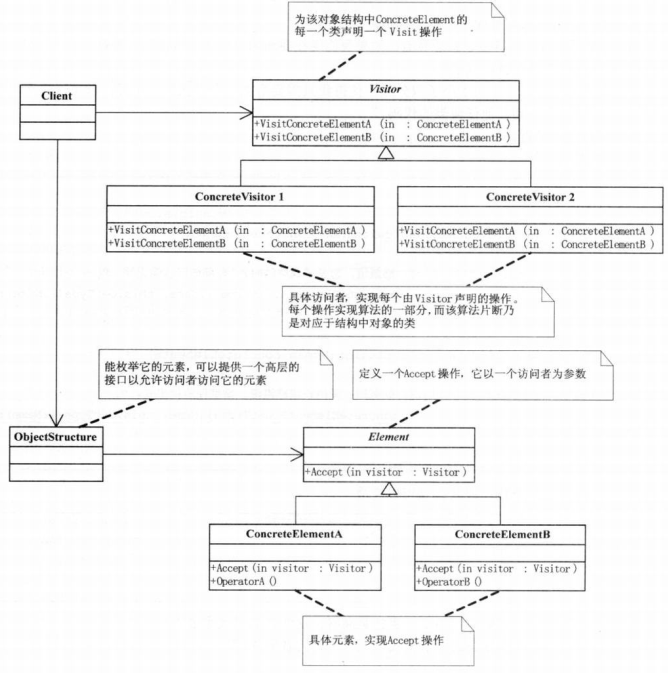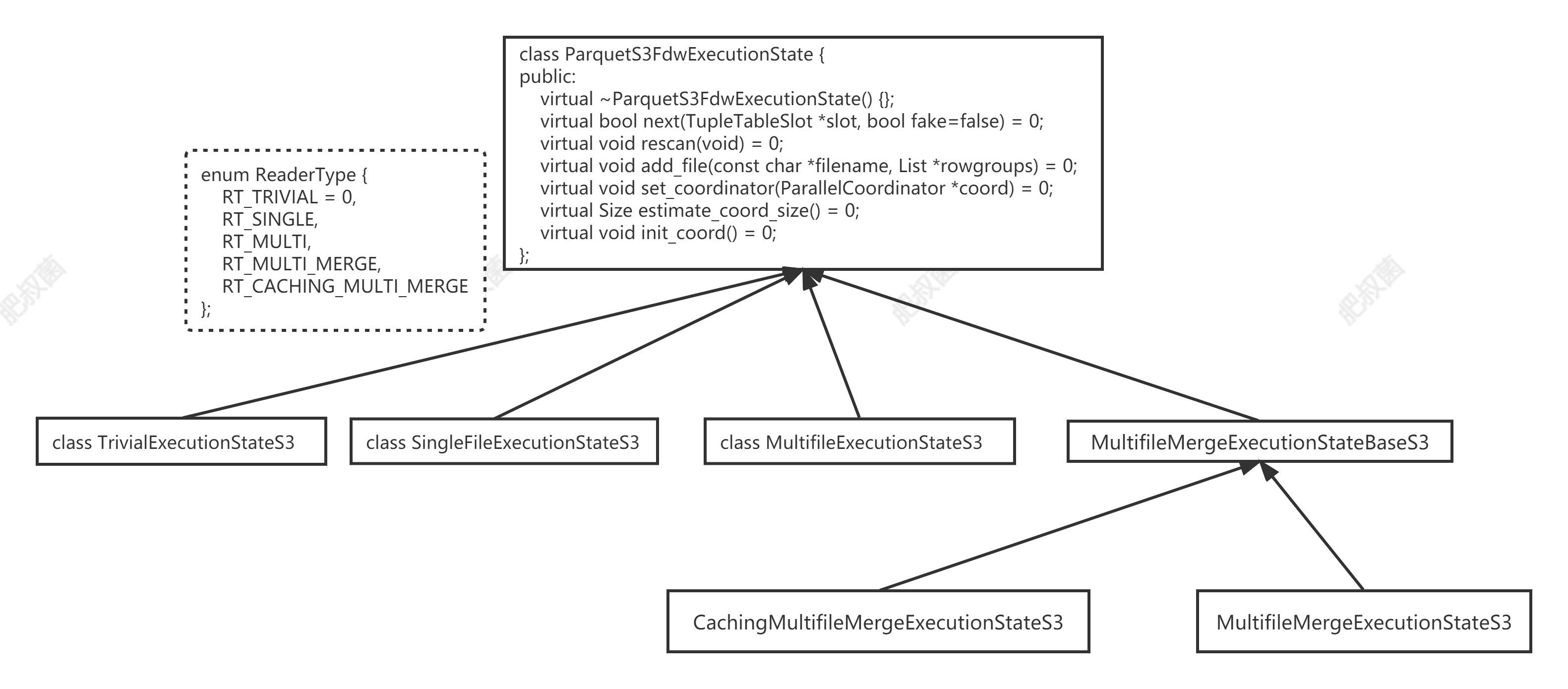
MultifileMergeExecutionStateBaseS3和SingleFileExecutionStateS3、MultifileExecutionStateS3类不同,reader成员被替换为ParquetReader *类型的readers vector。新增slots_initialized布尔变量指示slots成员是否已经初始化。slots成员是Heap类,Heap用于以优先级方式存储元组以及文件号。优先级被赋予具有最小key的元组。一旦请求了下一个元组,它将从堆的顶部取出,并从同一个文件中读取一个新元组并将其插入回堆中。然后重建堆以维持其属性。这个想法来自PostgreSQL中的nodeGatherMerge.c,但使用STL重新实现。slots Heap中存储的是ReaderSlot元素。
class MultifileMergeExecutionStateBaseS3 : public ParquetS3FdwExecutionState{
protected:
std::vector<ParquetReader *> readers;
/* Heap is used to store tuples in prioritized manner along with file
* number. Priority is given to the tuples with minimal key. Once next
* tuple is requested it is being taken from the top of the heap and a new
* tuple from the same file is read and inserted back into the heap. Then
* heap is rebuilt to sustain its properties. The idea is taken from
* nodeGatherMerge.c in PostgreSQL but reimplemented using STL. */
struct ReaderSlot{
int reader_id;
TupleTableSlot *slot;
};
Heap<ReaderSlot> slots;
bool slots_initialized;
首先看ParallelCoordinator相关函数,set_coordinator向ParquetReader *类型的readers vector中所有ParquetReader都设置coord成员,也就是这些coord都共享coord。
void set_coordinator(ParallelCoordinator *coord) {
this->coord = coord;
for (auto reader : readers) reader->set_coordinator(coord);
}
Size estimate_coord_size() {
return sizeof(ParallelCoordinator) + readers.size() * sizeof(int32);
}
void init_coord() {
coord->init_multi(readers.size());
}
