NIN神经网络
- 原理图:
- 代码实现:
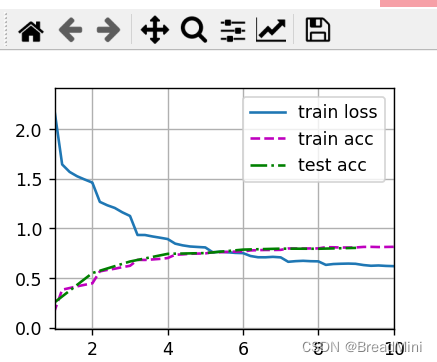
- 输出结果:
原理图:
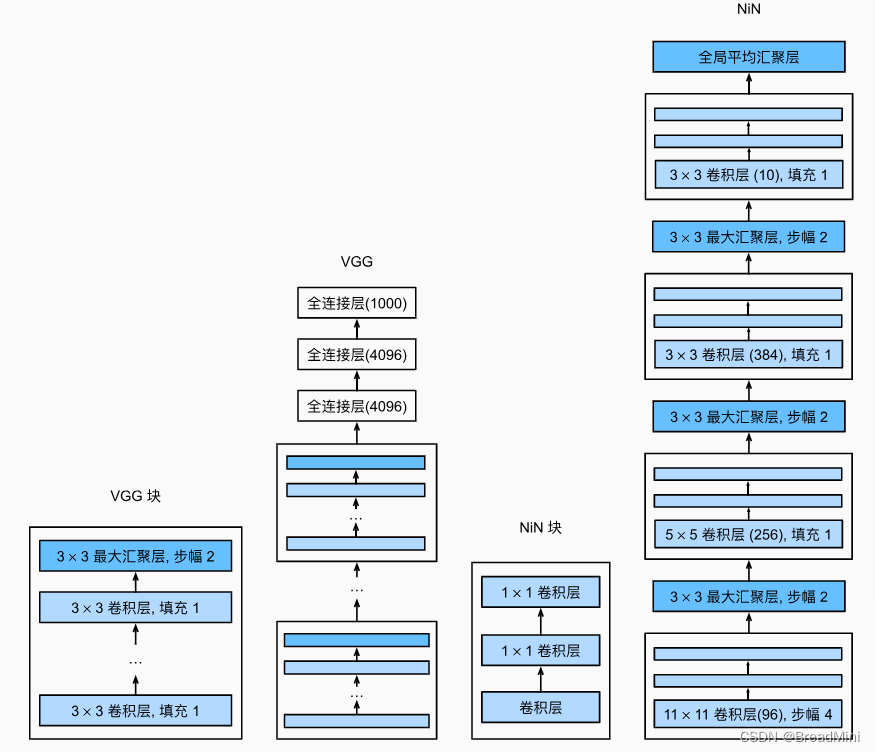
代码实现:
import torch
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
#模块化设计思想,方便重复使用。
#经过一个卷积层,再加两个1*1的卷积层。起到全连接层的作用。
nn.Conv2d(in_channels,out_channels,kernel_size,strides,padding),
nn.ReLU(),
# 两个1*1的卷积层,并不会改变形状,不改变通道数
nn.Conv2d(out_channels, out_channels, kernel_size=1, stride=1),
nn.ReLU(),
nn.Conv2d(out_channels,out_channels,kernel_size=1,stride=1),
nn.ReLU(),
)
#nn.Sequential 容器
net = nn.Sequential(
nin_block(1,96,kernel_size=11,strides=4,padding=0),
nn.MaxPool2d(kernel_size=3,stride=2),
nin_block(96,256,kernel_size=5,strides=1,padding=2),
nn.MaxPool2d(kernel_size=3,stride=2),
nin_block(256,384,kernel_size=3,strides=1,padding=1),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Dropout(0.5),
# [1,10,5,5]
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
#自适应平均池化。与普通的池化层不同,允许指定输出特征图的大小而不是池化层的大小。
#[1,10,5,5] => [1,10,1,1]
nn.AdaptiveAvgPool2d(output_size=(1,1)),
# [1,10,1,1] =>[1,10*1*1] =>[1,10]
nn.Flatten()
)
#开始训练
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
输出结果: