目录
5.1 Single Shot MultiBox Detector(SSD)
5.2 YOLO
5.2.1 v1
5.2.2 v2
5.2.3 v3
5.2.4 v4
5.2.5 v5 【后续出详细面试考点,订阅我的专栏,更新第一时间通知】
已更新: 百面算法工程师 | YOLOv5面试考点原理全解析-CSDN博客
5.2.6 v6
5.2.7 v7
5.2.8 v8 【后续出详细面试考点,订阅我的专栏,更新第一时间通知】
5.2.9 v9
5.3 NMS
5.4 Anchor
5.4.1 Anchor based
5.4.2 Anchor free
5.5 类别不均衡
5.6 anchor free FCOS
5.7 YOLOX
标题有超链接的,是对应网络的论文地址

欢迎大家订阅我的专栏一起学习共同进步
祝大家早日拿到offer! let's go
🚀🚀🚀http://t.csdnimg.cn/dfcH3🚀🚀🚀
Two stage : R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN和R-FCN
one stage: OverFeat、YOLOv1、YOLOv2、YOLOv3、SSD和RetinaNet
- anchor based:
- yolov3, yolov4, yolov5, yolov6, yolov7
- anchor free:
- FCOS, yolov8
5.1 Single Shot MultiBox Detector(SSD)
创新点
(1)基于Faster R-CNN的Anchor机制,提出了先验框(Prior box)
(2)从不同比例的特征图(多尺度特征)中产生不同比例的预测,并明确地按长宽比分离预测。
SSD在多个特征图上设置不同缩放比例和不同宽高比的先验框以融合多尺度特征图进行检测,大尺度特征图可以检测小物体信息,小尺度特征图能捕捉大物体信息,从而提高检测的准确性和定位的准确性。
不同于Faster R-CNN只在最后一个特征层取anchor, SSD在多个特征层上取default box,可以得到不同尺度的default box。在特征图的每个单元上取不同宽高比的default box,一般宽高比在{1,2,3,1/2,1/3}中选取,有时还会额外增加一个宽高比为1但具有特殊尺度的box。如下图所示,在8x8的feature map和4x4的feature map上的每个单元取4个不同的default box。

先验框匹配准则 【正负样本匹配】
(1)对图片中的每个ground truth, 在先验框中找到与其IOU最大的先验框,则该先验框对应的预测边界框与ground truth 匹配。
(2)对于(1)中每个剩下的没有与任何ground truth匹配到的先验框,找到与其IOU最大的ground truth,若其与该ground truth的IOU值大于某个阈值(一般设为0.5),则该先验框对应的预测边界框与该ground truth匹配。
按照这两个原则进行匹配,匹配到ground truth的先验框对应的预测边界框作为正样本,没有匹配到ground truth的先验框对应的预测边界框作为负样本。尽管一个ground truth可以与多个先验框匹配,但是ground truth的数量相对先验框还是很少,按照上面的原则进行匹配还是会造成负样本远多于正样本的情况。为了使正负样本尽量均衡(一般保证正负样本比例约为1:3),SSD采用hard negative mining, 即对负样本按照其预测背景类的置信度进行降序排列,选取置信度较小的top-k作为训练的负样本。
5.2 YOLO
5.2.1 v1
创新点
将整张图作为网络的输入,Anchor free方法直接在输出层回归bounding box的位置和类别
anchor based 缺点:FCOS论文总结
- 检测器的性能和Anchor的size以及aspect ratio相关,比如在RetinaNet中改变Anchor(论文中说这是个超参数hyper-parameters)能够产生约4%的AP变化。换句话说,Anchor要设置的合适才行。
- 一般Anchor的size和aspect ratio都是固定的,所以很难处理那些形状变化很大的目标(比如一本书横着放w远大于h,竖着放h远大于w,斜着放w可能等于h,很难设计出合适的Anchor)。而且迁移到其他任务中时,如果新的数据集目标和预训练数据集中的目标形状差异很大,一般需要重新设计Anchor。(kmeans)【比如书本竖着放和斜着放还有平着放它的anchor大小就不同】
- 为了达到更高的召回率(查全率),一般需要在图片中生成非常密集的Anchor Boxes尽可能保证每个目标都会有Anchor Boxes和它相交。比如说在FPN(Feature Pyramid Network)中会生成超过18万个Anchor Boxes(以输入图片最小边长800为例),那么在训练时绝大部分的Anchor Boxes都会被分为负样本,这样会导致正负样本极度不均。
- Anchor的引入使得网络在训练过程中更加的繁琐,因为匹配正负样本时需要计算每个Anchor Boxes和每个GT BBoxes之间的IoU。
预测
YOLO将输入图像分成7x7的网格,每个网格预测2个边界框,总共 49x2=98 个bounding box。若某物体的ground truth的中心落在该网格,则该网格中与这个ground truth IOU最大的边界框负责预测该物体。
对每个边界框预测5个值,分别是边界框的中心x,y(相对于所属网格的边界),边界框的宽高w,h(相对于原始输入图像的宽高的比例),以及这些边界框的confidence scores(边界框与ground truth box的IOU值)。同时每个网格还需要预测c个类条件概率 (是一个c维向量,表示某个物体object在这个网格中,且该object分别属于各个类别的概率,这里的c类物体不包含背景)。论文中的c=20,则每个网格需要预测2x5+20=30个值,这些值被映射到一个30维的向量。
5.2.2 v2
YOLOv2相对v1版本,在继续保持处理速度的基础上,从预测更准确(Better),速度更快(Faster),识别对象更多(Stronger)这三个方面进行了改进
创新点有如下:
(1)Batch Normalization:在每个卷积层后加Batch Normalization(BN)层,去掉dropout。
(2)High Resolution:YOLOv2将输入图片的分辨率提升至448x448。
(3)Convolutional With Anchor Boxes:使用Anchor Boxes预测边界框
(4)Dimension Clusters:采用k-means聚类算法对训练集中的边界框做了聚类分析,选用boxes之间的IOU值作为聚类指标。
(5)New Network,Darknet-19:19个卷积层和5个max pooling层的新Backbone。
(6)Direct location prediction:对预测框的偏移量进行约束
(7)Fine-Grained Features:提出pass through层将高分辨率的特征图与低分辨率的特征图联系在一起,从而实现多尺度检测。
(8)Multi-Scale Training:YOLOv2采用多尺度输入的方式训练,在训练过程中每隔10个batches,重新随机选择输入图片的尺寸,由于Darknet-19下采样总步长为32,输入图片的尺寸一般选择32的倍数{320,352,…,608}。
5.2.3 v3
创新点:
backbone部分由Yolov2时期的Darknet-19进化至Darknet-53,加深了网络层数,引入了Resnet中的跨层加和操作。
Yolov3借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。
针对anchor box采用聚类的方法获取合适的尺寸。
5.2.4 v4
创新点:
使用了新的Backbone: CSDarknet50。
为了增大感受野,YOLOv4使用了SPP-block(金字塔池化)
改进SAM,改进PAN,和交叉小批量标准化(CmBN),使YOLOv4的设计适合于有效的训练和检测
Mosaic数据增强
使用IOU损失代替原始xywh位置损失,其他的采用交叉熵损失函数。
加权残差连接、跨阶段部分连接、DropBlock正则化、Mish激活等。
5.2.5 v5 【后续出详细面试考点,订阅我的专栏,更新第一时间通知】
百面算法工程师 | YOLOv5面试考点原理全解析-CSDN博客
5.2.6 v6
【后续可能出详细流程,提前订阅我的专栏,更新第一时间通知】
5.2.7 v7
5.2.8 v8 【后续出详细面试考点,订阅我的专栏,更新第一时间通知】
5.2.9 v9
5.3 NMS
- 根据置信度得分进行排序
- 选择置信度最高的边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU。
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空。
Code
import numpy as np
import torch
def nms(boxes, score, conf_thres, iou_thres, classes, agnostic = True):
tf = score[:] > conf_thres
score = score[tf]
keep = []
idx = np.argsort(score)[::-1] # start:stop:step
if agnostic:
pred = torch.hstack((boxes,classes))
offset = pred[:,4:5] * 4096
boxes = pred[:,0:4] + offset
# print(boxes)
while len(idx) > 0:
keep.append(idx[0])
overlap = np.zeros_like(idx[1:], dtype= np.float32)
for i, j in enumerate(idx[1:]):
bbox1 = boxes[idx[0]]
bbox2 = boxes[j]
out = iou(bbox1, bbox2)
overlap[i] = out
idx = idx[1:][overlap < iou_thres]
# return keep
# box = []
# for i in keep:
# box.append(boxes[i])
# return box
return keep, boxes[keep]
def iou(bbox1,bbox2):
x1, y1, x2, y2 = bbox1 # left_top right_bottom
x3, y3, x4, y4 = bbox2
if (x1 <= (x3 + x4) /2 <= x2 ) or (y1 <= (y3 + y4) /2 <= y2):
left_top_x = max(x1, x3)
left_top_y = max(y1, y3)
right_bottom_x = min(x2, x4)
right_bottom_y = min(y2, y4)
i = (right_bottom_x - left_top_x) * (right_bottom_y - left_top_y)
o = (x2 - x1) * (y2 - y1) + (x4 - x3) * (y4 - y3) - i
IoU = i / o
return IoU
else:
return 0 # 不相交
if __name__ == '__main__':
boxes = torch.Tensor([
[100, 100, 200, 200],
[120, 110, 220, 210],
[300, 320, 400, 400],
[180, 100, 300, 180]
])
scores = np.array([0.9, 0.8, 0.7, 0.6])
classes = torch.Tensor([[0],[1],[1],[2]])
# np.concatenate 先转置 可以拼接
out = nms(boxes=boxes, score=scores, conf_thres=0.5, iou_thres=0.25, classes=classes)
print(out)5.4 Anchor
5.4.1 Anchor based
anchor通俗来讲就是先验框。首先预设一组不同尺度不同位置的固定参考框,覆盖几乎所有位置和尺度,每个参考框负责检测与其交并比大于阈值 (训练预设值,常用0.5或0.7) 的目标,anchor技术将问题转换为"这个固定参考框中有没有认识的目标,目标框偏离参考框多远",不再需要多尺度遍历滑窗,真正实现了又好又快
优点 【缺点见5.2.1】
使用anchor机制产生密集的anchor box,使得网络可直接在此基础上进行目标分类及边界框坐标回归。加入先验,训练稳定
密集的anchor box可有效提高网络目标召回能力,对于小目标检测来说提升非常明显。
5.4.2 Anchor free
优点
更大更灵活的解空间、摆脱了使用anchor而带来计算量从而让检测和分割都进一步走向实时高精度
缺点
正负样本极端不平衡
语义模糊性(两个目标中心点重叠)
检测结果不稳定,需要设计更多的方法来进行re-weight
5.5 类别不均衡
负样本的数量极大于正样本的数量,比如包含物体的区域(正样本)很少,而不包含物体的区域(负样本)很多。比如检测算法在早期会生成许多bbox。而一幅常规的图片中,object占少数。这意味着绝大多数的bbox属于background。
由于大多数都是简单易分的负样本(属于背景的样本),使得训练过程不能充分学习到属于那些有类别样本的信息;其次简单易分的负样本太多,可能掩盖了其他有类别样本的作用(这些简单易分的负样本仍产生一定幅度的loss,数量多会对loss起主要贡献作用,因此就主导了梯度的更新方向,掩盖了重要的信息)
为什么二阶段网络不会出现类别不均衡问题
因为通过RPN阶段可以减少候选目标区域,而在分类阶段,可以固定前景与背景比值(foreground-to-background ratio)为1:3,或者使用OHEM(online hard example mining)使得前景和背景的数量达到均衡。
5.6 anchor free FCOS 【以下内容参考B站up主霹雳吧啦wz】
FCOS https://arxiv.org/abs/1904.01355 https://arxiv.org/abs/2006.09214
现今有关Anchor-Free的网络也很多,比如DenseBox、YOLO v1、CornerNet、FCOS以及CenterNet,YOLOX等等,而FCOS它不仅是Anchor-Free还是One-Stage,FCN-base detector
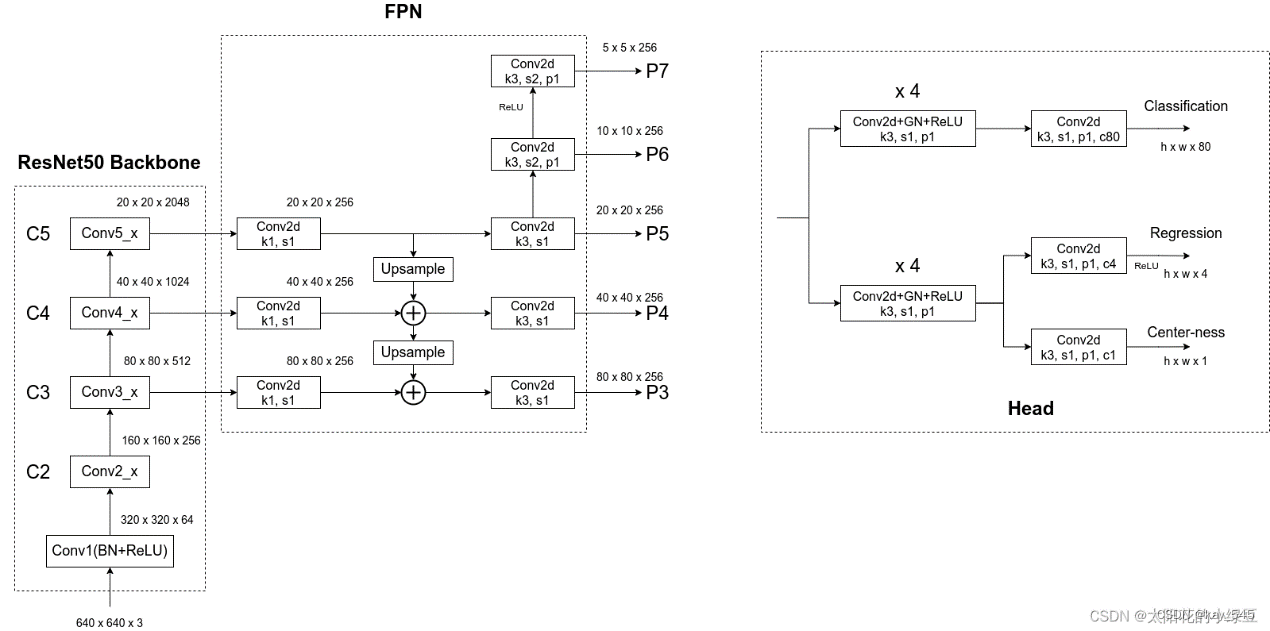
对于Classification分支,在预测特征图的每个位置上都会预测80个score参数(MS COCO数据集目标检测任务的类别数为80)。
对于Regression分支,在预测特征图的每个位置上都会预测4个距离参数(距离目标左侧距离l,上侧距离t,右侧距离r以及下侧距离b,注意,这里预测的数值是相对特征图尺度上的)。假设对于预测特征图上某个点映射回原图的坐标是( c x , c y ) (c_x, c_y)(c x ,c y),特征图相对原图的步距是s,那么网络预测该点对应的目标边界框坐标为

对于Center-ness分支,在预测特征图的每个位置上都会预测1个参数,center-ness反映的是该点(特征图上的某一点)距离目标中心的远近程度,它的值域在0~1之间,距离目标中心越近center-ness越接近于1,下面是center-ness真实标签的计算公式
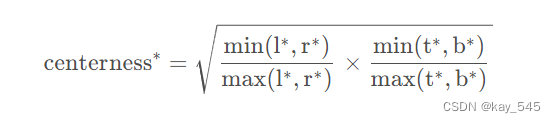
Anchor free 正负样本匹配
Specifically, location (x, y) is considered as a positive sample if it falls into the center area of any ground-truth box, by following [42]. The center area of a box centered at (cx , cy ) is defined as the sub-box (cx − rs, cy − rs, cx + rs, cy + rs) , where s is the total stride until the current feature maps and r is a hyper-parameter being 1.5 on COCO. The sub-box is clipped so that it is not beyond the original box. Note that this is different from our original conference version, where we consider the locations positive as long as they are in a ground-truth box.
