fero - yolo - mamba:基于选择性状态空间的面部表情检测与分类
- 摘要
- Introduction
- Related work
FER-YOLO-Mamba: Facial Expression Detection and Classification Based on Selective State Space
摘要
面部表情识别(FER)在理解人类情绪线索方面起着关键作用。然而,基于视觉信息的传统FER方法存在一些局限性,如预处理、特征提取和多阶段分类过程。
这些不仅增加了计算复杂性,还需要大量的计算资源。
考虑到基于卷积神经网络(CNN)的FER方案在识别面部表情图像中嵌入的深层、长距离依赖关系方面常常不足,以及Transformer固有的二次计算复杂性,本文提出了FER-YOLO-Mamba模型,该模型融合了Mamba和YOLO技术的原理,以促进面部表情图像识别和定位的高效协调。
在FER-YOLO-Mamba模型中,作者进一步设计了一个FER-YOLO-VSS双分支模块,该模块结合了卷积层在局部特征提取中的固有优势与状态空间模型(SSMs)在揭示长距离依赖关系方面的卓越能力。
据作者所知,这是首次为面部表情检测和分类设计的视觉Mamba模型。
为了评估所提出的FER-YOLO-Mamba模型的性能,作者在两个基准数据集RAF-DB和SFEW上进行了实验。
实验结果表明,FER-YOLO-Mamba 模型与其他模型相比取得了更好的结果。
Introduction
面部表情识别(FER)作为情感识别的基本组成部分,有效地捕捉和分析微妙的面部变化,揭示了个人的情感状态。随着人工智能(AI)和计算机视觉(CV)的发展,它已成为情感计算领域的基石,为人类-计算机交互和情感分析等应用提供了强大的支持[1]。准确的面部表情识别不仅能让人们更深入地了解人类情感的复杂内涵,也为开发智能和富有同情心的交互系统奠定了坚实的基础。目前,FER已在情感计算、人类-计算机交互、辅助医疗、智能监控和安全、娱乐产业、远程教育以及情感状态分析等领域得到广泛应用,吸引了众多研究者的关注[2]。
传统的基于视觉的FER通常依赖于视觉信息,如面部图像或视频,来分析和识别个人的面部表情并确定其情感状态。这一技术源自计算机视觉和模式识别,涉及多个步骤,如面部图像的预处理、特征提取和分类。对于FER任务,面部图像预处理对于后续的特征提取和识别至关重要,包括面部检测、对齐和归一化操作。预处理之后,使用特定的算法或模型从眼睛、嘴巴和眉毛等区域提取面部表情特征,包括形状、纹理和运动信息。
基于提取的特征,采用分类器或识别算法对表情进行分类,包括识别微笑、愤怒、惊讶等其他情感状态[3, 4]。尽管基于视觉的FER技术已经取得了一系列显著成果,但它往往依赖于手动设计的特征提取器,这在一定程度上可能限制了其准确捕捉和分类复杂多变的面部表情的能力。由于面部表情的多样性和动态性,传统的手动特征提取方法可能无法全面捕捉微妙的面部变化,导致分类准确率下降。此外,光照条件、 Head 姿态和遮挡等因素也可能对识别性能产生负面影响[5]。
此外,基于深度学习的目标检测能够检测目标同时获取深层特征,从而实现精确分类。因此,将这项技术应用于面部表情的检测和分类具有广泛的研究前景。目前基于深度学习的FER研究主要集中在CNN和Transformer模型的优化上,因为CNN往往难以捕捉长距离依赖关系和细粒度的面部表情特征,而Transformer模型受到二次计算复杂度的限制[6]。在这种情况下,由于在建模长距离交互的同时保持了线性计算复杂度,状态空间模型(SSMs)中的Mamba模型[7]引起了研究者的关注,以解决这些限制。
为了克服现有技术的局限,本文提出了一个用于FER任务的YOLO-Mamba模型,命名为FER-YOLO-Mamba,它结合了YOLO和Mamba的优势,实现了对面部表情图像的高效检测和分类。本文的主要贡献可以总结如下:
作者创新性地开发了一个FER-YOLO-Mamba模型,它基于SSM构建了一个视觉 Backbone 网络。这是将SSM驱动的架构集成到面部表情检测和分类领域的一次开创性尝试,首次探索了该模型在这一领域的研究。
作者进一步设计了一个双分支结构,它不仅整合了原始的局部详细信息以及OSS提供的全局上下文信息,还结合了具有多层感知机的注意力机制。该注意力机制通过全局平均池化、多层感知机(MLPs)和逐元素乘法技术实现输入特征图的空间注意力机制。通过选择性地放大关键信息区域,同时降低不相关或次要区域的影响,该模块显著增强了模型在FER任务中的辨别力和精确度。
为了验证所提出的FER-YOLO-Mamba模型的有效性,作者在两个手动标注的面部表情数据集RAF-DB和SFEW上进行了实验。实验结果表明,与其它方法相比,FER-YOLO-Mamba模型取得了更好的效果。
本文的其余部分组织如下:第二节概述了相关工作。第三节在介绍SSM原理之前,详细介绍了作者提出的FER-YOLO-Mamba的设计。第四节作者披露了用于实验的数据集并提供性能分析。最后,第五节总结了本文。
Related work
Facial Expression Recognition
FER在人类-计算机交互领域扮演着至关重要的角色,尤其是在智能机器人和虚拟助手等应用中。通过准确识别用户的面部表情,系统可以更好地理解用户的情绪和意图,从而提供更加个性化的服务体验。此外,FER在心理健康领域也展示了其独特的价值。在协助诊断和治疗抑郁症和自闭症等疾病时,医生通过分析患者的面部表情可以更准确地评估患者的情绪状态,从而制定出更有效的治疗方案。这项技术的应用不仅提高了心理健康服务的准确性和效率,还让患者获得了更精确的诊断和治疗体验。
为了实现面部表情的自动分类,传统的基于视觉信息的FER方法主要侧重于通过图像处理技术和模式识别算法提取和分析面部特征。这些方法通常包括人脸检测、特征提取和表情分类。
在特征提取阶段,传统的FER方法常常依赖于手工设计的特征提取器,包括几何、纹理和运动特征提取。在基于几何特征的方法中,特征是通过分析面部标志点的位置、距离和角度获得的。Tian等人[3]提出了一种基于几何特征的FER方法,该方法识别和分析面部动作单元以实现表情分类。基于纹理特征的方法则利用面部皮肤纹理的变化来识别表情,通常通过灰度共生矩阵或局部二值模式计算。Shan等人[8]使用局部二值模式作为纹理特征进行FER。此外,运动特征方法用于捕捉面部肌肉的运动和变化以识别不同的表情。Bartlett等人[9]提出了一种结合了几何和动态特征的FER方法,在自发表情识别中取得了良好的性能。