compare_slots函数用于通过sort keys比较两个slot。如果a大于b,返回true;否则返回false。
/* compare_slots
* Compares two slots according to sort keys. Returns true if a > b,
* false otherwise. The function is stolen from nodeGatherMerge.c
* (postgres) and adapted. */
bool compare_slots(const ReaderSlot &a, const ReaderSlot &b) {
TupleTableSlot *s1 = a.slot; TupleTableSlot *s2 = b.slot;
Assert(!TupIsNull(s1)); Assert(!TupIsNull(s2));
for (auto sort_key: sort_keys) {
AttrNumber attno = sort_key.ssup_attno;
Datum datum1, datum2; bool isNull1, isNull2;
if (this->schemaless) { /* In schemaless mode, presorted column data available on each reader. TupleTableSlot just have a jsonb column. */
auto reader_a = readers[a.reader_id]; auto reader_b = readers[b.reader_id];
std::vector<ParquetReader::preSortedColumnData> sorted_cols_data_a = reader_a->get_current_sorted_cols_data();
std::vector<ParquetReader::preSortedColumnData> sorted_cols_data_b = reader_b->get_current_sorted_cols_data();
datum1 = sorted_cols_data_a[attno].val; isNull1 = sorted_cols_data_a[attno].is_null;
datum2 = sorted_cols_data_b[attno].val; isNull2 = sorted_cols_data_b[attno].is_null;
} else {
datum1 = slot_getattr(s1, attno, &isNull1); datum2 = slot_getattr(s2, attno, &isNull2);
}
int compare = ApplySortComparator(datum1, isNull1, datum2, isNull2, &sort_key);
if (compare != 0)
return (compare > 0);
}
return false;
}
get_schemaless_sortkeys函数主要用途是判别如果sorted_cols中包含的列,而reader list中的该列没有数据,则需要将其剔除出sort_keys列表。
/* get_schemaless_sortkeys
* - Get sorkeys list from reader list.
