本文来源公众号“GiantPandaCV”,仅用于学术分享,侵权删,干货满满。
原文链接:FasterTransformer Decoding 源码分析(三)-LayerNorm介绍
作者丨进击的Killua
来源丨https://zhuanlan.zhihu.com/p/669440844
编辑丨GiantPandaCV
GiantPandaCV | FasterTransformer Decoding 源码分析(一)-整体框架介绍-CSDN博客
GiantPandaCV | FasterTransformer Decoding 源码分析(二)-Decoder框架介绍-CSDN博客
本文是FasterTransformer Decoding 源码分析的第三篇,主要介绍FasterTransformer中LayerNorm是如何实现及优化的。首先会简单介绍下LayerNorm的背景知识,然后从源码上逐层向下分析具体的实现。
1 背景知识
Layer normalization(层归一化)是一种用于深度神经网络中的归一化技术。它可以对网络中的每个神经元的输出进行归一化,使得网络中每一层的输出都具有相似的分布,目前已被广泛应用于深度学习模型的各个子模块中。LayerNorm的计算很简单,它计算的粒度体现在每一组数据本身上,每组数据之间毫无关系,所以非常适合并行来计算。如下图所示,图中一个batch有3组数据,每组数据分别计算平均值和标准差,再用均值和标准差去处理每组数据中元素即可,公式为如下所示。公式中的gamma和beta为可学习参数,增强数据的可表达性。严格描述和定义可参考文档。
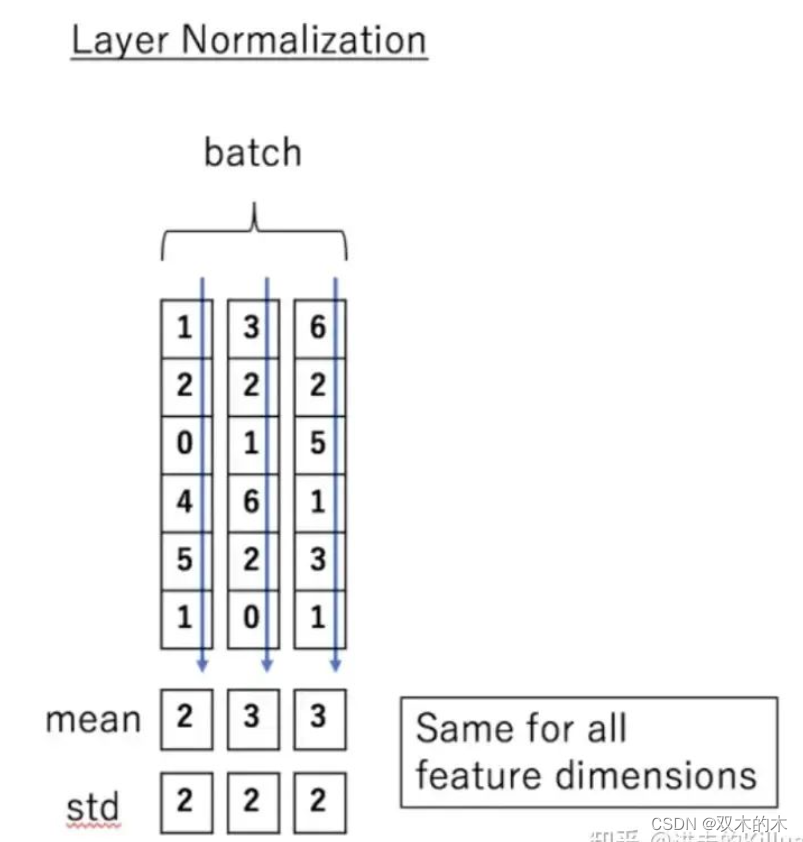
LayerNorm举例

LayerNorm 计算公式
2 源码分析
2.1 方法入口
Decoding实现中最普通的LayerNorm方法调用入口如下所示,出了输入输出的数据描述外就是公式中罗列的gamma、beta和eps参数,这里还是比较好理解的。
invokeGeneralLayerNorm(decoder_normed_input_, // layernorm输出
decoder_input, // layernorm输入
decoder_layer_weight->at(l).pre_layernorm_weights.gamma,
decoder_layer_weight->at(l).pre_layernorm_weights.beta,
layernorm_eps_,
batch_size, // 一个批次处理的数据个数
hidden_units_, // 单个数据样本的维度
(float*)nullptr,
0,
stream_);2.2 调用kernel
入口调用的函数签名如下,opt_version默认是2,int8_mode是量化模式,这里先跳过。
template<typename T>
void invokeGeneralLayerNorm(T* out,
const T* input,
const T* gamma,
const T* beta,
const float layernorm_eps,
const int m, // 一个批次处理的数据个数
const int n, // 单个数据样本的维度
float* scale,
float* dynamic_scale,
const int int8_mode,
cudaStream_t stream,
int opt_version)函数的实现上有一些设计,针对数据维度是偶数且类型是半精度浮点型(half)的数据样本,采用了定制化的kernel实现,这个kernel和后续要讲的联合kernel复用一套底层代码。这里大概说下优化点,就是会对2个half类型的元素处理进行代码展开,减少指令判断加速运行,后续介绍联合算子的时候再详细介绍。
{
dim3 grid(m);
const bool dynamic_quant = dynamic_scale != nullptr;
if (n % 2 == 0 && (std::is_same<T, half>::value)
&& opt_version > 0) {
int half_n = n / 2;
int half_n_32 = (half_n + 31) / 32 * 32;
dim3 block(min(half_n_32, 512));
int rolls_per_thread = half_n / block.x;
int unroll_factor = 8;
while (unroll_factor > rolls_per_thread && unroll_factor > 1) {
unroll_factor /= 2;
}
using T2 = typename TypeConverter<T>::Type;
/* we launch (and instantiate) the kernel by specializing for unroll_factor -> residual_num -> is_bias ->
* opt_version */
dispatch_generalAddBiasResidualLayerNormOpt_unroll_factor((T2*)out,
(T2*)out,
(const T2*)out,
(const T2*)nullptr,
(const T2*)input,
(const T2*)nullptr,
(const T2*)gamma,
(const T2*)beta,
layernorm_eps,
m,
half_n,
nullptr,
nullptr,
scale,
dynamic_scale,
int8_mode,
grid,
block,
stream,
opt_version,
false, // is_output
1, // residual_num
unroll_factor);
}
对于其他比较常规的数据类型,会调用generalLayerNorm kernel函数来进行处理。这里gridSize等于一批处理的数据个数,即一个block处理输入的一份数据,对这一份数据进行normalize即可,符合并行处理的思路。blockSize是一份数据的维度和1024的较小值,可以理解,大多数CUDA设备一个block支持的最大线程数就是1024,所以这里要min处理下。这里还有个trick就是维度如果不是32的倍数就也设置为1024,主要是为了最大化利用warp(32个线程)特性来处理数据。动态量化的部分我们先跳过,接下来就是调用函数进入到kernel实现部分。
else {
dim3 block(min(n, 1024));
/* For general cases, n is equal to hidden_units, e.g., 512/1024.
Since we have warp shuffle inside the code, block.x % 32 should be 0.
*/
if (n % 32 != 0) {
block.x = 1024;
}
/* should pay attention to the rsqrt precision*/
if (dynamic_quant) {
size_t maxbytes = n * sizeof(T);
if (maxbytes >= (48 << 10)) {
check_cuda_error(cudaFuncSetAttribute(
generalLayerNorm<T, true>, cudaFuncAttributeMaxDynamicSharedMemorySize, maxbytes));
}
generalLayerNorm<T, true><<<grid, block, maxbytes, stream>>>(
input, gamma, beta, out, layernorm_eps, m, n, scale, dynamic_scale, int8_mode); // For gpt-3
}
else {
generalLayerNorm<T, false><<<grid, block, 0, stream>>>(
input, gamma, beta, out, layernorm_eps, m, n, scale, dynamic_scale, int8_mode); // For gpt-3
}
}
}2.3 kernel实现
这里为了代码结构更加清晰先将量化相关的代码先去掉了,整个流程还是比较容易理解,通过两次block级别的归约实现了下面公式的计算,具体在代码中做了详细注释。

一个block处理一个数据(n维度),block中有m个线程,1个线程可能处理1到多个数据中的元素,如下图所示。这里n=8,m=4,所以一个线程需要处理2个数据,反映到代码中就是单个线程对2个元素进行本地求和和差值平方。

block实现逻辑
template<typename T, bool DYNAMIC_SCALING = false>
__global__ void generalLayerNorm(const T* __restrict input,
const T* __restrict gamma,
const T* __restrict beta,
T* normed_output,
const float layernorm_eps,
int m,
int n,
float* scale,
float* dynamic_scale,
const int int8_mode)
{
const int tid = threadIdx.x;
// 共享内存,存储block内求得的均值mean、方差
__shared__ float s_mean;
__shared__ float s_variance;
float mean = 0.0f;
float variance = 0.0f;
// 该循环将本线程要处理的若干个输入数据元素进行本地求和
float local_sum = 0.0f;
for (int i = tid; i < n; i += blockDim.x) {
// ldg函数用于从全局内存中按照给定的地址加载数据,并且该函数能够利用缓存来提高访问效率
local_sum += (float)(ldg(&input[blockIdx.x * n + i]));
}
// 进行block级别归约,即将本block中所有线程计算的local_sum进行求和,得到这个数据样本所有元素的和
mean = blockReduceSum(local_sum);
// 通过0号线程进行取平均
if (threadIdx.x == 0) {
s_mean = mean / n;
}
// 在block内进行同步,确保所有线程都拿到s_mean
__syncthreads();
// 该循环将本线程要处理的元素进行差值平方求和
float local_var_sum = 0.0f;
for (int i = tid; i < n; i += blockDim.x) {
float diff = (float)(ldg(&input[blockIdx.x * n + i])) - s_mean;
local_var_sum += diff * diff;
}
// 进行block级别归约,即将本block中所有线程计算的差值平方进行求和,得到这个数据样本所有元素的方差
variance = blockReduceSum(local_var_sum);
// 通过0号线程对方差进行运算
if (threadIdx.x == 0) {
s_variance = rsqrtf(variance / n + layernorm_eps);
}
// 在block内进行同步,确保所有线程都拿到s_variance
__syncthreads();
Scalar_T abs_max = 1e-6f;