在分类器设计中,传统方法通常使用诸如支持向量机(SVM)、K近邻(KNN)等机器学习算法。Alhussan等人[10]提出了一种基于优化SVM的有效的FER方法,强调了模型优化和特征提取在提高识别性能中的重要性。Subudhiray等人[4]讨论了基于K近邻算法的面部情绪识别技术,强调了使用有效特征的重要性。
为了克服手工设计特征提取器在FER中的局限性,这些传统方法常常在复杂环境中难以全面捕捉与表情相关的关键信息,并缺乏对光照、面部姿态和遮挡的鲁棒性。因此,越来越多的研究行人转向深度学习方法,尤其是卷积神经网络(CNNs),用于面部表情识别任务。结果,Wang等人[11]介绍了一种基于CNN的FER方法,并关注了不同卷积层之间信息共享和重用的概念。Sarvakar等人[12]构建了一个基于CNN的FER模型,该模型在多个面部表情数据集上进行训练和测试。此外,Patro等人[13]开发了一个基于定制DCNN的FER系统。通过深度学习方法,该系统可以自动学习和提取与快乐、悲伤、愤怒等情绪相关的特征。
此外,作为FER研究的另一个持续领域,基于多模态信息融合的方法不仅整合视觉信息,还融合了音频、文本等其他模态的数据,以进一步提高FER的准确性和可靠性。Zadeh等人[14]研究了不同数据源在情绪分析中的利用,提出了一种张量融合网络,以整合和分析来自不同模态的数据。同样,Pan等人[15]提出了一种基于面部表情、语音和脑电图(EEG)的多模态情绪识别方法。提取的情绪特征不仅包括传统的面部表情和语音特征,还包括EEG信号的特征。在[16]中,Zhang等人对基于深度学习的多模态情绪识别技术进行了系统回顾,主要讨论了情绪识别的最新发展和前景。
Object Detection Methods Based on the YOLO Series
近年来,随着深度学习技术的发展,目标检测算法取得了显著进展。在这些算法中,由于YOLO(You Only Look Once)系列算法的效率和实时性能,它们受到了广泛关注。
YOLO算法的第一个版本[17]提出了将目标检测任务转化为回归问题的概念。随后,YOLOv2[18]在原版基础上进行了几处改进,包括引入批量归一化以提高模型的收敛速度和稳定性,以及使用高分辨率分类器来提升其捕捉细粒度特征的能力。此外,YOLOv3[19]通过使用更深的Darknet-53架构改进了网络结构,并引入了残差连接以防止梯度消失和模型退化。YOLOv3还采用了多尺度预测,通过在不同尺度的特征图上检测来有效捕捉不同大小的物体。
