ByteBuffer源码阅读
ByteBuffer是一个用于处理字节数据的缓冲区类。它是Java NIO 包的一部分,提供了一种高效的方式来处理原始字节数据。
ByteBuffer可以用来读取、写入、修改和操作字节数据,它是一种直接操作字节的方式,比起传统的InputStream和OutputStream,它更加灵活和高效。
01. 阅读前准备
Buffer 一般配合另一个类 Channel 配合使用完成读写的操作,这里先来创建读取使用的 Channel 和缓冲使用的 Buffer。
FileChannel channel = new FileInputStream("data.txt").getChannel();
ByteBuffer buffer = ByteBuffer.allocate(10); // 准备缓冲区
channel.read(buffer); // 将文件的内容读取到缓冲区
02. 基本构造解析
ByteBuffer 底层维护了一个存放数据的 Byte 数组,同时使用了多个属性来配合完成写入、读取的操作,底层的大致结构是这样的:
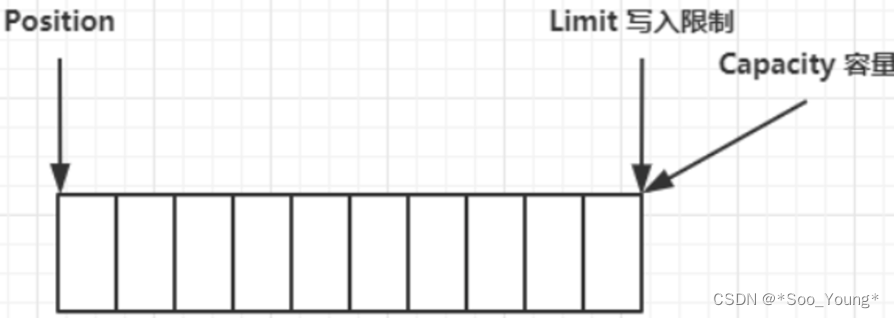
Position 是一个指向当前读或者写位置的指针(通过 filp 方法来切换读写模式)
Limit 是限制位置,根据读写模式的不同,限制的内容也不同
Capacity 就是底层数组的容量。
03. ByteBuffer 对象的构造
通过上面的案例不难看出,ByteBuffer 的获取方法并不是直接 new 的,而是调用了类中提供的静态方法 allocate(int capacity) 来构造对象,这个方法具体实现是这样的:
public static ByteBuffer allocate(int capacity) {
// 检测传入数据是否正确
if (capacity < 0)
throw new IllegalArgumentException();
// 调用 HeapByteBuffer 的构造方法
return new HeapByteBuffer(capacity, capacity);
}
ByteBuffer 是一个抽象类,而 HeapByteBuffer 是 ByteBuffer 的一个具体实现类之一,它是在堆内存中分配的 ByteBuffer。 HeapByteBuffer是通过**ByteBuffer.allocate(int capacity)**方法创建的,它将字节数据存储在Java虚拟机的堆内存中。
HeapByteBuffer(int cap, int lim) { // package-private
super(-1, 0, lim, cap, new byte[cap], 0);
/*
hb = new byte[cap];
offset = 0;
*/
}
ByteBuffer(int mark, int pos, int lim, int cap, // package-private
byte[] hb, int offset)
{
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
// 最终调用的,Buffer 抽象类中的构造方法
Buffer(int mark, int pos, int lim, int cap) { // package-private
// 检查 cap
if (cap < 0)
throw new IllegalArgumentException("Negative capacity: " + cap);
this.capacity = cap; // 设置容量
limit(lim); // 设置 limit
position(pos); // 设置 position
// 检测 mark 的值,如果 mark > position
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}
方法中调用了父类,也就是 ByteBuffer 的构造方法来构造对象,最终调用的是 Buffer 中的构造方法,其中出现了一个之前没有提到的参数**mark ,这个**参数用于设置初始标记,这个标记是一个可选的位置,它允许你在某个位置上设置一个标记,然后稍后可以通过调用 reset() 方法将位置恢复到这个标记处;这样就能理解上面的检测 mark 的值,这个值是不应该放到 position 的后面的,因为它代表的含义是回退。
所以在初始化的时候一般是将其设置为 -1,也就是约定的未设置值的状态,在 Buffer 抽象类中也是这样定义的:
// Invariants: mark <= position <= limit <= capacity
private int mark = -1;
将文件中的内容读取到 Buffer 需要调用 Channel 中的 read(ByteBuffer dst) 方法,下面来看一下方法具体的实现,因为本文是 Buffer 的源码解析,所以将重点聚焦在 Buffer 类上,关于 Channel 以注释的方式说明:
public int read(ByteBuffer dst) throws IOException {
// 检测 Channel 是否开启,若未开启会抛出 ClosedChannelException 异常
ensureOpen();
// 检测文件权限,如果不可读,抛出 NonReadableChannelException 异常
if (!readable)
throw new NonReadableChannelException();
// 锁,类型为 Object
synchronized (positionLock) {
int n = 0; // 用于存储实际读取的字节数目
int ti = -1; // 用于存储当前线程的标识符
try {
begin();
ti = threads.add();
// 再次检测 Channel 是否开启
if (!isOpen())
return 0;
// 执行读取的操作
do {
n = IOUtil.read(fd, dst, -1, nd);
} while ((n == IOStatus.INTERRUPTED) && isOpen());
// 返回读取的字节数
return IOStatus.normalize(n);
} finally {
threads.remove(ti);
end(n > 0);
assert IOStatus.check(n);
}
}
}
04. 将 Channel 中的内容读取到 Buffer
其中最重要的方法就是 IOUtil 类的静态 read 方法,来看一下它的具体实现:
static int read(FileDescriptor fd, ByteBuffer dst, long position,
NativeDispatcher nd)
throws IOException
{
// 检查 ByteBuffer 是否为只读的
if (dst.isReadOnly())
throw new IllegalArgumentException("Read-only buffer");
// 检查是否为直接缓冲区
if (dst instanceof DirectBuffer)
return readIntoNativeBuffer(fd, dst, position, nd);
// 创建一个临时的直接缓冲区,大小为 dst 的剩余大小
ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining());
try {
// 将数据读取到临时的直接缓冲区
int n = readIntoNativeBuffer(fd, bb, position, nd);
bb.flip();
if (n > 0)
dst.put(bb); // 将数据放入传入的 Buffer 中
return n;
} finally {
// 释放临时直接缓冲区
Util.offerFirstTemporaryDirectBuffer(bb);
}
}
// 计算剩余大小的方法
public final int remaining() {
int rem = limit - position;
return rem > 0 ? rem : 0;
}
上面的方法将数据读取到直接缓冲区中,直接缓冲区的优势是在于其数据存储在堆外(off-heap memory)而不是堆内存中。这种特性使得直接缓冲区在进行I/O操作时能够更有效地与操作系统进行交互,从而提高了I/O操作的性能和效率。
上面方法使用了 put 方法将存储在直接缓冲区的内容读取到了传入的 Buffer 中:
public ByteBuffer put(ByteBuffer src) {
// 如果是传入的类型堆缓冲区,可以通过数组拷贝的方式复制
if (src instanceof HeapByteBuffer) {
// 自己读取自己
if (src == this)
throw new IllegalArgumentException();
HeapByteBuffer sb = (HeapByteBuffer)src;
int pos = position();
int sbpos = sb.position();
// 源 Buffer 中内容大于当前 Buffer 的剩余容量
int n = sb.limit() - sbpos;
if (n > limit() - pos)
throw new BufferOverflowException();
// 数组拷贝复制
System.arraycopy(sb.hb, sb.ix(sbpos),
hb, ix(pos), n);
sb.position(sbpos + n);
position(pos + n);
// 传入的类型是直接缓冲区
} else if (src.isDirect()) {
int n = src.remaining(); // 源 Buffer 的内容容量
int pos = position(); // 写指针
// 源 Buffer 中内容大于当前 Buffer 的剩余容量
if (n > limit() - pos)
throw new BufferOverflowException();
// 该方法的作用是从当前 ByteBuffer 中读取数据,
// 并将其存储到指定的字节数组 dst 中的指定位置 offset 开始的 length 个位置中。
src.get(hb, ix(pos), n);
position(pos + n);
} else {
super.put(src);
}
return this;
}
这样就完成了将直接缓冲区中的内容复制到新的 Buffer 中。
总结一下,read 方法的原理就是将文件中的内容读取到更有效与系统进行 IO 交互的直接缓冲区中,然后将直接缓冲区中的内容复制到传入的堆缓冲区中。
05. flip 转换方法
为什么在读取和写入数据之前需要调用
flip()方法来转换模式呢?上面我们提到,Buffer 的读取和存储都依赖指针进行的,flip 方法实质上就是对指针进行操作来实现模式的转换的。
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
无论是读模式还是写模式的转换,position 都是位于 0 的位置,也就是读取也要从头开始读,写也要从头开始写(覆盖,后面提到的 compact 方法可以将未读的内容保留下来)
limit 即或者写的限制,如果是从读模式转到写模式,将 limit 设置为 position,也就是最后写入的位置,但是当从读取切换到写入模式的时候,因为 limit 会直接切换成 position 的值,所以有可能会导致写入量大于 limit 而抛出 BufferOverflowException 异常,比如下面的操作:
public class ByteBufferFlipTest {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(10);
buffer.flip(); // 切换到读模式
buffer.flip(); // 切换到写模式
buffer.put((byte) 1);
}
}
运行后就会这样:
Exception in thread "main" java.nio.BufferOverflowException
at java.nio.Buffer.nextPutIndex(Buffer.java:525)
at java.nio.HeapByteBuffer.put(HeapByteBuffer.java:173)
at org.example.ByteBufferFlipTest.main(ByteBufferFlipTest.java:10)
所以切换的时候一定要注意避免这种情况,因为对 Buffer 的操作比较底层,需要根据合理的设计来实现需求,比如当我们明确的知道读取的是多少字节的时候,可以通过 Buffer 类提供的
limit(int newLimit) 方法来设置限制的值。
06. compact() 保留未读内容的切换方法
上面提到,如果使用 filp 方法来转换读取的模式,实质上是不会保留未读取的内容的,这里要将的 compact 方法则会保留未读取的内容,下面来看一下具体的实现。
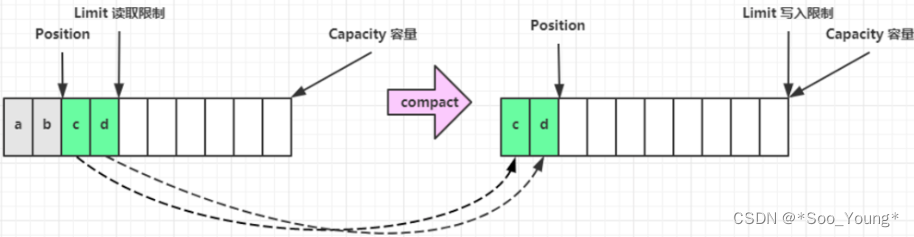
public ByteBuffer compact() {
int pos = position(); // 获取 position
int lim = limit(); // 获取 limit(读限制)
assert (pos <= lim); // 断言
int rem = (pos <= lim ? lim - pos : 0); // 剩余未读的内容
// 从 hb 中读取从 pos 长度为 rem 的内容到 hb 从 0 开始长度为 rem 中
System.arraycopy(hb, ix(pos), hb, ix(0), rem);
position(rem); // 设置新的指针(写指针)
limit(capacity()); // 将 limit 设置为容量
discardMark(); // 将 mark 设置为 -1
return this;
}
方法中使用 void arraycopy(Object src, int srcPos, Object dest, int destPos, int length); 方法将未读取的内容保留到 byte 数组中,实现了上面图片中的效果。
07. put 方法和 clear 方法
通过上面的阅读,再来看两个比较轻松的方法,put 方法用于将 byte 存入 Buffer 中,clear 用于将 Buffer 重置到初始状态。
public ByteBuffer put(byte x) {
hb[ix(nextPutIndex())] = x; // 获取下一个存放数据的位置
return this;
}
final int nextPutIndex() {
int p = position;
if (p >= limit)
throw new BufferOverflowException();
position = p + 1; // 自增操作
return p;
}
protected int ix(int i) {
return i + offset;
}
put 中使用到的 ix 方法是 ByteBuffer 类中的一个受保护的辅助方法,用于计算指定索引位置在底层数组中的实际位置;offset 是一个成员变量,表示底层数组中的偏移量。
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
clear 方法则是将指针直接重置到初始位置(数据并未删除)







![[渗透利器]某大佬公开自用红队渗透工具](https://img-blog.csdnimg.cn/img_convert/14ef6e451886efc67e2988a0e73c7834.png)

![[ 项目 ] tcmalloc简化版—高并发内存池](https://img-blog.csdnimg.cn/direct/0ad5d1a5f91f44b2b227ddef3abd3f95.png)