最开始的一句话是说,对于特征图上的某一点( x , y ) (x,y)(x,y),只要它落入GT box中心区域,那么它就被视为正样本(其实在2019年的文章中,最开始说的是只要落入GT内就算正样本)。对应的参考文献[42]就是2019年发表的FCOS版本。但在2020年发表的FCOS版本中,新加了一条规则,在满足以上条件外,还需要满足点( x , y ) (x,y)(x,y)在( c x − r s , c y − r s , c x + r s , c y + r s ) (c_x - rs, c_y - rs, c_x + rs, c_y + rs)(cx−rs,cy−rs,cx+rs,cy+rs)这个sub-box范围内,其中( c x , c y ) (cx, cy)(cx,cy)是GT的中心点,s是特征图相对原图的步距,r是一个超参数控制距离GT中心的远近,在COCO数据集中r设置为1.5,关于r的消融实验可以看2020版论文的表6。换句话说点( x , y ) (x,y)(x,y)不仅要在GT的范围内,还要离GT的中心点( c x , c y ) (c_x, c_y)(cx,cy)足够近才能被视为正样本。
如果feature map上的某个点同时落入两个GT Box内(即两个GT Box相交区域),那该点到底分配给哪个GT Box,【FPN能够减少这种情况】
5.7 YOLOX
主要的差别就在检测头head部分。之前的检测头就是通过一个卷积核大小为1x1的卷积层实现的,即这个卷积层要同时预测类别分数、边界框回归参数以及object ness(耦合头),这种方式在文章中称之为coupled detection head(耦合的检测头)。作者说采用coupled detection head是对网络有害的,如果将coupled detection head换成decoupled detection head(解耦的检测头)【分开预测cls,bbox,obj】能够大幅提升网络的收敛速度。
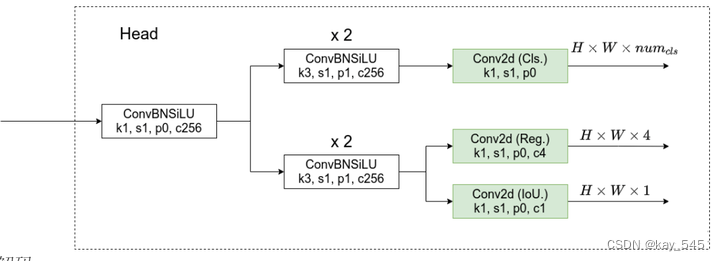
解码:
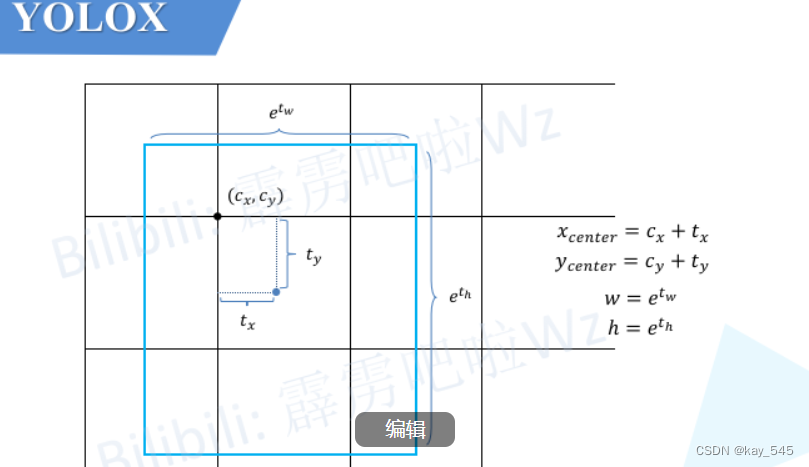
注意这些值都是相对预测特征图尺度上的,如果要映射回原图需要乘上当前特征图相对原图的步距stride
正负样本匹配SimOTA[最优传输成本] 最小化cost可以理解为让网络以最小的学习成本学习到有用的知识