这是我的第272篇原创文章。
一、引言
粒子群算法(Particle Swarm Optimization, PSO)是一种启发式优化算法,可以用于优化神经网络模型的参数。在优化长短期记忆网络(Long Short-Term Memory, LSTM)时,可以结合粒子群算法来搜索最优的参数设置,以提高LSTM模型的性能和泛化能力。下面是一个简单的步骤示例,演示如何使用PSO来优化LSTM的超参数。
二、实现过程
2.1 读取数据集
# 读取数据集
data = pd.read_csv('data.csv')
# 将日期列转换为日期时间类型
data['Month'] = pd.to_datetime(data['Month'])
# 将日期列设置为索引
data.set_index('Month', inplace=True)data:
2.2 划分数据集
# 拆分数据集为训练集和测试集
train_size = int(len(data) * 0.8)
train_data = data[:train_size]
test_data = data[train_size:]
# 绘制训练集和测试集的折线图
plt.figure(figsize=(10, 6))
plt.plot(train_data, label='Training Data')
plt.plot(test_data, label='Testing Data')
plt.xlabel('Year')
plt.ylabel('Passenger Count')
plt.title('International Airline Passengers - Training and Testing Data')
plt.legend()
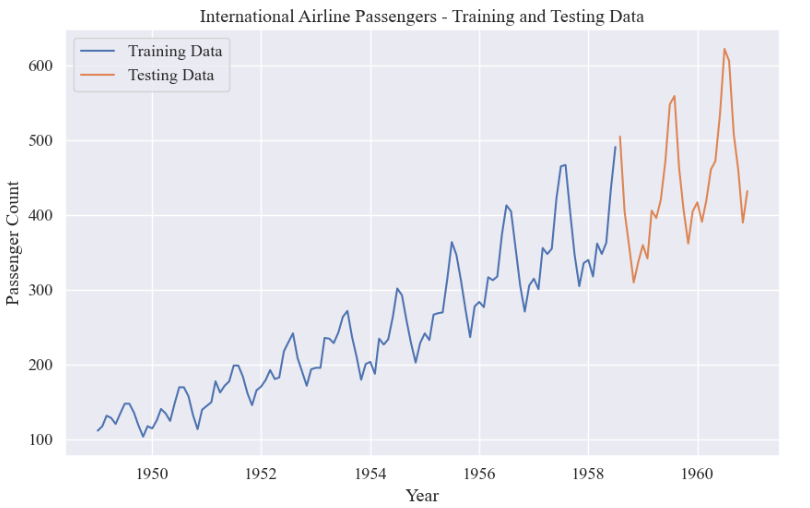
plt.show()共144条数据,8:2划分:训练集115,测试集29。
训练集和测试集:
2.3 归一化
# 将数据归一化到 0~1 范围
scaler = MinMaxScaler()
train_data_scaler = scaler.fit_transform(train_data.values.reshape(-1, 1))
test_data_scaler = scaler.transform(test_data.values.reshape(-1, 1))2.4 构造数据集
# 定义滑动窗口函数
def create_sliding_windows(data, window_size):
X, Y = [], []
for i in range(len(data) - window_size):
X.append(data[i:i + window_size, 0:data.shape[1]])
Y.append(data[i + window_size, 0])
return np.array(X), np.array(Y)
# 定义滑动窗口大小
window_size = 1
# 创建滑动窗口数据集
X_train, Y_train = create_sliding_windows(train_data_scaler, window_size)
X_test, Y_test = create_sliding_windows(test_data_scaler, window_size)
# 将数据集转换为 LSTM 模型所需的形状(样本数,时间步长,特征数)
X_train = np.reshape(X_train, (X_train.shape[0], window_size, 1))
X_test = np.reshape(X_test, (X_test.shape[0], window_size, 1))2.5 建立模型进行预测
# (1) PSO Parameters
MAX_EPISODES = 2
MAX_EP_STEPS = 2
c1 = 2
c2 = 2
w = 0.5
pN = 2 # 粒子数量
# (2) LSTM Parameters
dim = 4 # 搜索维度
X = np.zeros((pN, dim) ) # 所有粒子的位置和速度
V = np.zeros((pN, dim))
pbest = np.zeros((pN, dim)) # 个体经历的最佳位置和全局最佳位置
gbest = np.zeros(dim)
p_fit = np.zeros(pN) # 每个个体的历史最佳适应值
print(p_fit.shape)
print(p_fit.shape)
t1 = time.time()
'''
神经网络第一层神经元个数
神经网络第二层神经元个数
dropout比率
batch_size
'''
UP = [150, 15, 0.5, 16]
DOWN = [50, 5, 0.05, 8]
# (3) 开始搜索
for i_episode in range(MAX_EPISODES):
pass
# 训练模型 使用PSO找到的最好的神经元个数
neurons1 = int(gbest[0])
neurons2 = int(gbest[1])
dropout = gbest[2]
batch_size = int(gbest[3])
model = build_model(X_train, neurons1, neurons2, dropout)
history1 = model.fit(X_train, y_train, epochs=150, batch_size=batch_size, validation_split=0.2, verbose=1,
callbacks=[EarlyStopping(monitor='val_loss', patience=9, restore_best_weights=True)])
# 使用 LSTM 模型进行预测
train_predictions = model.predict(X_train)
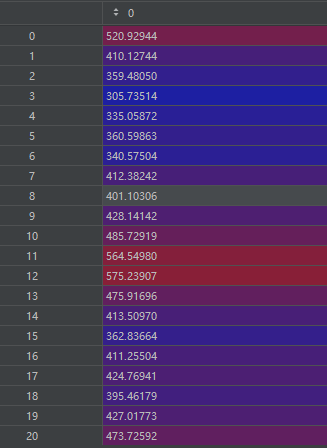
test_predictions = model.predict(X_test)best_params:

test_predictions:
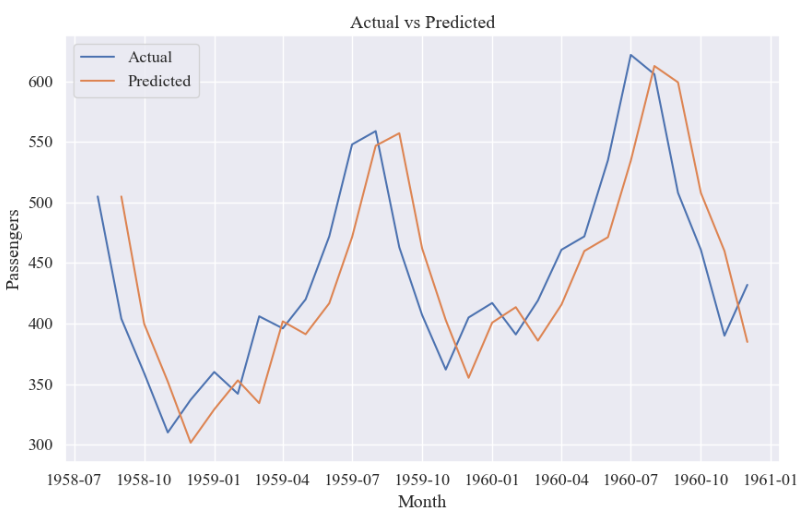
2.6 预测效果展示
# 绘制测试集预测结果的折线图
plt.figure(figsize=(10, 6))
plt.plot(test_data, label='Actual')
plt.plot(list(test_data.index)[-len(test_predictions):], test_predictions, label='Predicted')
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.title('Actual vs Predicted')
plt.legend()
plt.show()测试集真实值与预测值:
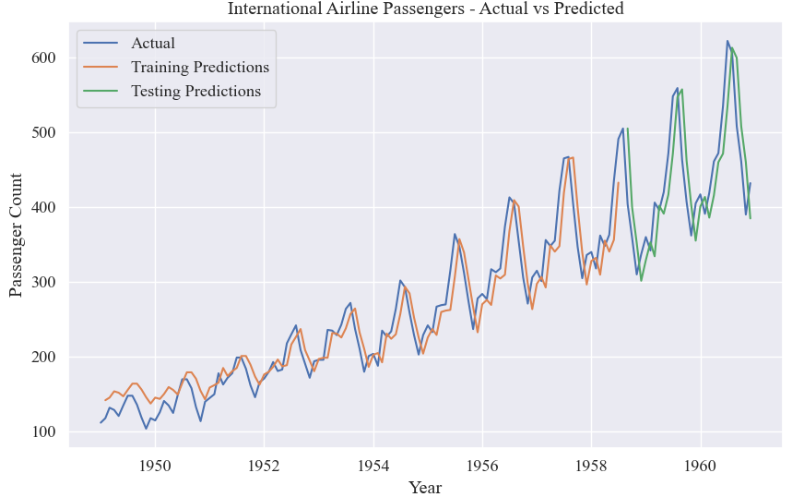
# 绘制原始数据、训练集预测结果和测试集预测结果的折线图
plt.figure(figsize=(10, 6))
plt.plot(data, label='Actual')
plt.plot(list(train_data.index)[look_back:train_size], train_predictions, label='Training Predictions')
plt.plot(list(test_data.index)[-(len(test_data)-look_back):], test_predictions, label='Testing Predictions')
plt.xlabel('Year')
plt.ylabel('Passenger Count')
plt.title('International Airline Passengers - Actual vs Predicted')
plt.legend()
plt.show()原始数据、训练集预测结果和测试集预测结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。