* - The sorkey is create when create column mapping on each reader
*/
void get_schemaless_sortkeys() {
this->sort_keys.clear();
for (size_t i = 0; i < this->sorted_cols.size(); i++) {
for (auto reader: readers) { /* load sort key from all reader */
ParquetReader::preSortedColumnData sd = reader->get_current_sorted_cols_data()[i];
if (sd.is_available) {
this->sort_keys.push_back(sd.sortkey);
break;
}
}
}
}
MultifileMergeExecutionStateS3
MultifileMergeExecutionStateS3继承自MultifileMergeExecutionStateBaseS3类,没有新增成员,包含的成员函数和上节的ExecutionStateS3子类类似。add_file函数创建ParquetReader的流程和上节的ExecutionStateS3子类类似,不同之处在于需要将新创建的reader加入readers vector,且每个reader拥有自己的标识,以每次添加前的readers vector大小作为reader_id标识。
void add_file(const char *filename, List *rowgroups) {
ListCell *lc; std::vector<int> rg;
foreach (lc, rowgroups)
rg.push_back(lfirst_int(lc));
int32_t reader_id = readers.size(); // 以readers vector大小作为reader_id标识
ParquetReader *r = create_parquet_reader(filename, cxt, reader_id);
r->set_rowgroups_list(rg); r->set_options(use_threads, use_mmap);
if (s3_client) r->open(dirname, s3_client);
else r->open();
r->set_schemaless_info(schemaless, slcols, sorted_cols);
r->create_column_mapping(tuple_desc, attrs_used);
readers.push_back(r); // 将新创建的reader加入readers vector
}
initialize_slots函数在第一次 调用next函数时被调用,用于初始化slots binary heap。
/* initialize_slots Initialize slots binary heap on the first run. */
void initialize_slots(){
std::function<bool(const ReaderSlot &, const ReaderSlot &)> cmp = [this] (const ReaderSlot &a, const ReaderSlot &b) { return compare_slots(a, b); }; // 确定比较函数
int i = 0;
slots.init(readers.size(), cmp);
for (auto reader: readers) { // 循环对每个reader创建ReaderSlot
ReaderSlot rs;
PG_TRY_INLINE(
{
MemoryContext oldcxt = MemoryContextSwitchTo(cxt); rs.slot = MakeTupleTableSlotCompat(tuple_desc); MemoryContextSwitchTo(oldcxt);
}, "failed to create a TupleTableSlot"
);
if (reader->next(rs.slot) == RS_SUCCESS) {
ExecStoreVirtualTuple(rs.slot);
rs.reader_id = i;
slots.append(rs); // 如果next调用成功,则保留该ReaderSlot
}
++i;
}
if (this->schemaless) get_schemaless_sortkeys();
PG_TRY_INLINE({ slots.heapify(); }, "heapify failed");
slots_initialized = true;
}
next函数在slots_initialized为false,即未初始化slots binary heap时,初始化heap。获取slots heap中最小的ReaderSlot,从其中读取一条记录作为返回slot。尝试从与head slot相同的读取器读取另一条记录。如果成功,新记录将其放入堆中,堆将被重新初始化。否则,如果读取器中没有更多的记录,那么当前头将从堆中移除,堆将重新被初始化。
bool next(TupleTableSlot *slot, bool /* fake=false */) {
if (unlikely(!slots_initialized)) initialize_slots();
if (unlikely(slots.empty())) return false;
/* Copy slot with the smallest key into the resulting slot */
const ReaderSlot &head = slots.head(); // 获取slots heap中最小的ReaderSlot,即head处的
PG_TRY_INLINE(
{
ExecCopySlot(slot, head.slot); ExecClearTuple(head.slot);
}, "failed to copy a virtual tuple slot"
);
/* Try to read another record from the same reader as in the head slot. In case of success the new record makes it into the heap and the heap gets reheapified. Else if there are no more records in the reader then current head is removed from the heap and heap gets reheapified. */
if (readers[head.reader_id]->next(head.slot) == RS_SUCCESS){
ExecStoreVirtualTuple(head.slot);
PG_TRY_INLINE({ slots.heapify_head(); }, "heapify failed");
} else {
#if PG_VERSION_NUM < 110000
/* Release slot resources */
PG_TRY_INLINE(
{
ExecDropSingleTupleTableSlot(head.slot);
}, "failed to drop a tuple slot"
);
#endif
slots.pop();
}
return true;
}
CachingMultifileMergeExecutionStateS3
CachingMultifileMergeExecutionStateS3是MultifileMergeExecutionState的一个专门版本,它能够合并大量文件,而不会同时打开所有文件。为此,它利用CachingParqueReader将所有读取数据存储在内部缓冲区中。其新增std::vector<uint64_t> ts_active存储每个reader activation的时间戳,用于获取最近最少使用active的reader。int num_active_readers用于存储标识为active的reader的数量,int max_open_files用于存储最大打开文件的数量。
