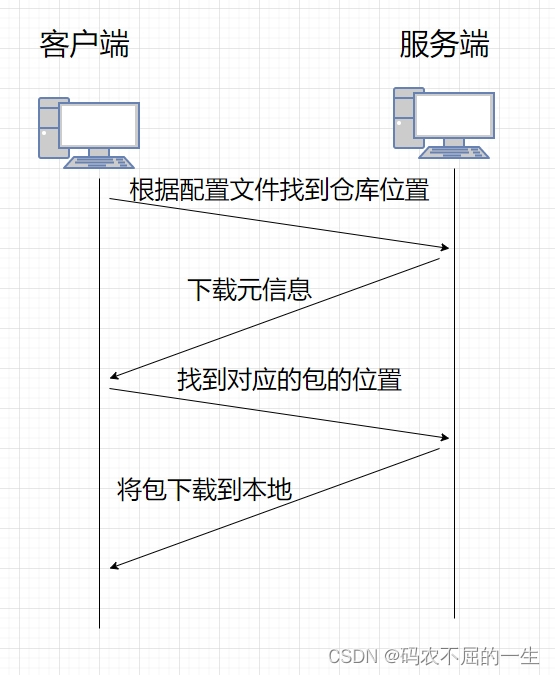
关联式容器
在初阶阶段,我们已经接触过STL中的部分容器,比如:vector、list、deque、
forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面
存储的是元素本身。那什么是关联式容器?它与序列式容器有什么区别?
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是
<key, value>
结构的
键值对,在数据检索时比序列式容器效率更高

键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量
key
和
value
,
key
代
表键值,
value
表示与
key
对应的信息
。比如:现在要建立一个英汉互译的字典,那该字典中必然
有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应
该单词,在词典中就可以找到与其对应的中文含义。
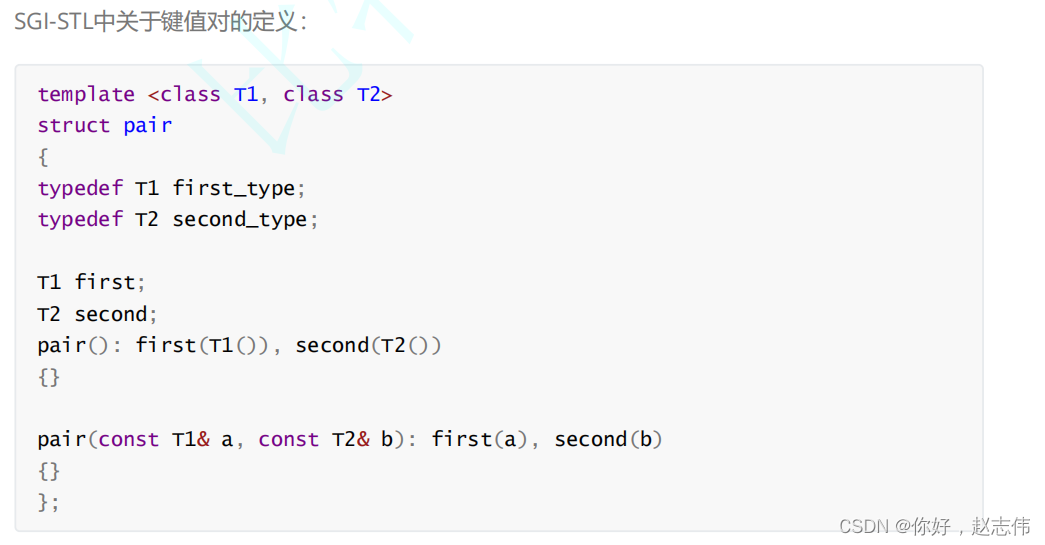
树形结构的关联式容器
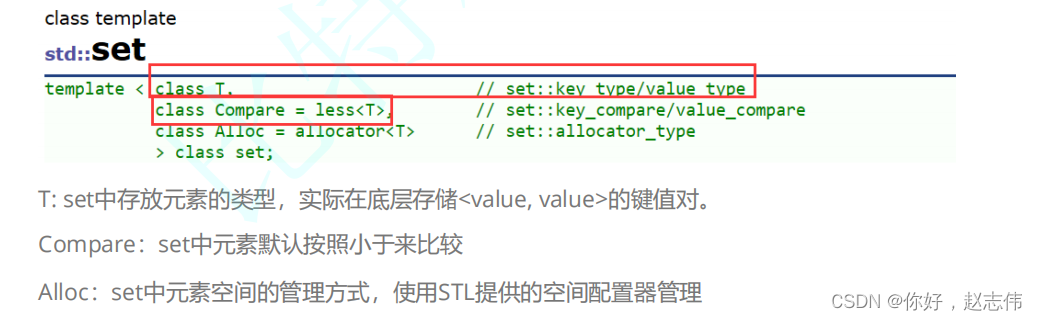
根据应用场景的不桶,STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结 构的关联式容器主要有四种:map、set、multimap、multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列.下面一依次介绍每一个容器
set
1. set是按照一定次序存储元素的容器
2. 在set中,元素的value也标识它(value就是key,类型为T),并且每个
value必须是唯一的
。
set中的元素
不能在容器中修改
(元素总是const),但是可以从容器中插入或删除它们。
3. 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行
排序。
4. set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对
子集进行直接迭代。
5. set在底层是用二叉搜索树(红黑树)实现的。
注意:
1. 与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放
value,但在底层实际存放的是由<value, value>构成的键值对。
2. set中插入元素时,只需要插入value即可,不需要构造键值对。
3. set中的元素不可以重复(因此可以使用set进行去重)。
4. 使用set的迭代器遍历set中的元素,可以得到有序序列
5. set中的元素默认按照小于来比较
6. set中查找某个元素,时间复杂度为:
7. set中的元素不允许修改(为什么?)
8. set中的底层使用二叉搜索树(红黑树)来实现
set的使用
set
的构造
|
函数声明
|
功能介绍
|
|
set (const Compare& comp = Compare(), const Allocator&
= Allocator() );
|
构造空的
set
|
|
set (InputIterator first, InputIterator last, const
Compare& comp = Compare(), const Allocator& =
Allocator() );
|
用
[first, last)
区
间中的元素构造
set
|
|
set ( const set<Key,Compare,Allocator>& x);
|
set
的拷贝构造
|
set
的迭代器
|
函数声明
|
功能介绍
|
|
iterator begin()
|
返回
set
中起始位置元素的迭代器
|
|
iterator end()
|
返回
set
中最后一个元素后面的迭代器
|
|
const_iterator cbegin()
const
|
返回
set
中起始位置元素的
const
迭代器
|
|
const_iterator cend() const
|
返回
set
中最后一个元素后面的
const
迭代器
|
|
