精简版:经过一些profile发现flash-linear-attention中的rwkv6 linear attention算子的表现比RWKV-CUDA中的实现性能还要更好,然后也看到了继续优化triton版本kernel的线索。接着还分析了一下rwkv6 cuda kernel的几次开发迭代以此说明对于不懂cuda以及平时无法从擅长cuda的大佬身上取经的人比如我就完全放弃cuda了,可以深入学一下和使用triton,这已经完全足够了(除了会写之外还可以了解内部的MLIR相关的编译器知识,可以对GPU体系架构理解得更加深刻)。
0x0. 前言
本文主要讲一些看到的RWKV 6模型的Linear Attention模块推理加速方法,在这篇博客中暂不涉及对kernel的深入解析。首先,flash-linear-attention(https://github.com/sustcsonglin/flash-linear-attention )这个仓库旨在对各种线性Attention架构进行工程加速,例如RetNet,GLA,Manba,RWKV6(2024年4月引入)。它使用Triton来编写代码,并针对不同的线性Transformer架构使用不同的优化方式。例如对于RWKV 6就采用在时间维度进行kernel fuse的方式来加速。其次,RWKV-CUDA是RWKV系列模型迭代中针对Linear Attention模块的改进开发的自定义高性能cuda kernel(https://github.com/BlinkDL/RWKV-CUDA)。flash-rwkv(https://github.com/BBuf/flash-rwkv)仓库在RWKV-CUDA的最优性能算子的基础上进行了封装,提供了rwkv5_cuda_linear_attention和rwkv6_cuda_linear_attention两个接口方便在HuggingFace模型实现中直接加速推理的prefill阶段速度。
本篇文章主要会对比一下RWKV6 Linear Attention模块的naive实现(pure pytorch),RWKV-CUDA的RWKV6 Linear Attention cuda kernel实现(用flash-rwkv提供的接口进行测试),flash-linear-attention里的RWKV6 Linear Attention实现。来说明Triton已经成为目前LLM时代开发的一个趋势,小伙伴们确实可以学起来。目前我对Triton的了解也非常少而且很肤浅,后续也会持续学习和实践。
下面列举本文相关的资料,如果你想对RWKV 6这个架构有一些了解可以阅读后面三个链接,当然不阅读也不影响阅读本文:
- https://github.com/sustcsonglin/flash-linear-attention
- https://mp.weixin.qq.com/s/Vol_LeHVHDAwE1pWTHOl2Q
- 梳理RWKV 4,5(Eagle),6(Finch)架构的区别以及个人理解和建议
- RWKV 模型保姆级微调教程
另外,本文使用了PyTorch Profiler TensorBoard 插件来做程序的性能分析,感兴趣的小伙伴可以在系统调优助手,PyTorch Profiler TensorBoard 插件教程 获取到详细的教程。
0x1. 瓶颈是什么
RWKV6 推理 Prefill 阶段的性能瓶颈就在于RWKV6模型代码中的rwkv6_linear_attention_cpu函数:https://huggingface.co/RWKV/rwkv-6-world-1b6/blob/main/modeling_rwkv6.py#L54-L104
def rwkv6_linear_attention(
training,
receptance,
key,
value,
time_decay,
time_first,
state,
):
no_cuda = any(t.device.type != "cuda" for t in [time_decay, time_first, receptance, key, value])
# Launching the CUDA kernel for just one token will actually be slower (there is no for loop in the CPU version
# in this case).
one_token = key.size(1) == 1
if no_cuda or one_token:
return rwkv6_linear_attention_cpu(
receptance, key, value, time_decay, time_first, state
)
else:
...
这里的判断是如果是decode阶段(对比prefill阶段)或者非GPU模式执行代码,就使用rwkv6_linear_attention_cpu这个算子,否则就使用优化后的实现比如使用这里的cuda kernel(https://github.com/BlinkDL/RWKV-CUDA/tree/main/wkv6)编译出的CUDA Kernel。flash-linear-attention库的目的是使用Triton来加速rwkv6_linear_attention_cpu这个naive的实现。这个naive实现的代码如下:
def hf_rwkv6_linear_attention_cpu(receptance, key, value, time_decay, time_first, state):
# For CPU fallback. Will be slower and probably take more memory than the custom CUDA kernel if not executed
# within a torch.no_grad.
batch, seq_length, _ = receptance.shape
num_heads, head_size = time_first.shape
key = key.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2).transpose(-2, -1) # b, t, h, n -> b, h, t, n -> b, h, n, t
value = value.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2) # b, t, h, n -> b, h, t, n
receptance = receptance.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2) # b, t, h, n -> b, h, t, n
time_decay = torch.exp(-torch.exp(time_decay.float())).view(batch, seq_length, num_heads, head_size).permute(0, 2, 3, 1) # b, t, h, n -> b, h, n, t
time_first = time_first.float().reshape(-1, 1, 1).reshape(num_heads, -1, 1) # h, n -> h * n, 1, 1 -> h, n, 1
out = torch.zeros_like(key).reshape(batch, seq_length, num_heads, head_size)
for current_index in range(seq_length):
current_receptance = receptance[:, :, current_index:current_index+1, :]
current_key = key[:, :, :, current_index:current_index+1]
current_value = value[:, :, current_index:current_index+1, :]
current_time_decay = time_decay[:, :, :, current_index:current_index+1]
attention_output = current_key @ current_value
out[:, current_index] = (current_receptance @ (time_first * attention_output + state)).squeeze(2)
with torch.no_grad():
# attention_output.shape: [b, h, n, 1] x [b, h, 1, n] -> [b, h, n, n]
# current_time_decay * state: [b, h, n, 1] * [b, h, n, n] ->[b, h, n, n]
# state.shape: [b, h, n, n]
state = attention_output + current_time_decay * state
return out, state
这样看代码可能会有点懵,可以看下一节的完整demo测试代码。
0x2. Profile代码编写
上一节明确了,我们需要加速RWKV模型中rwkv6_linear_attention_cpu的计算,https://github.com/sustcsonglin/flash-linear-attention 这个库在2024年4月份支持了RWKV6模型,它加速RWKV 6 Linear Attention计算的核心api有两个,fused_recurrent_rwkv6和chunk_rwkv6。现在直接写出profile的代码(https://github.com/BBuf/flash-rwkv/blob/main/profile/profile_rwkv6_linear_attention.py)来对naive的实现,RWKV官方提供的cuda kernel以及fused_recurrent_rwkv6和chunk_rwkv6进行性能分析。
import sys
import torch
from fla.ops.rwkv6.chunk import chunk_rwkv6
from fla.ops.rwkv6.recurrent_fuse import fused_recurrent_rwkv6
from flash_rwkv import rwkv6_cuda_linear_attention
def hf_rwkv6_linear_attention_cpu(receptance, key, value, time_decay, time_first, state):
# For CPU fallback. Will be slower and probably take more memory than the custom CUDA kernel if not executed
# within a torch.no_grad.
batch, seq_length, _ = receptance.shape
num_heads, head_size = time_first.shape
key = key.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2).transpose(-2, -1)
value = value.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2)
receptance = receptance.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2)
time_decay = torch.exp(-torch.exp(time_decay.float())).view(batch, seq_length, num_heads, head_size).permute(0, 2, 3, 1)
time_first = time_first.float().reshape(-1, 1, 1).reshape(num_heads, -1, 1)
out = torch.zeros_like(key).reshape(batch, seq_length, num_heads, head_size)
for current_index in range(seq_length):
current_receptance = receptance[:, :, current_index:current_index+1, :]
current_key = key[:, :, :, current_index:current_index+1]
current_value = value[:, :, current_index:current_index+1, :]
current_time_decay = time_decay[:, :, :, current_index:current_index+1]
attention_output = current_key @ current_value
out[:, current_index] = (current_receptance @ (time_first * attention_output + state)).squeeze(2)
with torch.no_grad():
state = attention_output + current_time_decay * state
return out, state
if __name__ == "__main__":
mode = sys.argv[1]
B = 1
H = 32
L = 54
D = 64
HIDDEN_SIZE = H * D
dtype = torch.float32
if mode == 'hf':
profile_path = '/bbuf/rwkv_profile_result/hf/'
elif mode == 'recurrent':
profile_path = '/bbuf/rwkv_profile_result/recurrent/'
elif mode == 'chunk':
profile_path = '/bbuf/rwkv_profile_result/chunk/'
elif mode == 'cuda':
profile_path = '/bbuf/rwkv_profile_result/cuda'
else:
raise NotImplementedError
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(
wait=1,
warmup=1,
active=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler(profile_path, worker_name='worker0'),
record_shapes=True,
profile_memory=True, # This will take 1 to 2 minutes. Setting it to False could greatly speedup.
