kaggle 叶子分类
- 目的:将叶子进行分类。
- 实现步骤:
- 1、数据处理:
- 2、加载数据
- 3、 定义残差块
- 4、定义Resnet模型。
- 5、定义训练以及评估函数:
- 6、开始训练:
- 7、输出结果:
目的:将叶子进行分类。
实现步骤:
1、数据处理:
对数据进行处理。由于数据图片(测试集,训练集,验证集全都放在了images中,应将其进行分开)
处理步骤:
1、 读取csv文件,解析其中的地址信息。
2、 创建 训练集 和 测试集 的文件夹,用于存放对应的图片数据。
3、 遍历 训练数据 和 测试数据 中的图片地址,从images复制到对应文件夹中
定义数据处理函数:
#定义读取数据的函数
def read_images():
# 读取 csv文件。
train_df = pd.read_csv("train.csv")
test_df = pd.read_csv("test.csv")
# 创建 保存训练集和测试集的文件夹
os.makedirs(name="train_images",exist_ok=True) #训练集
os.makedirs(name="val_images",exist_ok=True) #验证集
os.makedirs(name="test_images",exist_ok=True) #测试集
#设置验证集的占比
val_ration = 0.2
#获取训练集的样本数量。
num_samples = len(train_df)
#验证集的样本数量。
num_val_samples = int(num_samples * val_ration)
# 取出验证集的所有索引
val_indices = random.sample(range(num_samples),num_val_samples)
# print(val_indices)
#复制images中的数据到 训练集中
for index,row in train_df.iterrows():
# print(row[1]) #打印看一下数据格式
# print(index)
# print(row['image'])
image_path = row['image']
label = row['label']
# 若下标在验证集的索引中:
if index in val_indices:
target_dir = os.path.join("val_images",label)
else:
target_dir = os.path.join("train_images", label)
os.makedirs(target_dir,exist_ok=True)
shutil.copy(image_path,target_dir)
#复制images中的数据到 训练集中
for row in train_df.iterrows():
#print(row[1]) #打印看一下数据格式
# print(row[1]['image'])
image_path = row[1]['image']
label = row[1]['label']
target_dir = os.path.join("train_images",label)
os.makedirs(target_dir,exist_ok=True)
shutil.copy(image_path,target_dir)
#复制images中的数据到 测试集 中
for row in test_df.iterrows():
#print(row[1]) #打印看一下数据格式
# print(row[1]['image'])
image_path = row[1]['image']
target_dir = os.path.join("test_images/test_data")
os.makedirs(target_dir,exist_ok=True)
shutil.copy(image_path,target_dir)
# read_images()
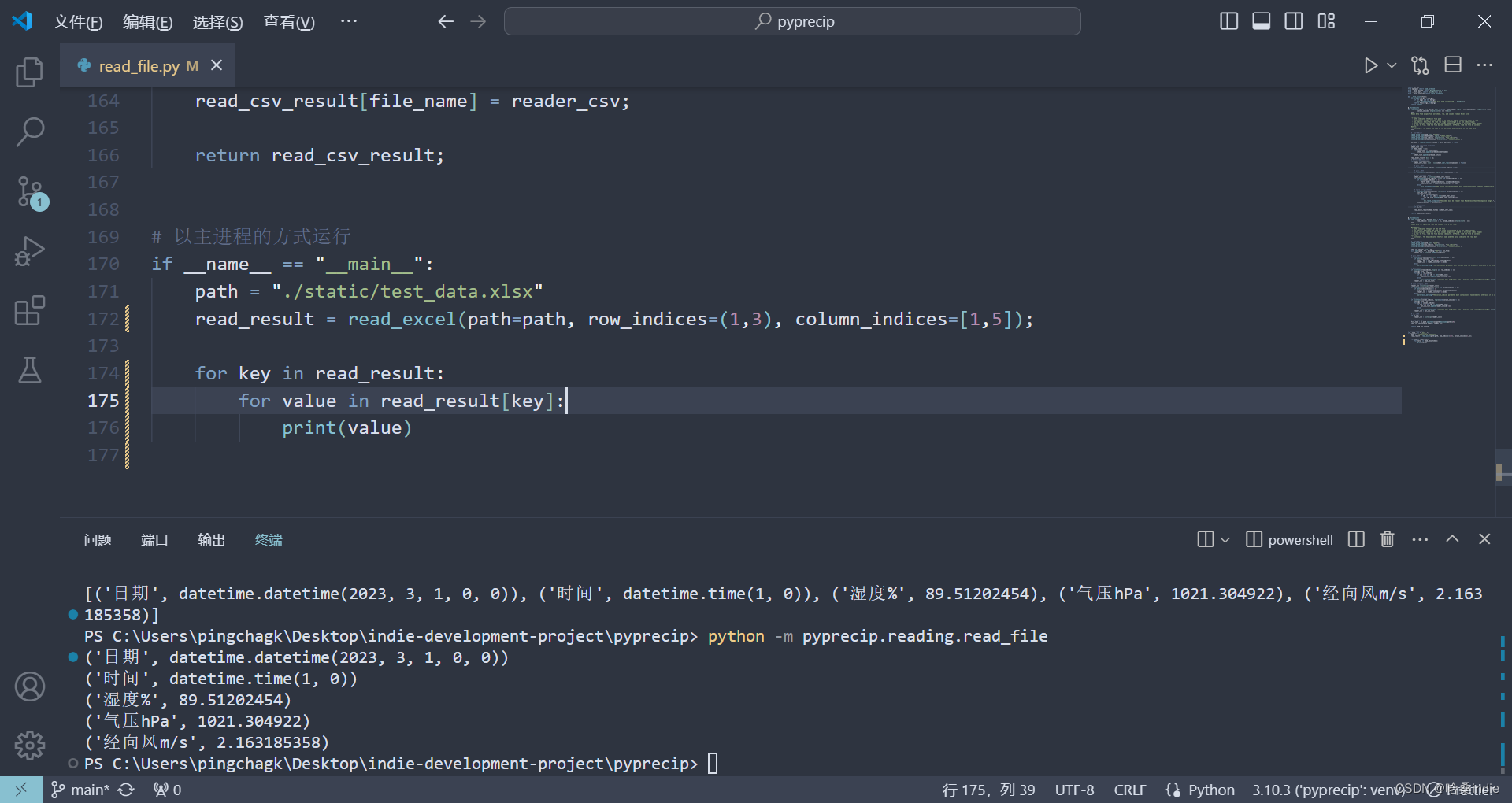
对于读取测试集时,
target_dir = os.path.join(“test_images/test_data”) 这里的路径我为啥要设置多一个/test_data呢,因为如果不设置这个文件夹的话,后续使用Dataloader.datasets.ImageFolder 就读取不了,但是我现在不知道如何直接加载一个文件夹中图片,所以暂时只能这样。
2、加载数据
tran = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
# torchvision.transforms.Resize((96,96))
]
)
#读取数据
train_data = torchvision.datasets.ImageFolder(root="train_images",transform=torchvision.transforms.ToTensor())
val_data = torchvision.datasets.ImageFolder(root="val_images",transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.ImageFolder(root="test_images",transform=torchvision.transforms.ToTensor())
batch_sz = 256
#加载数据
train_loader = DataLoader(train_data,batch_sz,shuffle=True,drop_last=True)
val_loader = DataLoader(val_data,batch_sz,shuffle=False,drop_last=False)
test_loader = DataLoader(test_data,batch_sz,shuffle=False,drop_last=False)
# for (images,labels) in train_loader:
# print(images.shape)
# 从上边这段代码可知 images维度torch.Size([128, 3, 224, 224]) (样本数量,通道,高度,宽度)
3、 定义残差块
class ResidualBlock(nn.Module):
def __init__(self,in_channels,out_channels,strides=1):
super(ResidualBlock,self).__init__()
# 设置卷积核为3,padding =1能够保持大小不变
self.conv1 = nn.Conv2d(in_channels,out_channels,kernel_size=3,stride=strides,padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels,out_channels,kernel_size=3,stride=1,padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
#如果
self.downsample = None
# 因为步幅不为 1 的话 就会导致形状大小发生变化。
if strides != 1 or in_channels != out_channels:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels,out_channels,kernel_size=1,stride=strides),
nn.BatchNorm2d(out_channels)
)
def forward(self,X):
Y = self.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.downsample is not None:
X = self.downsample(X)
Y += X
return self.relu(Y)
4、定义Resnet模型。
原理图:
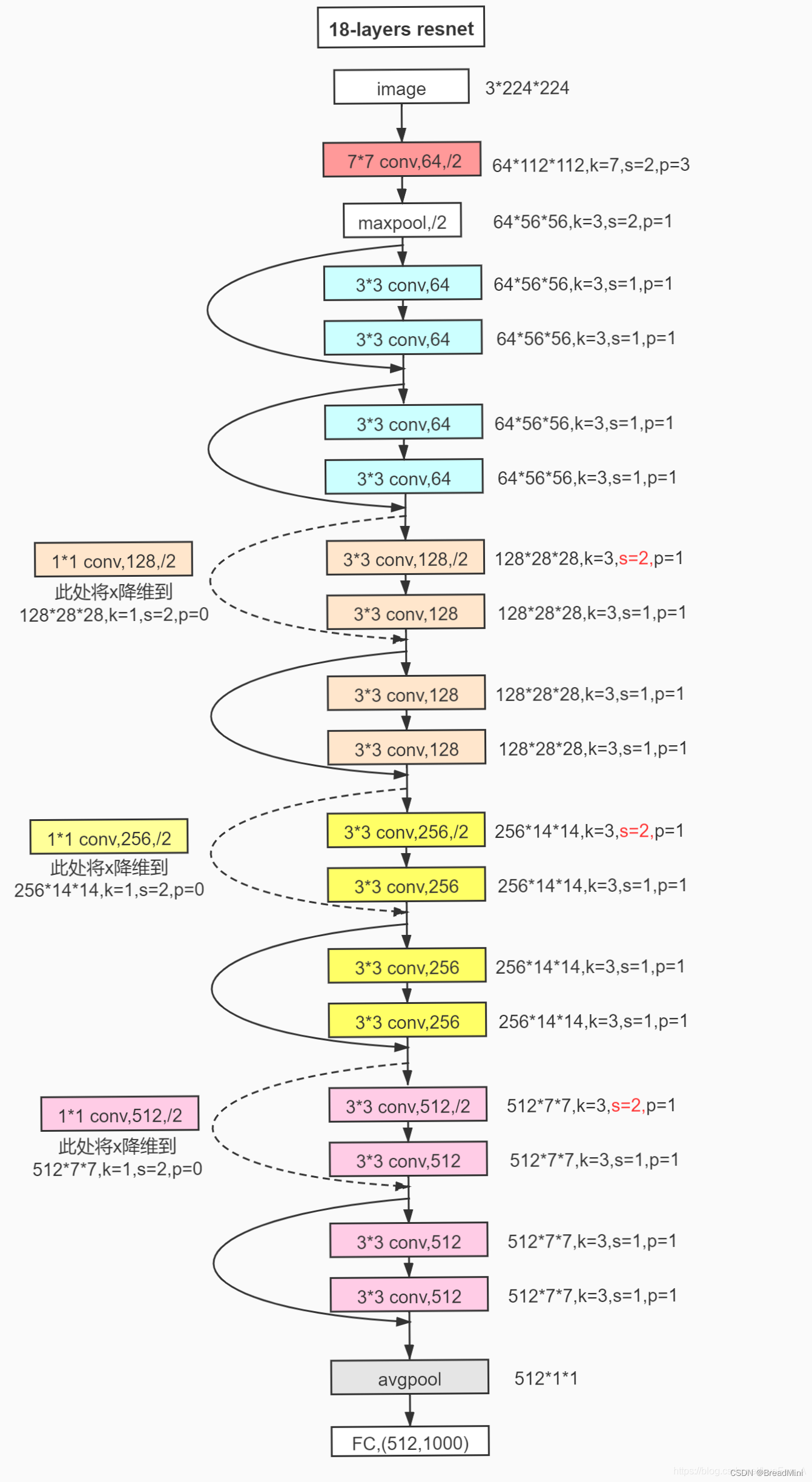
定义Resnet18模型。
第一层:7x7 的卷积层,64 个输出通道,步幅为 2。
最大池化层:3x3 的池化核,步幅为 2,用于下采样。
4 个阶段(layers),每个阶段包含若干个残差块(ResidualBlock)。
第一个阶段:2 个残差块。 每个残差块包括两个卷积。
第二个阶段:2 个残差块。
第三个阶段:2 个残差块。
第四个阶段:2 个残差块。
全局平均池化层:对特征图进行全局平均池化,将每个通道的特征图变成一个值。
全连接层:将全局平均池化层的输出连接到输出类别数量的全连接层,用于分类
class Resnet18(nn.Module):
def __init__(self):
super(Resnet18, self).__init__()
# H2 = (224- 7 + 3 * 2) / 2 +1 =112
# [128,3,224,224] => [128,64,112,112]
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
# H2 = (112 - 3 + 2*1 )/2 +1 = 56
# [128,64,112,112] => [128,64,56,56]
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 添加残缺块 1,每个残缺块呢,当block2为2时,会产生2个残缺块,执行四次卷积。
# H2 = (56 - 3+2*1)/1 +1 = 56
# 第一个残缺块:[128,64,56,56] => [128,64,56,56]
# [128,64,56,56] => [128,64,56,56]
# 第二个残缺块:[128,64,56,56] => [128,64,56,56]
# [128,64,56,56] => [128,64,56,56]
self.layer1 = self.make_layer(64, 64, 2)
# 添加残缺块 2
# 第一个残缺块:H2 = (56 - 3 +2*1)/2+1 = 28
# [128,64,56,56] => [128,128,28,28]
# H2 = (28 - 3 + 2*1)/1 +1 =28
# [128,128,56,56] => [128,128,28,28]
# X : [128,64,56,56] => [128,128,28,28] 只是将X的通道数和形状变为与 Y一致,可相加。
#第二个残缺块:[128,128,28,28] => [128,128,28,28]
# [128,128,28,28] => [128,128,28,28]
self.layer2 = self.make_layer(64, 128, 2, stride=2)
# 添加残缺块 3
# 第一个残缺块:H2 = (28-3 + 2*1)/2 +1 = 14
# [128,128,28,28] => [128,256,14,14]
# [128,256,14,14] => [128,256,14,14]
# x: [128,128,28,28] => [128,256,14,14]
# 第二个残缺块:H2 = (14-3 +2*1) /1 +1 = 14
# [128,256,14,14] => [128,256,14,14]
# [128,256,14,14] => [128,256,14,14]
self.layer3 = self.make_layer(128, 256, 2, stride=2)
# 添加残缺块 4
# 第一个残缺块:H2 = (14 - 3 +2*1)/2 +1 = 7
# [128,256,14,14] =>[128,512,7,7]
# [128,512,7,7] => [128,512,7,7]
# X : [[128,256,14,14]] => [128,512,7,7]
# 第二个残缺块:H2 = (7-3+2*1)/1+1 =7
# [128,512,7,7] => [128,512,7,7]
# [128,512,7,7] => [128,512,7,7]
self.layer4 = self.make_layer(256, 512, 2, stride=2)
# 池化层,采用自适应池化(指定特征图的高度,宽度)
# [128,512,7,7] => [128,512,1,1]
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# 全连接层
# [128,512] => [128,176]
self.fc = nn.Linear(512, 176)
def make_layer(self, in_channels, out_channels, blocks, stride=1):
layers = []
layers.append(ResidualBlock(in_channels, out_channels, stride))
for _ in range(1, blocks):
# 这里的stride 默认为1
layers.append(ResidualBlock(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
# [128,512,1,1] => [128,512*1*1]
x = torch.flatten(x, 1)
x = self.fc(x)
return x
5、定义训练以及评估函数:
device = torch.device('cuda')
def train(model, train_loader, val_loader, criterion, optimizer, num_epochs):
for epoch in range(num_epochs):
model.train() # 设置模型为训练模式
train_loss = 0.0
correct = 0
total = 0
# 训练模型
for x, y in train_loader:
x, y = x.to(device), y.to(device)
optimizer.zero_grad() # 梯度清零
outputs = model(x) # 前向传播
loss = criterion(outputs, y) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
train_loss += loss.item() * x.size(0)
_,predicted = outputs.max(1) #这里_ 表示占位符,outputs.max(1)返回的是最大值,和最大值的索引
total += y.size(0)
correct += predicted.eq(y).sum().item()
# 计算训练集上的平均损失和准确率
train_loss = train_loss / len(train_loader.dataset)
train_acc = 100. * correct / total
# 在验证集上评估模型
val_loss, val_acc = evaluate(model, val_loader, criterion)
# 打印训练信息
print(
f'Epoch [{epoch + 1}/{num_epochs}], Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.2f}%, Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%')
def evaluate(model, val_loader, criterion):
model.eval() # 设置模型为评估模式
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad(): # 禁止梯度计算
for x, y in val_loader:
x, y = x.to(device), y.to(device)
outputs = model(x)
loss = criterion(outputs, y)
val_loss += loss.item() * x.size(0)
_, predicted = outputs.max(1)
total += y.size(0)
correct += predicted.eq(y).sum().item()
# 计算验证集上的平均损失和准确率
val_loss = val_loss / len(val_loader.dataset)
val_acc = 100. * correct / total
return val_loss, val_acc
6、开始训练:
model = Resnet18().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
num_epochs = 10
train(model,train_loader,val_loader,criterion=criterion,optimizer=optimizer,num_epochs=num_epochs)
7、输出结果:
好家伙,直接过拟合了,应该对数据进一步处理,避免过拟合。
Epoch [1/10], Train Loss: 4.0659, Train Acc: 10.37%, Val Loss: 7.2078, Val Acc: 9.92%
Epoch [2/10], Train Loss: 2.5477, Train Acc: 32.15%, Val Loss: 22.1796, Val Acc: 3.00%
Epoch [3/10], Train Loss: 1.8311, Train Acc: 47.40%, Val Loss: 10.9325, Val Acc: 6.52%
Epoch [4/10], Train Loss: 1.3895, Train Acc: 58.54%, Val Loss: 2.5158, Val Acc: 33.61%
Epoch [5/10], Train Loss: 1.0679, Train Acc: 67.53%, Val Loss: 13.1189, Val Acc: 8.95%
Epoch [6/10], Train Loss: 0.8598, Train Acc: 73.25%, Val Loss: 5.0033, Val Acc: 20.12%
Epoch [7/10], Train Loss: 0.7152, Train Acc: 77.59%, Val Loss: 1.3642, Val Acc: 59.86%
Epoch [8/10], Train Loss: 0.5771, Train Acc: 81.43%, Val Loss: 0.6216, Val Acc: 79.32%
Epoch [9/10], Train Loss: 0.5036, Train Acc: 83.70%, Val Loss: 3.3536, Val Acc: 34.62%
Epoch [10/10], Train Loss: 0.4170, Train Acc: 86.52%, Val Loss: 8.0067, Val Acc: 21.36%


![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-13-按键实验](https://img-blog.csdnimg.cn/direct/bcad413e52ca4f1e9869c1882c8541c1.png)