随后,为了在保持YOLO系列效率的同时提高准确度,YOLOv4[20]应运而生,它采用了更复杂的网络结构CSPDarknet53,并引入了诸如跨阶段部分连接(CSP)和自对抗训练(SAT)等技术。YOLOv5通过采用更高效的计算方法和硬件加速技术,提高了模型的灵活性和可用性,实现了高准确度和快速检测速度。YOLOv7[21]通过划分网格并在每个网格中预测每个物体的位置和类别,实现了快速准确的目标检测。与之前版本相比,YOLOv7提高了检测准确度,并能满足更多应用场景的需求。作为YOLO系列的最新模型,YOLOv8由Ultralytics发布,基于YOLO系列的历史版本构建。YOLOv8引入了新特性,使用了更深、更复杂的网络结构,以及更高效的损失函数,从而提高了检测准确度和检测速度。此外,由Megvii开发的YOLOX[22]目标检测算法,基于YOLOv3-SPP进行改进,将原始的基于 Anchor 点的方法转变为 Anchor-Free 点形式,并融合了其他先进的检测技术,如解耦头和标签分配SimOTA,实现了卓越的性能。
State Space Model on Visual Recognition
状态空间模型(SSM)最近在深度学习中作为状态空间转换的关键方法受到了关注。从连续控制系统中的SSM获得灵感,并整合了前沿的HiPPO初始化方法,LSSL模型已有效地展示了SSM在解决序列中长期依赖关系的广泛潜力。然而,LSSL模型由于状态表示的计算复杂性和大量的存储需求而面临限制。为了解决这个问题,S4模型被引入,通过参数对角线结构和标准化来提升性能。随后,一系列具有不同结构的SSM(例如,复数对角线结构,选择机制等)出现,展示了在各自应用场景中的显著优势。
在视觉处理方面,Liu等人从SSM获得灵感,提出了视觉状态空间模型(VMamba)。这个模型不仅继承了SSM在全球接收场方面的优势,还实现了线性计算复杂性,显著提高了图像处理的效率。随后,通过引入Res-VMamba模型,Chen等人进一步增强了VMamba模型,并针对细粒度食品图像分类任务进行了优化。在遥感图像分类中,Chen等人提出了RSMamba模型,利用高效的、硬件感知的Mamba实现来有效整合全球接收场和线性复杂性建模的优势。
在医学图像处理方面,Yue等人引入了MedMamba模型,这是第一个专为医学图像分类设计的特定Mamba模型。此外,Ma等人提出了U-Mamba模型,通过结合U-Net架构和Mamba模型的优势,有效提升了生物医学图像分割的性能。Ruan等人提出的VM-UNet模型将视觉Mamba与U-Net结合用于医学图像分割任务,通过整合多尺度特征信息增强了分割的准确性和鲁棒性。Liu等人展示了Swin-UMamba模型,该模型将Swin Transformer与Mamba结合用于预训练,进一步为生物医学图像分割任务的模型准确性做出了贡献。此外,Yang等人引入了Vivim模型,为医学视频目标分割提供了一种新颖的方法。Gong等人展示了nnMamba模型的卓越性能,该模型通过结合深度学习与SSM的优势,在处理复杂的3D图像数据方面表现出色。最后,Guo等人提出了MambaMorph模型,为可变形MR-CT配准任务提供了一种新的解决方案。
State Space Models
状态空间模型(SSMs)因其独特的封装动态系统能力而越来越受到研究者的青睐。这种模型能有效地将输入信号(表示为
x
(
t
)
∈
R
5
x(t) \in \mathbb{R}^5
x(t)∈R5)通过隐含的潜在状态
h
(
t
)
∈
R
N
h(t) \in \mathbb{R}^N
h(t)∈RN 转换为输出变量(表示为
y
(
t
)
∈
R
5
y(t) \in \mathbb{R}^5
y(t)∈R5),在建模复杂时间序列时显示出强大的适应性。SSMs深深植根于控制理论,其核心结构由以下一组线性常微分方程(ODEs)给出:
h ′ ( t ) = A h ( t ) + B x ( t ) , h'(t) = Ah(t) + Bx(t), h′(t)=Ah(t)+Bx(t),
其中 A ∈ C N × N A \in \mathbb{C}^{N \times N} A∈CN×N, B , C ∈ C N B, C \in \mathbb{C}^N B,C∈CN 对于一个状态大小 N N N,以及连接矩阵 D ∈ C D \in \mathbb{C} D∈C。
在SSMs中,状态转移矩阵 A A A 在决定状态向量 h ( t ) h(t) h(t) 的演变路径方面起着关键作用,而输入矩阵 B B B、输出矩阵 C C C 和前馈矩阵 D D D 分别揭示了输入信号 x ( t ) x(t) x(t)、状态 h ( t ) h(t) h(t) 和输出响应 y ( t ) y(t) y(t) 之间的内在联系。在深度学习中,通常倾向于采用离散时间框架,这需要将描述系统动态特性的连续方程转换为离散形式,以满足计算要求并确保与数据采集的采样频率同步。
SSMs的离散化本质上将系统的连续时间常微分方程组转换为等效的离散时间表示,可以通过对输入信号应用零阶保持策略来实现,从而构建如下离散时间SSM:
h
k
+
1
=
A
h
k
+
B
x
k
,
h_{k+1} = Ah_k + Bx_k,
hk+1=Ahk+Bxk,
y
k
=
C
h
k
+
D
x
k
,
y_k = Ch_k + Dx_k,
yk=Chk+Dxk,
其中
A
=
e
A
Δ
,
B
=
(
e
A
Δ
−
I
)
A
−
1
B
,
C
=
C
,
D
=
D
,
B
,
C
∈
R
D
×
N
A = e^{A\Delta}, B = (e^{A\Delta} - I)A^{-1}B, C = C, D = D, B, C \in \mathbb{R}^{D \times N}
A=eAΔ,B=(eAΔ−I)A−1B,C=C,D=D,B,C∈RD×N,以及
Δ
∈
R
D
\Delta \in \mathbb{R}^D
Δ∈RD。
Mamba算法[7],凭借其在SSM框架内独特的选择性扫描机制,在面部表情检测和分类任务中
显示出显著优势。这种机制的核心在于其能够根据当前和历史上文动态调整系统矩阵B和D
这是其与其他方法区别开来的一个关键特性。
在面部表情图像分析中,多样性和复杂性对传统方法提出了挑战。然而,Mamba算法通过其
选择性扫描机制,专注于输入数据的关键区域,有效地提取与面部表情相关的特征。这种精确
的关注使得算法能够更准确地捕捉到表情的细微变化,从而提高检测和分类的准确性。
重要的是, Mamba算法通过动态调整系统矩阵B和D ,增强了处理复杂时间动态的能力。
这对于面部表情的检测和分类为关键,因为面部表情不仅涉及单帧内的细微差别,还涉及连
续帧之间的动态变化。算法能实时响应输入数据特征的改变,准确捕捉到这种复杂的时间动
