文章目录
- 论文精读-存内计算芯片研究进展及应用
- 概述
- 背景介绍
- 前人工作
- 存内计算
- 3.1 SRAM存内计算
- 3.2 DRAM存内计算
- 3.3 ReRAM/PCM存内计算
- 3.4 MRAM存内计算
- 3.5 NOR Flash存内计算
- 3.6 基于其他介质的存内计算
- 3.7 存内计算芯片
- 应用场景
- 总结
- QA
论文精读-存内计算芯片研究进展及应用
优点:
1、详细总结了存内计算的发展
概述
随着数据快速增长,冯诺依曼架构内存墙成为计算性能进一步提升的关键瓶颈。新型存算一体架构(包 括存内计算(IMC)架构与近存计算(NMC)架构),有望打破冯诺依曼架构瓶颈,大幅提高算力和能效。该文介绍了 存算一体芯片的发展历程、研究现状以及基于各类存储器介质(如传统存储器DRAM, SRAM和Flash和新型非易 失性存储器ReRAM, PCM, MRAM, FeFET等)的存内计算基本原理、优势与面临的问题。然后,以知存科技 WTM2101量产芯片为例,重点介绍了存算一体芯片的电路结构与应用现状。最后,分析了存算一体芯片未来的 发展前景与面临的挑战。
背景介绍
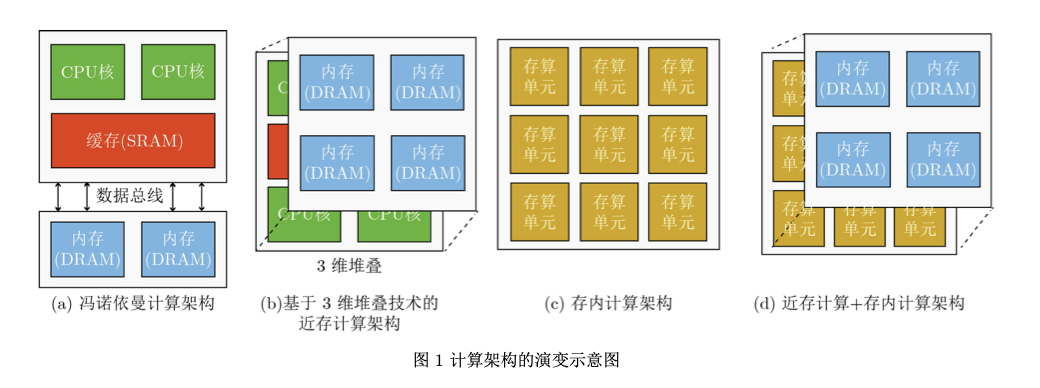
自2012年起, 全世界每天产生的数据量约为2.5×1018 Byte,且该 体量仍然以每40个月翻倍的速度在持续增长[1]。海 量数据的高效存储、迁移与处理成为当前信息领域的重大挑战。然而,由于冯诺依曼架构的局限性[2], 数据的高效处理遇到了存储墙和功耗墙两大问题。 在冯诺依曼架构中,数据存储与处理是分离的,存 储器与处理器之间通过数据总线进行数据传输,如 图1(a)所示。
一方面,存储器的访问速度远远小于 处理器的运算速度,系统整体会受到传输带宽的限 制,导致处理器的实际算力远低于理论算力,难以 满足大数据应用的快、准响应需求,称为存储墙问 题。通过增加数据总线带宽或者时钟频率可以在一 定程度上提高处理器性能,但必将带来更大的功耗 与硬件成本开销,且其扩展性也严重受限。(but,我感觉,这里主要是带宽墙,茶壶里倒饺子,目前内存的频率已经很快了,而且现在内存都是直连cpu。不过似乎大多数地方没有将存储墙与带宽墙分开,因为这两个一般是伴生关系。存储墙不仅考虑数据访问,还考虑数据存储容量和功耗)
另一方 面,冯诺依曼架构的存储与计算分离,数据在存储 器与处理器之间的频繁迁移带来巨大的传输功耗,称为功耗墙瓶颈。例如,英伟达的研究报告指出, 在22 nm工艺节点下,浮点运算所需的数据传输功 耗是数据处理功耗的约200倍[3,4]。