with_stack=True
) as p:
for i in range(10):
q = (torch.randn(B, L, HIDDEN_SIZE).cuda().to(torch.float16)).requires_grad_(True)
k = (torch.randn(B, L, HIDDEN_SIZE).cuda().to(torch.float16)).requires_grad_(True)
v = torch.randn(B, L, HIDDEN_SIZE).cuda().to(torch.float16).requires_grad_(True)
w = torch.nn.functional.logsigmoid(torch.randn(B, L, HIDDEN_SIZE)).cuda().to(torch.float32).requires_grad_(True)
u = (torch.randn(H, D).cuda().to(torch.float16)).requires_grad_(True)
state = (torch.randn(B, H, D, D).cuda().to(torch.float32)).requires_grad_(True)
if mode == 'hf':
o1, state1 = hf_rwkv6_linear_attention_cpu(q, k, v, w, u, state)
elif mode =='cuda':
o2, state2 = rwkv6_cuda_linear_attention(q, k, v, w, u.flatten(), state)
else:
batch, seq_length, _ = q.shape
num_heads, head_size = u.shape
k = k.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2) # B, T, H, K -> B, H, T, K
v = v.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2) # B, T, H, K - > B, H, T, V
q = q.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2) # B, H, T, K
w = -torch.exp(w.float()).view(batch, seq_length, num_heads, head_size).permute(0, 2, 1, 3) # B, T, H, K -> B, H, T, K
u = u.float().reshape(num_heads, head_size) # H, K
if mode == 'recurrent':
o3, state3 = fused_recurrent_rwkv6(q, k, v, w, u, initial_state=state, scale=1.0, output_final_state=True)
elif mode == 'chunk':
o4, state4 = chunk_rwkv6(q, k, v, w, u, initial_state=state, scale=1.0, output_final_state=True)
p.step()
这段代码就是要分别profile hf_rwkv6_linear_attention_cpu,rwkv6_cuda_linear_attention,fused_recurrent_rwkv6,chunk_rwkv6这三个api看一下它们的性能表现以及GPU kernel的详细使用情况。但这段代码中有一些需要说明的地方:
hf_rwkv6_linear_attention_cpu这个api接收的输入Tensor形状和fla包提供的两个加速api的输入Tensor形状不一样,所以在对hf_rwkv6_linear_attention_cpu设定输入之后需要经过一些维度重排操作才能给fla包的两个api使用。- 对于
time_decay来说,hf_rwkv6_linear_attention_cpu在计算时做了两次exp,而fused_recurrent_rwkv6和chunk_rwkv6的api内部会做一次exp,所以输入给fused_recurrent_rwkv6和chunk_rwkv6的time_decay只需要做内层的-exp操作就足够了。 - 对于输出来说,