activate_reader函数的流程如下:如果reader尚未激活,则打开它。如果active readers的数量超过限制,函数将关闭最近最少使用的reader。
ParquetReader *activate_reader(ParquetReader *reader) {
if (ts_active[reader->id()] > 0) return reader; /* If reader's already active then we're done here */
if (max_open_files > 0 && num_active_readers >= max_open_files) { /* Does the number of active readers exceeds limit? */
uint64_t ts_min = -1; /* initialize with max uint64_t */ int idx_min = -1;
/* Find the least recently used reader */
for (std::vector<ParquetReader *>::size_type i = 0; i < readers.size(); ++i) {
if (ts_active[i] > 0 && ts_active[i] < ts_min) {
ts_min = ts_active[i]; idx_min = i;
}
}
if (idx_min < 0) throw std::runtime_error("failed to find a reader to deactivate");
readers[idx_min]->close(); // 关闭最近最少使用的reader
ts_active[idx_min] = 0; num_active_readers--;
}
struct timeval tv; gettimeofday(&tv, NULL);
/* Reopen the reader and update timestamp */
ts_active[reader->id()] = tv.tv_sec*1000LL + tv.tv_usec/1000;
if (s3_client) reader->open(dirname, s3_client);
else reader->open();
num_active_readers++;
return reader;
}
initialize_slots函数初始化slots binary heap,和上一个类的函数不同之处在于其初始化ts_active,并调用activate_reader函数对reader进行了激活,并且调用了reader对象的set_schemaless_info和create_column_mapping函数。
/* initialize_slots Initialize slots binary heap on the first run. */
void initialize_slots() {
std::function<bool(const ReaderSlot &, const ReaderSlot &)> cmp =
[this] (const ReaderSlot &a, const ReaderSlot &b) { return compare_slots(a, b); };
int i = 0;
this->ts_active.resize(readers.size(), 0);
slots.init(readers.size(), cmp);
for (auto reader: readers)
{
ReaderSlot rs;
PG_TRY_INLINE(
{
MemoryContext oldcxt;
oldcxt = MemoryContextSwitchTo(cxt);
rs.slot = MakeTupleTableSlotCompat(tuple_desc);
MemoryContextSwitchTo(oldcxt);
}, "failed to create a TupleTableSlot"
);
activate_reader(reader);
reader->set_schemaless_info(schemaless, slcols, sorted_cols);
reader->create_column_mapping(tuple_desc, attrs_used);
if (reader->next(rs.slot) == RS_SUCCESS)
{
ExecStoreVirtualTuple(rs.slot);
rs.reader_id = i;
slots.append(rs);
}
++i;
}
if (this->schemaless)
get_schemaless_sortkeys();
PG_TRY_INLINE({ slots.heapify(); }, "heapify failed");
slots_initialized = true;
}
next函数用于获取下一个solt,和上一个类的函数不同之处在于ReadStatus增加了RS_INACTIVE类型的处理,也就是调用activate_reader函数激活对应的reader。
bool next(TupleTableSlot *slot, bool /* fake=false */) {
if (unlikely(!slots_initialized)) initialize_slots();
if (unlikely(slots.empty())) return false;
/* Copy slot with the smallest key into the resulting slot */
const ReaderSlot &head = slots.head();
PG_TRY_INLINE(
{
ExecCopySlot(slot, head.slot); ExecClearTuple(head.slot);
}, "failed to copy a virtual tuple slot"
);
/* Try to read another record from the same reader as in the head slot.
* In case of success the new record makes it into the heap and the
* heap gets reheapified. If next() returns RS_INACTIVE try to reopen
* reader and retry. If there are no more records in the reader then
* current head is removed from the heap and heap gets reheapified.
*/
while (true) {
ReadStatus status = readers[head.reader_id]->next(head.slot);
switch(status) {
case RS_SUCCESS:
ExecStoreVirtualTuple(head.slot);
PG_TRY_INLINE({ slots.heapify_head(); }, "heapify failed");
return true;
case RS_INACTIVE: /* Reactivate reader and retry */
activate_reader(readers[head.reader_id]); break;
case RS_EOF:
#if PG_VERSION_NUM < 110000
/* Release slot resources */
PG_TRY_INLINE(
{
ExecDropSingleTupleTableSlot(head.slot);
}, "failed to drop a tuple slot"
);
#endif
slots.pop();
return true;
}
}
}