上述存储墙与功 耗墙问题并称为冯诺依曼架构瓶颈为了缓解冯诺依曼架构瓶颈,目前产业界采用 的主流方案是通过高速接口、光互联、3维堆叠、 增加片上缓存等方法来提高数据带宽,并把存储器 和处理器之间的数据传输距离缩短,以减小功耗。 其中,产业界应用较多的是3维堆叠技术与增加片 上缓存等方法。以3维堆叠技术[5,6]为例,其基本思 想就是把更多的存储器通过在垂直方向上的堆叠, 提高数据带宽,并缩短两者之间的距离,这在本质 上称为近存计算架构[7,8],如图1(b)所示。但是, 3维堆叠技术并没有改变冯诺依曼架构,只能在一 定程度上缓解,但并不能从根本上解决冯诺依曼架 构瓶颈。存内计算,作为一种新型计算架构,直接 利用存储器本身进行数据处理,从根本上消除数据搬运,实现存储与计算融合一体化,有望突破冯诺 依曼架构存储墙与功耗墙瓶颈,成为后摩尔时代集 成电路领域的重点研究方向之一,如图1©所示。 近年来,基于先进2.5D/3D封装技术,结合近存计 算和存内计算的新型架构得到业界的重点关注,有 望从存储与计算两方面进一步优化性能,如图1(d)所示。
前人工作
存算一体包括近存计算与存内计算,其概念最 早在1969年被提出[9,10],后续各国学者在电路、算 法、计算架构、操作系统、系统应用等层面开展了 一系列相关研究。例如,1997年,文献[11]展示了 一种智能内存(Intelligent RAM)方案,其将处理器 和DRAM集成在单颗芯片上,算力可达到当时最 先进的Cray向量处理器(Cray T-90)的5倍。1999 年,文献[12]提出了一种嵌入计算功能的灵活内存 (FlexRAM)方案,仿真结果表明该芯片架构可使计算性能提升25~40倍。但是,早期由于缺少大数据 处理的应用需求,加之芯片的制造成本昂贵、设计 复杂,存算一体技术多年来仅停留在研究阶段。
2015年以来,由于摩尔定律的逐渐失效与冯诺 依曼架构的局限性越来越明显,加之大数据应用的 驱动,工艺水平的不断提高,存算一体技术重新受 到关注,并成为研究热潮。例如,在2017年微处理 器顶级年会(Micro2017)上,众多高校和企业都推 出了他们的存算一体芯片或系统原型[13–15],包括苏 黎世联邦理工学院、加利福尼亚大学圣巴巴拉分 校、英伟达、英特尔、微软、三星等。2019年,文 献[16]提出的SRAM存算一体芯片可实现二值权重 的神经网络卷积计算。2020年,文献[17]展示了一 款ReRAM存算一体芯片,在降低计算延迟的同时 大幅提升能效。2021年,文献[18]提出三值DRAM 存算一体架构实现神经网络运算加速。2022年,文 献[19]提出了多芯粒的存算一体集成芯片。