在处理时间序列预测问任务时,损失函数的选择非常重要,因为它会驱动算法的学习过程。以往的工作提出了不同的损失函数,以解决数据存在偏差、需要长期预测、存在多重共线性特征等问题。
本文工作总结了常用的的 14 个损失函数并对它们的优缺点进行分析,这些损失函数已被证明在不同领域提供了最先进的结果。

时间序列数据与一般基于回归的数据略有不同,因为在特征中添加了时间信息,使目标更加复杂。时间序列数据具有以下组成部分
level:每个时间序列都有一个 base level,简单的 base level 的计算可以直接通过对历史数据进行平均/中位数计算得到;
周期性:时间序列数据也有一种称为周期性的模式,它不定期重复,这意味着它不会以相同的固定间隔出现;
趋势:表示时间序列在一段时间内是增加还是减少。也就是说,它有上升(增加)或下降(减少)的趋势;
季节性:在一段时间内重复出现的模式称为季节性;
噪声:在提取水平、周期性、趋势和季节性之后,剩下的就是噪声,噪声是数据中完全随机的变化。
每个机器学习模型的基本目标都是改进模型的选定指标并减少与之相关的损失。用于时间序列预测的机器学习或深度学习模型的一个重要组成部分是损失函数,模型的性能是根据损失函数来衡量的,促使了模型参数的更新。
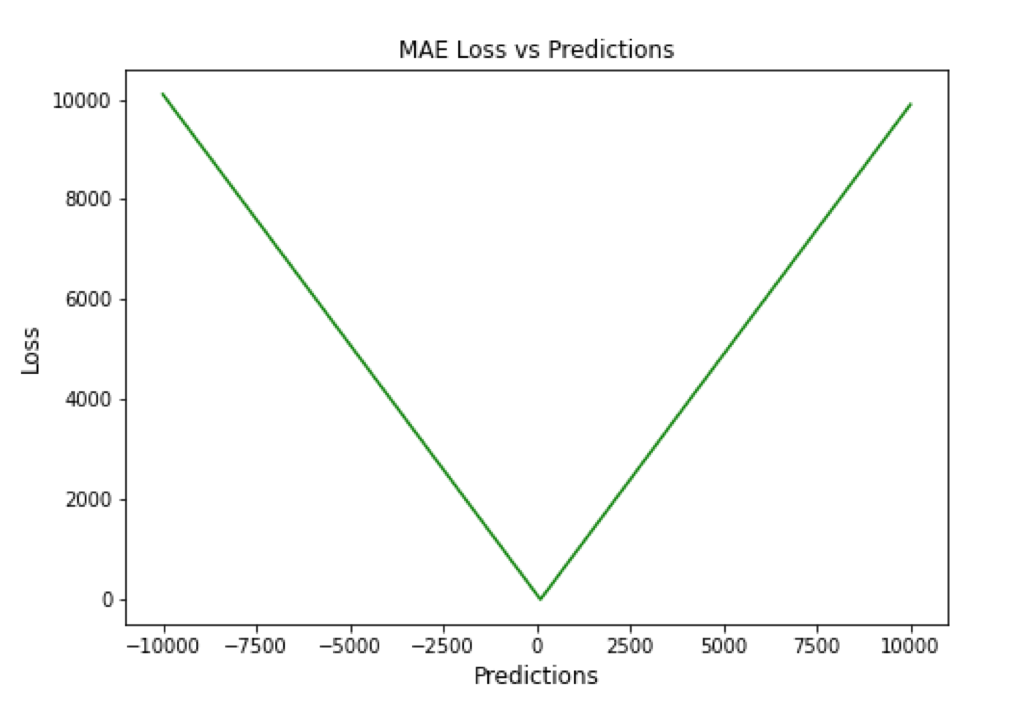
Mean Absolute Error (MAE)
MAE,也称为 L1 损失,是预测值与实际值之间的绝对误差:

所有样本值的绝对误差的均值就称为 MAE:


Mean Squared Error (MSE)
MSE,也称为 L2 损失,是预测值与实际值之间的平方误差:
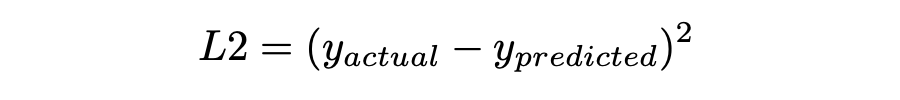
所有样本值的平方误差的均值就称为 MSE,也称作均方误差:
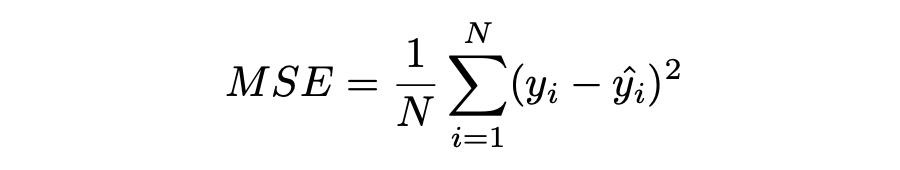
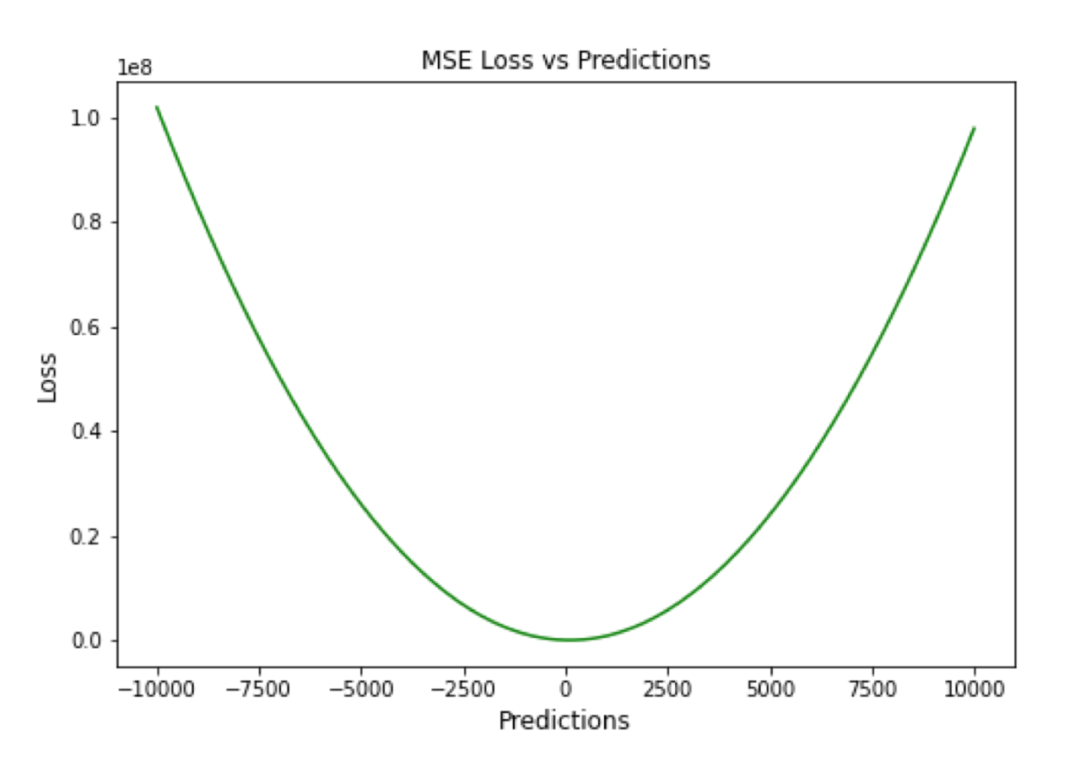
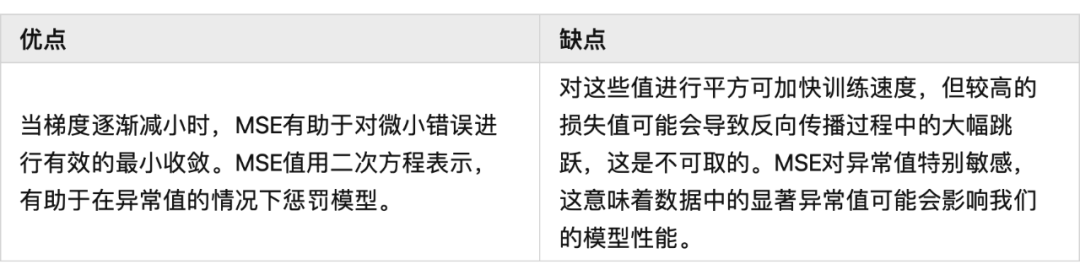
MSE 也称为二次损失,因为惩罚是平方而不是与误差成正比。当误差被平方时,离群值被赋予更多的权重,为较小的误差创建一个平滑的梯度。受益于这种对巨大错误的惩罚,有助于优化算法获得参数的最佳值。鉴于错误是平方的,MSE 永远不会是负数,错误的值可以是 0 到无穷大之间的任何值。随着错误的增加,MSE 呈指数增长,好的模型的 MSE 值将接近于 0。
Mean Bias Error (MBE)
高估或低估参数值的倾向称为偏差或平均偏差误差。偏差的唯一可能方向是正向或负向。正偏差表示数据误差被高估,而负偏差表示误差被低估。
实际值和预期值之间的差异被测量为平均偏差误差(MBE)。预测中的平均偏差由 MBE 量化。除了不考虑绝对值外,它实际上与 MAE 相同。应谨慎对待 MBE,因为正向误差和负向误差可能会相互抵消。
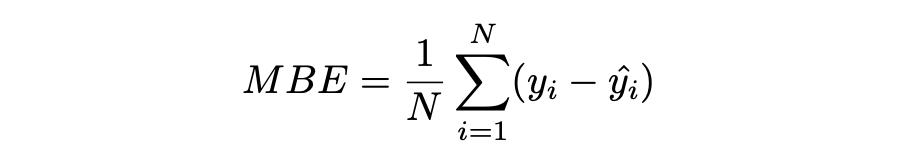
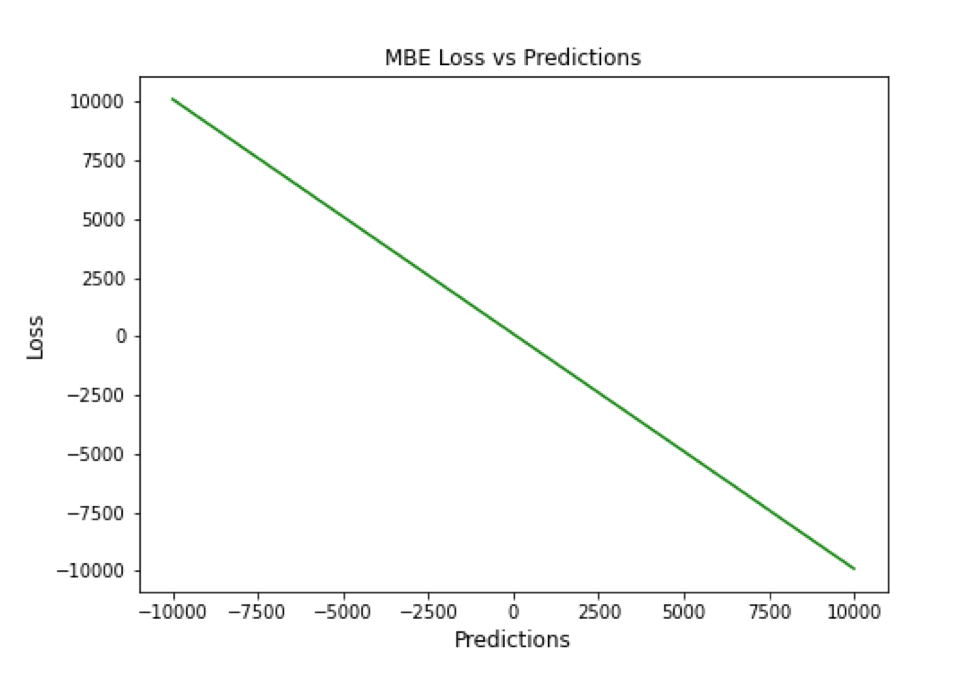
▲ MBE Loss与Predictions的性能图

Relative Absolute Error (RAE)
RAE 的计算将总绝对误差除以平均值与实际值之间的绝对差值:


RAE 是一种基于比率的指标,用于评估预测模型的有效性。RAE 的可能值介于 0 和 1 之间。接近零的值(零是最佳值)是良好模型的特征。
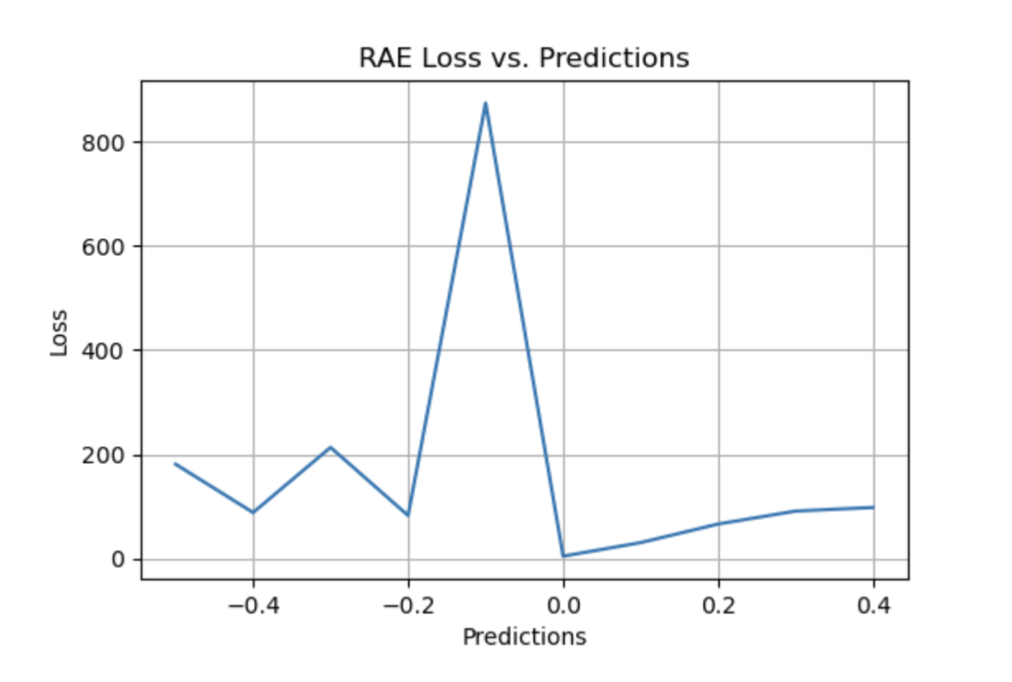
▲ RAE Loss与Predictions的性能图

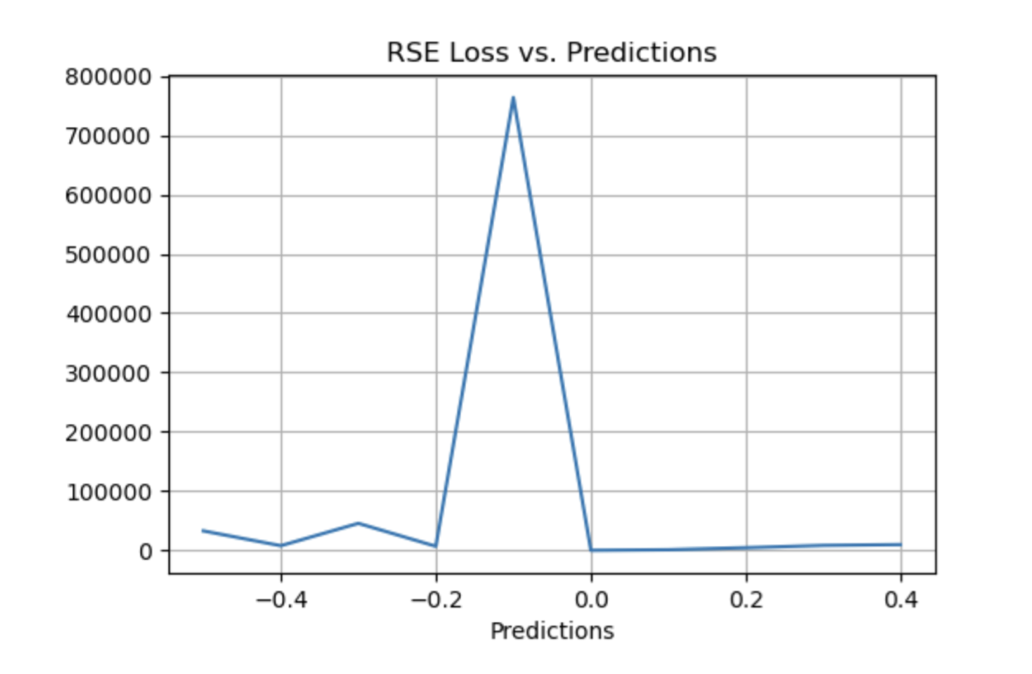
Relative Squared Error (RSE)
RSE 衡量在没有简单预测器的情况下结果的不准确程度。这个简单的预测变量仅代表实际值的平均值。结果,相对平方误差将总平方误差除以简单预测变量的总平方误差以对其进行归一化。可以在以不同单位计算误差的模型之间进行比较。
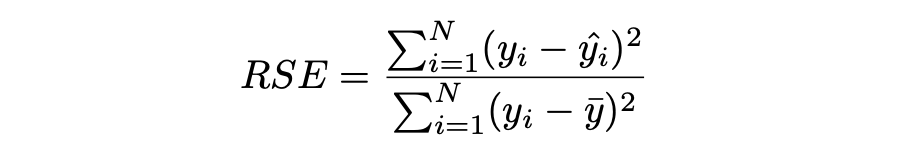
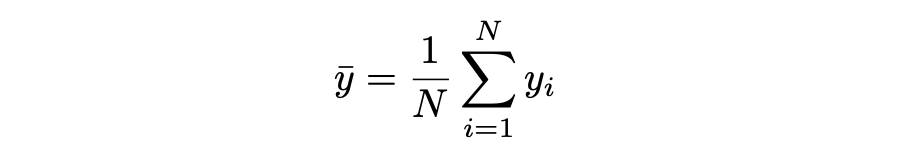
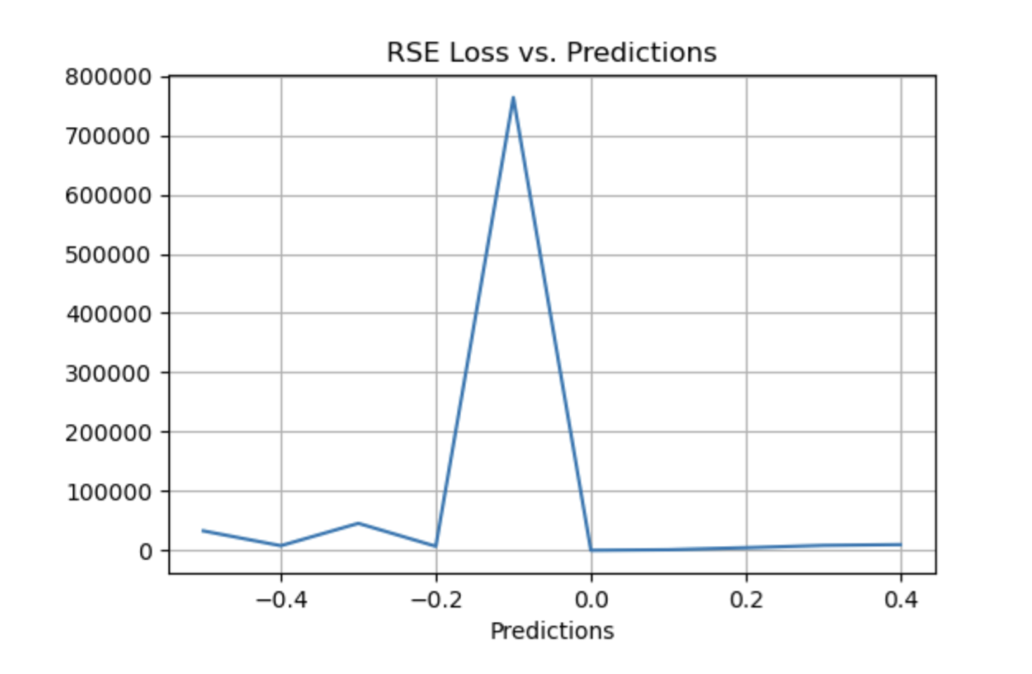
▲ RSE Loss与Predictions的性能图

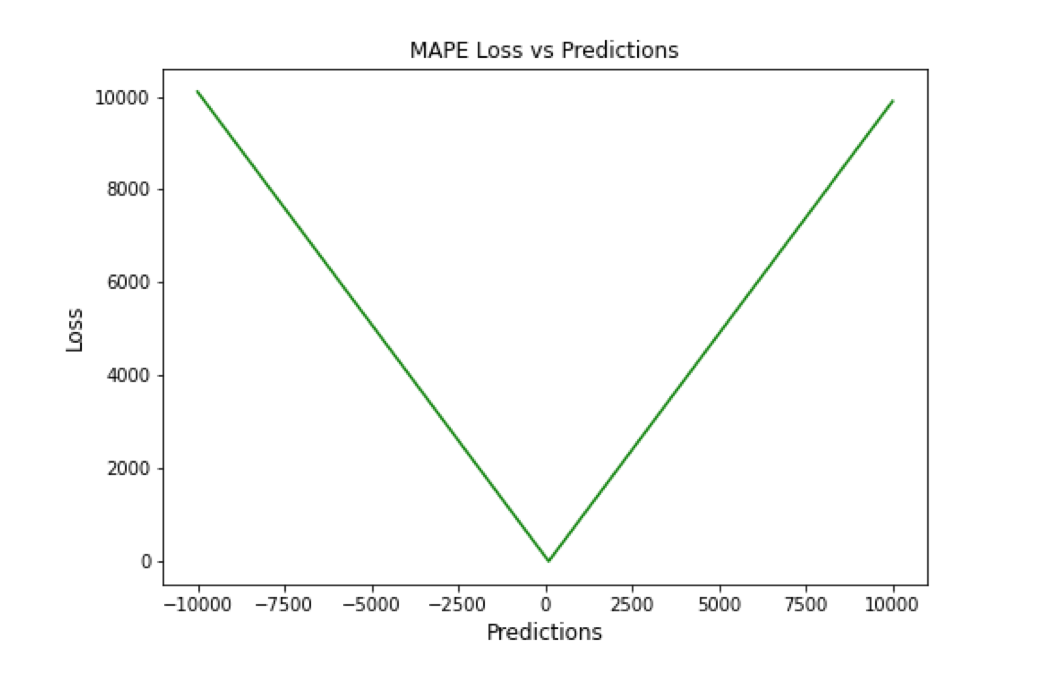
Mean Absolute Percentage Error (MAPE)
平均绝对百分比误差(MAPE),也称为平均绝对百分比偏差(MAPD),是用于评估预测系统准确性的指标。它通过从实际值减去预测值的绝对值除以实际值来计算每个时间段的平均绝对百分比误差百分比。由于变量的单位缩放为百分比单位,因此平均绝对百分比误差(MAPE)广泛用于预测误差。当数据中没有异常值时,它效果很好,常用于回归分析和模型评估。
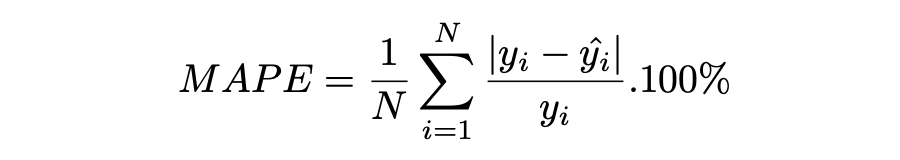
▲ MAPE Loss与Predictions的性能图

Root Mean Squared Error (RMSE)
MSE 的平方根用于计算 RMSE。均方根偏差是 RMSE 的另一个名称。它考虑了实际值的变化并测量误差的平均幅度。RMSE 可以应用于各种特征,因为它有助于确定特征是否增强模型预测。当非常不希望出现巨大错误时,RMSE 最有用。
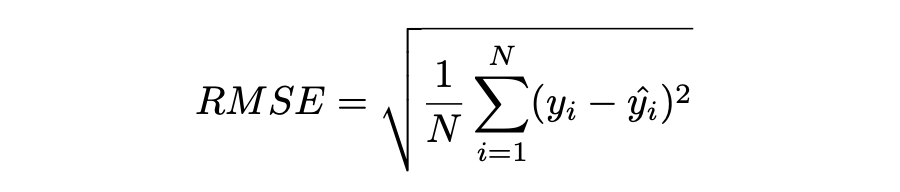
▲ RMSE Loss与Predictions的性能图
Mean Squared Logarithmic Error (MSLE)
均方对数误差(MSLE)衡量实际值与预期值之间的差异。添加对数减少了 MSLE 对实际值和预测值之间的百分比差异以及两者之间的相对差异的关注。MSLE 将粗略地处理小的实际值和预期值之间的微小差异以及大的真实值和预测值之间的巨大差异。

这种损失可以解释为真实值和预测值之间比率的度量:


▲ MSLE Loss与Predictions的性能图

Root Mean Squared Logarithmic Error (RMSLE)
RMSLE 通过应用 log 到实际和预测的值,然后进行相减。当同时考虑小误差和大误差时,RMSLE 可以避免异常值的影响。
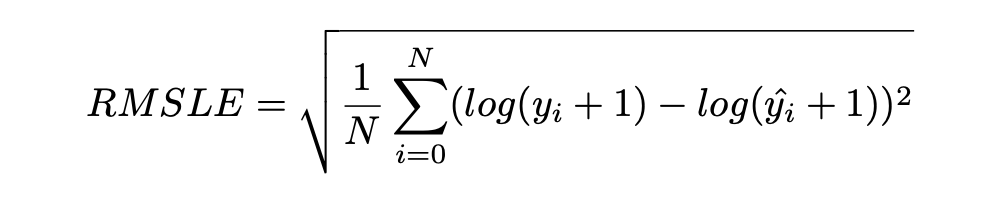
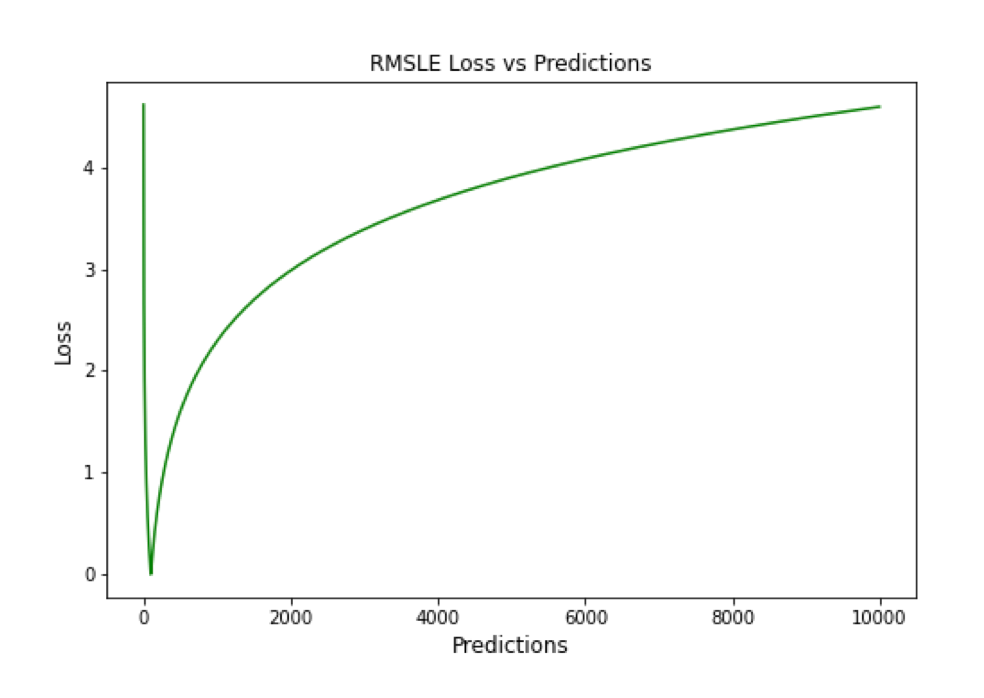
▲ RMSLE Loss与Predictions的性能图

Normalized Root Mean Squared Error (NRMSE)
归一化均方根误差(NRMSE)RMSE 有助于不同尺度模型之间的比较。该变量具有观测范围的归一化 RMSE(NRMSE),它将 RMSE 连接到观测范围。
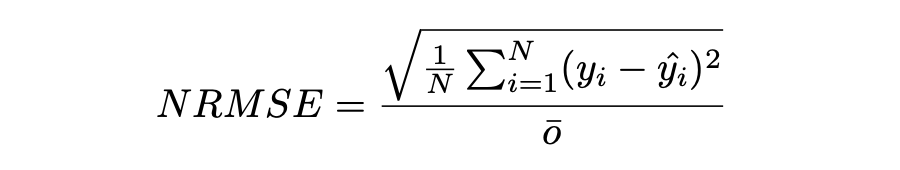
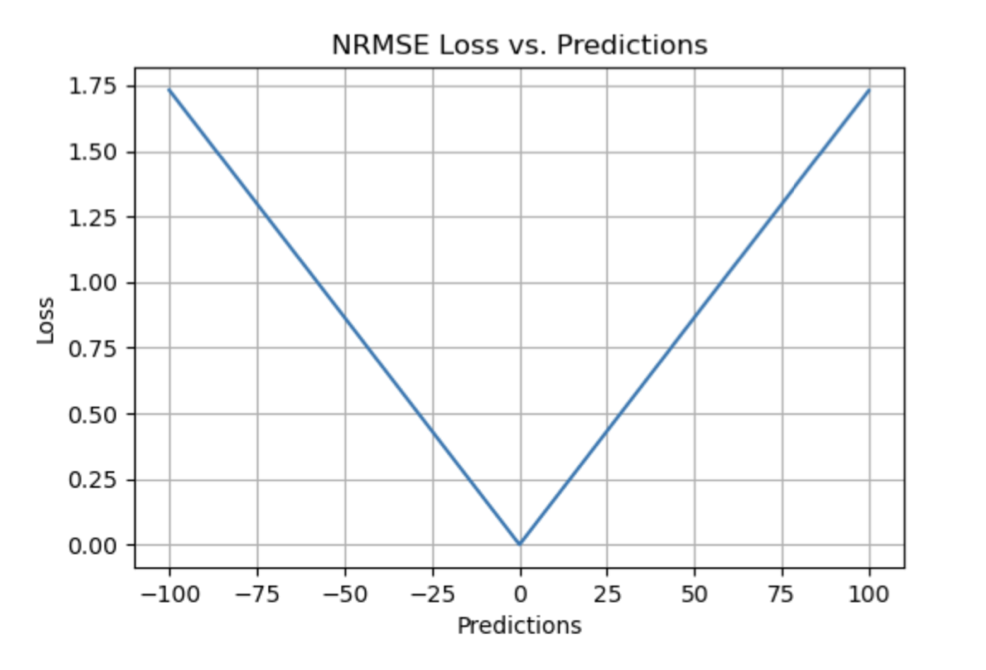
▲ NRMSE Loss与Predictions的性能图

Relative Root Mean Squared Error (RRMSE)
RRMSE 是没有维度的 RMSE 变体。相对均方根误差(RRMSE)是一种均方根误差度量,它已根据实际值进行缩放,然后由均方根值归一化。虽然原始测量的尺度限制了 RMSE,但 RRMSE 可用于比较各种测量方法。当您的预测被证明是错误的时,会出现增强的 RRMSE,并且该错误由 RRMSE 相对或以百分比表示。
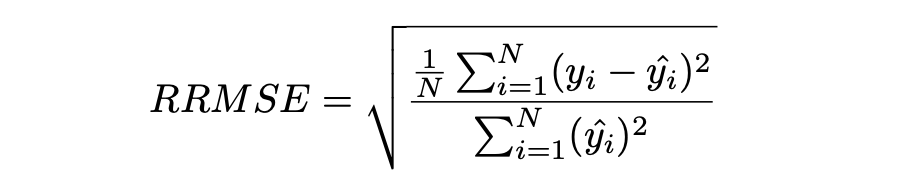
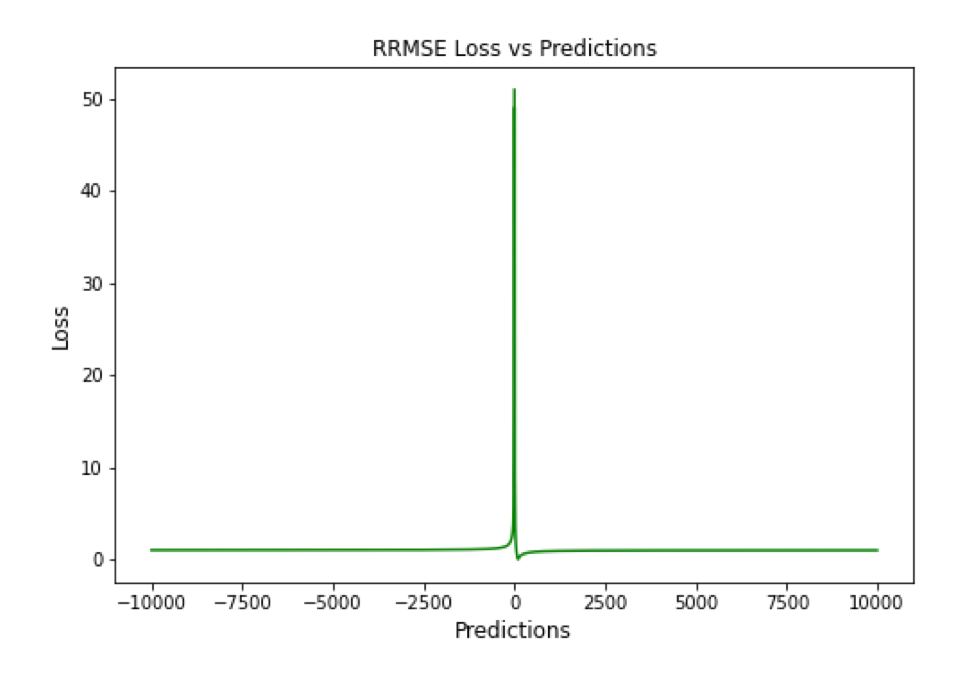
▲ RRMSE Loss与Predictions的性能图

Huber Loss
Huber 损失是二次和线性评分算法的理想组合。还有超参数 delta. 对于小于 delta 的损失值,应该使用 MSE;对于大于 delta 的损失值,应使用 MAE。这成功地结合了两种损失函数的最大特点。

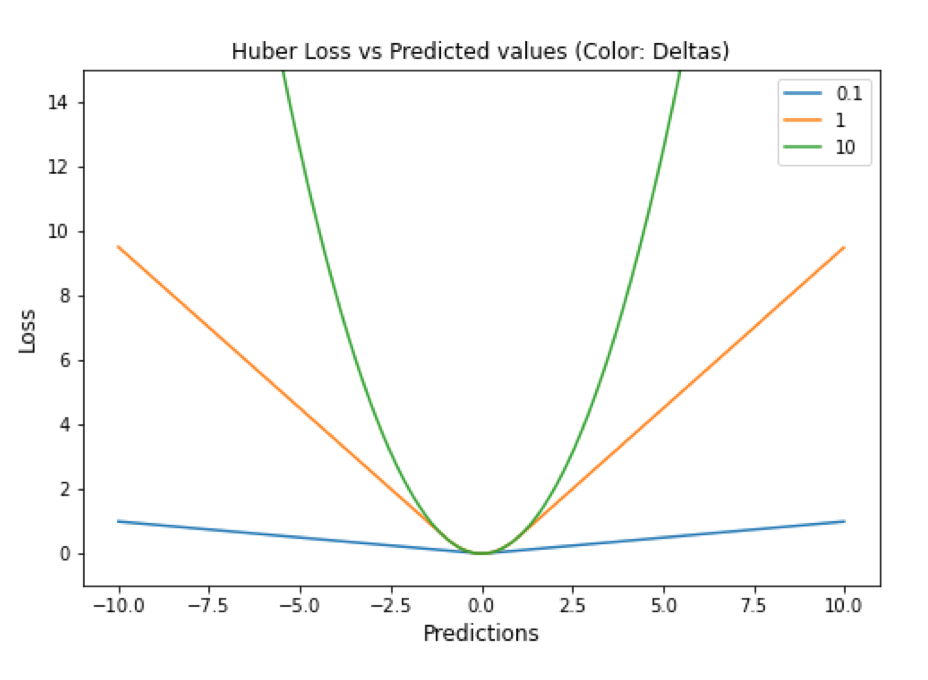
▲ Huber Loss与Predictions的性能图

LogCosh Loss
LogCosh 计算误差的双曲余弦的对数。这个函数比二次损失更平滑。它的功能类似于 MSE,但不受重大预测误差的影响。鉴于它使用线性和二次评分技术,它非常接近 Huber 损失。


▲ LogCosh Loss与Predictions的性能图

Quantile Loss
分位数回归损失函数用于预测分位数。分位数是指示组中有多少值低于或高于特定阈值的值。它计算跨预测变量(独立)变量值的响应(因)变量的条件中位数或分位数。除了第 50 个百分位数是 MAE,损失函数是 MAE 的扩展。它不对响应的参数分布做出任何假设,甚至为具有非常量方差的残差提供预测区间。
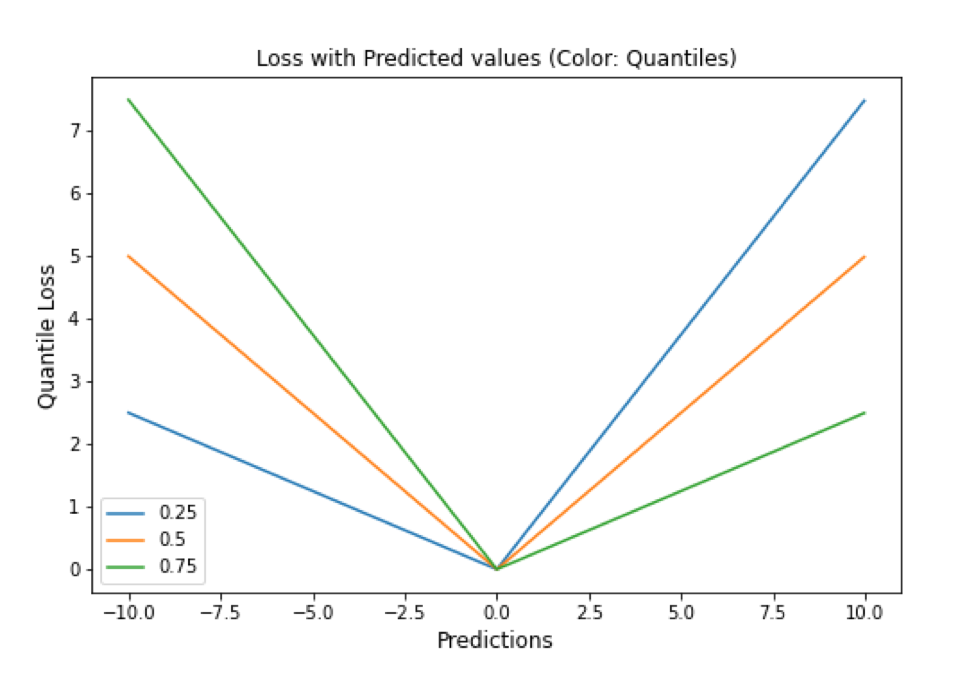
▲ Quantile Loss与Predictions的性能图

总结
损失函数在确定给定目标的良好拟合模型中起着关键作用。对于时间序列预测等复杂目标,不可能确定通用损失函数。有很多因素,如异常值、数据分布的偏差、ML 模型要求、计算要求和性能要求。没有适用于所有类型数据的单一损失函数。在主要关注模型架构和数据类型的学术环境中,损失函数可以通过用于训练的数据集属性(如分布、边界等)来确定。
这项工作试图构建特定损失函数可能有用的情况,例如在数据集中出现异常值的情况下,均方误差是最佳策略;然而,如果有更少的异常值,则平均绝对误差将是比 MSE 更好的选择。同样,如果我们希望保持平衡,并且我们的目标基于百分位数损失,那么使用 LogCosh 是更好的方法。
补充--P10,P50,P90算法代码
#!/usr/bin/env python
#coding:utf8
def test_percentile():
"""
方式一:直接写算法
:return:
"""
array = sorted([95, 95, 96, 95, 97, 93, 94, 95, 96, 94])
"""93 94 94 95 95 95 95 96 96 97"""
n = len(array)
location_10 = (n - 1) * 0.1
i = int(location_10)
j = (round(location_10, 1) - i)
percentage10 = (1 - j) * array[i] + j * array[i + 1]
location_50 = (n - 1) * 0.5
i = int(location_50)
j = (round(location_50, 1) - i)
percentage50 = (1 - j) * array[i] + j * array[i + 1]
location_90 = (n - 1) * 0.9
i = int(location_90)
j = (round(location_90, 1) - i)
percentage90 = (1 - j) * array[i] + j * array[i + 1]
print(percentage10, percentage50, percentage90) # 输出:(93.9, 95.0, 96.1)
def test_numpy_percentile():
"""
方式二:使用numpy库
:return: None
"""
import numpy as np
array = sorted([95, 95, 96, 95, 97, 93, 94, 95, 96, 94])
percentage10 = np.percentile(array, 10)
percentage50 = np.percentile(array, 50)
percentage90 = np.percentile(array, 90)
print(percentage10, percentage50, percentage90) # 输出:(93.9, 95.0, 96.1)
if __name__ == "__main__":
test_percentile()
test_numpy_percentile()来源:
论文标题:
A Comprehensive Survey of Regression Based Loss Functions for Time Series Forecasting
论文链接:
https://arxiv.org/abs/2211.02989
代码链接:
https://github.com/aryan-jadon/Regression-Loss-Functions-in-Time-Series-Forecasting-Tensorflow