目录
摘要
ABSTRACT
1 DeepLabV3
1.1 空间金字塔池化(ASPP)
1.2 解码器(Decoder)
1.3 Xception
2 相关代码
摘要
DeepLabV3+ 是由Google Brain团队开发的深度学习模型,专注于语义分割任务。它采用深度卷积神经网络和空间金字塔池化等先进技术,能够准确地捕获图像的语义信息。通过空洞卷积和多尺度预测等策略,DeepLabV3+能够在不同尺度下有效地分割图像,同时通过解码器模块和融合级联特征进一步提高分割精度。这使得DeepLabV3+成为处理复杂场景和提取细节信息的强大工具,在图像分割、医学图像分析等领域具有广泛的应用前景。
ABSTRACT
DeepLabV3+ is a deep learning model developed by the Google Brain team, focusing on semantic segmentation tasks. It employs advanced techniques such as deep convolutional neural networks and spatial pyramid pooling to accurately capture the semantic information of images. Through strategies like dilated convolutions and multi-scale prediction, DeepLabV3+ can effectively segment images at different scales, while further enhancing segmentation accuracy through decoder modules and feature cascading fusion. This makes DeepLabV3+ a powerful tool for handling complex scenes and extracting detailed information, with wide applications in areas such as image segmentation and medical image analysis.
1 DeepLabV3
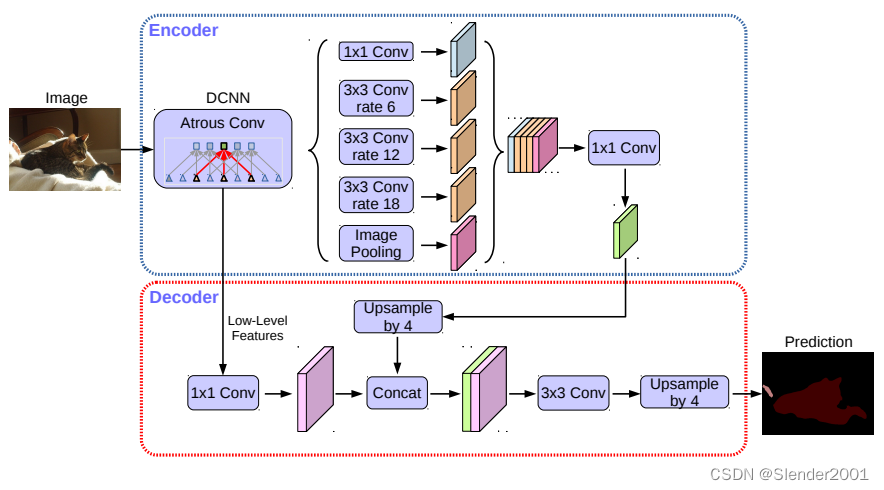
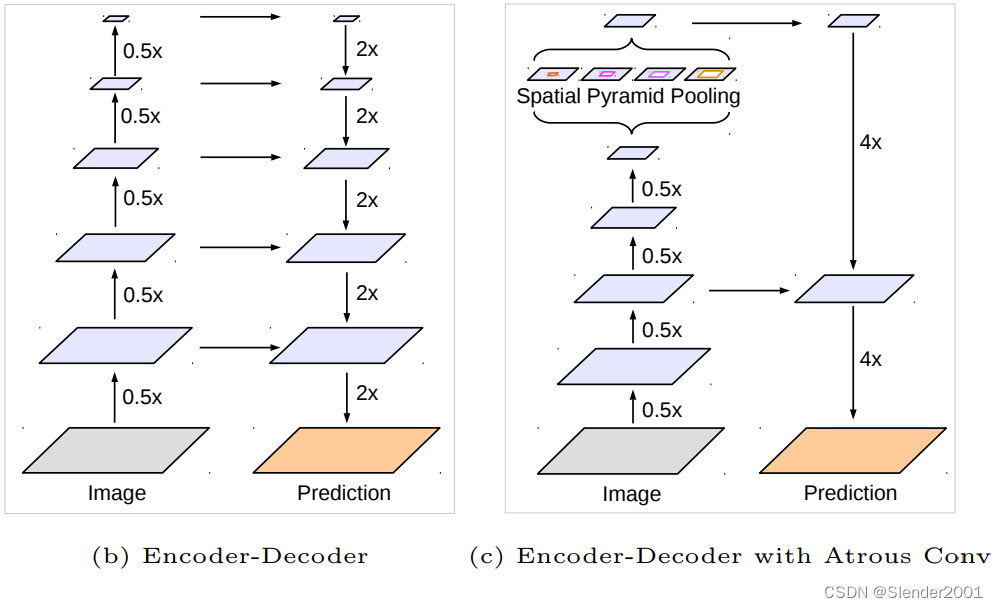
DeepLabv3+模型的整体架构如下图所示,它的Encoder的主体是带有空洞卷积的DCNN,可以采用常用的分类网络如ResNet,然后是带有空洞卷积的空间金字塔池化模块(Atrous Spatial Pyramid Pooling,ASPP),主要是为了引入多尺度信息;相比DeepLabv3,v3+引入了Decoder模块,其将底层特征与高层特征进一步融合,提升分割边界准确度。从某种意义上看,DeepLabv3+在DilatedFCN基础上引入了EcoderDecoder的思路。
对于DilatedFCN,主要是修改分类网络的后面block,用空洞卷积来替换stride=2的下采样层,如下图所示:其中a是原始FCN,由于下采样的存在,特征图不断降低;而b为DilatedFCN,在第block3后引入空洞卷积,在维持特征图大小的同时保证了感受野和原始网络一致。
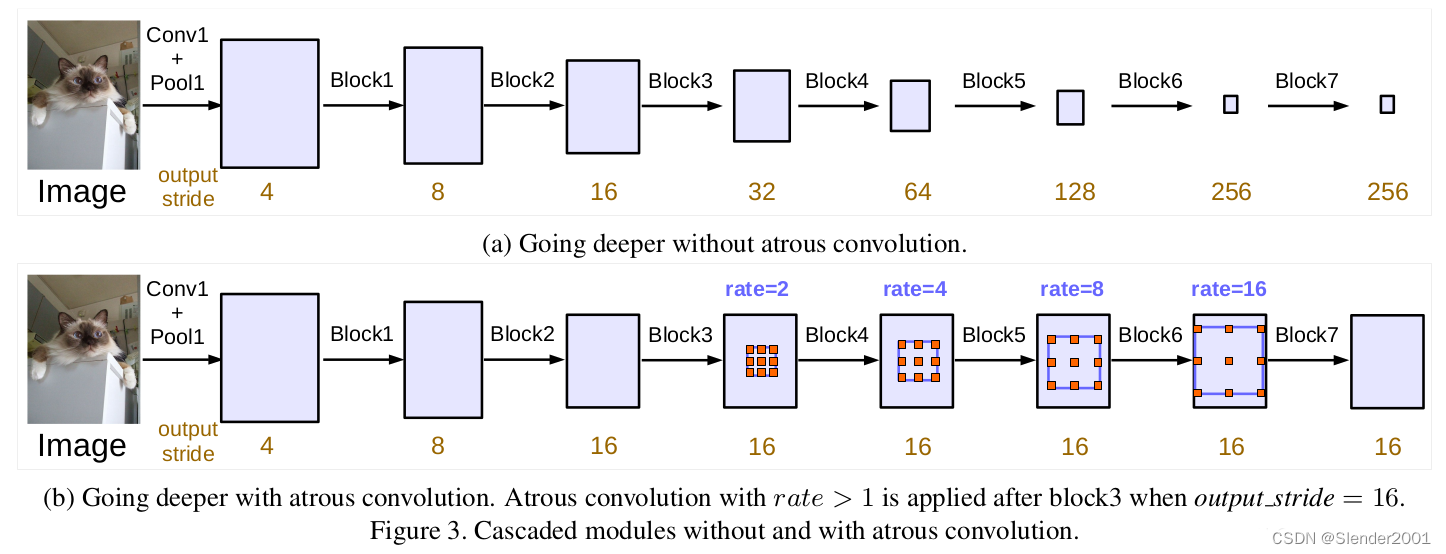
在DeepLab中,将输入图片与输出特征图的尺度之比记为output_stride,如上图的output_stride为16,如果加上ASPP结构,就变成如下图所示。其实这就是DeepLabv3结构,v3+只不过是增加了Decoder模块。这里的DCNN可以是任意的分类网络,一般又称为backbone,如采用ResNet网络。

1.1 空间金字塔池化(ASPP)
在DeepLab中,采用空间金字塔池化模块来进一步提取多尺度信息,这里是采用不同rate的空洞卷积来实现这一点。ASPP模块主要包含以下几个部分: (1) 一个1×1卷积层,以及三个3x3的空洞卷积,对于output_stride=16,其rate为(6, 12, 18) ,若output_stride=8,rate加倍(这些卷积层的输出channel数均为256,并且含有BN层); (2)一个全局平均池化层得到image-level特征,然后送入1x1卷积层(输出256个channel),并双线性插值到原始大小; (3)将(1)和(2)得到的4个不同尺度的特征在channel维度concat在一起,然后送入1x1的卷积进行融合并得到256-channel的新特征。