reverse_iterator rbegin()
|
返回
set
第一个元素的反向迭代器,即
end
|
|
reverse_iterator rend()
|
返回
set
最后一个元素下一个位置的反向迭代器,
即
begin
|
|
const_reverse_iterator
crbegin()const
|
返回
set
第一个元素的反向
const
迭代器,即
cend
|
|
const_reverse_iterator
crend() const
|
返回
set
最后一个元素下一个位置的反向
const
迭
代器,即
cbegin
|
set
的容量
|
函数声明
|
功能介绍
|
|
bool empty ( ) const
|
检测
set
是否为空,空返回
true
,否则返回
true
|
|
size_type size() const
|
返回
set
中有效元素的个数
|
set
修改操作
|
函数声明
|
功能介绍
|
|
pair<iterator,bool> insert (
const value_type& x )
|
在
set
中插入元素
x
,实际插入的是
<x, x>
构成的
键值对,如果插入成功,返回
<
该元素在
set
中的
位置,
true>,
如果插入失败,说明
x
在
set
中已经
存在,返回
<x
在
set
中的位置,
false>
|
|
void erase ( iterator position )
|
删除
set
中
position
位置上的元素
|
|
size_type erase ( const
key_type& x )
|
删除
set
中值为
x
的元素,返回删除的元素的个数
|
|
void erase ( iterator first,
iterator last )
|
删除
set
中
[first, last)
区间中的元素
|
|
void swap (
set<Key,Compare,Allocator>&
st );
|
交换
set
中的元素
|
|
void clear ( )
|
将
set
中的元素清空
|
|
iterator find ( const
key_type& x ) const
|
返回
set
中值为
x
的元素的位置
|
|
size_type count ( const
key_type& x ) const
|
返回
set
中值为
x
的元素的个数
|
补充:
lower_bound
iterator lower_bound (const value_type& val);
const_iterator lower_bound (const value_type& val) const;
该函数将返回一个指向不小于val的第一个元素的迭代器
upper_bound
iterator upper_bound (const value_type& val);
const_iterator upper_bound (const value_type& val) const;
该函数将返回一个指向大于val的第一个元素的迭代器
multiset
1. multiset是按照特定顺序存储元素的容器,其中元素是可以重复的。
2. 在multiset中,元素的value也会识别它(因为multiset中本身存储的就是<value, value>组成
的键值对,因此value本身就是key,key就是value,类型为T). multiset元素的值不能在容器
中进行修改(因为元素总是const的),但可以从容器中插入或删除。
3. 在内部,multiset中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则
进行排序。
4. multiset容器通过key访问单个元素的速度通常比unordered_multiset容器慢,但当使用迭
代器遍历时会得到一个有序序列。
5. multiset底层结构为二叉搜索树(红黑树)。
注意:
1. multiset中再底层中存储的是
<value, value>
的键值对
2. mtltiset的插入接口中只需要插入即可
3. 与set的区别是,multiset中的元素可以重复,set中value是唯一的
4. 使用迭代器对multiset中的元素进行遍历,可以得到有序的序列
5. multiset
中的
元素不能修改
6.