文献[20–24] 基于SRAM/ReRAM发表了一系列存算一体器件、 芯片与系统相关的研究成果。迄今,基于SRAM, DRAM, Flash, ReRAM, PCM, FeFET, MRAM等 各类存储介质,涌现出了一系列相关研究工作[25–38], 存算一体芯片研究百花齐放,如图2所示。特别 地,2021-2022年,被誉为芯片领域奥林匹克的顶 级国际会议ISSCC收录了存算一体相关论文20余 篇,研究单位包括三星、台积电、麻省理工学院、 普林斯顿大学、清华大学、北京大学、复旦大学、 中国科学院大学等国际顶尖高校和企业。
虽然基于各类存储介质的存算一体芯片研究百 花齐放,但是各自在大规模产业化之前都仍然面临 一些问题和挑战。
更具体地,
1、SRAM工艺成熟,且 微缩性好;但是属于易失性存储器(掉电数据丢 失),且单元面积较大,成本较高,难以通过较低 成本实现大规模、大算力存内计算芯片。
2、DRAM 工艺成熟,且单元面积较小;但同属易失性存储器,需定期刷新,且存在漏电问题,难以实现高精 度存内计算芯片,近年来被广泛应用于近存计算。
3、ReRAM属于非易失性存储器,且能够实现大规模 交叉点阵列,是未来实现存内计算芯片的潜力介质 之一;但是目前的工艺尚不成熟,存储单元的多比 特精度较低(低于8 bit),且一致性/鲁棒性较差。
4、PCM属于非易失性存储器,且能够实现大规模交 叉点阵列;但是功耗较大,速度较慢,耐久性较 差。
5、FeFET可实现非易失性存储,且能实现交叉 点阵列;但是目前的工艺也尚不成熟。
6、MRAM是 非易失性存储器,具有高耐久性、高速度、低功耗 等优点,工艺相对较成熟,扩展性较好,但是器件 的阻值(约几千欧姆)与高低阻值比率(约250%)相对 较小,在实现多比特存内计算芯片方面具有一定挑 战。
7、Flash是非易失性存储器,掉电数据不丢失, 且工艺成熟,成本低,已实现量产芯片(如Myth- ic的M1076,知存科技的WTM2101),但在微缩性 方面存在一定挑战;
存内计算
由于计算范式和存储介质的不同,存内计算芯片可以有不同的分类方法。
根据计算范式的不同, 主要分为模拟式和数字式两种。模拟式存内计算是 指存储单元内部或阵列周边的信号以模拟信号的方 式进行操作,数字式存内计算是指在实际运算过程 中,存储单元内部或阵列周边的信号以数字信号的 方式进行操作。其中,诸多的研究工作同时包含了 模拟和数字两种运算方式。
