前言
keys 可以一次性把 Redis 中的所有 key 都获取到,但这个操作比较危险,一次性获取所有的key 很容易会导致 Redis 阻塞。
而通过渐进式遍历(不是一个命令就将所有的 key 值拿到,而是每执行一次命令只获取其中的一小部分,这样就能保证当前的操作不会太卡,而想获得所有的 key 值就要重复执行多次命令)就能做到在获取到所有 key 的同时也不会阻塞 Redis 服务器,
SCAN
以渐进式的⽅式进⾏键的遍历
语法
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
时间复杂度:O(1)
返回值:下⼀次 scan 的游标(cursor)以及本次得到的键。
游标和下标是完全不一样的,Redis 可以通过游标找到下次遍历对应的位置,但游标的含义只有 Redis 知道,程序员/客户端是不知道的
注意:⾸次 scan 从 0 开始,当 scan 返回的下次位置为 0 时,遍历结束
MATCH pattern 选项表示进行字符串匹配,与 keys 作用相同
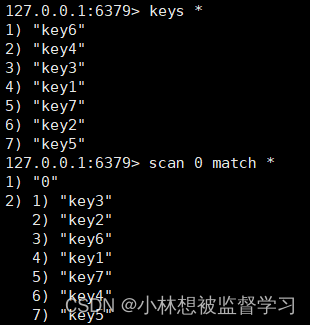
COUNT count 选项限制要获取多少个 key
注意此处的 count 和 MySQL 的 limit 不一样,limit 是精确的获取一个区间内的数据,而此处的 count 仅仅是对 Redis 的一个建议,实际返回的个数和指定的 count 可能不一致,但区别不会很大
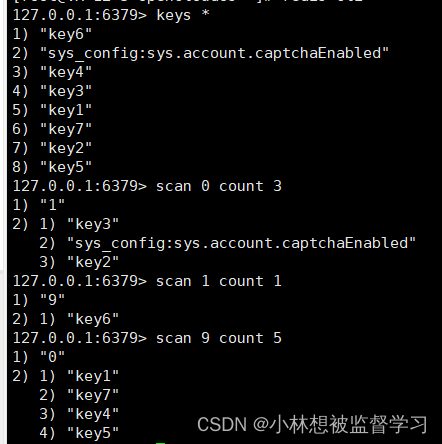
TYPE type 选项限制键值对 value 的类型(但Redis 版本较低可能没有该选项)
注意:
渐进性遍历 scan 虽然解决了阻塞的问题,但如果在遍历期间键有所变化(增加、修改、删 除),可能导致遍历时键的重复遍历或者遗漏,这点务必在实际开发中考虑(实际上在很多地方都很忌惮一边遍历,一边修改,比如 Java,c++ 等)
除了 scan 以外,Redis ⾯向哈希类型、集合类型、有序集合类型分别提供了 hscan、sscan、zscan 命 令,它们的⽤法和 scan 基本类似,感兴趣的读者可以⾃⾏做扩展学习。