在
multiset
中找某个元素,时间复杂度为
7. multiset
的作用:可以对元素进行排序
#include <set>
void TestSet()
{
int array[] = { 2, 1, 3, 9, 6, 0, 5, 8, 4, 7 };
// 注意:multiset在底层实际存储的是<int, int>的键值对
multiset<int> s(array, array + sizeof(array)/sizeof(array[0]));
for (auto& e : s)
cout << e << " ";
cout << endl;
return 0;
}
map
1. map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元
素。
2. 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的
内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型
value_type绑定在一起,为其取别名称为pair:
typedef pair<const key, T> value_type;
3. 在内部,map中的元素总是按照键值key进行比较排序的。
4. map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序
对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
5. map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
6. map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。


map的使用
|
函数声明
|
功能介绍
|
|
map()
|
构造一个空的
map
|
| map(const map &x) | 拷贝构造 |
map的迭代器
|
函数声明
|
功能介绍
|
|
begin()
和
end()
|
begin:
首元素的位置,
end
最后一个元素的下一个位置
|
|
cbegin()
和
cend()
|
与
begin
和
end
意义相同,但
cbegin
和
cend
所指向的元素不
能修改
|
|
rbegin()
和
rend()
|
反向迭代器,
rbegin
在
end
位置,
rend
在
begin
位置,其
++
和
--
操作与
begin
和
end
操作移动相反
|
|
crbegin()
和
crend()
|
与
rbegin
和
rend
位置相同,操作相同,但
crbegin
和
crend
所
指向的元素不能修改
|
map
的容量与元素访问
|
函数声明
|
功能简介
|
|
bool empty ( ) const
|
检测
map
中的元素是否为空,是返回
true
,否则返回
false
|
|
size_type size() const
|
返回
map
中有效元素的个数
|
|
mapped_type& operator[ ] (const
key_type& k)
|
返回
key
对应的
value
|
问题:当key不在map中时,通过operator获取对应value时会发生什么问题?

注意:在元素访问时,有一个与
operator[]
类似的操作
at()(
该函数不常用
)
函数,都是通过
key
找到与
key
对应的
value
然后返回其引用,不同的是:
当
key
不存在时,
operator[]用默认
value与key构造键值对然后插入,返回该默认value
,
at()
函数直接抛异常
。

//pair<K,V>
V& operator[](const K& key)
{
// 不管插入成功还是失败,pair中iterator始终指向key所在节点的iterator
pair<iterator, bool> ret = insert(make_pair(key, V()));
iterator it = ret.fisrt;
return it->second;
}key存在,插入失败 返回 --> pair<存在的key所在节点的迭代器,false>key不存在,插入成功 返回 --> pair<新插入key所在节点的迭代器,true>
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉","苹果","草莓", "苹果","草莓" };
map<string, int> countMap;
for (auto& e : arr)
{
countMap[e]++;
//auto it = countMap.find(e);
//if (it != countMap.end())
//{
// it->second++;
//}
//else
//{
// //const pair<string, int>& val = { e, 1 };
// countMap.insert({ e, 1 });
//}
}
for (auto& kv : countMap)
{
cout << kv.first << ":" << kv.second << endl;
}
cout << endl;
map
中元素的修改
|
函数声明
|
功能简介
|
|
pair<iterator,bool> insert (
const value_type& x )
|
在
map
中插入键值对
x
,注意
x
是一个键值
对,返回值也是键值对:
iterator
代表新插入
元素的位置,
bool
代表释放插入成功
|
|
void erase ( iterator position )
|
删除
position
位置上的元素
|
|
size_type erase ( const
key_type& x )
|
删除键值为
x
的元素
|
|
void erase ( iterator first,
iterator last )
|
删除
[first, last)
区间中的元素
|
|
void swap (
map<Key,T,Compare,Allocator>&
mp )
|
交换两个
map
中的元素
|
|
void clear ( )
|
将
map
中的元素清空
|
|
iterator find ( const key_type& x
)
|
在
map
中插入
key
为
x
的元素,找到返回该元
素的位置的迭代器,否则返回
end
|
|
const_iterator find ( const
key_type& x ) const
|
在
map
中插入
key
为
x
的元素,找到返回该元
素的位置的
const
迭代器,否则返回
cend
|
|
size_type count ( const
key_type& x ) const
|
返回
key
为
x
的键值在
map
中的个数,注意
map
中
key
是唯一的,因此该函数的返回值
要么为
0
,要么为
1
,因此也可以用该函数来
检测一个
key
是否在
map
中
|
map<string, string> dict;
pair<string, string> kv1("sort", "排序");
dict.insert(kv1);
dict.insert(pair<string, string>("left", "左边"));
dict.insert(make_pair("right", "右边"));
dict.insert(make_pair("right", "xxxx"));
// 隐式类型转换
//pair<string, string> kv2 = { "string", "字符串" };
dict.insert({ "string", "字符串" });
//map<string, string>::iterator it = dict.begin();
auto it = dict.begin();
while (it != dict.end())
{
// iterator key不能修改 value可以修改
// const_iterator key不能修改 value不能修改
//it->first += 'x';
it->second += 'x';
//cout << (*it).first << ":" << (*it).second << endl;
cout << it->first << ":" << it->second << endl;
//cout << it.operator->()->first << ":" << it.operator->()->second << endl;
++it;
}
cout << endl;
for (auto& kv : dict)
{
//auto& [x, y] = kv;
cout << kv.first << ":" << kv.second << endl;
}
cout << endl;
/*for (auto& [x, y] : dict)
{
cout << x << ":" << y << endl;
}
cout << endl;*/
//map<string, string> dict2 = { {"string", "字符串"}, {"left", "左边"},{"right", "右边"} };
map<string, string> dict2 = { kv1, {"left", "左边"},{"right", "右边"} };#include <string>
#include <map>
void TestMap()
{
map<string, string> m;
// 向map中插入元素的方式:
// 将键值对<"peach","桃子">插入map中,用pair直接来构造键值对
m.insert(pair<string, string>("peach", "桃子"));
// 将键值对<"peach","桃子">插入map中,用make_pair函数来构造键值对
m.insert(make_pair("banan", "香蕉"));
// 借用operator[]向map中插入元素
/*
operator[]的原理是:
用<key, T()>构造一个键值对,然后调用insert()函数将该键值对插入到map中