// 该循环利用均值和方差对本线程要处理的元素进行normalize,并输出到normed_output中
for (int i = tid; i < n; i += blockDim.x) {
const int index = blockIdx.x * n + i;
float beta_val = (beta == nullptr) ? 0.0f : (float)ldg(&beta[i]);
T val = (T)((((float)input[index] - s_mean) * s_variance) * (float)(ldg(&gamma[i])) + beta_val);
normed_output[index] = val;
}
}下面这个就是block维度归约求和的实现,利用了两次warp维度归约求和来实现,这个实现还是比较经典和常用的,值得参考借鉴。
warp归约求和的实现
-
__shfl_xor_sync(FINAL_MASK, val, mask, 32):这是 warp 内的异或操作,通过每个线程与邻近线程的值进行异或,得到不同的值,本质上就是要获得移位后的元素内容。 -
val = add(val, __shfl_xor_sync(FINAL_MASK, val, mask, 32)):将每个线程的值与邻近线程异或的结果累加到当前线程的值上,最终得到 warp 内的和。
即整个循环通过不断地将 mask 右移,实现了 warp 内的规约操作,下图可清晰表明这个流程,还可以阅读这篇文章了解更详细的线程束洗牌指令的归约使用 jhang:CUDA编程入门之Warp-Level Primitives。
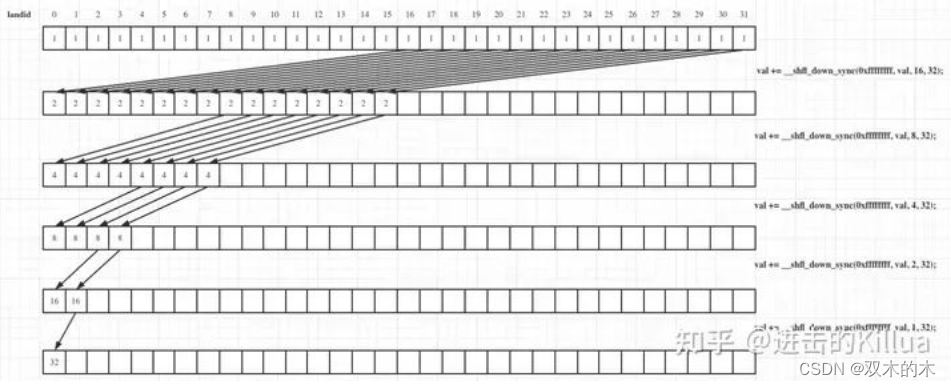
#define FINAL_MASK 0xffffffff
template<typename T>
__inline__ __device__ T warpReduceSum(T val)
{
#pragma unroll
for (int mask = 16; mask > 0; mask >>= 1)
val = add(val, __shfl_xor_sync(FINAL_MASK, val, mask, 32)); //__shfl_sync bf16 return float when sm < 80
return val;
}block归约求和的实现
有了warp级别的归约之后,block级别的归约先对每个warp都进行求和,通过每个warp中的0号线程把warp内求和的结果存到共享内存中,共享内存的大小是32(一个block最多有1024个线程,而warp大小是32个线程,一个block最多有32个warp,所以这里共享内存大小设置为32可覆盖所有warp),然后再对这个共享内存中存储的32个结果再进行一次warp归约求和,最终得到block级别的最终结果。
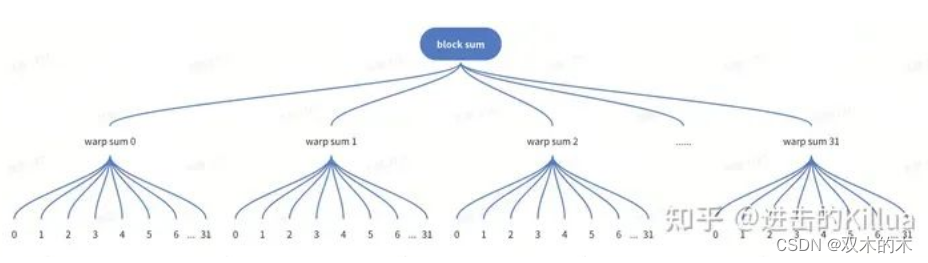
block 归约求和数据流
template<typename T>
__inline__ __device__ T blockReduceSum(T val)
{
// 32个元素即可
static __shared__ T shared[32];
// thread在warp中的index
int lane = threadIdx.x & 0x1f;
// warp在block的index
int wid = threadIdx.x >> 5;
val = warpReduceSum<T>(val);
if (lane == 0)
shared[wid] = val;
__syncthreads();
// Modify from blockDim.x << 5 to blockDim.x / 32. to prevent
// blockDim.x is not divided by 32
// 针对线程数不足的情况,对val进行赋值0,不影响最终结果。
val = (threadIdx.x < (blockDim.x / 32.f)) ? shared[lane] : (T)(0.0f);
val = warpReduceSum<T>(val);
return val;
}
3 总结
本文总结了FasterTransformer中的General LayerNorm实现,主要是CUDA开发中比较基础的共享内存、block归约和warp归约的一些应用,非常基础,没有用到太多华丽的技巧。OneFlow之前也出了一篇关于LayerNorm的优化实现,个人觉得比FasterTransformer中的实现优化力度还要更大一些,可以参考OneFlow:CUDA优化之LayerNorm性能优化实践学习(CUDA优化之LayerNorm性能优化实践 - 知乎 (zhihu.com))。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。