fused_recurrent_rwkv6和chunk_rwkv6的结果需要转置一下才能得到和hf_rwkv6_linear_attention_cpu一样的计算结果,state不需要做额外操作,直接就可以对应上。 - 注意api的调用方式,例如
chunk_rwkv6(q, k, v, w, u, initial_state=state, scale=1.0, output_final_state=True)里面的kwargs是缺一不可的。
接下来就可以执行这个profile脚本分别得到这三个api的profile结果了。我在一张NVIDIA A800-SXM4-80GB上进行了profile,结果上传到了 https://github.com/BBuf/flash-rwkv/tree/main/profile/rwkv_profile_result ,你可以通过 tensorboard --logdir=./rwkv_profile_result/recurrent/ --bind_all 这样的命令来可视化结果,并在本地的浏览器中打开 http://localhost:6006/#pytorch_profiler 网址来查看详细的结果。
0x3. Profile结果分析
0x3.1 hf_rwkv6_linear_attention_cpu 函数profile结果
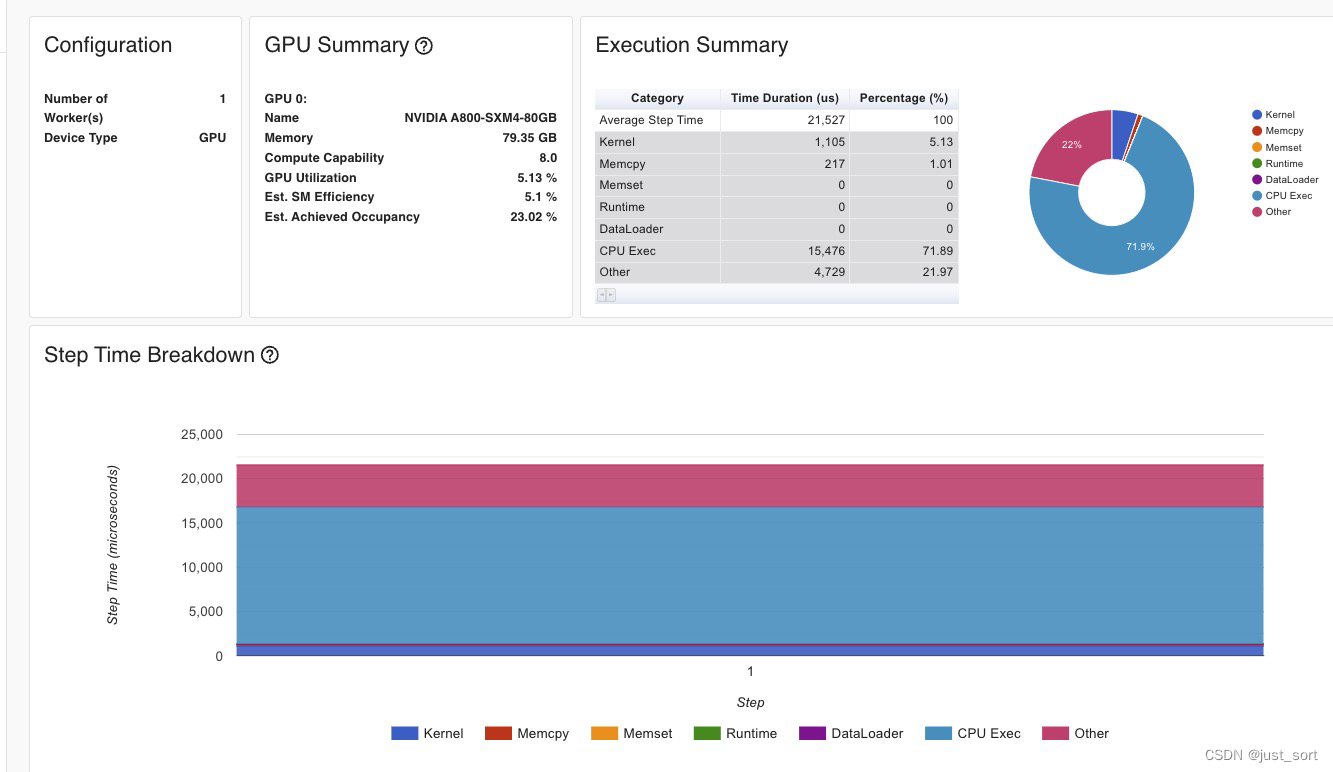
使用hf_rwkv6_linear_attention_cpu函数进行计算时Kernel部分花了1105us,算子总的时间花了21.5ms,然后它的kernel分布为:
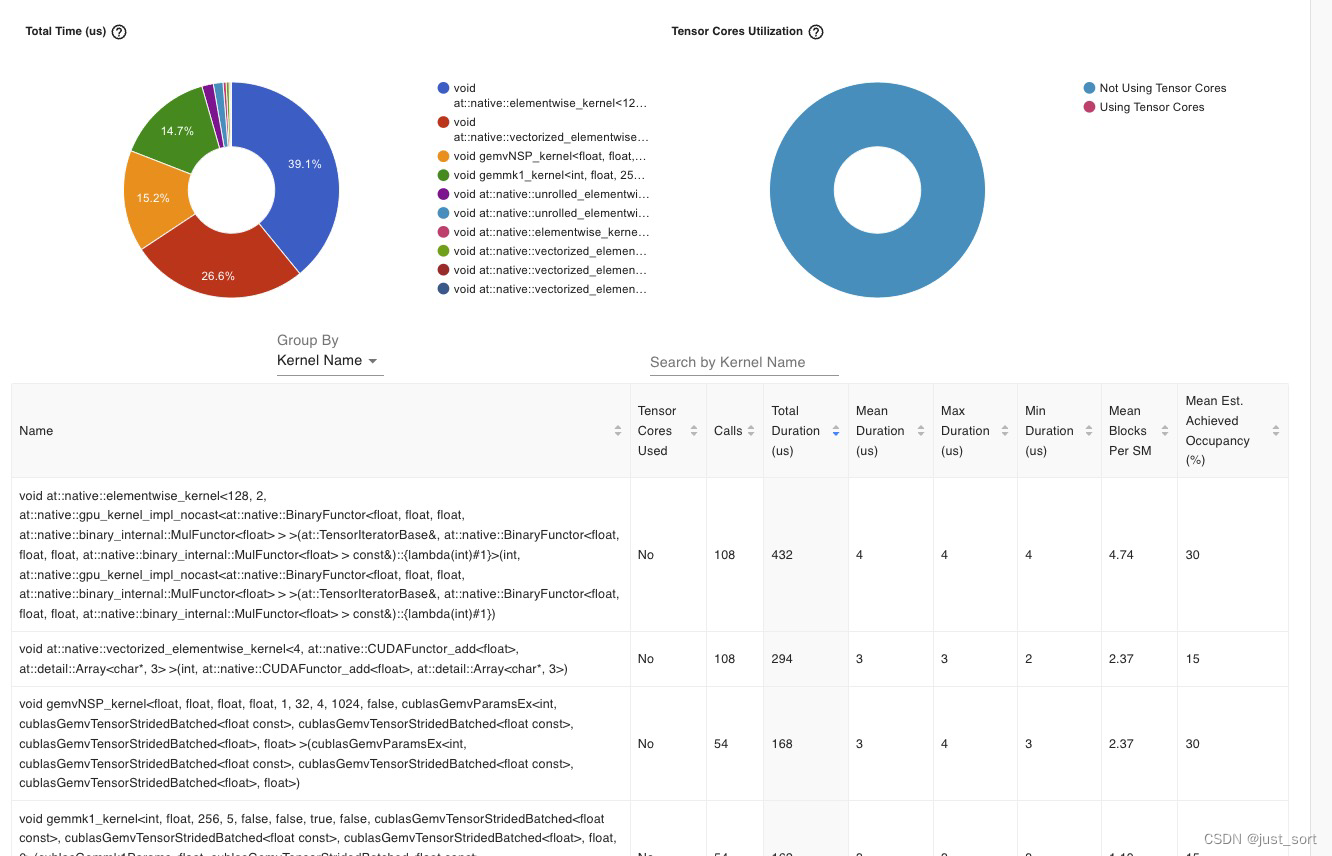 我们可以发现在kernel里面只有gemv相关的矩阵乘调用,并且elementwise算子占比非常大已经接近40%。
我们可以发现在kernel里面只有gemv相关的矩阵乘调用,并且elementwise算子占比非常大已经接近40%。
0x3.2 rwkv6_cuda_linear_attention API profile结果
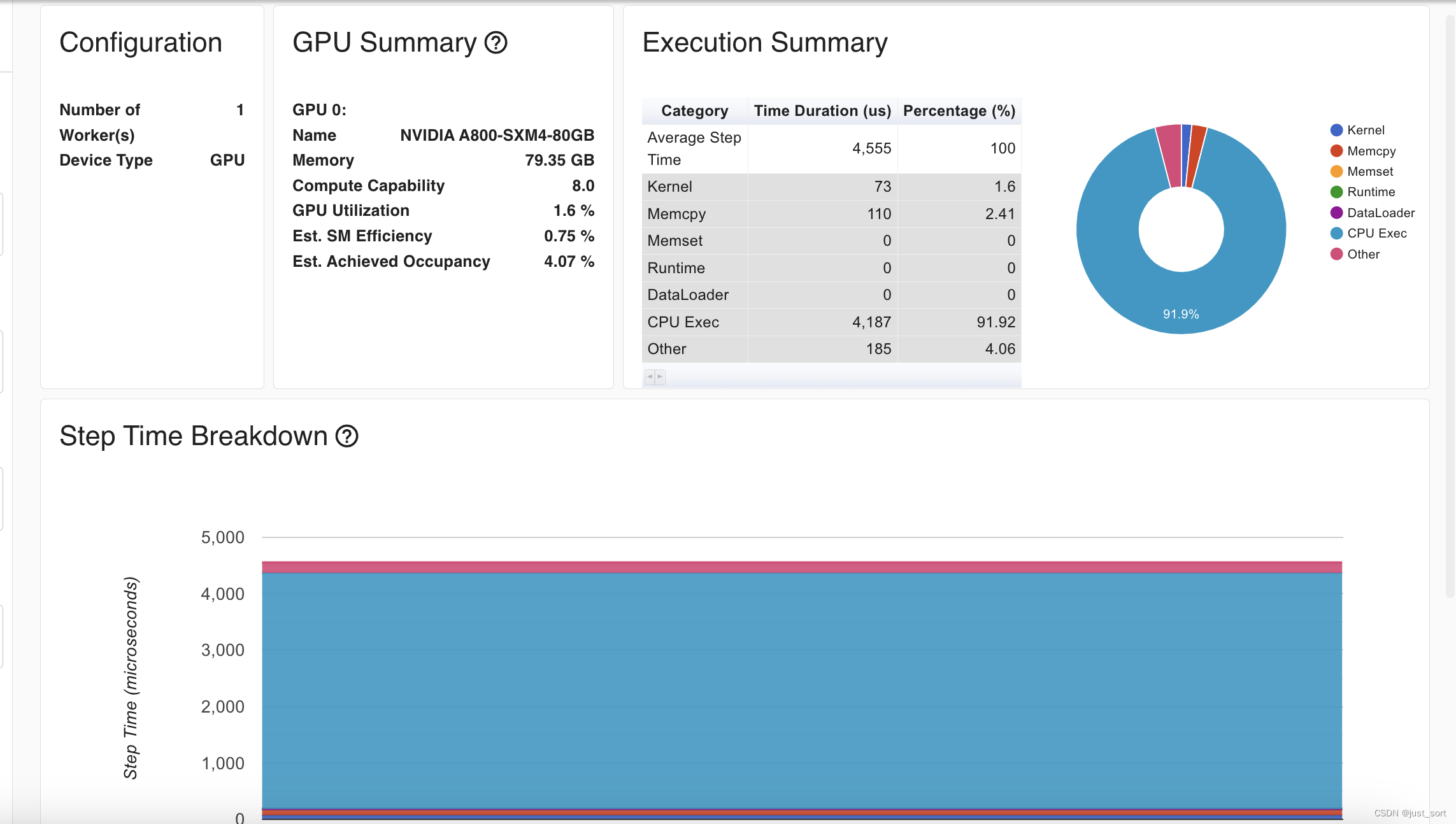
kernel的执行时间为73us,算子执行的总时间只花了4.5ms,相比于naive的实现(21.5)速度有大幅提升。观察GPU kernel执行情况:
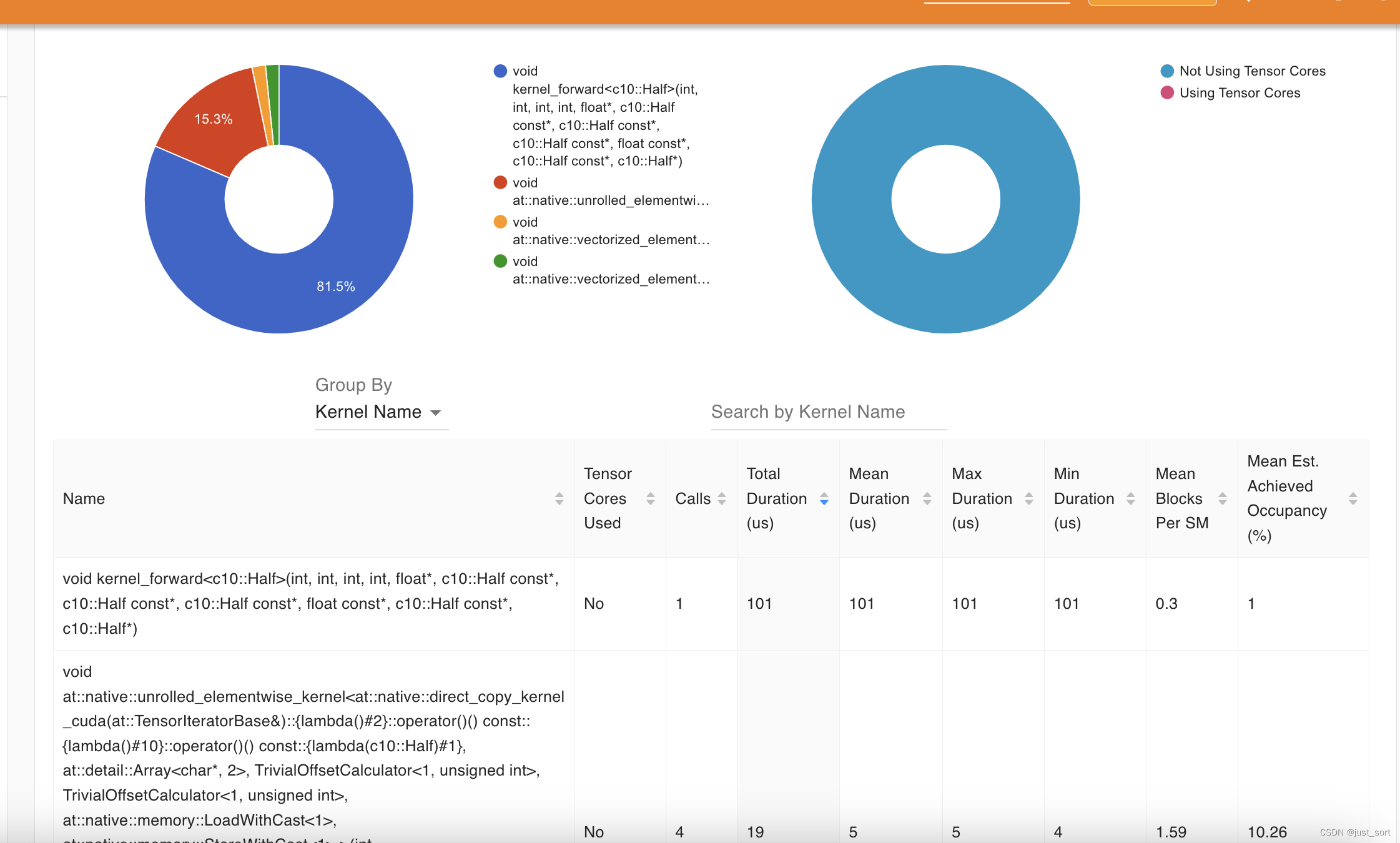
现在rwkv6_cuda_linear_attention中的核心kernel: kernel_forward执行时间为101us。并且现在这个版本只有上面截图的2个kernel有耗时,剩下的2个elementwise的kernel耗时只有2us。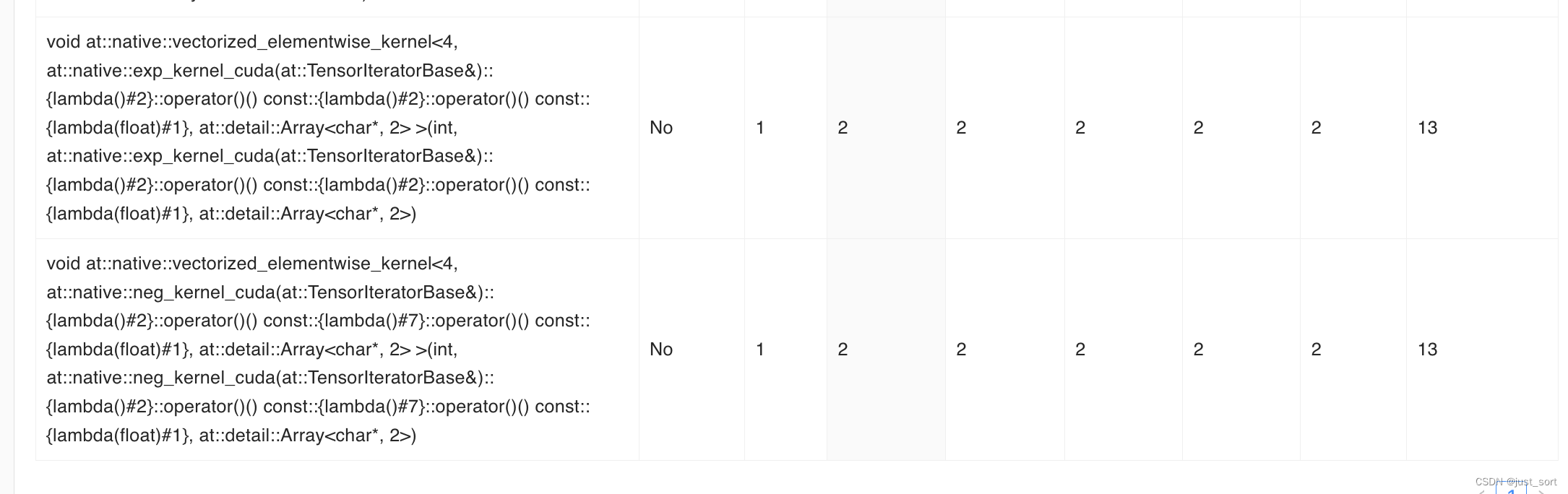
由此可见,使用cuda来编写和优化上面的rwkv6_cuda_linear_attention api可以获得大幅度的性能提升。
0x3.3 fused_recurrent_rwkv6 API profile结果
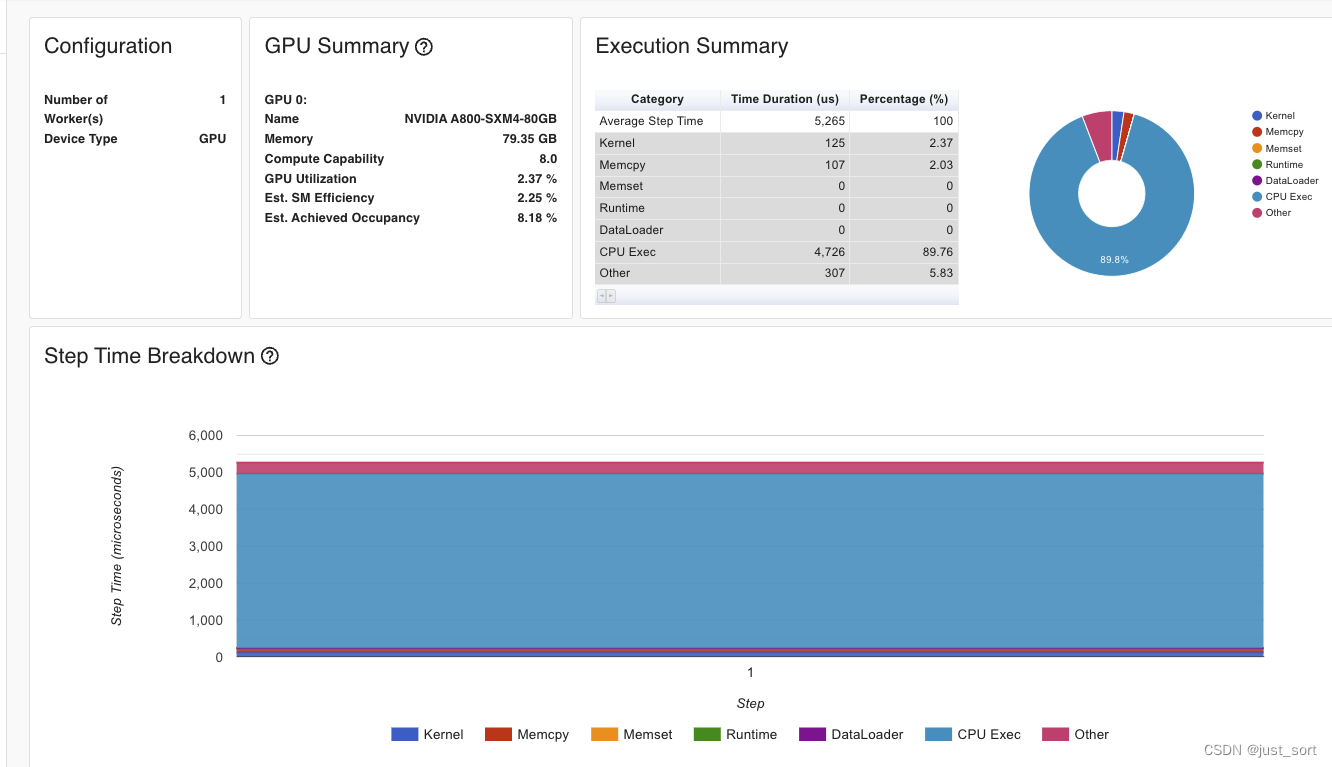
现在Kernel执行总时间只有125us,算子总的时间花了5.26ms,相比于naive的实现(21.5)速度有大幅提升,同时kernel的占比也明显更小,GPU kernel分布情况:
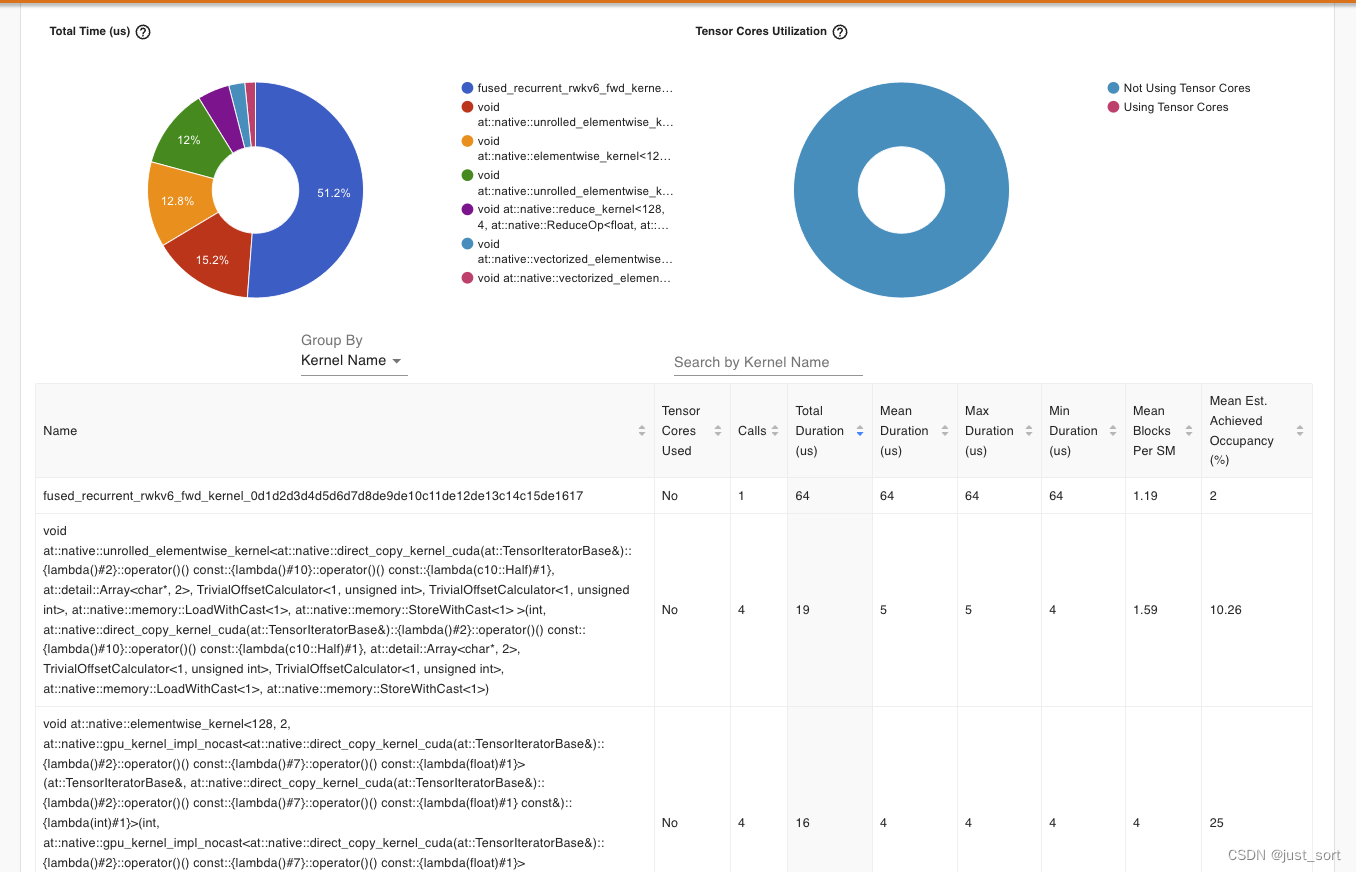
在GPU kernel的具体执行分布中,fused_recurrent_rwkv6_fwd_kernel已经是比例的最大的kernel了,而这个kernel的整体耗时非常低只花了64us,而在naive的实现中则存在数个耗时超过100us的elementwise kernel。目前的整体耗时和优化后的cuda kernel实现也是比较接近的。
0x3.4 chunk_rwkv6 API profile结果
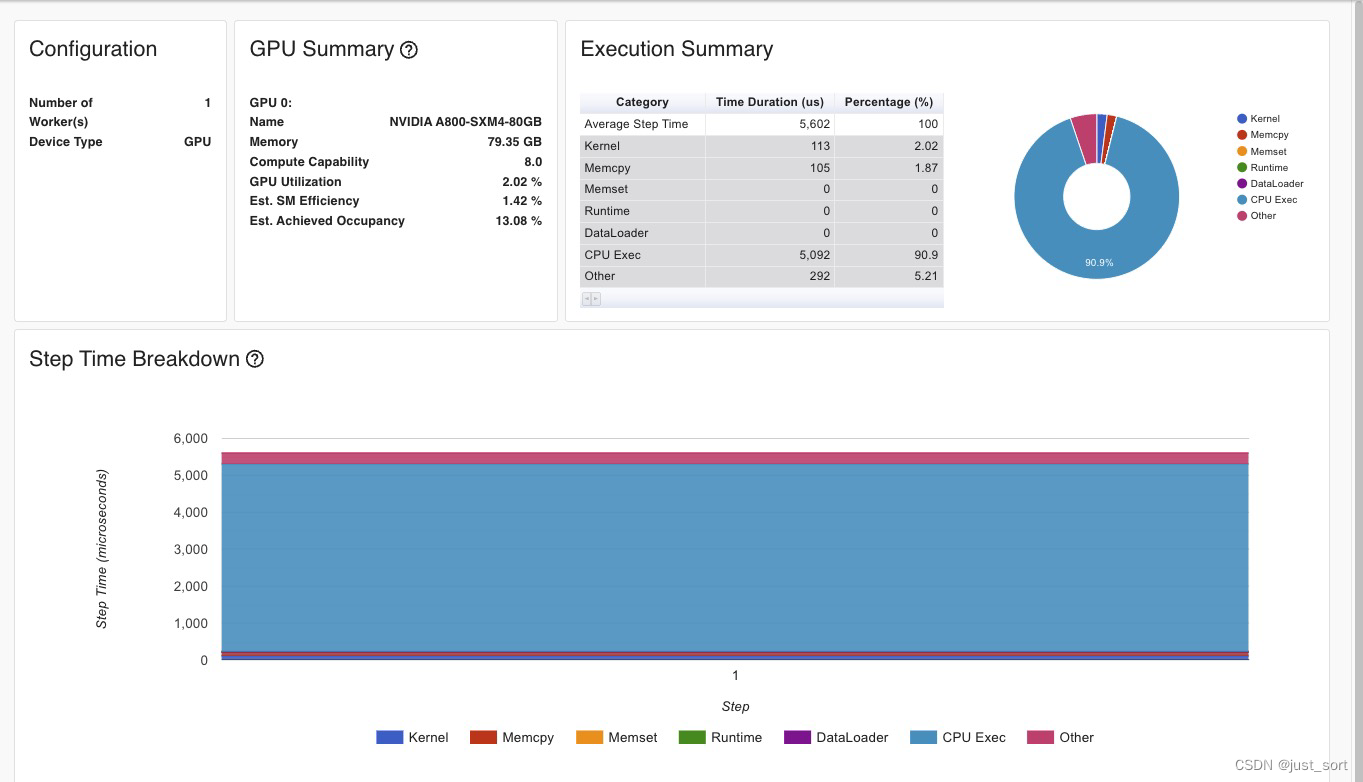
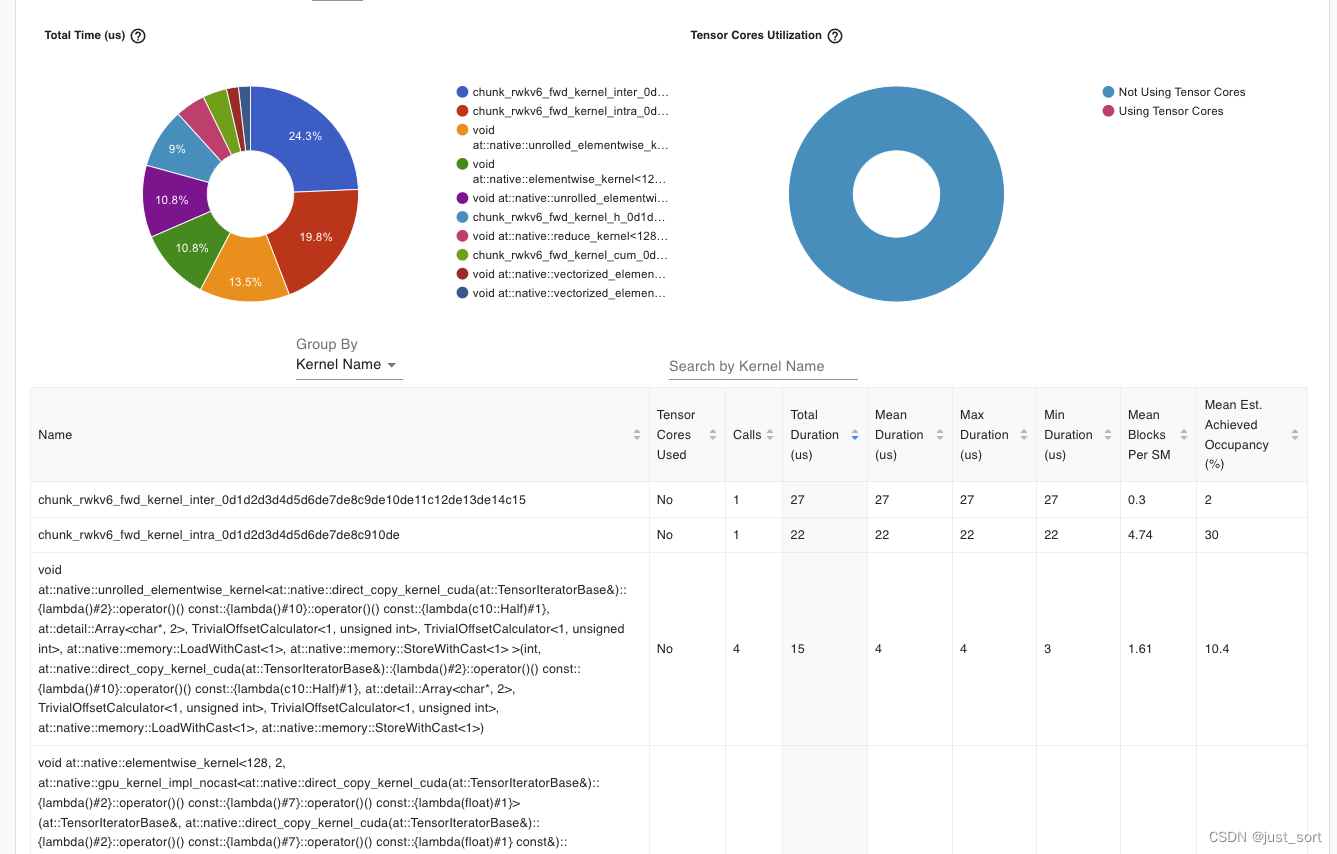
chunk_rwkv6的情况和fused_recurrent_rwkv6类似,也是达到了不错的性能。
0x3.5 Profile结果总结
| 方法 | RWKV 6 Linear Attention端到端耗时(us) | Kernel最大耗时(us) |
|---|---|---|
| hf_rwkv6_linear_attention_cpu | 21500 | 432us |
| rwkv6_cuda_linear_attention | 4500 | 101us |
| fused_recurrent_rwkv6 | 5260 | 64us |
| chunk_rwkv6 | 5602 | 49us |
注:hf_rwkv6_linear_attention_cpu中有很多个耗时比较长的element-wise kernel,性能是最差的,这里只记录了耗时最长的那个element-wise kernel,已经足够说明问题。后续三种方案都通过kernel fuse让hf_rwkv6_linear_attention_cpu实现中的seq_length维度的遍历和众多gemv/elemetwise相关kernel最终fuse成1个或者2个kernel。chunk_rwkv6 api的计算分为2个kernel,耗时分别为27和22us,统计kernel最大耗时的时候进行了求和。
结论:手工优化的rwkv6_cuda_linear_attention在端到端的耗时方面目前是最快的,从上面的profile代码也可以看出来主要原因是因为它不需要对各个输入进行一系列的维度转换,而naive的实现和Triton的实现则必须做一堆维度转换来匹配api提供的计算功能。从Kernel最大耗时的角度看,triton实现的fused_recurrent_rwkv6和chunk_rwkv6 kernel本身的计算是比RWKV-CUDA的手工kernel更快的(虽然还不太清楚Triton实现的版本在编译中发生了什么,但真的找到了放弃cuda的理由,毕竟不是专业做这个东西的,而Triton大家都可以写),后续应该会考虑在Triton kernel的基础上继续做优化以及训练性能验证。
0x4. flash-rwkv库中的rwkv5_cuda_linear_attention开发历程
这里讲一下flash-rwkv库中的rwkv5_cuda_linear_attention这个api背后开发的迭代历程。时间回到2023年8月,ChatGPT的火爆让我也想参与到开源的大模型开发过程中,然后Peng Bo说可以参与到实现RWKV5 CUDA算子的事情。为了锻炼下CUDA就开始参与实现和优化RWKV5 CUDA,在这个过程中也有幸见识到了RWKV开源社区中 https://github.com/Blealtan 这位大佬的优化水平,同时也了解了Parallel Scan算法和实现。后续RWKV6的rwkv6_cuda_linear_attention仍然沿用了rwkv5的cuda kernel,只做了微量的坐标映射修改。
HuggingFace中RWKV5模型的Linear Attention Naive实现在 https://huggingface.co/RWKV/rwkv-5-world-1b5/blob/main/modeling_rwkv5.py#L62-L84 ,贴一下这段代码。
def rwkv5_linear_attention_cpu(receptance, key, value, time_decay, time_first, state):
input_dtype = receptance.dtype
# For CPU fallback. Will be slower and probably take more memory than the custom CUDA kernel if not executed
# within a torch.no_grad.
batch, seq_length, hidden_size = receptance.shape
num_heads, head_size = time_first.shape
key = key.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2).transpose(-2, -1)
value = value.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2)
receptance = receptance.float().view(batch, seq_length, num_heads, head_size).transpose(1, 2)
