文章目录
- 美团在KV存储squirrel优化和改进
- 在水平方向
- 1、对Gossip协议进行优化
- 在垂直扩展方面
- 1、forkless RDB数据复制优化
- 2、使用多线程,充分利用机器的多核能力
- 在高可用方面
- 美团持久化kv存储celler优化和改进
- 水平扩展优化
- 1、使用bulkload进行数据导入
- 2、线程模型调度优化
- 知识点解释
- 1、对于哨兵架构的redis虽然也使用一致性hash进行扩所容,但为什么有可能在扩缩容导致数据丢失?
- 2、为什么对于kv存储服务,当集群数量达到一定规模之后,再水平扩容会遇到哪些问题,如何解决?
- 3、mget操作在大集群中可能会有木桶效应,如何解决?
- 4、什么是Gossip协议,应用场景和优缺点分别是什么?
- Reference
美团在Redis Cluster和阿里的开源项目Tair基础上,分别自研开发了Squirrel和Celler两款KV存储系统。Squirrel全内存、高吞吐和低延迟,适合业务的数据量小,对延迟敏感,建议用 Squirrel ;Celler持久化、大容量、数据高可靠,适合数据量大,对延迟不是特别敏感,成本更低的Cellar 。
美团在KV存储squirrel优化和改进
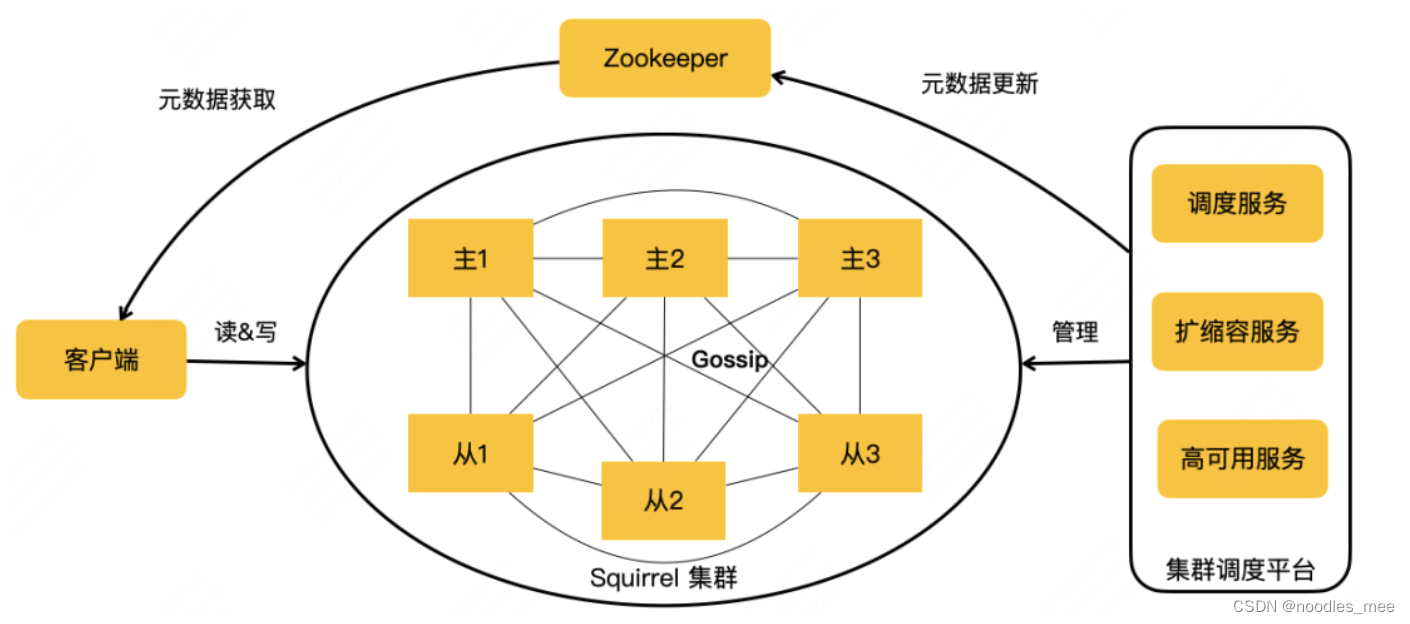
KV存储主要的两个问题是,数据量增后的扩张性和随着节点增加后的可用性如何保证。squrriel分别在水平方向扩展和垂直方向扩展优化。
在水平方向
1、对Gossip协议进行优化
使用markle tree 对每个节点的数据进行摘要,将集群中Gossip协议通信传输数据量减少了90%以上。同时使用单独的心跳线程更新拓扑结构元数据,对于工作线程只对拓扑元数据进行读,可以做到无锁读,gosssip的请求处理对业务请求完全没有影响。
在垂直扩展方面
1、forkless RDB数据复制优化
Redis在的RDB过程中是通过系统的fork()函数创建一个子进程,创建的子进程拥有和父进程相同的资源和数据(系统的copy on write思想),然后让子进程对拥有的内存数据进行持久化。fork过程非常快,通常在秒级别完成,但对于一个通常几十毫秒KV系统来说也是影响很大的,尤其要求响应非常高的系统往往也是不可以接受。forkless 不需要创建子进程,使用工作线程将每次数据变成写到一个持久化队列里面,实时同步对数据的变更,相比fork好处是,即使在RDB过程中,也不会阻塞工作线程,但如果变更数据很多时,需要占用工作工作线程时间,如果有大kv需要复制,可能也会造成单个用户请求耗时增加。
2、使用多线程,充分利用机器的多核能力
squirrle的多线程方案吞吐比社区IO的多线程提升70%,相比社区单线程提升3倍多,具体原因没有太理解。
在高可用方面
多机房部署进行融灾,但为了降低多机房部署维护的难度,并同时实现为存活节点过半选主过程,增加不存储数据的见证节点单独部署在一个机房。对于跨地域容灾,使用双向数据同步,对数据双向同步遇到的循环复制和数据冲突问题,分别使用同步数据带上clusterId和基于时间戳的last write win策略进行解决。
美团持久化kv存储celler优化和改进
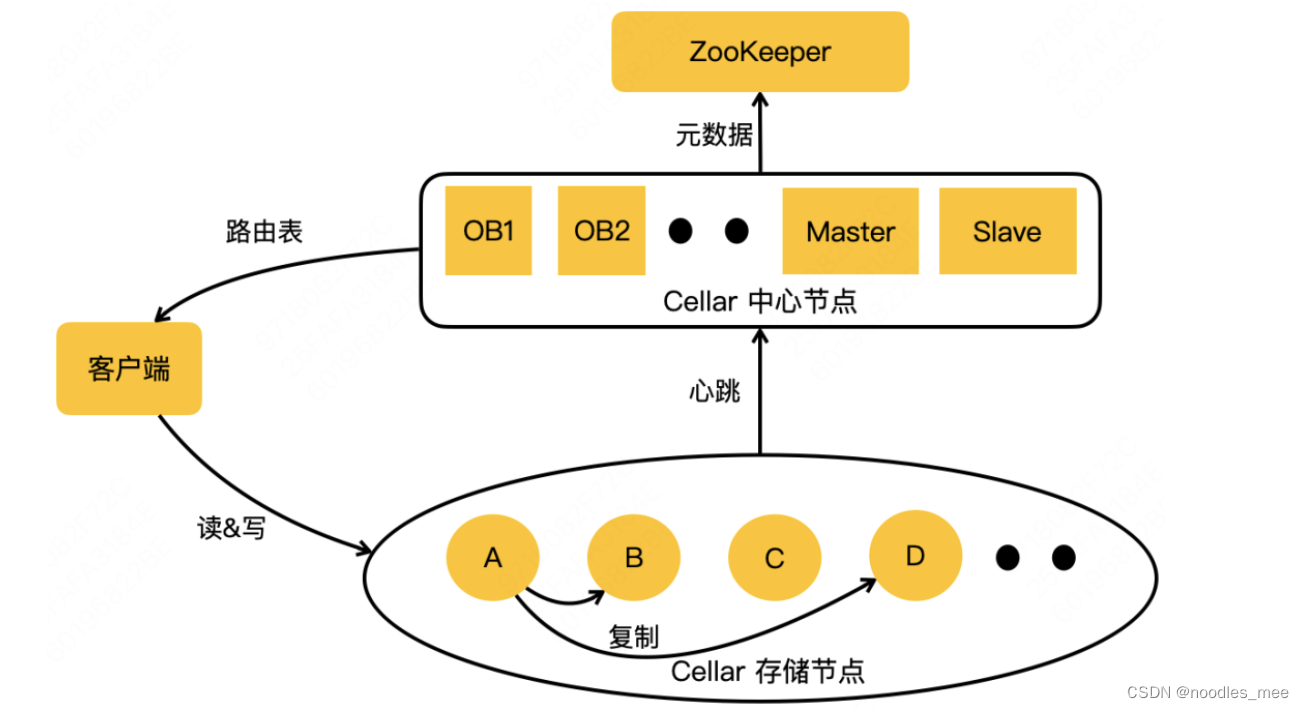
OB:只提供客户端集群节点元数据查询功能,可以水平扩展
ZooKeeper:分布式仲裁
Master:集群节点的管理
Slave:Master自己点,做容灾
kv存储希结构本身比较简单,基于内存的读写实现存储系统的高效性是kv系统设计的其中一个初衷原因,基于内存的存储系统受限于存储断电的丢失性和内存有限性,在有些场景,需要同时兼顾安全性、数据量和高效性。通过一定策略将热点数据缓存到内存中,将冷数据持久化到磁盘中,可以兼顾高效性和安全性。首先celler使用中心化方式进行集群管理和节点间数据同步,节点之间不用使用gossip进行通信,每个节点向管理中心发送心跳,理论上不存在水平扩展问题。但对单个节点来说,却存在水平扩展的问题。
水平扩展优化
1、使用bulkload进行数据导入
Celler是基于LSM-tree进行数据导入,存在写入放大的问题,为了解决这个问题,先将客户端数据使用对象存储(因为是直接从本地传输数据到对象存储服务器,突然理解为什么平时公司为什么对大数据问题,让客户端做数据的上传,然后只上传文件地址给服务端),将存储地址从客户端发送给服务器,服务器根据地址从对象存储服务器中获取数据,避免客户端网络不稳定可能导致的大数据传输失败问题。
2、线程模型调度优化
为了隔离开离线请求、快慢请求,使用四个队列和四个线程池分别处理,分别处理读快、读慢和写快写慢四种请求,保证对核心请求处理的效率。
知识点解释
1、对于哨兵架构的redis虽然也使用一致性hash进行扩所容,但为什么有可能在扩缩容导致数据丢失?
哨兵架构主要是为了保证高可用,但一个节点宕机,快速选择新的节点作为主节点。扩缩容主要有数据重分配和数据迁移过程中数据一致性问题,一致性hash只能减少扩缩容时数据迁移量,并不能保证数据迁移过程中一致性问题。数据迁移过程中,除了网络问题,如果迁移过程没有被正确管理,比如迁移过程中旧数据的更新并没有同步到新节点,会造成数据丢失。
2、为什么对于kv存储服务,当集群数量达到一定规模之后,再水平扩容会遇到哪些问题,如何解决?
管理复杂度增加,大规模节点中发现有问题的节点更加困难,更难保证数据的负载均衡;性能问题,集群节点内数据通信增加,网络宽带可能成为瓶颈,客户端访问数据分布在不同节点上,导致整体延时增加;数据一致性,在多个解节点维持事物的ACID更加困难,达到最终一致性延迟增高。其中一个有效解决方案是集群分区,根据业务场景,将数据划分到不同集群。
3、mget操作在大集群中可能会有木桶效应,如何解决?
mget是可以一次批量获取多个key的值。在大集群中,第一、节点数据可能分布不均匀,一致性hash只可以相对均匀维持数据的分布均匀;第二,节点性能差异,每个节点硬件、网络都会有差异,批量查询时,整个结果响应耗时以最差节点返回结果为准;第三,网络延迟的增加,如果同时请求多个数据中心的数据,整个查询延时会增加。针对这三个主要问题,可以定期重新分布数据;所有节点尽量使用相同的硬件和网络,对于热点key进行多副本处理或者升级硬件提升机器性能;减小单次mget查询的数据量,对于可以预测的热点key单独请求,缩短单次查询的耗时。
4、什么是Gossip协议,应用场景和优缺点分别是什么?
Gossip协议是分布式环境中节点之间信息交换的算法,使用过程要考虑如何避免循环传递,例如使用版本号和时间戳,分布式Id或者设置生存时间。工作原理,每个节点定期与周围节点交换信息,信息交换可以是单向,也可以是双向,每次选择交换节点事随机选取的,每次交换信息后会更新自身信息,并将更新信息在后续交换中传播。优点、去中心化,扩展性强,因为每次只用和部分节点进行交换,即使在大的分布式环境中依然可以使用,容错性高,即使某个节点出现故障,整个集群的消息依然可以保持正常交流。缺点、第一、冗余通信,同一个节点同一个更新信息,可能被通知多次;第二,全局达到一致性的时间会更长,由于每一轮只通知n个节点,过了一个周期后才会选择n个节点通知,需要经过多个周期之后,才有可能达到整个集群的一致性;第三、可能有些有些信息在某些节点不会被通知到,可以通过改进节点选择算法,或者调整更新频率或者范围(偶尔进行一次全局广播)。
Reference
美团大规模KV存储挑战与架构实践












![[C++基础学习-06]----C++指针详解](https://img-blog.csdnimg.cn/direct/ba7d3d958bb0454794ba1e37da3ef71f.png)