态,从而更好地理解面部表情的连续性和动态性,并提高检测和分类的准确性。
总之,凭借其独特的选择性扫描机制和动态调整能力,Mamba算法在面部表情检测和分类任
务中显显距大的潜力。其在捕捉细微表情变化和动态特征彷面的优势使该算法在面部表情图
像分析领域具有广泛的应用前景和重要的研究价值。
Overall architecture
图1示了所提出的FER- YOLO-Mamba网络的架构,该架构主要由三个核心部分组成:
CSPDarknet、FPN和YOLO Head。最初, CSPDarknet作为主干特征提取网络,负责从输入
图像进行初始特征提取。经过CSPDarknet处理后,输入图像转化为三个不同尺度的特征图,
尺对分别为10x 10 x 512、20x 20 x 256和40 x 40 x 128,包含从粗到细的分层多级
特征信息。
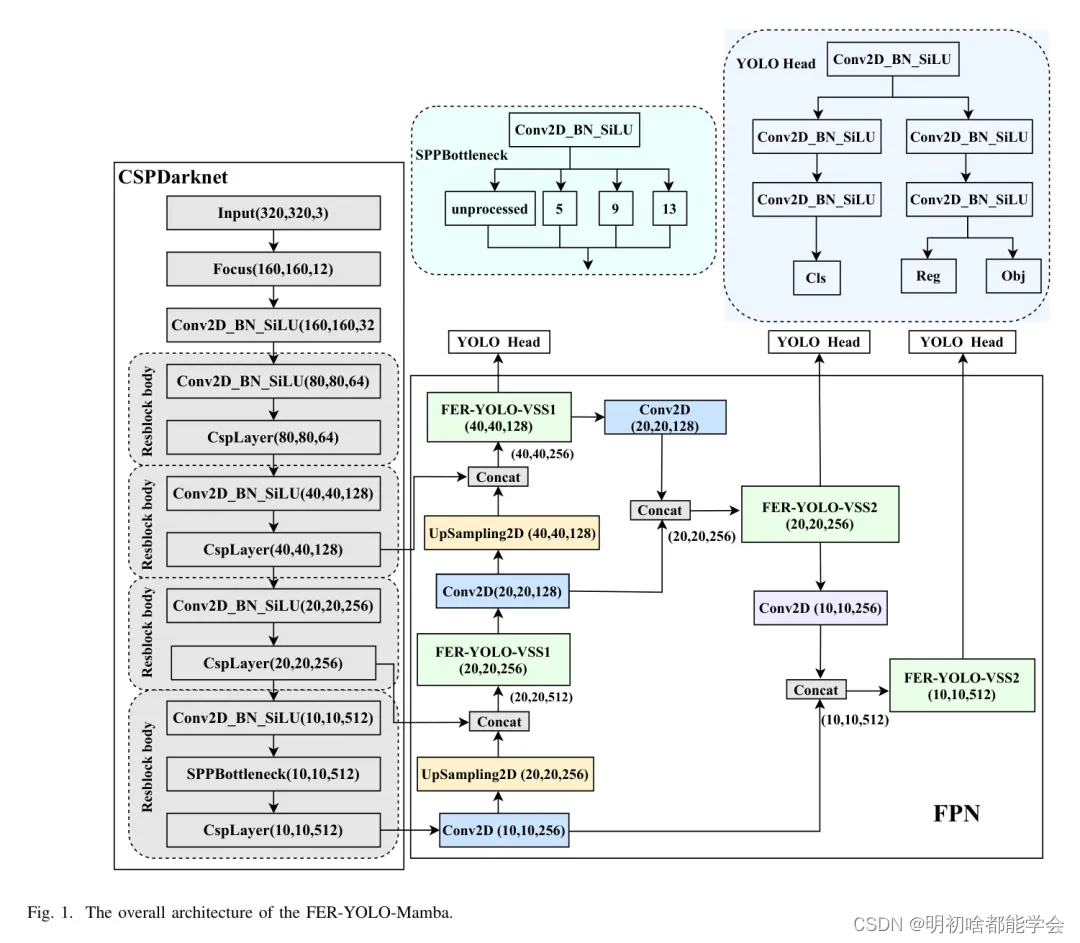
FPN作为增强特征提取网络,通过整合CSPDarknet输出的多尺度特征。该模块的核心概念在于有效地融合跨尺度特征,以捕获不同层次上的细节和上下文信息,从而增强整体特征表示。具体来说,FPN通过上采样将低级特征图上采样到与高级特征图尺寸一致,进行跨尺度交互,同时实施下采样操作以丰富特征融合的维度和深度。
作为FER-YOLO-Mamba框架的关键组成部分,YOLO Head承担分类和定位的双重责任。在CSPDarknet和FPN的协同处理后,网络生成三个加强的多尺度特征图。这些特征图可以被视为包含大量特征点的网格,每个特征点都与其通道相关联的特征向量。YOLO Head的核心机制涉及单独分析这些特征点,以确定它们与目标目标的关联。这个过程包括两个互补且独立的子任务:类预测,以确定与特征点相关联的目标类别;以及边界框回归,以精确估计目标的位置。最终,这两种预测的输出被融合,以全面识别图像中的目标。
与传统的目标检测数据集相比,FER数据集具有独特的特性。尽管它们只关注一个特征,但它们常常受到复杂背景的干扰。传统的FER方法常使用预处理技术来减弱背景影响并简化识别过程。然而,在FER-YOLO-Mamba模型的设计中,作者没有采用这样的预处理步骤。相反,作者直接使用带有背景的原始图像作为输入。这些输入图像的尺寸为,含有丰富的背景信息,这无疑对模型处理复杂场景和干扰的能力提出了更高的要求。同时,这也突显了FER-YOLO-Mamba模型在处理具有复杂背景的FER任务时所采用的独特策略,及其在实践应用中的巨大潜力。
FER-YOLO-VSS module
FER-YOLO-VSS模块是一个双分支结构。具体来说,该模块的输入首先通过通道分裂处理,分为两个大小相等的子输入,如图1所示:FER-YOLO-Mamba的整体架构。在后续步骤中进行独立特征提取和处理。这种设计旨在通过并行处理策略更有效地捕捉和提取图像中的关键特征信息。随后,这两个子输入进入它们各自特定的处理分支,即特征细化模块(FRM)分支和全方位状态空间(OSS)分支。
为了增强模型学习判别性和上下文感知特征表示的能力,FRM分支采用连续的通道维度压缩策略。此外,这个分支还结合了具有自适应特征权重调整的注意力机制,以调整不同特征的重要性。经过这一系列处理后,FRM分支最终恢复到原始的通道数,从而确保信息的完整性和准确性。