同时,根据存储介质的 不同,存内计算芯片可分为基于传统存储器和基于 新型非易失性存储器两种。传统存储器包括SRAM, DRAM和Flash等;新型非易失性存储器包括ReRAM, PCM, FeFET, MRAM等。其中,距离产业化较近 的是基于NOR Flash和基于SRAM的存内计算芯片。
3.1 SRAM存内计算
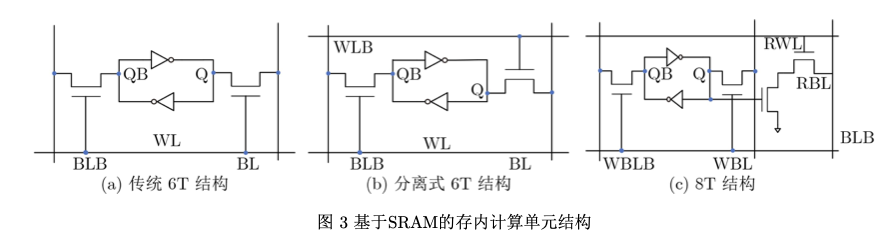
基于SRAM的存内计算芯片以典型的6T(6- Transistor)基本单元为基础,如图3(a)所示。由于 SRAM是二值存储器,二值乘累加运算等效于同或 累加运算,可以用于二值神经网络运算,其核心思 想是网络权重存储于SRAM单元中,激励信号从字 线给入,最终利用外围电路实现同或累加运算,结 果通过计数器或模拟电流/电压输出。如果要实现 多比特精度运算,通常需要多个单元进行拼接,这 不可避免地会带来面积开销。对6T基本单元的一 个简单修改是将字线进行拆分,如图3(b)所示。此 外,为了解决读写干扰问题,可以采用8T基本单元, 但明显增加了布局面积,如图3©所示。基于SRAM 的存内计算技术由于其工艺成熟度与良好的微缩 性,受到业界的高度关注,近几年的ISSCC会议上 连续报道了多篇相关论文。例如2021年,存内计算共有两个分论坛,共收录8篇论文,其中5篇是 SRAM存内计算芯片。在2022年的ISSCC中,北京 大学提出了一种基于动态逻辑且无模数转换器的 SRAM存内计算芯片[42]。
SRAM存内计算技术的主 要应用难点是在保证运算精度的前提下,实现高算 力和小面积。
3.2 DRAM存内计算
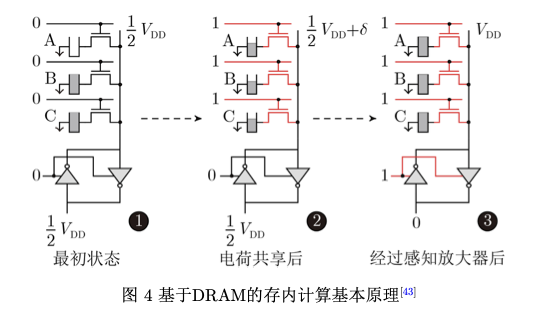
基于DRAM的存内计算芯片层次结构可分为阵列、子阵列和单元,一组阵列由若干子阵列和用 于读写操作的相关外围电路组成,而子阵列则包含 若干行1T1C(1-Transistor-1-Capacitor)单元、感知 放大器和本地解码器。其基本原理是利用DRAM 单元之间的电荷共享机制[13,43]。如图4所示为一种 典型实现方案[43],当多行单元同时被选通时,不同 单元之间因为存储数据的不同会产生电荷交换共享, 从而实现逻辑运算。
DRAM存内计算方案的主要难点:
一是其本身为易失性存储器,计算操作 会破坏数据,需要每次运算后进行刷新,带来功耗
二是实现大阵列运算时难以保证运算精度。
3.3 ReRAM/PCM存内计算
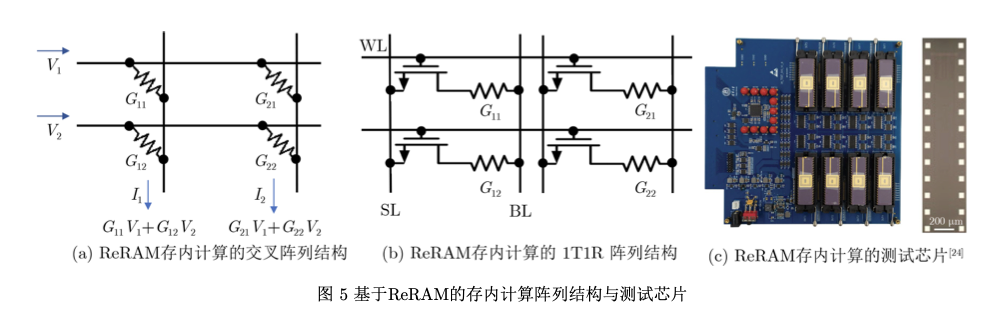
ReRAM/PCM存内计算的基本原理是利用存 储单元的模拟多比特特性,通过基于电流/电压的 欧姆定律与基尔霍夫定律进行矩阵乘加运算,主要 有1T1R (1-transistor-1-resistance)结构和交叉阵列 结构两种实现方案,如图5(a)和图5(b)所示。
ReRAM 能够实现大规模交叉点阵列,使其成为学术界的热 点研究方向。自2008年ReRAM首次实验发现以 来,基于ReRAM的存内计算研究就层出不穷。尤其2020年,清华大学研发出基于多个ReRAM阵列 的存内计算系统,该系统在手写数字集上的识别准 确率达到96.19%,与软件的识别准确率相当,证明 了存内计算架构全硬件实现的可行性,其测试芯片 如图5©所示[24]。ReRAM存内计算技术未来具有 非常大的应用潜力,目前的主要难点在于工艺尚不 太成熟,多比特精度实现较困难,一致性/鲁棒性 较差。
3.4 MRAM存内计算
MRAM存内计算主要有两种技术方案:
(1) 基于读/写操作的数字式存内计算;
(2) 基于基尔霍夫 电流定律和欧姆定律的模拟式存内计算。
早期的 MRAM存内计算大多基于数字式方案,如2015年 日本东北大学提出基于读操作实现多种布尔逻辑并 流片验证,获得了48.3%的能效提升[44];
2019年, 北京航空航天大学提出基于单次写操作的数字式MRAM 存内计算方案,实现计算结果原位存储的同时降低 了延时和功耗 [45–47]。基于MRAM的模拟式存内计 算的难点在于器件的阻值(约几千欧姆)与高低阻值 比率(约250%)相对较小,难以实现多比特精度。近 年来,得益于计算范式、器件、电路的多层次创新 突破,MRAM模拟存内计算发展迅速。
2021年, 美国普林斯顿大学通过电路级优化,流片验证了第 一款基于STT-MRAM的模拟存内计算硬核[48];
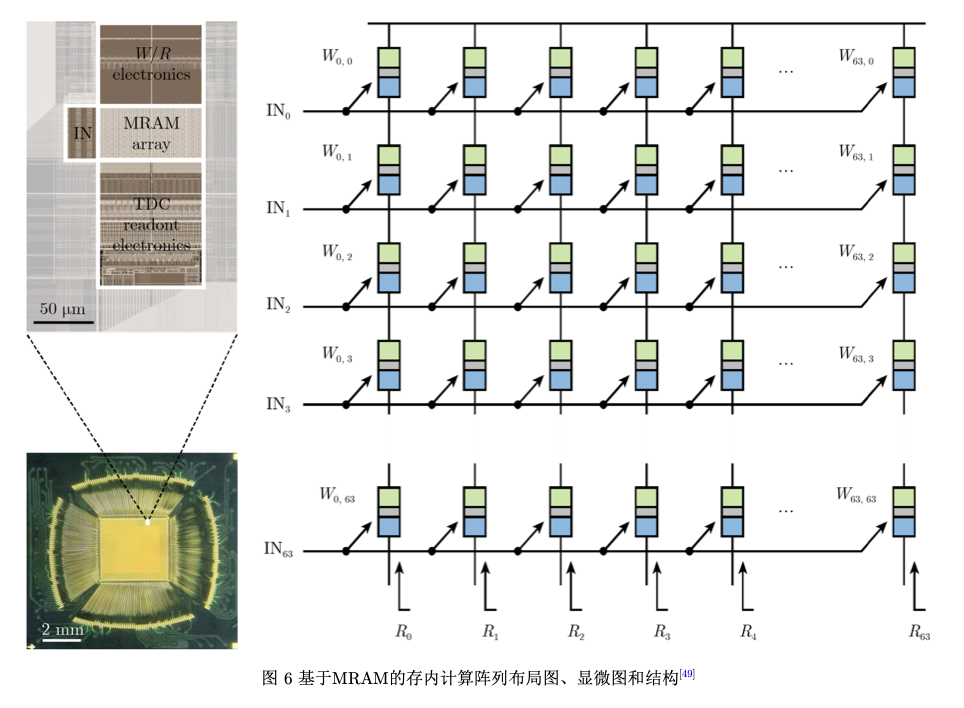
2022年,韩国三星公司在Nature期刊上发表了基于 电阻累加方案的MRAM模拟存内计算芯片原型,
并实现了最高405 TOPS/W的能效比[49],其阵列的 布局图、显微图和结构如图6所示。
3.5 NOR Flash存内计算
基于NOR Flash的存内计算技术原理与ReRAM 类似,如图7(a)所示。目前,NOR Flash存内计算 芯片技术相对较成熟,已于2021年实现量产。美国 的Mythic和国内的知存科技都已推出NOR Flash存 内计算芯片产品,其中,Mythic推出了M1076芯片 (如图7(b)所示),知存科技推出了WTM2101量产 SoC芯片(如图7©所示)。

3.6 基于其他介质的存内计算
此外,学术界还发表了基于NAND Flash以及新型纳米器件(如FeFET、斯格明子等)的存内计算 相关工作,其基本原理与上述方案类似,但是目前 仅仅是概念阶段,这里不再详述[50–54]。
3.7 存内计算芯片
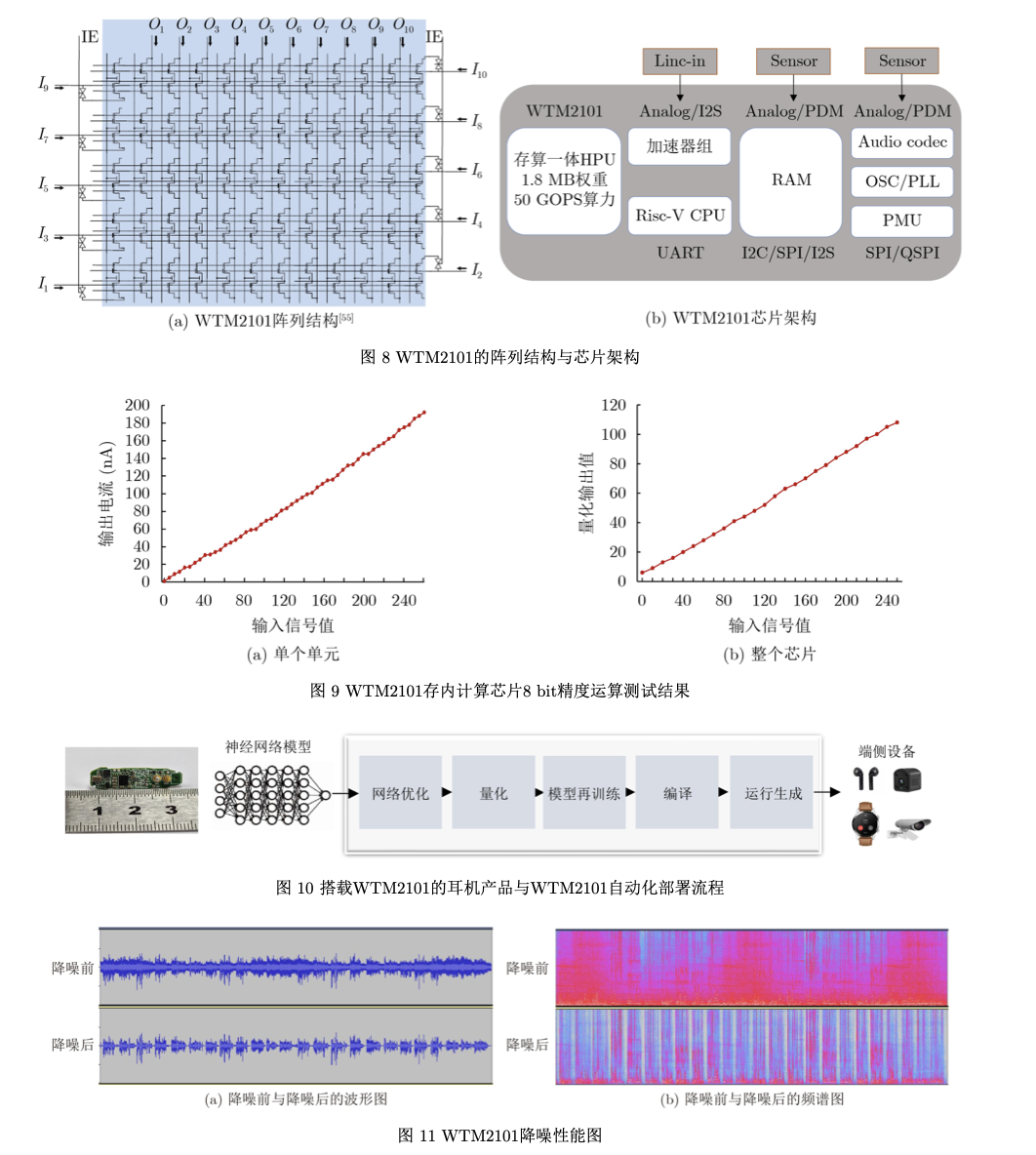
基于 NOR Flash 的soc :WTM2101
在NOR Flash存内计算芯片当中,向量-矩阵乘法运算基于电流/电压的跨导与基尔霍夫定律进 行物理实现,如图7(a)所示。因此,其核心是设计 NOR Flash单元阵列以满足大规模高能效向量-矩 阵乘法运算。同时,在核心电路的基础上,根据算 法特征设计芯片架构,以充分利用神经网络数据流 式的特点来实现芯片的并行化与流水线。在传统NOR Flash阵列中,对某一个特定器件编程会不可 避免地改变同一行上其他器件的状态,称为行干 扰。作为存内计算应用,NOR Flash编程需要逐个 器件进行单独操作,每个器件存储8 bit(256个量化 状态)以上的信息,微小的干扰就将导致状态的变 化。因此,需要抗编程干扰阵列结构来消除编程干 扰。除此之外,NOR Flash基于浮栅中电子的数量 来存储信息,随着时间的增加,电子会泄露,造成 阈值电压漂移。作为存储应用的NOR Flash器件通 常只保存1~2 bit信息(对应2~4个不同状态),状 态之间的裕量比较大(每个状态的电子数量多,即使泄露也能保持较长时间),不用特殊设计即可保存信息 10年以上。但在存内计算应用中,NOR Flash器件需要存储8 bit(256个不同状态)以上信息,状态之 间的裕量非常小,且通过整个阵列同时工作。因 此,阈值电压漂移的影响非常大。WTM2101通过 特殊的电路设计抑制阈值电压漂移对计算精度的影 响。此外,为了同时实现低功耗计算与低功耗控 制,WTM2101结合了RISC-V指令集与NOR Flash 存内计算阵列,其阵列结构与芯片架构如图8所 示,包括1.8 MB NOR Flash存内计算阵列,一个 RISC-V核,一个数字计算加速器组,320 kB RAM以及多种外设接口。
优势:
1、基 于存内计算架构,可高效地实现神经网络语音激活 检测和上百条语音命令词识别。
2、以超低功耗实 现神经网络环境降噪算法、健康监测与分析算法。
3、典型应用场景下,工作功耗均在微瓦级别。
4、采用极小封装尺寸。
应用场景
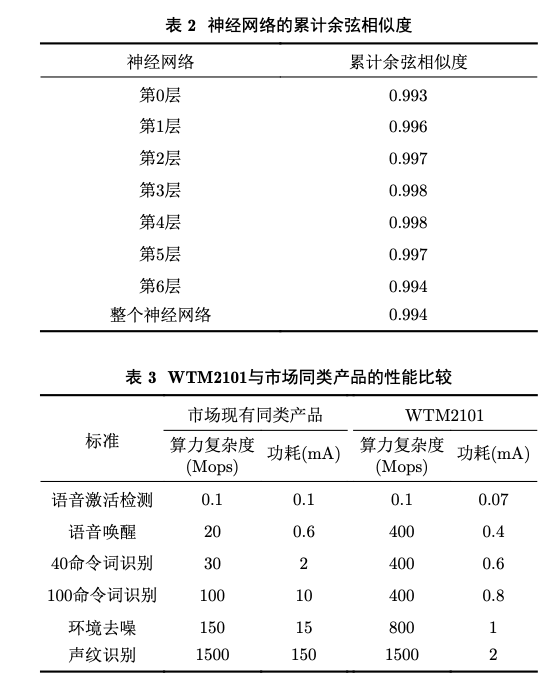
可应用于智能可穿戴设备、智能家居、安防监控、 玩具机器人等;适应多种应用,如语音识别、语音 降噪/增强、轻量级视觉识别、健康监测和声纹识 别等。如图10所示为搭载WTM2101的耳机产品及 其自动化部署流程。如图11所示为基于WTM2101 的耳机降噪前后效果的波形和频谱对比。如表2所 示为部署在WTM2101的神经网络的各层累计余弦 相似度(指存内计算相对于8-bit量化计算的余弦相 似度),可以看到经过8层神经网络计算,余弦相似度依旧保持在0.99以上。如表3所示为WTM2101在 语音激活检测、语音唤醒、命令词识别、环境去噪 和声纹识别方面与市场同类产品的对比。
总结
存内计算芯片技术,因其高算力、低功耗、低 成本等优势,未来可为物联网、大数据和人工智能 等具有海量数据特征的智能应用场景提供高能效硬 件解决方案。但要实现大规模产业化仍存在诸多挑 战:
(1)模拟计算精度提升困难,模拟存内计算的 精度受到信噪比的影响,很难做到8 以上。数字存内计算则不受信噪比的影响,但其能效、面积和成本需要综合权衡。近年来,通过数模混合的设计方式,可以在精度、成本与功耗之间得到很好的折中,是存内计算发展的一大重要方向。
(2)工具链 环节需更加完善以建立良好的生态:存内计算芯片 产业化处于起步阶段,目前面临相关工具链支持不足的问题,导致算法/应用厂商移植困难。随着存 内计算技术的快速发展,以及企业在这个技术领域 持续加大投入,相应的编译、优化等工具链可以快 速进步,有望建立初步的应用生态。
(3)跨层协同 设计需进一步加强:存内计算芯片涉及器件-工艺-芯片-算法-应用等多层次的跨层协同,各层环环相 扣,密不可分,需要跨层协同来实现性能(精度、 功耗、时延、可靠性等)与成本的最优。
QA
Q:存储墙与带宽墙的区别与联系?
A:
- 存储墙: 存储墙问题源于处理器(CPU)的计算速度远远超过内存的读写速度。随着处理器性能的快速提升,内存的性能增长却没有跟上,导致处理器在等待数据时出现闲置,无法充分发挥其计算能力。这种现象在高性能计算(HPC)领域尤为突出,因为它严重制约了计算效率。存储墙问题不仅涉及到内存的访问速度,还包括内存的容量和功耗问题98。
- 带宽墙: 带宽墙则更侧重于数据传输速率的限制。在计算机系统中,不同组件之间需要通过总线或网络进行数据交换,如果这些数据传输通道的带宽不足,就会成为系统性能的瓶颈。例如,在图形处理、网络通信或分布式计算中,数据传输需求可能非常巨大,如果带宽不够,就会限制整体性能。带宽墙问题通常与内存总线、互连网络或I/O系统相关710。
两者之间的关系是,存储墙问题通常伴随着带宽墙问题。当内存访问速度跟不上处理器需求时,不仅内存本身成为瓶颈,而且当处理器尝试通过有限的带宽从内存中获取数据时,带宽也成为问题。解决存储墙和带宽墙问题的方法包括改进内存技术、使用更快的互连技术、采用分布式存储策略、以及开发新的计算架构如存内计算(PIM)等3。