time_decay = torch.exp(-torch.exp(time_decay.float())).reshape(-1, 1, 1).reshape(num_heads, -1, 1)
time_first = time_first.float().reshape(-1, 1, 1).reshape(num_heads, -1, 1)
out = torch.zeros_like(key).reshape(batch, seq_length, num_heads, head_size)
for current_index in range(seq_length):
current_receptance = receptance[:, :, current_index:current_index+1, :]
current_key = key[:, :, :, current_index:current_index+1]
current_value = value[:, :, current_index:current_index+1, :]
attention_output = current_key @ current_value
out[:, current_index] = (current_receptance @ (time_first * attention_output + state)).squeeze(2)
with torch.no_grad():
state = attention_output + time_decay * state
return out, state
要把这段代码变成cuda kernel,首先需要在形式上做一些还原,使得它更靠近原始的计算公式。还原之后的原始计算公式如下(https://github.com/BlinkDL/RWKV-CUDA/blob/main/wkv5/run.py#L67-L87):
def RUN_FORMULA_1A(B, T, C, H, r, k, v, w, u):
N = C // H
r = r.view(B, T, H, N)
k = k.view(B, T, H, N)
v = v.view(B, T, H, N)
w = w.view(H, N)
u = u.view(H, N)
out = torch.zeros((B, T, H, N), device=DEVICE)
for b in range(B):
for h in range(H):
state = torch.zeros((N,N), device=DEVICE).contiguous()
for t in range(T):
for i in range(N):
for j in range(N):
x = k[b,t,h,j] * v[b,t,h,i]
s = state[i,j]
out[b,t,h,i] += r[b,t,h,j] * (u[h,j] * x + s)
state[i,j] = s * w[h,j] + x
return out.view(B, T, C)
这里有5个循环,其中N一般比较小,对于RWKV5和RWKV6来说,N一般固定为64。还有就是这个还原的公式没有返回state,而是在B,H的内循环中申请了一个局部的state,为了保持和上面的公式一致,需要把state的形状改成[B, H, N, N],就像在profile代码编写那一节看到的这样。这里的系列kernel暂时不考虑全局state,因为训练的时候类似于推理的Prefill,不需要有这个state。有了这个代码之后,只需要想好开多少个Block以及每个Block开多少个Thread就可以写出一个Baseline了,然后逐步优化。
0x4.1 BaseLine
这个是BaseLine kernel的链接:https://github.com/BlinkDL/RWKV-CUDA/blob/main/wkv5/cuda/wkv5_cuda_ref.cu
首先看一下Block数和每个Block的线程数:
void cuda_forward(int B, int T, int C, int H, float *r, float *k, float *v, float *w, float *u, float *y)
{
dim3 threadsPerBlock( min(B*C, 32) );
assert(B * C % threadsPerBlock.x == 0);
dim3 numBlocks(B * C / threadsPerBlock.x);
kernel_forward<<<numBlocks, threadsPerBlock>>>(B, T, C, H, r, k, v, w, u, y);
}
每个Block使用min(B*C, 32)个线程,然后Block数就是B*C//threadsPerBlock.x,上面的公式有5个循环,这里的C=H*N,也就是说这里会把第1个,第2个,第4个循环分配给CUDA kernel,那么可以预见kernel中每个线程的计算过程肯定还有一个T和N的循环。浏览下这里的cuda kernel:
template <typename F>
__global__ void kernel_forward(const int B, const int T, const int C, const int H,
const F *__restrict__ const _r, const F *__restrict__ const _k, const F *__restrict__ const _v, const F *__restrict__ const _w, const F *__restrict__ const _u,
F *__restrict__ const _y)
{
const int idx = blockIdx.x * blockDim.x + threadIdx.x;
const int _b = idx / C;
const int _h = (idx / N) % H;
const int _i = idx % N;
const int _o0 = _b*T*C + _h*N;
const int _o1 = _h*N;
const F *__restrict__ const k = _k + _o0;
const F *__restrict__ const v = _v + _o0 + _i;
const F *__restrict__ const r = _r + _o0;
F *__restrict__ const y = _y + _o0 + _i;
float state[N] = {0};
for (int __t = 0; __t < T; __t++)
{
const int _t = __t*C;
const F vv = v[_t];
for (int _j = 0; _j < N; _j++)
{
const int j = _t + _j;
const int m = _o1 + _j;
const float x = k[j] * vv;
const float s = state[_j];
atomicAdd(y + _t, r[j] * (_u[m] * x + s));
state[_j] = s * _w[m] + x;
}
}
}
观察这个baseline的kernel,首先通过线程id确定当前线程所在的第一循环b,第二循环h,第4循环i的位置,然后对T以及最后的N循环进行遍历,按照公式计算结果并使用atomicAdd累计答案。
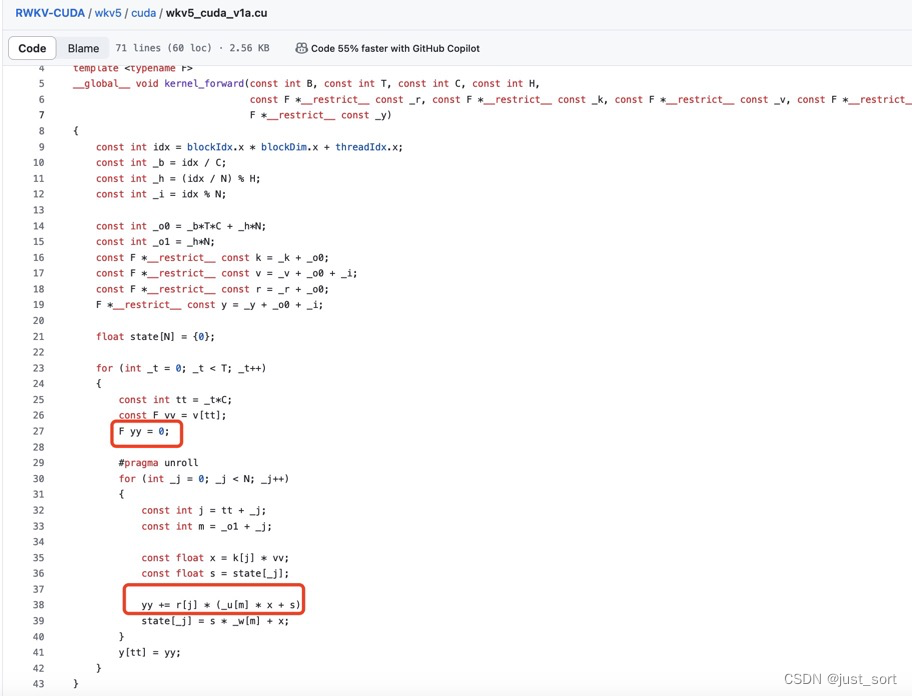
0x4.1 不必要的atomicAdd
对于每个线程来说它都有唯一的线程id,上面代码中F *__restrict__ const y = _y + _o0 + _i;这里的_o0+i一定是唯一的,所以这个atomicAdd可以去掉,用一个普通的变量来累加答案即可。https://github.com/BlinkDL/RWKV-CUDA/blob/main/wkv5/cuda/wkv5_cuda_v1a.cu
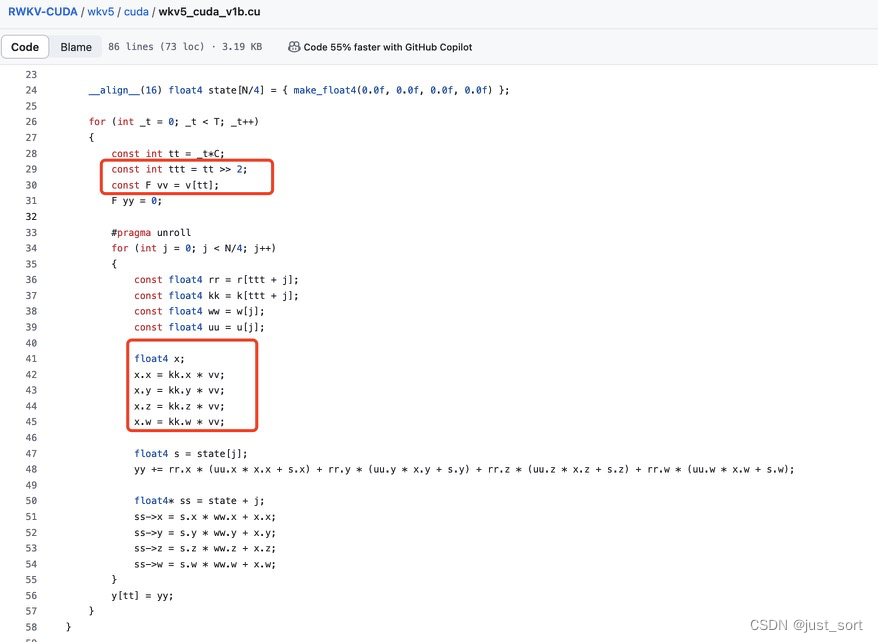
0x4.2 float4向量化
每个线程会在2个循环上频繁访问数据并计算,这里使用float4向量化读数据将有直接的收益。https://github.com/BlinkDL/RWKV-CUDA/blob/main/wkv5/cuda/wkv5_cuda_v1b.cu
0x4.3 线程块的调整