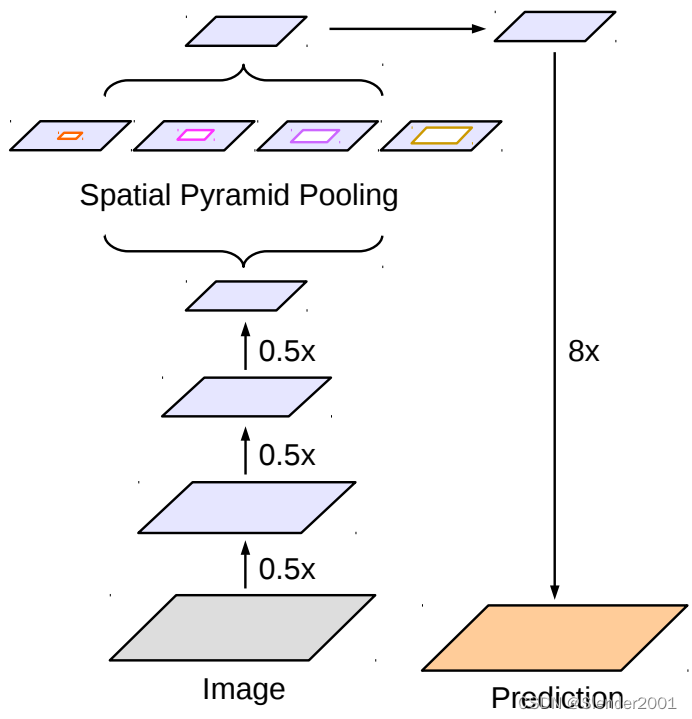
ASPP主要是为了抓取多尺度信息,这对于分割准确度至关重要,一个与ASPP结构比较像的是[PSPNet](Pyramid Scene Parsing Network)中的金字塔池化模块,如下图所示,主要区别在于这里采用池化层来获取多尺度特征。

1.2 解码器(Decoder)
对于DeepLabv3,经过ASPP模块得到的特征图的output_stride为8或者16,其经过1x1的分类层后直接双线性插值到原始图片大小,这是一种非常暴力的decoder方法,特别是output_stride=16。然而这并不利于得到较精细的分割结果,故v3+模型中借鉴了EncoderDecoder结构,引入了新的Decoder模块,如下图所示。首先将encoder得到的特征双线性插值得到4x的特征,然后与encoder中对应大小的低级特征concat,如ResNet中的Conv2层,由于encoder得到的特征数只有256,而低级特征维度可能会很高,为了防止encoder得到的高级特征被弱化,先采用1x1卷积对低级特征进行降维(paper中输出维度为48)。两个特征concat后,再采用3x3卷积进一步融合特征,最后再双线性插值得到与原始图片相同大小的分割预测。
1.3 Xception
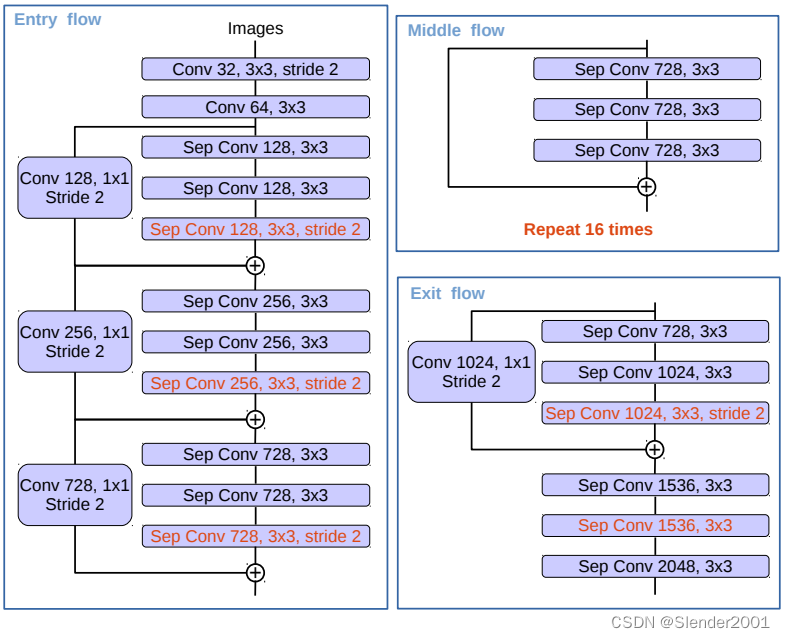
DeepLabv3所采用的backbone是ResNet网络,在v3+模型作者尝试了改进的Xception,Xception网络主要采用depthwise separable convolution,这使得Xception计算量更小。改进的Xception主要体现在以下几点: (1)参考MSRA的修改(Deformable Convolutional Networks),增加了更多的层; (2)所有的最大池化层使用stride=2的depthwise separable convolutions替换,这样可以改成空洞卷积 ; (3)与MobileNet类似,在3x3 depthwise convolution后增加BN和ReLU。
采用改进的Xception网络作为backbone,DeepLab网络分割效果上有一定的提升。作者还尝试了在ASPP中加入depthwise separable convolution,发现在基本不影响模型效果的前提下减少计算量。
2 相关代码
class DeepLab:输入x经过backbone得到16倍下采样的feature map1和低级feature map2;feature map1送入ASPP模块,得到结果,然后和feature map2一起送入Decoder模块;最后经过插值得到与原图大小相等的预测图。代码如下:
class DeepLab(BaseModel):
def __init__(self, num_classes, in_channels=3, backbone='xception', pretrained=True,
output_stride=16, freeze_bn=False, **_):
super(DeepLab, self).__init__()
assert ('xception' or 'resnet' in backbone)
if 'resnet' in backbone:
self.backbone = ResNet(in_channels=in_channels, output_stride=output_stride, pretrained=pretrained)
low_level_channels = 256
else:
self.backbone = Xception(output_stride=output_stride, pretrained=pretrained)
low_level_channels = 128
self.ASSP = ASSP(in_channels=2048, output_stride=output_stride)
self.decoder = Decoder(low_level_channels, num_classes)
if freeze_bn: self.freeze_bn()
def forward(self, x):
H, W = x.size(2), x.size(3)
x, low_level_features = self.backbone(x)
x = self.ASSP(x)
x = self.decoder(x, low_level_features)
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True)
return x
# Two functions to yield the parameters of the backbone
# & Decoder / ASSP to use differentiable learning rates
# FIXME: in xception, we use the parameters from xception and not aligned xception
# better to have higher lr for this backbone
def get_backbone_params(self):
return self.backbone.parameters()
def get_decoder_params(self):
return chain(self.ASSP.parameters(), self.decoder.parameters())
def freeze_bn(self):
for module in self.modules():
if isinstance(module, nn.BatchNorm2d): module.eval()需要注意的是:如果使用ResNet系列作为backbone,中间的低级feature map输出维度为256,如果使用Xception作为backbone,中间的低级feature map维度为128。不过,不管是256还是128,最终都要在送入Decoder后降采样到48通道。
backbone-ResNet:对于ResNet系列,一共有layer0~4,共五个layer。其中,前三个layers,也即layer0~layer2不变,仅针对layer3、layer4进行了改进,将普通卷积改为了空洞卷积。如果输出步幅(输入尺寸与输出feature map尺寸之比)为8,需要改动layer3和layer4;如果输出步幅为16,则仅改动layer4:
if output_stride == 16: s3, s4, d3, d4 = (2, 1, 1, 2)
elif output_stride == 8: s3, s4, d3, d4 = (1, 1, 2, 4)
if output_stride == 8:
for n, m in self.layer3.named_modules():
if 'conv1' in n and (backbone == 'resnet34' or backbone == 'resnet18'):
m.dilation, m.padding, m.stride = (d3,d3), (d3,d3), (s3,s3)
elif 'conv2' in n:
m.dilation, m.padding, m.stride = (d3,d3), (d3,d3), (s3,s3)
elif 'downsample.0' in n:
m.stride = (s3, s3)
for n, m in self.layer4.named_modules():
if 'conv1' in n and (backbone == 'resnet34' or backbone == 'resnet18'):
m.dilation, m.padding, m.stride = (d4,d4), (d4,d4), (s4,s4)
elif 'conv2' in n:
m.dilation, m.padding, m.stride = (d4,d4), (d4,d4), (s4,s4)
elif 'downsample.0' in n:
m.stride = (s4, s4)此外,中间的低级feature maps在ResNet系列中,是layer1的输出。
backbone-Xception:如果以Xception作为backbone,则需要对Xception的中间流(Middle Flow)和出口流(Exit flow)进行改动:去掉原有的池化层,并将原有的卷积层替换为带有步长的可分离卷积,但是入口流(Entry Flow)不变:
# Stride for block 3 (entry flow), and the dilation rates for middle flow and exit flow
if output_stride == 16: b3_s, mf_d, ef_d = 2, 1, (1, 2)
if output_stride == 8: b3_s, mf_d, ef_d = 1, 2, (2, 4)
# Entry Flow
self.conv1 = nn.Conv2d(in_channels, 32, 3, 2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32, 64, 3, 1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(64)
self.block1 = Block(64, 128, stride=2, dilation=1, use_1st_relu=False)
self.block2 = Block(128, 256, stride=2, dilation=1)
self.block3 = Block(256, 728, stride=b3_s, dilation=1)
# Middle Flow
for i in range(16):
exec(f'self.block{i+4} = Block(728, 728, stride=1, dilation=mf_d)')
# Exit flow
self.block20 = Block(728, 1024, stride=1, dilation=ef_d[0], exit_flow=True)
self.conv3 = SeparableConv2d(1024, 1536, 3, stride=1, dilation=ef_d[1])
self.bn3 = nn.BatchNorm2d(1536)
self.conv4 = SeparableConv2d(1536, 1536, 3, stride=1, dilation=ef_d[1])
self.bn4 = nn.BatchNorm2d(1536)
self.conv5 = SeparableConv2d(1536, 2048, 3, stride=1, dilation=ef_d[1])
self.bn5 = nn.BatchNorm2d(2048)而中间的低级feature maps在Xception系列中,是Entry Flow中block1的输出。
class ASPP:从backbone出来的输出步幅为16的feature maps被送入了ASPP模块,在该模块中经过不同膨胀率的卷积块和一个全局信息提取块后,concat起来,最后经过一个1*1卷积块之后,即为ASPP模块的输出。注意,这里之所以说是“块”,是因为其不单单包含一个操作,也包含了多个其他的操作,如BN、RELU、Dropout等,上文的1.1节等地方均有类似描述。如ASPP的不同膨胀率的分支定义如下:
def assp_branch(in_channels, out_channles, kernel_size, dilation):
padding = 0 if kernel_size == 1 else dilation
return nn.Sequential(
nn.Conv2d(in_channels, out_channles, kernel_size, padding=padding, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channles),
nn.ReLU(inplace=True))全局信息提取块定义如下:
self.avg_pool = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(in_channels, 256, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True))ASPP类定义的完整代码如下:
class ASSP(nn.Module):
def __init__(self, in_channels, output_stride):
super(ASSP, self).__init__()
assert output_stride in [8, 16], 'Only output strides of 8 or 16 are suported'
if output_stride == 16: dilations = [1, 6, 12, 18]
elif output_stride == 8: dilations = [1, 12, 24, 36]
self.aspp1 = assp_branch(in_channels, 256, 1, dilation=dilations[0])
self.aspp2 = assp_branch(in_channels, 256, 3, dilation=dilations[1])
self.aspp3 = assp_branch(in_channels, 256, 3, dilation=dilations[2])
self.aspp4 = assp_branch(in_channels, 256, 3, dilation=dilations[3])
self.avg_pool = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(in_channels, 256, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True))
self.conv1 = nn.Conv2d(256*5, 256, 1, bias=False)
self.bn1 = nn.BatchNorm2d(256)
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(0.5)
initialize_weights(self)
def forward(self, x):
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
x5 = F.interpolate(self.avg_pool(x), size=(x.size(2), x.size(3)), mode='bilinear', align_corners=True)
x = self.conv1(torch.cat((x1, x2, x3, x4, x5), dim=1))
x = self.bn1(x)
x = self.dropout(self.relu(x))
return xclass Decoder:Decoder部分属于最后一部分了,其接受backbone的低级feature maps和ASPP输出的feature maps,并对其分别进行了降维、上采样,然后concat,最后经过一组3*3卷积块后输出。其类定义代码如下:
class Decoder(nn.Module):
def __init__(self, low_level_channels, num_classes):
super(Decoder, self).__init__()
self.conv1 = nn.Conv2d(low_level_channels, 48, 1, bias=False)
self.bn1 = nn.BatchNorm2d(48)
self.relu = nn.ReLU(inplace=True)
# Table 2, best performance with two 3x3 convs
self.output = nn.Sequential(
nn.Conv2d(48+256, 256, 3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Conv2d(256, num_classes, 1, stride=1),
)
initialize_weights(self)
def forward(self, x, low_level_features):
low_level_features = self.conv1(low_level_features)
low_level_features = self.relu(self.bn1(low_level_features))
H, W = low_level_features.size(2), low_level_features.size(3)
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True)
x = self.output(torch.cat((low_level_features, x), dim=1))
return x需要注意的是,该代码将最后的4倍上采样插值的操作放到Decoder外面了,这一点与论文稍有差别,但只是归属不同,效果是一样的,不影响使用。