如果key已经存在,插入失败,insert函数返回该key所在位置的迭代器
如果key不存在,插入成功,insert函数返回新插入元素所在位置的迭代器
operator[]函数最后将insert返回值键值对中的value返回
*/
// 将<"apple", "">插入map中,插入成功,返回value的引用,将“苹果”赋值给该引用结果,
m["apple"] = "苹果";
// key不存在时抛异常
//m.at("waterme") = "水蜜桃";
cout << m.size() << endl;
// 用迭代器去遍历map中的元素,可以得到一个按照key排序的序列
for (auto& e : m)
cout << e.first << "--->" << e.second << endl;
cout << endl;
// map中的键值对key一定是唯一的,如果key存在将插入失败
auto ret = m.insert(make_pair("peach", "桃色"));
if (ret.second)
cout << "<peach, 桃色>不在map中, 已经插入" << endl;
else
cout << "键值为peach的元素已经存在:" << ret.first->first << "--->"
<< ret.first->second <<" 插入失败"<< endl;
// 删除key为"apple"的元素
m.erase("apple");
if (1 == m.count("apple"))
cout << "apple还在" << endl;
else
cout << "apple被吃了" << endl;
}【总结】1. map中的的元素是键值对2. map中的key是唯一的,并且不能修改3. 默认按照小于的方式对key进行比较4. map中的元素如果用迭代器去遍历,可以得到一个有序的序列5. map的底层为平衡搜索树(红黑树),查找效率比较高$O(log_2 N)$6. 支持[]操作符,operator[]中实际进行插入查找。
multimap
1. Multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对<key,value>,其中多个键值对之间的 key是可以重复的 。2. 在multimap中,通常按照key排序和惟一地标识元素,而映射的value存储与key关联的内容。key和value的类型可能不同,通过multimap内部的成员类型value_type组合在一起,value_type是组合key和value的键值对: typedef pair<const Key, T> value_type;3. 在内部,multimap中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对key进行排序的。4. multimap通过key访问单个元素的速度通常比unordered_multimap容器慢,但是使用迭代 器直接遍历multimap中的元素可以得到关于key有序的序列。5. multimap在底层用二叉搜索树(红黑树)来实现。
注意:multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以
重复的。
- multimap中的key是可以重复的。
- multimap中的元素默认将key按照小于来比较
- 使用时与map包含的头文件相同
相关例题
两个数组的交集I
给定两个数组
输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
nums1 和
nums2 ,返回
它们的
交集
输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。

class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
// 先去重
set<int> s1(nums1.begin(),nums1.end());
set<int> s2(nums2.begin(),nums2.end());
// set排过序,依次比较,小的一定不是交集,相等的是交集
auto it1 = s1.begin();
auto it2 = s2.begin();
vector<int> ret;
while(it1 != s1.end() && it2 != s2.end())
{
if(*it1 < *it2)
{
it1++;
}
else if(*it2 < *it1)
{
it2++;
}
else
{
ret.push_back(*it1);
it1++;
it2++;
}
}
return ret;
}
};
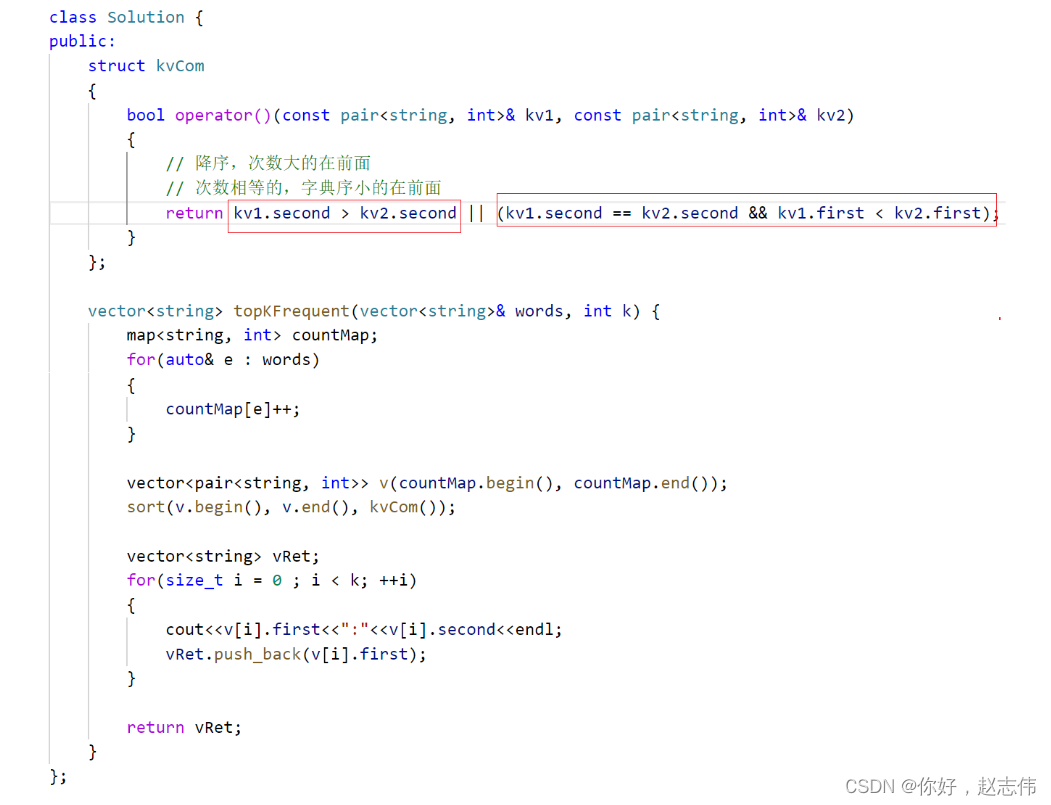
前K个高频单词
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。




![[力扣题解]102.二叉树的层序遍历](https://img-blog.csdnimg.cn/direct/d7964db06551417b81720b617de34a1b.png#pic_center)