在上面的版本中,每个Block的线程数是min(B*C, 32),而对于RWKV5和RWKV6系列的模型来说,C=H*D=H*64一定是超过32的,所以每个Block的线程数一定是32,也就是一个warp。从如何设置CUDA Kernel中的grid_size和block_size? 可知线程数太少会导致SM的Occupancy无法打满,导致性能变差,最好是每个Block直接开128个线程。但RWKV 5里面的调整是将每个Block的线程数调整到64,具体见:https://github.com/BlinkDL/RWKV-CUDA/blob/main/wkv5_bf16/cuda/wkv5_cuda_v1b.cu

0x4.4 Shared Memory
观察到在第三和第五两个循环下,会频繁访问r, k, u, w,因此可以把这几个数据存入shared memory再读取。https://github.com/BlinkDL/RWKV-CUDA/blob/main/wkv5_bf16/cuda/wkv5_cuda_v1b.cu
template <typename F>
__global__ void kernel_forward(const int B, const int T, const int C, const int H,
const F *__restrict__ const _r, const F *__restrict__ const _k, const F *__restrict__ const _v, const float *__restrict__ _w, const F *__restrict__ _u,
F *__restrict__ const _y)
{
const int b = blockIdx.x / H;
const int h = blockIdx.x % H;
const int i = threadIdx.x;
_w += h*_N_;
_u += h*_N_;
__shared__ float r[_N_], k[_N_], u[_N_], w[_N_];
float state[_N_] = {0};
__syncthreads();
u[i] = float(_u[i]);
w[i] = float(_w[i]);
__syncthreads();
for (int t = b*T*C + h*_N_ + i; t < (b+1)*T*C + h*_N_ + i; t += C)
{
__syncthreads();
r[i] = float(_r[t]);
k[i] = float(_k[t]);
__syncthreads();
const float v = float(_v[t]);
float y = 0;
#pragma unroll
for (int j = 0; j < _N_; j+=4)
{
const float4& r_ = (float4&)(r[j]);
const float4& k_ = (float4&)(k[j]);
const float4& w_ = (float4&)(w[j]);
const float4& u_ = (float4&)(u[j]);
float4& s = (float4&)(state[j]);
float4 x;
x.x = k_.x * v;
x.y = k_.y * v;
x.z = k_.z * v;
x.w = k_.w * v;
y += r_.x * (u_.x * x.x + s.x);
y += r_.y * (u_.y * x.y + s.y);
y += r_.z * (u_.z * x.z + s.z);
y += r_.w * (u_.w * x.w + s.w);
s.x = s.x * w_.x + x.x;
s.y = s.y * w_.y + x.y;
s.z = s.z * w_.z + x.z;
s.w = s.w * w_.w + x.w;
}
_y[t] = F(y);
}
}
这里如果想把state也存入shared memory,那么state就需要做成一个全局的state这样才可以只开N的大小否则就需要开N*N的大小导致SM上shared memory大小不够。
每个Block开启了64个线程,也就是2个warp,对于warp里面的每个线程来说,它在访问r, k, u, w的时候必定是独立且连续的,因为这些访问都在N这个循环中,不会发生Bank Conflict。
这就是rwkv5_cuda_linear_attention对应的cuda kernel目前的状态。但,怎么就被Triton秒了?
0x5. Triton实现粗略浏览
Triton的实现也是根据naive的实现来的,先看一下naive的实现以及相关的输入。https://github.com/sustcsonglin/flash-linear-attention/blob/main/fla/ops/rwkv6/recurrent_naive.py#L8-L36
def naive_recurrent_rwkv6(
q,
k,
v,
w,
u,
initial_state=None,
output_final_state=False
):
orig_dtype = q.dtype
q, k, v, w, u = map(lambda x: x.float(), (q, k, v, w, u))
batch_size, n_heads, seq_len, d_head_k = q.shape
_, _, _, d_head_v = v.shape
h = torch.zeros(batch_size, n_heads, d_head_k, d_head_v, dtype=torch.float32, device=q.device)
o = torch.zeros_like(v)
if initial_state is not None:
h += initial_state
for i in range(seq_len):
q_i = q[:, :, i, :]
k_i = k[:, :, i]
v_i = v[:, :, i, :]
w_i = w[:, :, i].exp()
kv_i = k_i[..., None] * v_i[..., None, :]
o_i = (h + u[None, ..., None] * kv_i) * q_i[..., None]
o[:, :, i] = o_i.sum(-2)
h = h * w_i[..., None] + kv_i
return o.to(orig_dtype)
q, k, v, w, u等定义如下:
B = 4
H = 4
L = 1024
D = 100
dtype = torch.float32
q = (torch.randn(B, H, L, D).cuda().to(dtype)).requires_grad_(True)
k = (torch.randn(B, H, L, D).cuda().to(dtype)).requires_grad_(True)
v = torch.randn(B, H, L, D).cuda().to(dtype).requires_grad_(True)
w = torch.nn.functional.logsigmoid(torch.randn(B, H, L, D)).cuda().to(torch.float32).requires_grad_(True)
u = (torch.randn(H, D).cuda().to(dtype)).requires_grad_(True)
do = torch.rand_like(v).cuda()
o = naive_recurrent_rwkv6(q, k, v, w, u)
这里q,k,v的head dim维度我重新设置为了D。
然后在实现fused_recurrent_rwkv6的时候各个输入tensor的shape也沿用了这里的设置。接口定义在 https://github.com/sustcsonglin/flash-linear-attention/blob/main/fla/ops/rwkv6/recurrent_fuse.py#L403 。
# if scale is None, use d_head_qk ** -0.5 by default. Otherwise specify the scale yourself. e.g. scale = 1.0
def fused_recurrent_rwkv6(
r: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
w: torch.Tensor,
u: torch.Tensor,
scale: int = -1,
initial_state: torch.Tensor = None,
output_final_state: bool = False,
causal: bool = True
) -> Tuple[torch.Tensor, torch.Tensor]:
r"""
Args:
r (torch.Tensor):
reception of shape `(B, H, T, K)`. Alias: q, query in linear attention.
k (torch.Tensor):
keys of shape `(B, H, T, K)`
v (torch.Tensor):
values of shape `(B, H, T, V)`
w (torch.Tensor):
data-dependent decays of shape `(B, H, T, K)` in log space! Alias: g.
u (torch.Tensor):
bonus of shape `(H, K)`
scale (Optional[int]):
Scale factor for the RWKV6 attention scores.
If not provided, it will default to `1 / sqrt(K)`. Default: `None`.
initial_state (Optional[torch.Tensor]):
Initial state of shape `(B, H, K, V)`. Default: `None`.
output_final_state (Optional[bool]):
Whether to output the final state of shape `(B, H, K, V)`. Default: `False`.
"""
if scale == -1:
scale = r.shape[-1] ** -0.5
if initial_state is not None:
initial_state = initial_state.detach()
o, final_state = FusedRecurrentRWKV6Function.apply(r, k, v, w, u, scale, initial_state, output_final_state)
return o, final_state
这里再关注下Triton实现的Kernel的线程网格设置相关代码,也就是FusedRecurrentRWKV6Function的forward函数:
class FusedRecurrentRWKV6Function(torch.autograd.Function):
@staticmethod
@contiguous
@custom_fwd
def forward(ctx, r, k, v, w, u, scale=None, initial_state=None, output_final_state=False, reverse=False):
# alias
q = r
batch_size, n_heads, seq_len, d_head_qk = q.shape
d_head_v = v.shape[-1]
# default scale
if scale is None:
scale = d_head_qk ** -0.5
BK, BV = min(triton.next_power_of_2(d_head_qk), 32), min(triton.next_power_of_2(d_head_v), 32)
NK, NV = triton.cdiv(d_head_qk, BK), triton.cdiv(d_head_v, BV)
num_stages = 1
num_warps = 1
o = q.new_empty(NK, batch_size, n_heads, seq_len,
d_head_v, dtype=torch.float32)
if output_final_state:
final_state = q.new_empty(batch_size, n_heads, d_head_qk, d_head_v)
else:
final_state = None
grid = (NV, NK, batch_size * n_heads)
fused_recurrent_rwkv6_fwd_kernel[grid](
q, k, v, w, u, o, initial_state, final_state,
q.stride(1), q.stride(2), q.stride(3),
v.stride(1), v.stride(2), v.stride(3),
batch_size, n_heads, seq_len, scale,
DK=d_head_qk, DV=d_head_v, BK=BK, BV=BV,
USE_INITIAL_STATE=initial_state is not None,
STORE_FINAL_STATE=final_state is not None,
REVERSE=reverse,
num_warps=num_warps,
num_stages=num_stages
)
o = o.sum(0)
ctx.save_for_backward(q, k, v, w, u, initial_state, o)
ctx.scale = scale
ctx.reverse = reverse
# we do not need the gradient of the final state from the next chunk
# similiar to Trunctated BPTT
if final_state is not None:
final_state = final_state.detach()
return o.to(q.dtype), final_state
根据提供的输入形状,我们可以推导出以下参数:
B(batch size)= 4H(number of heads)= 4L(sequence length)= 1024D(head dimension)= 100
我们可以使用这些参数来计算 BK 和 BV 的值,以及 NK 和 NV 的值:
BK=min(triton.next_power_of_2(D), 32)=min(128, 32)=32BV=min(triton.next_power_of_2(D, 32)=min(200, 32)=32NK=triton.cdiv(D, BK)=triton.cdiv(100, 32)=4NV=triton.cdiv(D, BV)=triton.cdiv(100, 32)=4
根据这些值,我们可以推导出 grid 的大小。根据代码中的定义,grid 是一个三元组,表示 Triton Kernel 的线程网格大小,其中包括 (NV, NK, batch_size * n_heads)。
在这个例子中,batch_size * n_heads = 4 * 4 = 16。因此,grid 的大小将是 (4, 4, 16),相当于有256个Block在并行计算,而每个Block的内部目前Triton的Kernel中指定的是1个warp也就是32个进程来计算。
而在RWKV-CUDA的实现中,对于这个case一共会使用16个线程块,然后每个线程块使用100个线程,从直觉上看这就是一个很不好的配置,Block数太小无法用满SM。
 Triton的kernel后续在接着学习和分析,我也需要认真学习下triton。
Triton的kernel后续在接着学习和分析,我也需要认真学习下triton。
0x6. 总结
关于flash-linear-attention中rwkv6加速算子的实现后面再解析吧,后续如果RWKV6的Linear Attention算子优化在开源社区有新的进展,我也会及时跟进和分享给大家。