OSS分支[30]首先对输入特征应用层归一化作为预处理步骤,之后将归一化的特征分为两条平行的子路径。在第一条路径中,特征经历包括线性变换层和激活函数的简化转换。同时,第二条路径涉及的过程相对更为复杂,因为特征在进入全方位选择性扫描模块(OSSM)深入提取特征信息之前,经历了三个 Level 的逐步处理,包括线性层、深度可分离卷积和激活函数。
OSSM使用SSM技术实现对面部表情图像在水平、垂直、对角线和反向对角线方向的双向选择性扫描。这种方法旨在增强图像在多个方向上的全局有效感受野,并从各种角度提取全局空间特征。具体来说,八种不同方向的选择性扫描能够从多个方向捕捉到大规模空间特征。在此之后,应用层归一化来标准化特征,并通过元素乘法将此分支的输出与第一条分支的输出进行深度融合。随后,借助线性混合层来整合每个分支的特征,并融入残差连接策略,协同构建FER-YOLO-VSS2模块的最终输出响应。在OSS分支中,SiLU激活函数被选为默认激活单元。最后,将两个分支的输出特征沿通道维度拼接,并通过1x1卷积层进行深层特征融合,以增强特征图之间的深层交互效果。
根据输出通道数的不同,FER-YOLO-VSS模块分为两个变体: FER-YOLO-VSS1 和 FER-YOLO-VSS2。FER-YOLO-VSS1 旨在减少通道数,引入了“捷径”连接机制(C → 2C)。同时,FER-YOLO-VSS2 保持了输入和输出通道数的一致性,增加了“捷径”连接以提高信息流效率(C → C)。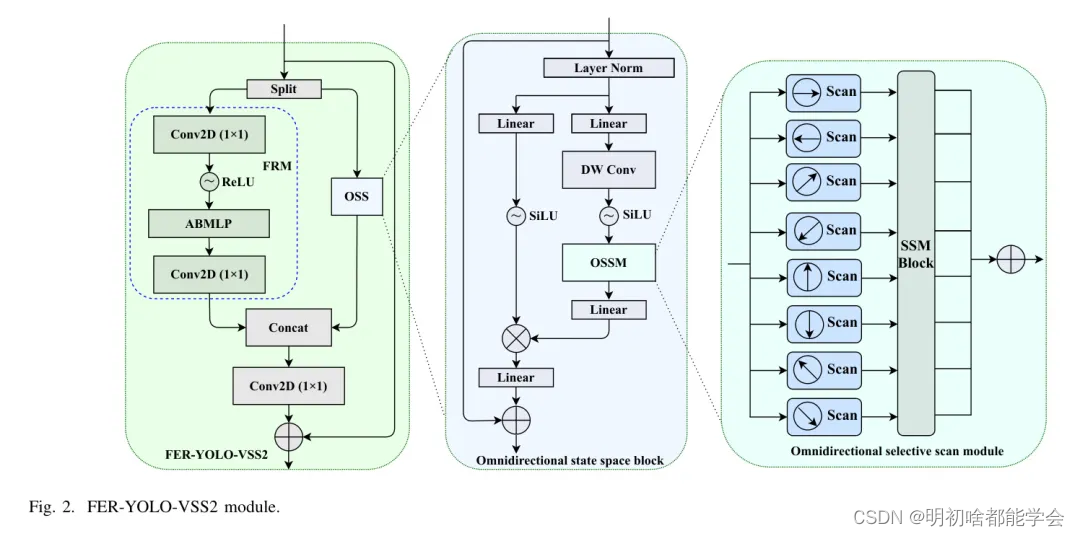
总的来说,作为核心模块,FER YOLO-VSS 不仅整合了原始的局部信息,还整合了来自 OSS 提供的全局上下文信息,并融合了带有多层感知机的注意力机制。这种设计策略旨在通过注意力机制实现局部和全局信息的互补融合,从而提高模型处理关键信息的能力,进而提升整体性能。
注力块与多层感知机(ABMLP)模块融合了全局平均池化、多层感知机(MLP)和逐元素乘法技术,以实现对输入特征图的空域注意力机制。其核心功能是在识别任务中选择性地突出关键信息区域,同时减弱不相关或次要区域的影响,从而提高模型的判别性能。
ABMLP 的伪代码如算法1所示。首先,形状为 ( x \in \mathbb{R}^{R \times b \times c \times h \times w} ) 的输入特征图通过全局平均池化得到一个形状为 ( (b, c) ) 的特征向量 ( y )。随后,特征向量 ( y ) 被送入 MLP 中,通过一系列非线性变换生成注意力权重向量。这个 MLP 包含三个线性层,在两层后引入 ReLU 激活函数以引入非线性特性,并在最后使用 Sigmoid 激活函数以产生注意力权重向量。

这个权重响量适当地重新调整形状以匹配原始输入特征图的维度,结果是形状为(b, c, 1, 1)以.
进行后续操作。后,重新调整形状的注意力权重响量与原始输入特征图x进行逐元素乘法,
生成自注意力增强的特征图,这是ABMLP模块的输出结果。