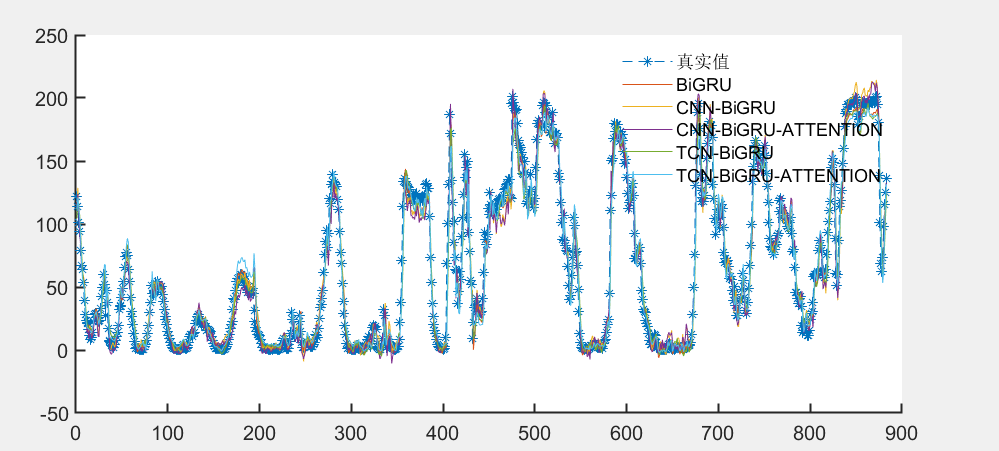
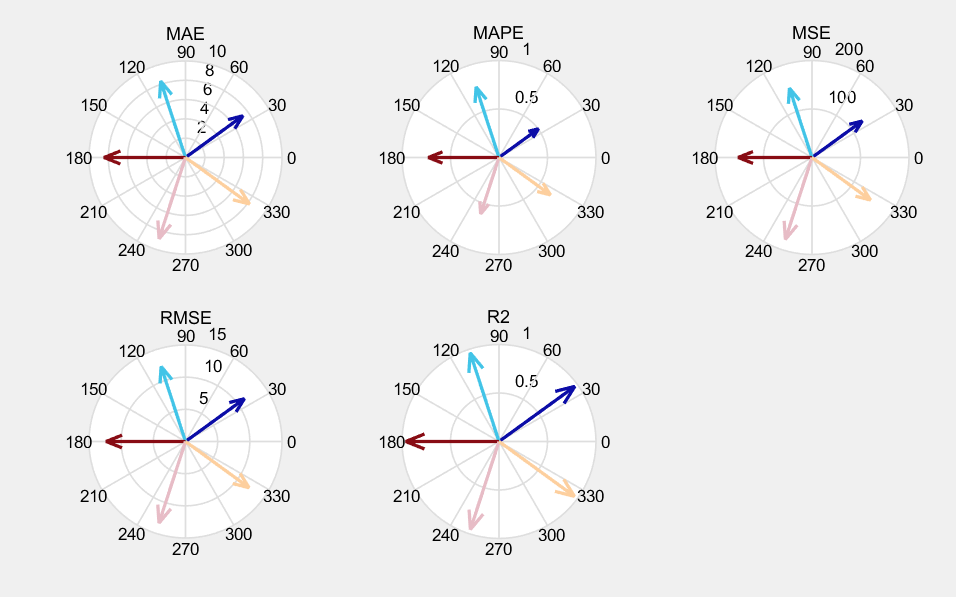
- 各模型效果对比:
-
基于风电数据集上进行效果对比
数据集:
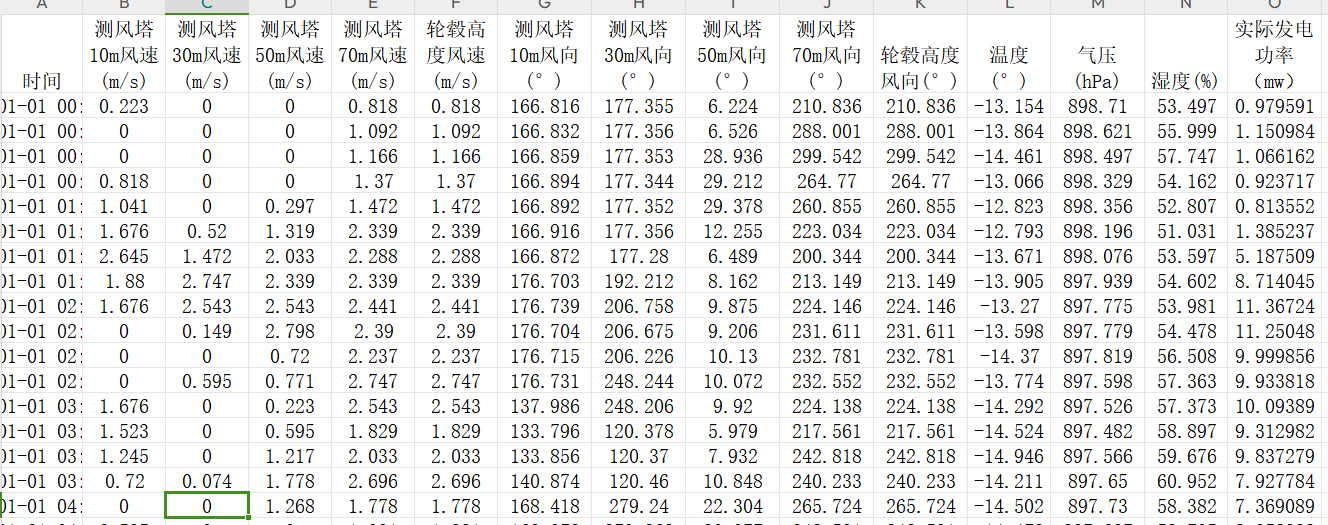
效果对比: