热帖排行
不同的算分方式:

只存变化的帖子到redis中,每五分钟算一次分,定时任务
存redis
构建redis键
//统计帖子分数
//key:post:score -> value:postId
public static String getPostScoreKey() {
return PREFIX_POST + SPLIT + "score";
}
添加帖子时
// 计算帖子分数
String redisKey = RedisKeyUtil.getPostScoreKey();
redisTemplate.opsForSet().add(redisKey, post.getId());
加精时
@RequestMapping(path = "/wonderful", method = RequestMethod.POST)
@ResponseBody
public String setWonderful(int id) {
//加精是改status
discussPostService.updateStatus(id, 1);
//触发发帖事件,将帖子存入es服务器
Event event = new Event()
.setTopic(TOPIC_PUBLISH)
.setUserId(hostHolder.getUser().getId())
.setEntityType(ENTITY_TYPE_POST)
.setEntityId(id);
eventProducer.fireEvent(event);
// 计算帖子分数
String redisKey = RedisKeyUtil.getPostScoreKey();
redisTemplate.opsForSet().add(redisKey, id);
return CommunityUtil.getJsonString(0);
}
评论时
//触发发帖时间,存到es服务器
if(comment.getEntityType() == ENTITY_TYPE_POST) {
event = new Event()
.setTopic(TOPIC_PUBLISH)
.setUserId(comment.getUserId())
.setEntityType(ENTITY_TYPE_POST)
.setEntityId(discussPostId);
eventProducer.fireEvent(event);
// 计算帖子分数
String redisKey = RedisKeyUtil.getPostScoreKey();
redisTemplate.opsForSet().add(redisKey, discussPostId);
}
点赞时
if(entityType == ENTITY_TYPE_POST){
//计算帖子分数
String redisKey = RedisKeyUtil.getPostScoreKey();
redisTemplate.opsForSet().add(redisKey, postId);
}
设置定时任务
定时任务类:
public class PostScoreRefreshJob implements Job, CommunityConstant {
private static final Logger logger = LoggerFactory.getLogger(PostScoreRefreshJob.class);
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private DiscussPostService discussPostService;
@Autowired
private LikeService likeService;
@Autowired
private ElasticsearchService elasticsearchService;
// 牛客纪元
private static final Date epoch;
static {
try {
epoch = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").parse("2021-08-01 00:00:00");
} catch (ParseException e) {
throw new RuntimeException("初始化日期失败!", e);
}
}
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException{
String redisKey = RedisKeyUtil.getPostScoreKey();
BoundSetOperations operations = redisTemplate.boundSetOps(redisKey);
if (operations.size() == 0) {
logger.info("[任务取消] 没有需要刷新的帖子!");
return;
}
logger.info("[任务开始] 正在刷新帖子分数: " + operations.size());
while (operations.size() > 0) {
this.refresh((Integer) operations.pop());
}
logger.info("[任务结束] 帖子分数刷新完毕!");
}
private void refresh(int postId) {
// 查询帖子
DiscussPost post = discussPostService.findDiscussPostById(postId);
if (post == null) {
logger.error("该帖子不存在: id = " + postId);
return;
}
// 是否精华
boolean wonderful = post.getStatus() == 1;
// 评论数量
int commentCount = post.getCommentCount();
// 点赞数量
long likeCount = likeService.findEntityLikeCount(ENTITY_TYPE_POST, postId);
// 计算权重
double w = (wonderful ? 75 : 0) + commentCount * 10 + likeCount * 2;
// 分数 = 帖子权重 + 距离天数(天数越大,分数越低)
//Math.max(w, 1) 防止分数为负数
//秒->天
double score = Math.log10(Math.max(w, 1))
+ (post.getCreateTime().getTime() - epoch.getTime()) / (1000 * 3600 * 24);
// 更新帖子分数
discussPostService.updateScore(postId, score);
// 同步es的搜索数据
post.setScore(score);
elasticsearchService.saveDiscussPost(post);
}
}
配置Quartz任务
//刷新帖子分数的任务
@Bean
public JobDetailFactoryBean postScoreRefreshJobDetail() {
JobDetailFactoryBean factoryBean = new JobDetailFactoryBean();
factoryBean.setJobClass(PostScoreRefreshJob.class);
factoryBean.setName("postScoreRefreshJob");
factoryBean.setGroup("communityJobGroup");
// 是否持久保存
factoryBean.setDurability(true);
factoryBean.setRequestsRecovery(true);
return factoryBean;
}
//刷新帖子分数的触发器
@Bean
public SimpleTriggerFactoryBean postScoreRefreshTrigger(JobDetail postScoreRefreshJobDetail) {
SimpleTriggerFactoryBean factoryBean = new SimpleTriggerFactoryBean();
factoryBean.setJobDetail(postScoreRefreshJobDetail);
factoryBean.setName("postScoreRefreshTrigger");
factoryBean.setGroup("communityTriggerGroup");
// 5分钟刷新一次
factoryBean.setRepeatInterval(1000 * 60 * 5);
factoryBean.setJobDataMap(new JobDataMap());
return factoryBean;
}
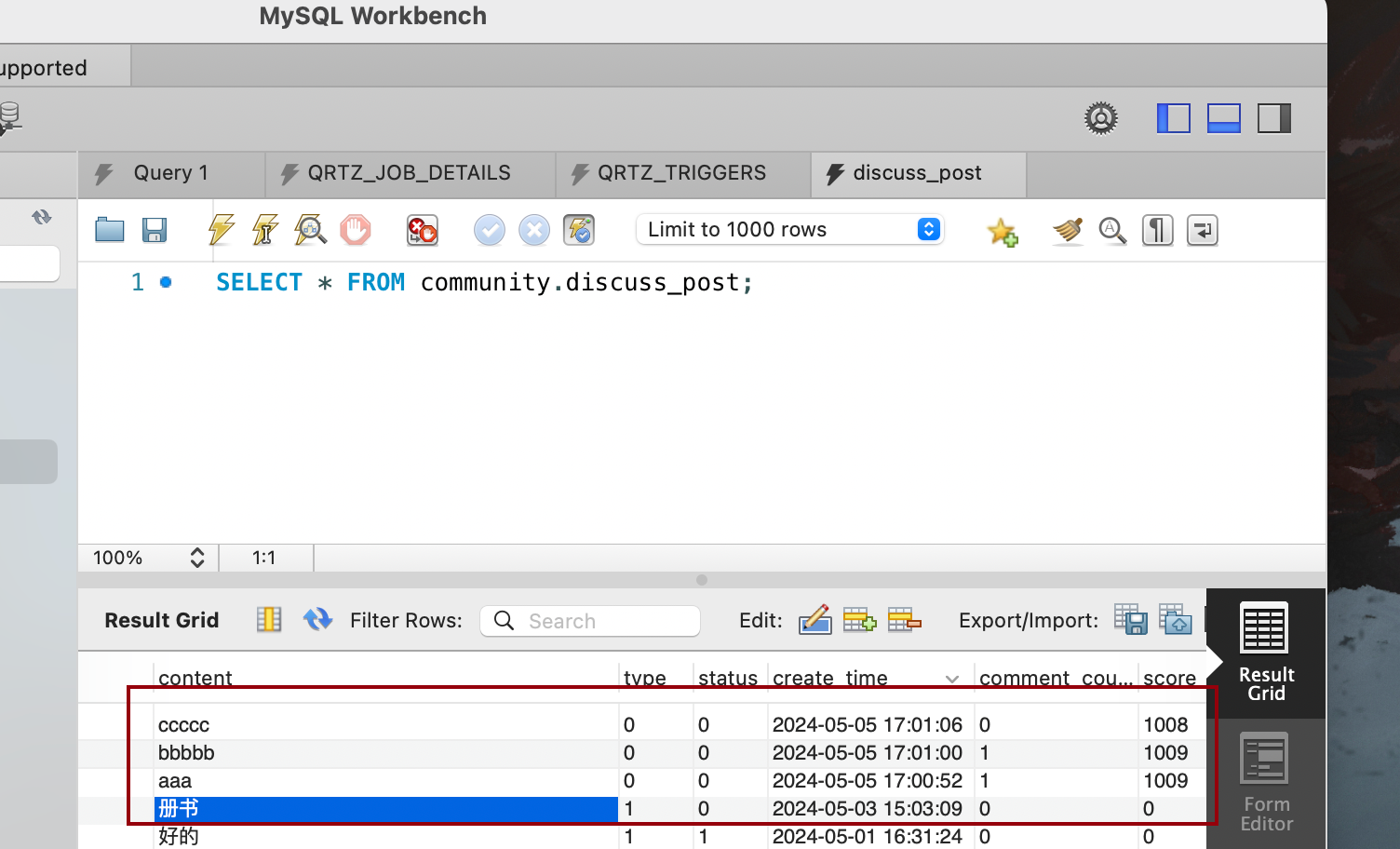
在首页按时间和分数展现
之前的mapper默认按时间排,现在修改成两种模式,0安时间排,1按得分排
@Mapper
public interface DiscussPostMapper {
//userId为0时,表示查询所有用户的帖子,如果不为0,表示查询指定用户的帖子
//offset表示起始行号,limit表示每页最多显示的行数
//orderMode表示排序模式,0-默认排序,1-按热度排序
List<DiscussPost> selectDiscussPosts(int userId, int offset, int limit, int orderMode);
//查询帖子的行数
//userId为0时,表示查询所有用户的帖子
int selectDiscussPostRows(@Param("userId") int userId);
//@param注解用于给参数取别名,拼到sql语句中,如果只有一个参数,并且在<if>标签里,则必须加别名
int insertDiscussPost(DiscussPost discussPost);
DiscussPost selectDiscussPostById(int id);
//根据id查询帖子
int updateCommentCount(int id, int commentCount);
//修改帖子类型
int updateType(int id, int type);
//修改帖子状态
int updateStatus(int id, int status);
//修改帖子分数
int updateScore(int id, double score);
}
修改xml:
<select id="selectDiscussPosts" resultType="DiscussPost">
select
<include refid="selectFields"></include>
from discuss_post
where status != 2
<if test="userId != 0">
and user_id = #{userId}
</if>
<if test="orderMode == 0">
order by type desc, create_time desc
</if>
<if test="orderMode == 1">
order by type desc, score desc, create_time desc
</if>
limit #{offset}, #{limit}
</select>
重构service:
public List<DiscussPost> findDiscussPosts(int userId, int offset, int limit, int orderMode) {
return discussPostMapper.selectDiscussPosts(userId, offset, limit, orderMode);
}
重构homeController(传入orderMode)
package com.newcoder.community.controller;
import com.newcoder.community.entity.DiscussPost;
import com.newcoder.community.entity.Page;
import com.newcoder.community.service.DiscussPostService;
import com.newcoder.community.service.LikeService;
import com.newcoder.community.service.UserService;
import com.newcoder.community.util.CommunityConstant;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RequestParam;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Controller
public class HomeController implements CommunityConstant {
@Autowired
private UserService userService;
@Autowired
private DiscussPostService discussPostService;
@Autowired
private LikeService likeService;
@RequestMapping(path = "/index", method = RequestMethod.GET)
public String getIndexPage(Model model, Page page, @RequestParam(name="orderMode", defaultValue = "0") int orderMode) {
//方法调用前,Spring会自动把page注入给model,所以html中可以直接访问page的数据。
//先查前10个帖子
page.setRows(discussPostService.findDiscussPostRows( 0));
page.setPath("/index?orderMode=" + orderMode);
List<DiscussPost> list = discussPostService.findDiscussPosts(0,page.getOffset(), page.getLimit(), orderMode);
List<Map<String, Object>> discussPosts = new ArrayList<>();
if(list != null) {
for (DiscussPost post : list) {
Map<String, Object> map = new java.util.HashMap<>();
map.put("post", post);
map.put("user", userService.findUserById(post.getUserId()));
//查询帖子的点赞数量
long likeCount = likeService.findEntityLikeCount(ENTITY_TYPE_POST, post.getId());
map.put("likeCount", likeCount);
discussPosts.add(map);
}
}
model.addAttribute("discussPosts", discussPosts);
model.addAttribute("orderMode", orderMode);
return "/index";
}
@RequestMapping(path = "/error", method = RequestMethod.GET)
public String getErrorPage() {
return "/error/500";
}
// 没有权限时的页面
@RequestMapping(path = "/denied", method = RequestMethod.GET)
public String getDeniedPage() {
return "/error/404";
}
}
- @RequestParam注解,参数通过request请求传过来,有默认值。
修改index.html
<!-- 筛选条件 -->
<ul class="nav nav-tabs mb-3">
<li class="nav-item">
<a th:class="|nav-link ${orderMode==0?'active':''}|" th:href="@{/index(orderMode=0)}">最新</a>
</li>
<li class="nav-item">
<a th:class="|nav-link ${orderMode==1?'active':''}|" th:href="@{/index(orderMode=1)}">热门</a>
</li>
</ul>
生成长图(Deprecated)

wkhtmltopdf
将文件上传到云服务器(Deprecated)
上面上一步的长图,工具没调试好,因此也不用。
优化热门帖子列表
缓存:适用于不经常更新的数据(更新缓存不频繁)

(避免直接访问数据库,Redis可跨服务器)
多级缓存-redis
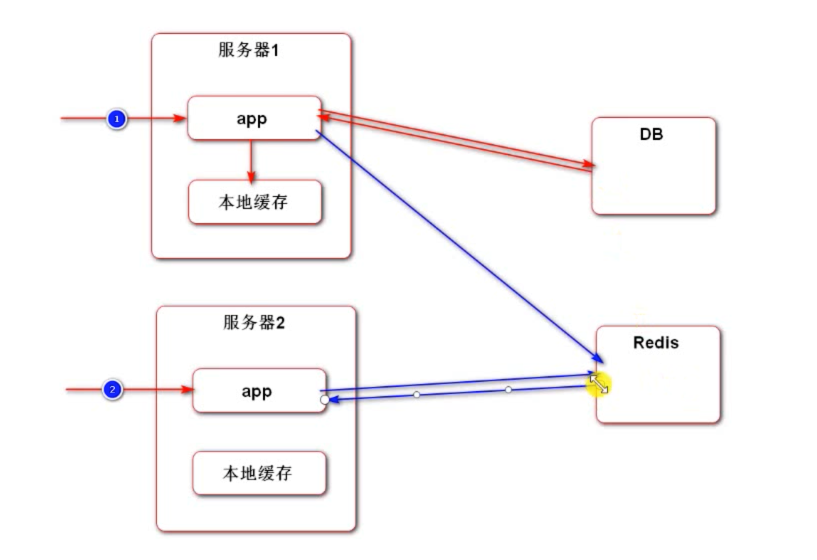
缓存详细的调用过程:
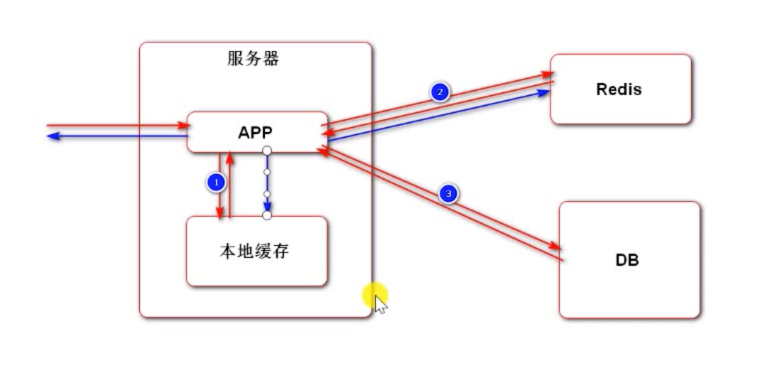
(本地缓存→ redis→ 数据库)
导入依赖
使用Caffeine进行本地缓存
<!-- https://mvnrepository.com/artifact/com.github.ben-manes.caffeine/caffeine -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
设置参数
# CaffeineProperties
caffeine.posts.max-size=15
caffeine.posts.expire-seconds=180
在业务层注入:
@Value("${caffeine.posts.max-size}")
private int maxSize;
@Value("${caffeine.posts.expire-seconds}")
private int expireSeconds;
修改DiscussPostService
配置缓存
//帖子列表缓存
private LoadingCache<String, List<DiscussPost>> postListCache;
//帖子总数缓存
private LoadingCache<Integer, Integer> postRowsCache;
缓存写
在构造函数执行之前:
@PostConstruct
public void init() {
//初始化帖子列表缓存
postListCache = Caffeine.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(expireSeconds, TimeUnit.SECONDS)
.build(new CacheLoader<String, List<DiscussPost>>() {
@Override
public @Nullable List<DiscussPost> load(String key) throws Exception {
if (key == null || key.length() == 0)
throw new IllegalArgumentException("参数错误!");
String[] params = key.split(":");
if (params == null || params.length != 2)
throw new IllegalArgumentException("参数错误!");
int offset = Integer.valueOf(params[0]);
int limit = Integer.valueOf(params[1]);
//TODO: 二级缓存:Redis -> mysql
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPosts(0, offset, limit, 1);
}
}
);
//初始化帖子总数缓存
postRowsCache = Caffeine.newBuilder()
.maximumSize(maxSize)
.expireAfterWrite(expireSeconds, TimeUnit.SECONDS)
.build(new CacheLoader<Integer, Integer>() {
@Override
public @Nullable Integer load(Integer integer) throws Exception {
logger.debug("load post rows from DB.");
return discussPostMapper.selectDiscussPostRows(0);
}
});
}
缓存读
public List<DiscussPost> findDiscussPosts(int userId, int offset, int limit, int orderMode) {
//只有首页按照热门排序才会缓存
//key是offset:limit
//get方法是从缓存中取数据
if (userId == 0 && orderMode == 1) {
return postListCache.get(offset + ":" + limit);
}
//不缓存
logger.debug("load post list from DB.");
return discussPostMapper.selectDiscussPosts(userId, offset, limit, orderMode);
}
public int findDiscussPostRows(int userId) {
if (userId == 0) {
return postRowsCache.get(userId);
}
//不缓存
logger.debug("load post rows from DB.");
return discussPostMapper.selectDiscussPostRows(userId);
}
首先在测试类中创建函数插入100000w条帖子:
//创建10w条数据进行压力测试
@Test
public void initDataForTest() {
for(int i = 0; i < 100000; i++) {
DiscussPost post = new DiscussPost();
post.setUserId(111);
post.setTitle("互联网寒冬");
post.setContent("今年的互联网寒冬真是太冷了。");
post.setCreateTime(new Date());
post.setScore(Math.random() * 2000);
discussPostService.addDiscussPost(post);
}
}
测试代码
@Test
public void testCache() {
//第一次查询,应该从数据库中查
System.out.println(discussPostService.findDiscussPosts(0, 0, 10, 1));
//第二次查询,应该从缓存中查
System.out.println(discussPostService.findDiscussPosts(0, 0, 10, 1));
//第三次查询,应该从缓存中查
System.out.println(discussPostService.findDiscussPosts(0, 0, 10, 1));
//第三次查询,应该从数据库中查
System.out.println(discussPostService.findDiscussPosts(0, 0, 10, 0));
}
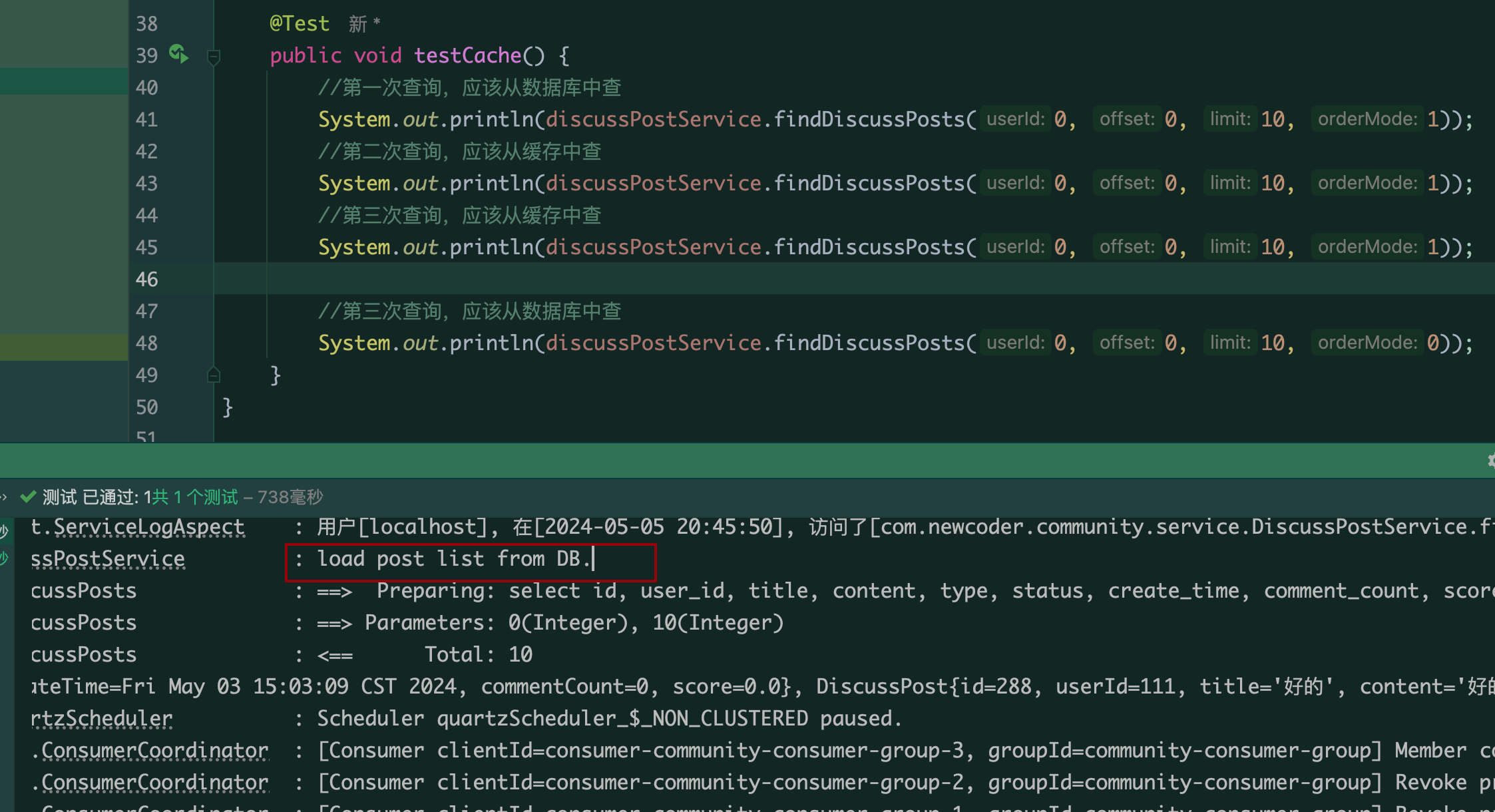
(前三次查询,日志只打印了一次,说明只差了一次数据库)
压力测试
使用JMeter进行测试,下载地址:
https://jmeter.apache.org/download_jmeter.cgi
下载后到bin目录下,运行
sh jmeter.sh
出来GUI界面,依次配置测试计划、线程组、HTTP请求,在聚合报告里看:
不加缓存
注释掉ServiceLogAspect的注解,可以干净日志
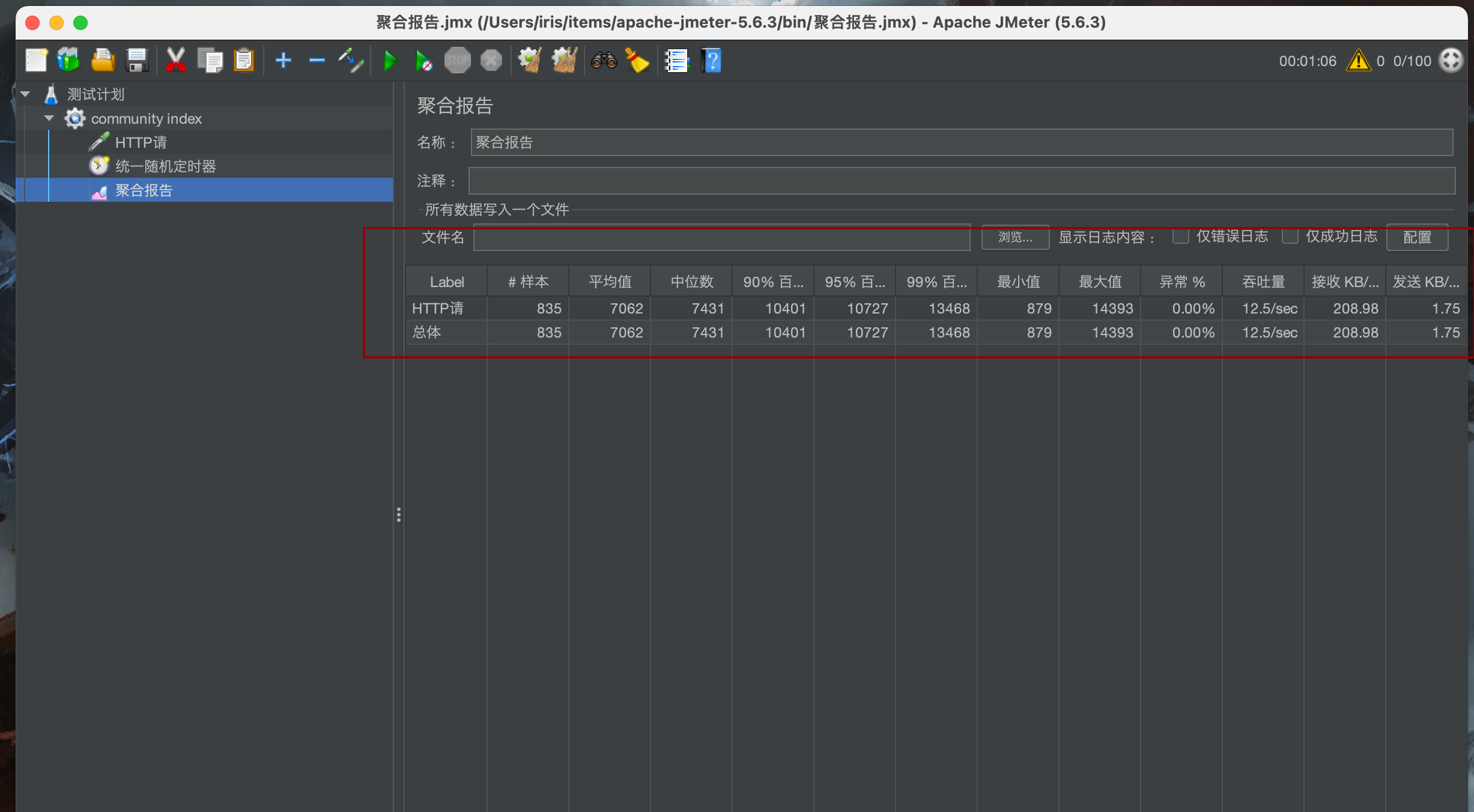
100个线程,吞吐量约12.5
加缓存
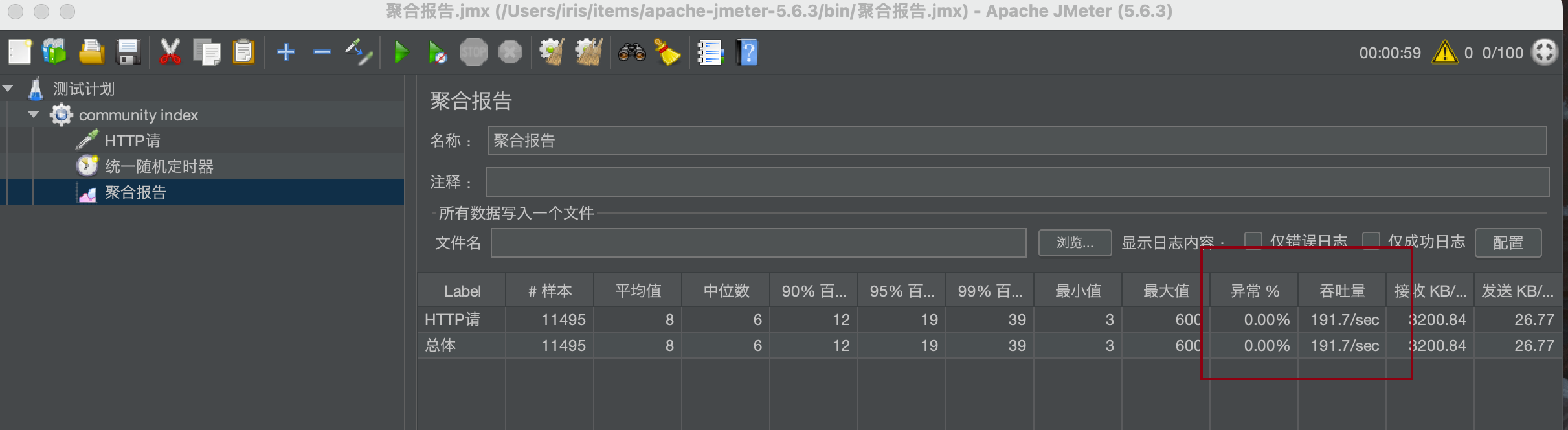
直接191.7,增加了十几倍










![[C++基础学习-06]----C++指针详解](https://img-blog.csdnimg.cn/direct/ba7d3d958bb0454794ba1e37da3ef71f.png)