前言
在前文中,我们已经学习了Spring框架,Spring MVC框架,相信大家对这些基础的内容已经熟练使用了,今天,我们继续来学习Mybatis框架。就目前而言,Mybatis框架依然是比较实用的框架,这篇博客,将通过Mybatis框架和Spring框架的结合,来讲解Mybatis框架的使用,学完之后你就可以自己写接口玩了。
什么是Mybatis框架
Mybatis的主要作用是快速实现对关系型数据库中的数据进行访问的框架。Mybatis可以不依赖于Spring框架直接使用,但是,需要进行大量的配置,导致前期工作量比较大。基于Spring框架目前是业内使用的标准之一,所以,通常会整合Spring和Mybatis框架,以减少配置。现在,让我们来通过创建工程来使用Mybatis框架吧。
创建一个Mybatis项目
创建工程
创建过程不需要选择任何的骨架,只需要创建一个简单的maven项目就行:
点击next,修改项目名称:
一个基础的maven项目就创建好了

添加依赖
<dependencies>
<!--mybatis依赖-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.6</version>
</dependency>
<!--mybatis整合Spring依赖-->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>2.0.6</version>
</dependency>
<!--Spring依赖-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.3.14</version>
</dependency>
<!--Spring JDBC依赖-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.3.14</version>
</dependency>
<!--MySQL连接依赖-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.21</version>
</dependency>
<!--数据库连接池依赖-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-dbcp2</artifactId>
<version>2.8.0</version>
</dependency>
<!--JUnit测试依赖-->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.7.0</version>
<scope>test</scope>
</dependency>
</dependencies>一共需要添加这么多的依赖,有些依赖,我们前文是添加过的,有些依赖虽然我们没有用过,但是通过名字就知道它是干嘛的。不要嫌多,真是开发中,这些依赖只是基础中的基础,实际用到的依赖只会更多,多到你怀疑人生。
这里主要说下数据库连接池依赖:简单理解,就是一个池子,用来放数据库连接,你如果知道线程池的话,那应该很好理解,原理是一样的。数据库连接池允许应用程序重复使用一个已经创建的数据库连接,而不用再重新创建。释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。
配置环境
我们先创建一个测试类:

接着创建数据库,数据库默认大家已经安装了,博主这里用的是虚拟机Docker:
如果你也是用的虚拟机,直接启动mysql的容器就可以了,然后创建数据库:
create database mybatis在工程中配置可视化面板:
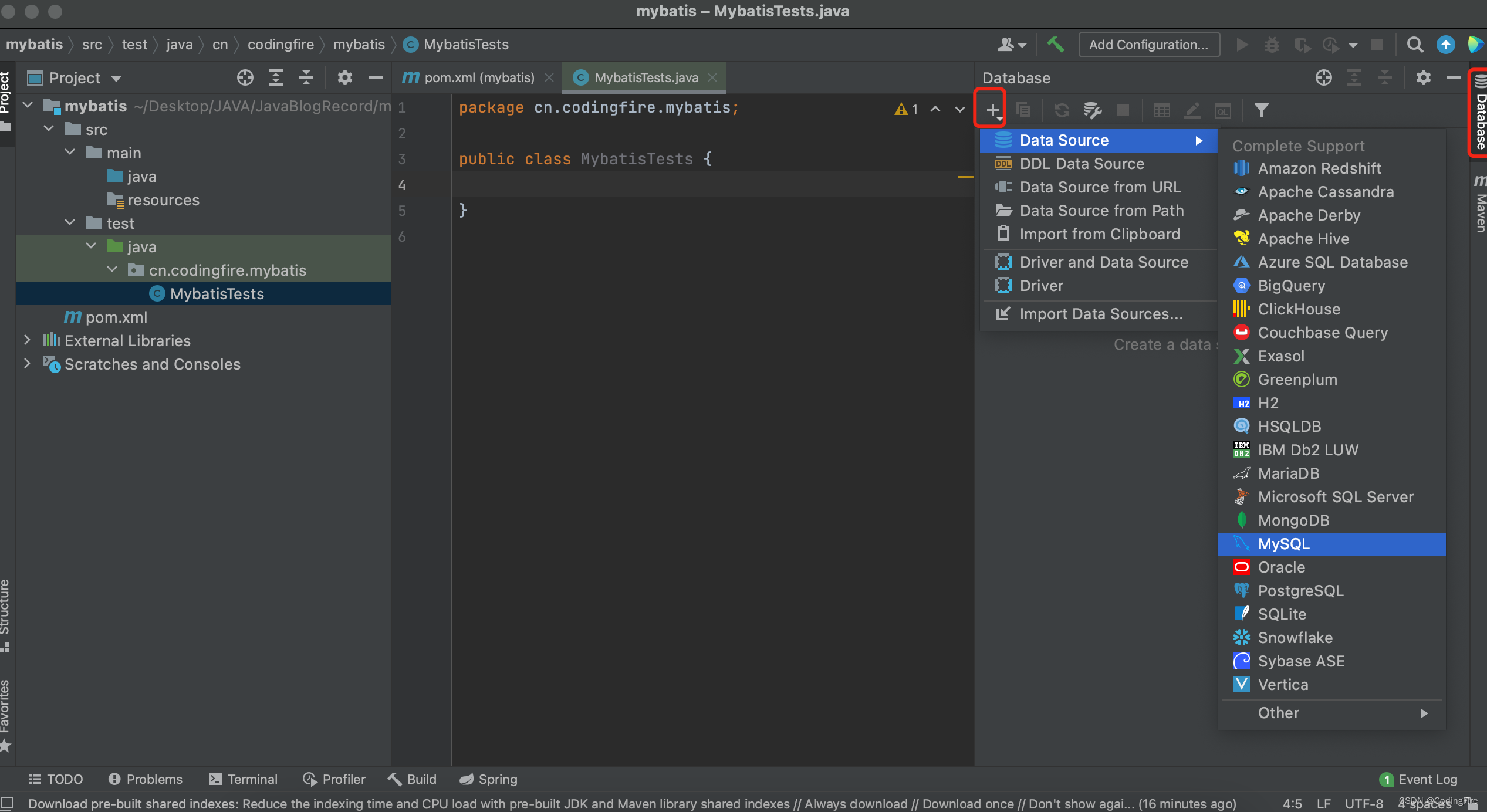
用户名和密码写自己的数据库用户密码,URL要具体到刚创建的数据库名:
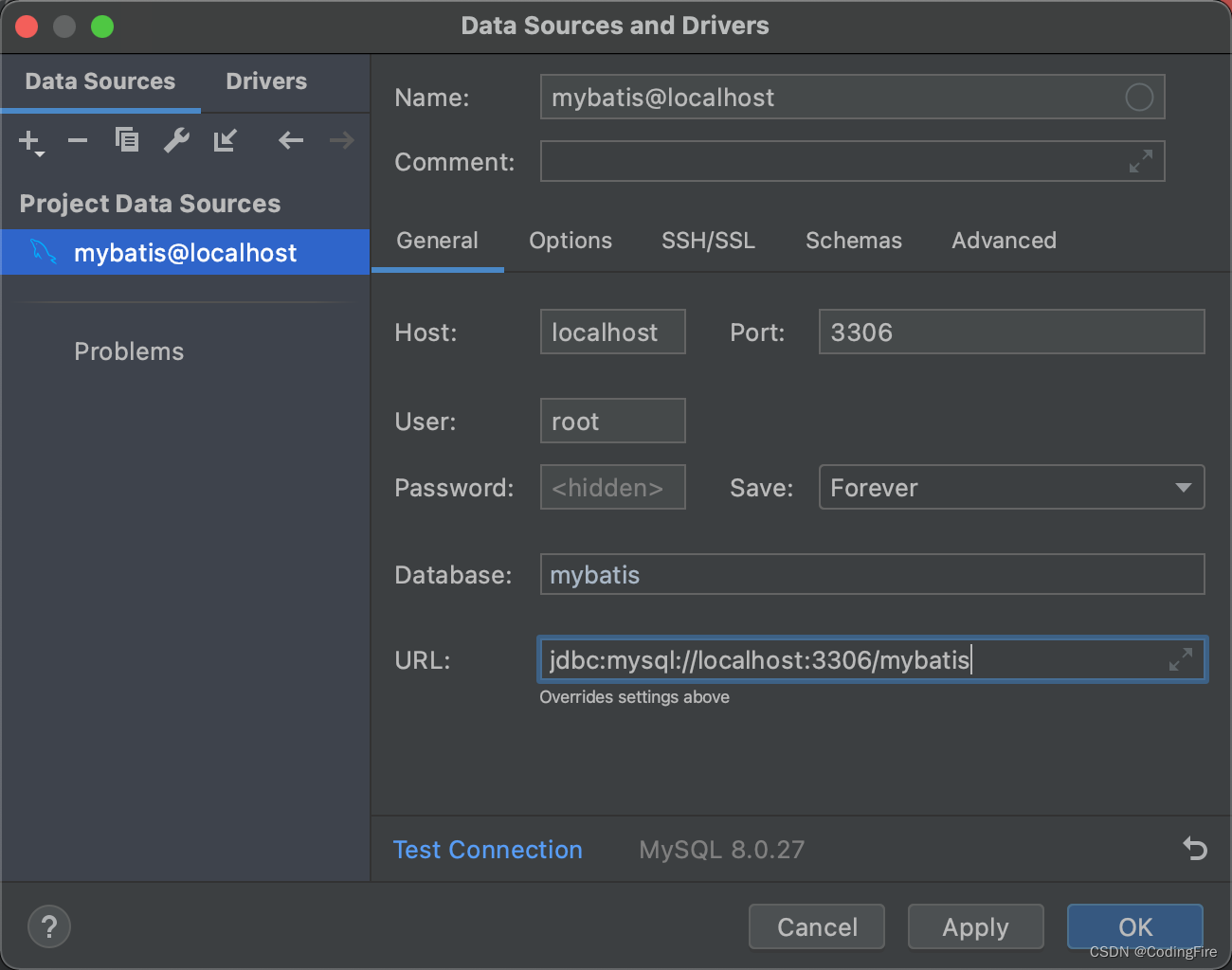
最后点击确定就可以了。
创建一张用户表用于测试:
create table admin
(
id bigint unsigned auto_increment,
username varchar(50) default null unique comment '用户名',
password char(64) default null comment '密码(密文)',
nickname varchar(50) default null comment '昵称',
avatar varchar(255) default null comment '头像URL',
phone varchar(50) default null unique comment '手机号码',
email varchar(50) default null unique comment '电子邮箱',
primary key (id)
) comment '用户表' charset utf8mb4;此表和真实表比还是缺了不少字段的,只是提一下,大家知道就行,真是开发还会有很多其他的字段。 做完这些,我们来创建配置文件datasource.properties,选择file,进行创建:
接着在该文件中添加连接数据库的配置:
datasource.url=jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
datasource.driver=com.mysql.cj.jdbc.Driver
datasource.username=root
datasource.password=xxxxxxxx部分写你自己的数据库密码。这里我们看到我们的属性都添加了datasource前缀,是为了防止和系统变量名冲突。
接下来要按照spring框架中那样创建配置类,目的是可以自动扫描,这个大家都已经知道了:

package cn.codingfire.mybatis.config;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
@Configuration
@PropertySource("classpath:datasource.properties")
public class SpringConfig {
}
@PropertySource是Spring框架的注解,用于读取properties类型的配置文件,读取到的值将存入到Spring容器的Environment对象中。
做完这些,就可以简单测试下环境是否已经准备好了,在配置类中获取配置文件中配置的数据库信息:
package cn.codingfire.mybatis.config;
import org.apache.commons.dbcp2.BasicDataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.PropertySource;
import org.springframework.core.env.Environment;
import javax.sql.DataSource;
@Configuration
@PropertySource("classpath:datasource.properties")
public class SpringConfig {
@Bean
public DataSource dataSource(Environment env) {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setUrl(env.getProperty("datasource.url"));
dataSource.setDriverClassName(env.getProperty("datasource.driver"));
dataSource.setUsername(env.getProperty("datasource.username"));
dataSource.setPassword(env.getProperty("datasource.password"));
return dataSource;
}
}
测试环境
然后在测试类中测试是否能拿到读取到的数据库信息:
package cn.codingfire.mybatis;
import cn.codingfire.mybatis.config.SpringConfig;
import org.junit.Test;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import org.springframework.core.env.ConfigurableEnvironment;
import javax.sql.DataSource;
import java.sql.Connection;
public class MybatisTests {
@Test
public void loadBasicInfo() {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
ConfigurableEnvironment environment = ac.getEnvironment();
System.out.println(environment.getProperty("datasource.url"));
System.out.println(environment.getProperty("datasource.driver"));
System.out.println(environment.getProperty("datasource.username"));
System.out.println(environment.getProperty("datasource.password"));
ac.close();
}
}
单独运行此测试方法,看看能不能获取到我们配置的数据库信息:

很明显,获取到了数据库信息,说明我们的配置是正确的,接着我们尝试去连接数据库,看看是否能获取到数据库连接对象:
package cn.codingfire.mybatis;
import cn.codingfire.config.SpringConfig;
import org.junit.Test;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import org.springframework.core.env.ConfigurableEnvironment;
import javax.sql.DataSource;
import java.sql.Connection;
public class MybatisTests {
@Test
public void loadBasicInfo() {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
ConfigurableEnvironment environment = ac.getEnvironment();
System.out.println(environment.getProperty("datasource.url"));
System.out.println(environment.getProperty("datasource.driver"));
System.out.println(environment.getProperty("datasource.username"));
System.out.println(environment.getProperty("datasource.password"));
ac.close();
}
@Test
public void testConnection() throws Exception {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
DataSource dataSource = ac.getBean("dataSource", DataSource.class);
Connection connection = dataSource.getConnection();
System.out.println(connection);
ac.close();
}
}
运行testConection方法,查看运行结果:
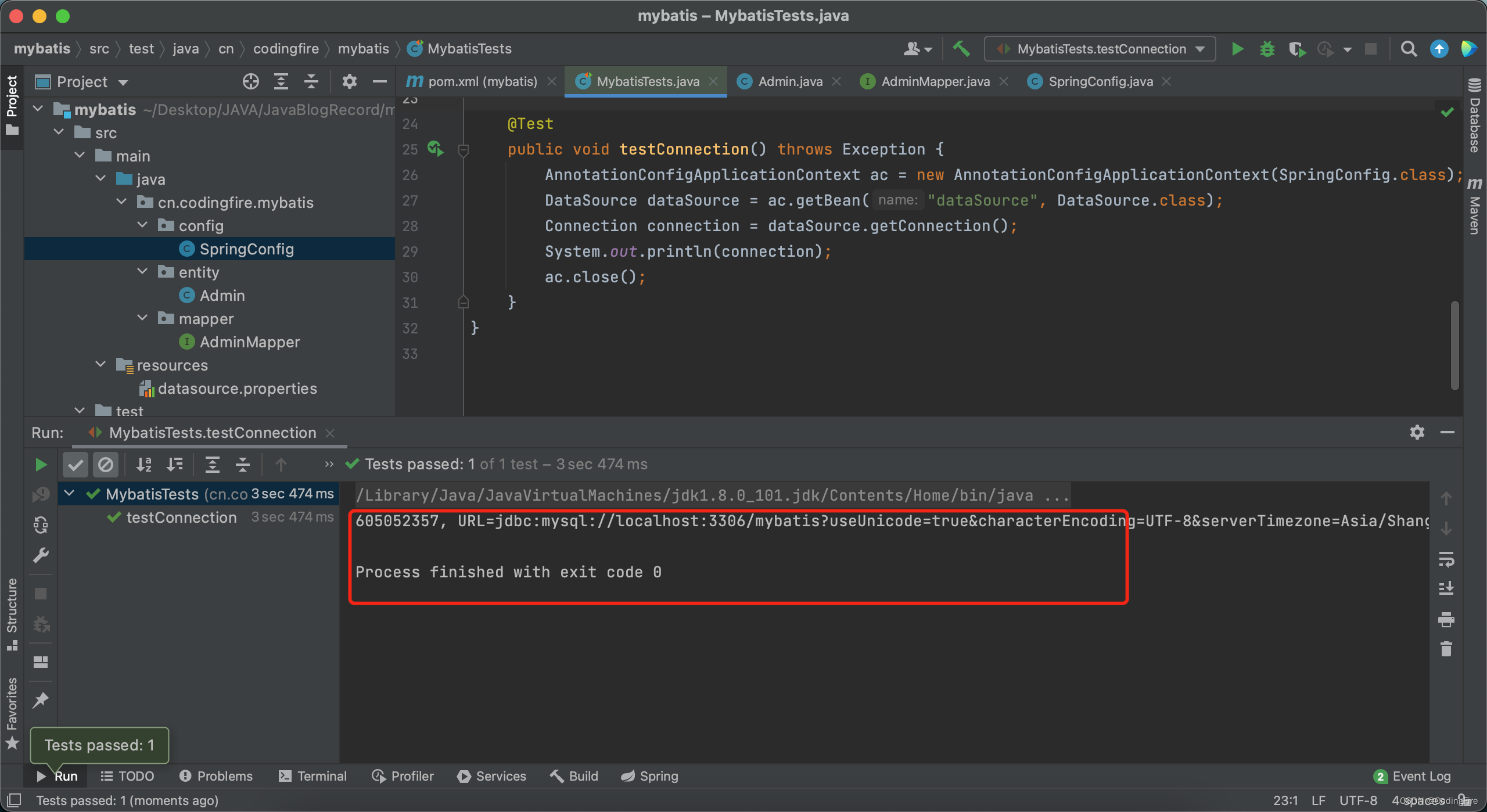
可以看到,控制台已经输出了数据库连接对象,测试成功,到这里,我们的环境就搞定了,接下来可以去做一些真实的开发了。
Mybatis基本使用
注意事项
使用Mybatis访问数据时,需要编写数据访问的抽象方法,配置抽象方法的sql语句。抽象方法通常使用Mapper作为后缀,Mybatis框架底层将通过接口代理模式来实现。执行的sql语句对应的抽象方法返回值,除了查询,其他一律使用int,虽然void也可以,但并不推荐,int可以表示受影响的行数,我们可以即此判断成功失败。查询则返回数据对应的类型即可。
根据一些业内的不成文规范:
插入方法以insert作为前缀;
删除方法以delete作为前缀;
修改方法以update作为前缀;
查询方法,若是统计数量,以count作为前缀;获取单个数据,以get,find作为前缀;获取列表,以list作为前缀。如果有条件,可用by来进行承接,比如,getById。
关于方法参数,我们前文已经讲过,若是参数少,可以直接写,若是参数多,则需作为对象来进行传递。
插入一条用户数据
当插入一条用户数据的时候,sql语句如下:
insert into ams_admin (username, password, nickname, avatar, phone,
email) values (?,?,? ... ?);
由于sql中数据较多,不利于我们在方法参数中使用,所以我们需要将这些参数封装起来,做一个用户对象来进行传递。
创建一个用户数据模型:
package cn.codingfire.mybatis.entity;
import java.io.Serializable;
public class Admin implements Serializable {
private String username;
private String password;
private String nickname;
private String avatar;
private String phone;
private String email;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getNickname() {
return nickname;
}
public void setNickname(String nickname) {
this.nickname = nickname;
}
public String getAvatar() {
return avatar;
}
public void setAvatar(String avatar) {
this.avatar = avatar;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
}
注意:实现了序列化接口,序列化ID在不同的编译器中可能需要显示的声明,否则会有问题,IDE默认是不检查的,所以不需要写,其他的编译器大家看运行情况吧。
创建一个接口类,声明一个抽象方法,方法参数使用我们新创建的数据模型对象:
package cn.codingfire.mybatis.mapper;
import cn.codingfire.mybatis.entity.Admin;
public interface AdminMapper{
int insert(Admin admin);
}
这里不要忘了自动扫描,需要在SpringConfig配置类中添加扫描配置:
@MapperScan("cn.codingfire.mybatis.mapper")
配置的时候路径不要配置的太大,一定要具体到包名,否则乱扫描实在不是一件让人开心的事。
这里还有一个知识点,提一下,上面的扫描也可以不配置,但是需要在当前mapper类的抽象方法上添加@mapper注解,所以我们更推荐上面的方式。
接下来,需要配置抽象方法对应的SQL语句,这些SQL语句推荐配置在 xml文件中。
如果不写在xml中,就只能这么写:
@Insert("insert into admin(username,password,nickname,avatar,phone,email) values(......)")
int insert(Admin admin);由于sql语句太长,在这里导致可读性变差,所以实际开发中推荐写在xml语句中。
xml文件基本格式:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="">
</mapper>创建一个xml文件,贴进去就可以了。
xml文件有几点要知道:
- 根据要执行的sql语句选择对应的节点insert/delete/update/select
- 节点的id是抽象方法的名称
- 在节点内部写sql语句
- sql语句中的未知参数用#{}来占位
了解了这些,我们就可以在xml文件中写sql了,首先写一个增加用户的sql,也是我们抽象方法的sql:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="xxxxxx">
<insert id="insert">
insert into admin (username, password, nickname, avatar, phone, email)
values (#{username}, #{password}, #{nickname}, #{avatar}, #{phone}, #{email})
</insert>
</mapper>
虽然写完了,但是还不能够工作,因为编译器根本不知道你在xml文件中写了这些sql,还需要给他们关联起来,这样编译器才会根据抽象方法的名字去读对应的sql,所以接下来要这么做:将DataSource配置给Mybatis框架,并为Mybatis配置这些XML文件的路径。
在datasource.properties中补充一条配置:
mybatis.mapper-locations=classpath:mapper/AdminMapper.xmlxml文件很多时,可以使用通配符*:
mybatis.mapper-locations=classpath:mapper/*.xml添加好了之后还需要读取,根据Spring自动创建对象的特性,我们需要在SpringConfig类中新增方法去读取xml文件:
@Bean
public SqlSessionFactoryBean sqlSessionFactoryBean(DataSource dataSource, @Value("${mybatis.mapper-locations}") Resource mapperLocations) {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSource);
sqlSessionFactoryBean.setMapperLocations(mapperLocations);
return sqlSessionFactoryBean;
}我们前文已经学过,@Bean注解可以使Spring框架自动调用此方法,并管理返回的对象。@Value注解作用是从Env中读取配置,看里面的名字是不是和datasource.properties文件中的xml路径的名字一样,读出来的就是xml的路径,locations有s,代表可以是多个xml文件,正应了上面说的通配符。
到这里,我们前期需要做的配置就完成了,接下来,我们在测试类中来写一个添加用户的操作,看看能不能通过调用AdminMapper的 insert()方法插入数据。
首先我们创建一个添加用户的类叫InsertTests:
package cn.codingfire.mybatis;
public class InsertTests {
}然后添加测试方法:
@Test
public void testInsert() {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
AdminMapper adminMapper = ac.getBean(AdminMapper.class);
Admin admin = new Admin();
admin.setUsername("admin1");
admin.setPassword("123456");
adminMapper.insert(admin);
ac.close();
}运行单独的添加方法,竟然报错了,原因是xml文件的namespace没有写,所以也给大家提个醒,namespace要写xml的路径:
<mapper namespace="cn.codingfire.mybatis.mapper.AdminMapper">
接着,我们再运行这个测试方法:
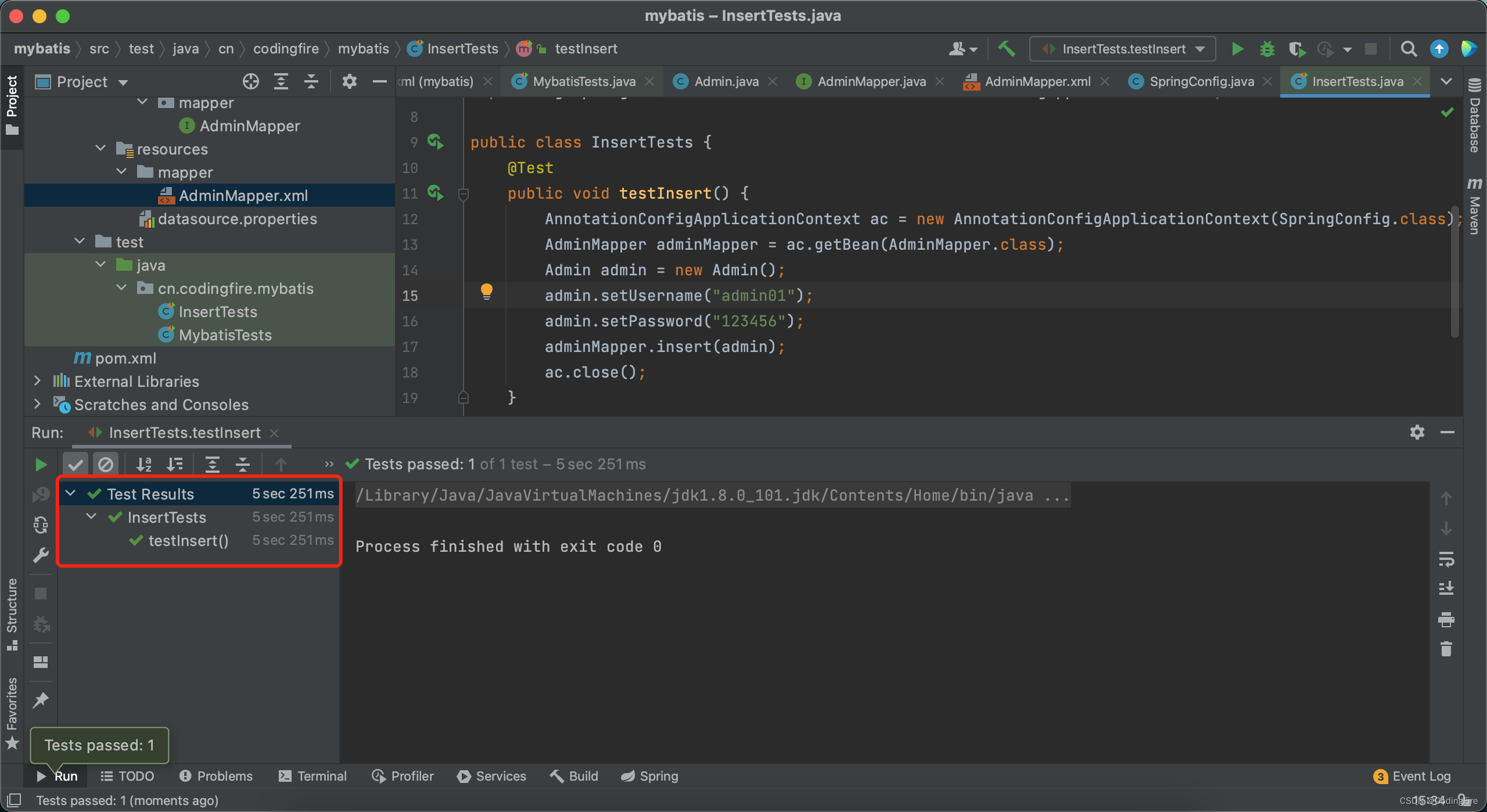
发现这个方法已经执行成功,我们去数据库可视化 面板看看admin表中有没有我们新插入的数据:
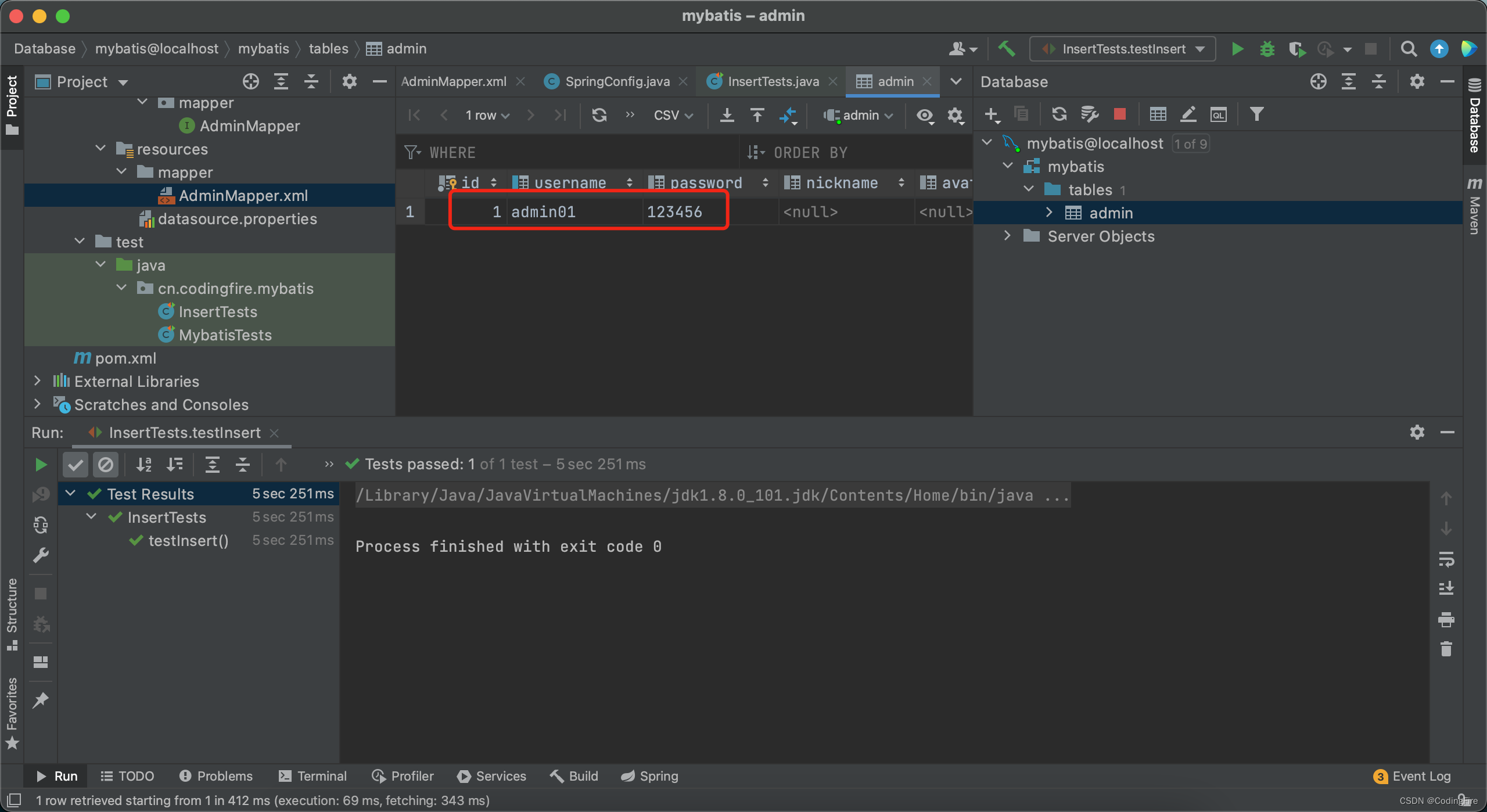
看到已经成功插入,至此,插入数据的全部操作我们已经实现,你学会了吗?
获取id相关
细心的童鞋可能已经发现了,我们的Admin类中没有声明id,虽然id可以在表中自动生成且自增,但是我们有时候希望插入数据后可以获取到插入数据的id,所以,我们还需要在Admin类中声明id,并补充其set和get方法:
private Long id;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}声明完还不够,还需要在xml文件中添加2个属性,useGeneratedKeys和 keyProperty:
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
原代码
</insert>
如上配置之后,Mybatis执行此插入数据的操作后,会将自动编号的id赋值到参数Admin admin的id属性中,keyProperty指的就是将自动编号的值放回到参数对象的那个属性中。
删除一条数据
删除数据一般是根据id来做,要删除一条数据,大致的sql语句如下:
delete from admin where id=xxx
在AdminMapper接口中添加抽象方法如下:
int deleteById(Long id);在AdminMapper.xml中添加以上抽象方法映射的sql语句如下:
<delete id="deleteById">
delete from admin where id=#{id}
</delete>
我们就不新建类了,直接在InsertTests类中进行测试如下:
@Test
public void testDeleteById() {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
AdminMapper adminMapper = ac.getBean(AdminMapper.class);
Long id = 1L;
int rows = adminMapper.deleteById(id);
System.out.println("删除完成,受影响的行数=" + rows);
if (rows == 1) {
System.out.println("删除成功");
} else {
System.out.println("删除失败,尝试删除的(id=" + id + ")不存在!");
}
ac.close();
}我们刚刚添加的数据id为1,我们现在就来删除看看,能不能成功。运行代码,看看结果:
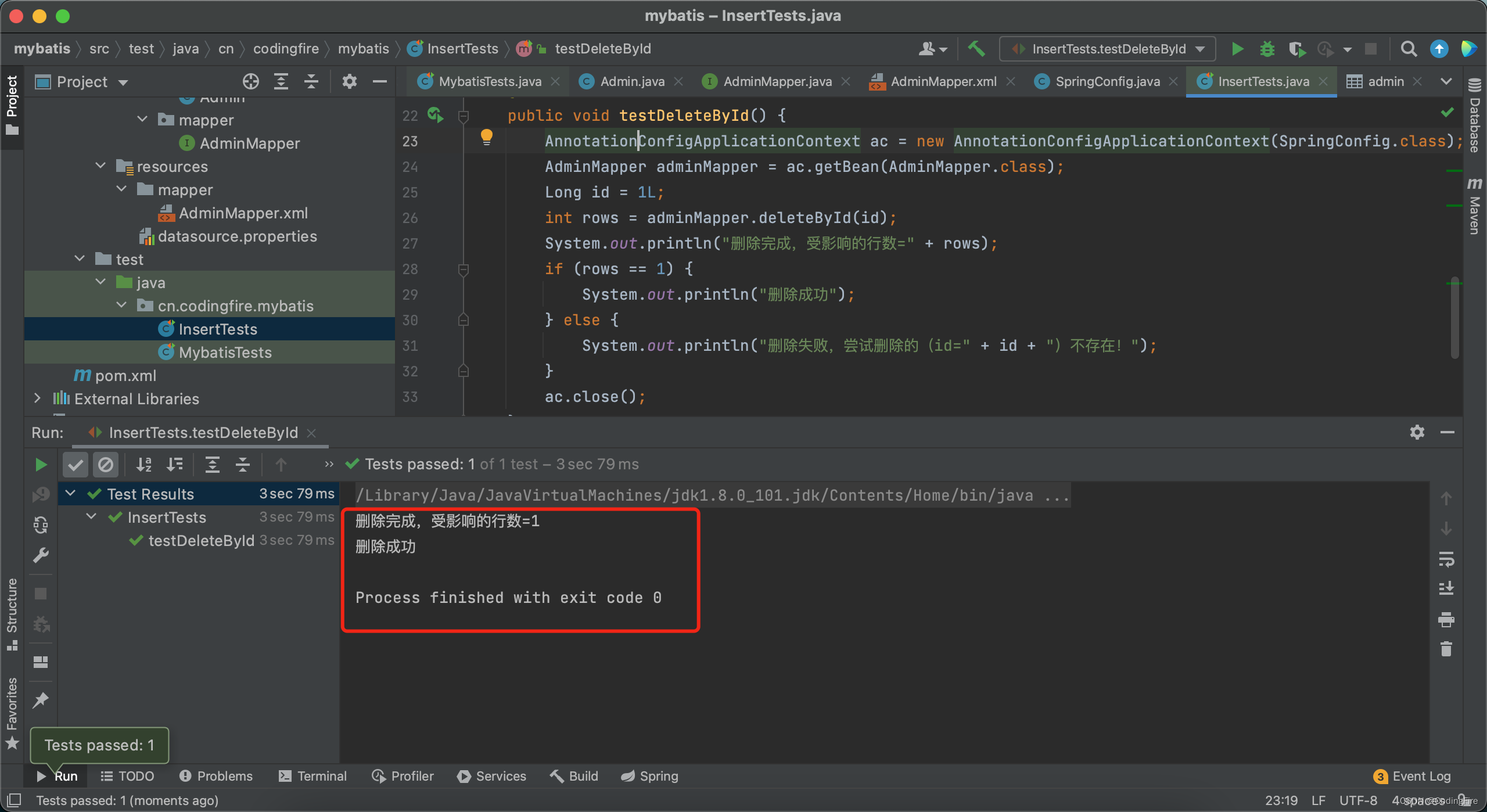
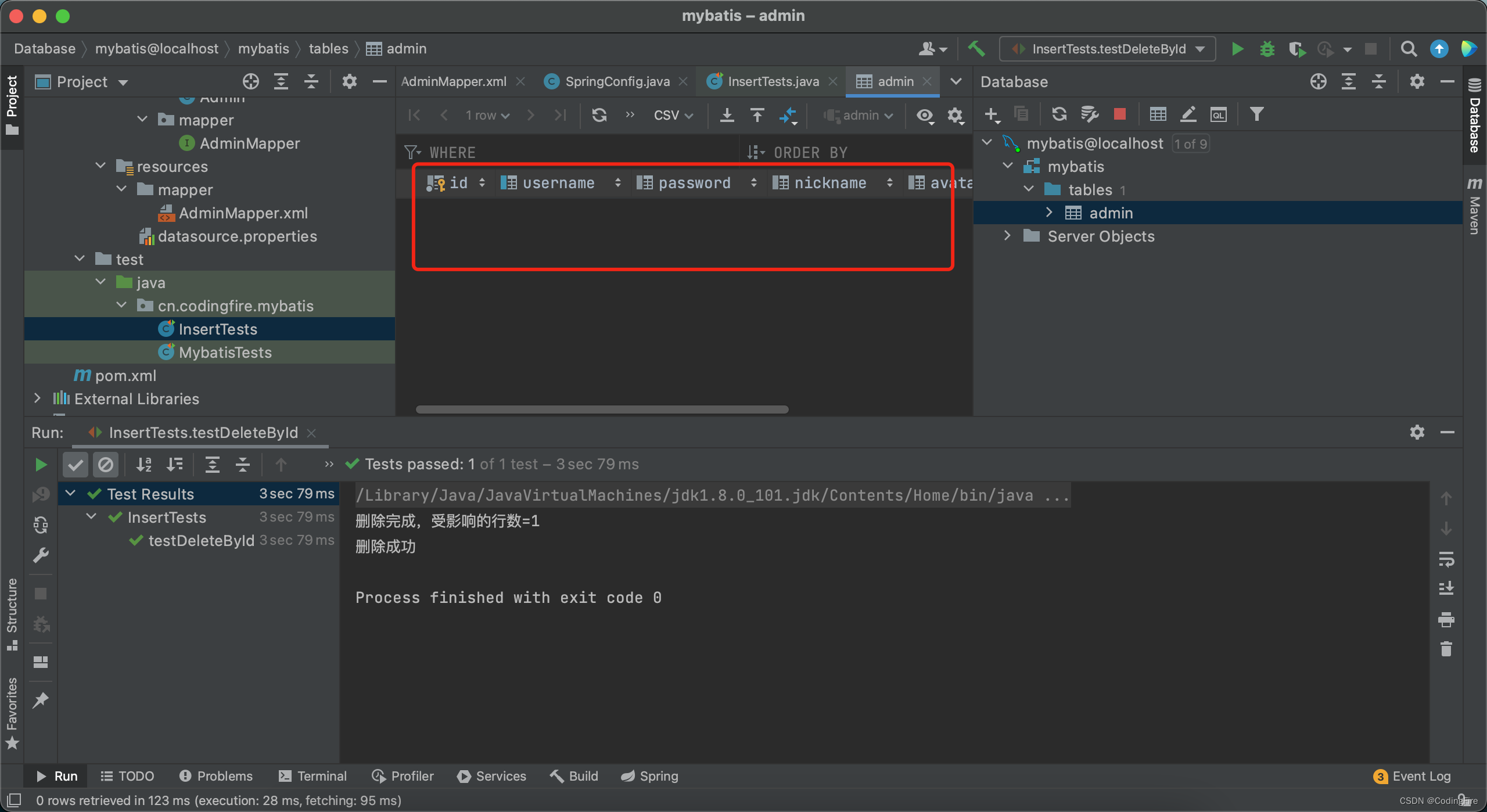
删除成功,可视化视图中新添加的那条数据也不在了:
修改数据
在修改之前,我们还需要通过插入操作先插入一条数据,不出意外的话,插入的数据如下:

现在我们来对这条数据进行修改,首先准备修改的sql:
update admin set password=xxxx where id=xxxx
在AdminMapper类中添加一个修改的抽象方法:
int updatePasswordById(@Param("id") Long id, @Param("password") String password);这里就用到了前文中说到的参数的注解@Param来指定参数名,这是因为,java源代码经过编译后,所有局部的量的名称都会丢失,为使得配置SQL语句时可根据指定的名称使用方法中的参数值,需要在方法的各参数前添加@Param以指定名称,若是参数有一个,则可以不用此注解,Mybatis可以直接找到这个参数,当大于1个时,则需要使用此注解。
接着在xml文件中添加修改的sql如下:
<update id="updatePasswordById">
update admin set password=#{password} where id = #{id}
</update>
括号中的名字需是@Param注解指定的名字。
接着运行以下测试代码:
@Test
public void testUpdatePasswordById() {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
AdminMapper adminMapper = ac.getBean(AdminMapper.class);
Long id = 1L;
String password = "000000";
int rows = adminMapper.updatePasswordById(id, password);
if (rows == 1) {
System.out.println("密码修改成功");
} else {
System.out.println("密码修改失败,尝试访问的(id=" + id + ")不存在!");
}
ac.close();
}查看运行结果:
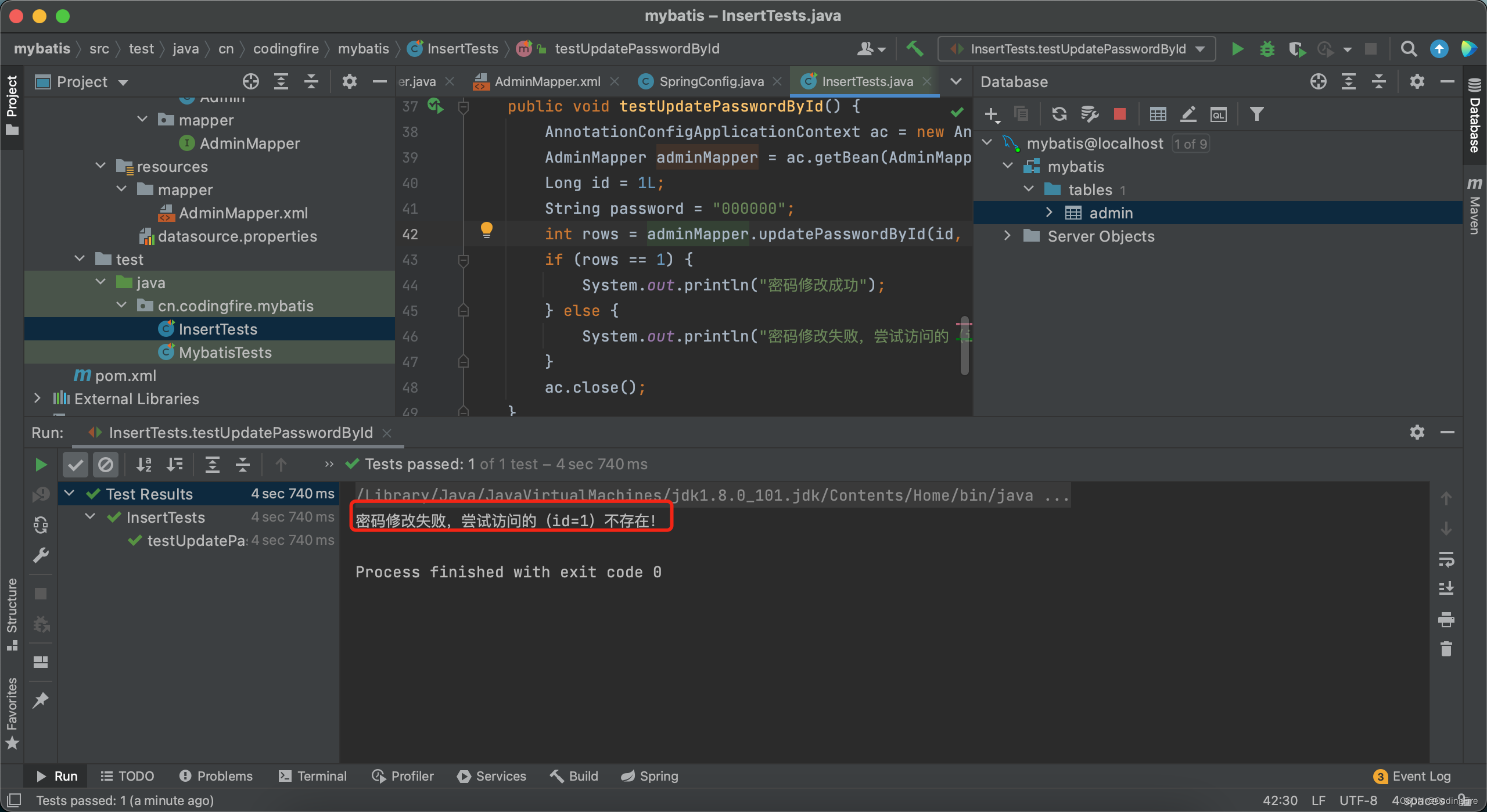
这是因为第一次插入的数据其id为1,删除后,新插入的数据不会再使用已删除的id,而是继续向后加一位使用,修改id为1的数据就出现id为1的护具不存在,我们把需要修改的id改为2,再执行测试代码:

可视化视图中看下表中数据,也已经修改成功:

查询数据
增删改都已经完成,接下来我们来做查询数据的操作,和增删改不同的是,查询数据要返回一个list,但这里只查询表中有多少条数据,查询返回引用类型的方式我们将在下面讲解。现在,先来看看查询的sql:
select count(*) from admin
接着在AdminMapper类中添加一个查询的抽象方法:
int count();这也是我们前面提到过的命名规范,要牢记。
接着在xml文件中添加对应的sql映射语句:
<select id="count" resultType="int">
select count(*) from admin
</select>
所有select节点必须配置resultType或resultMap这2个属性中的其中1个,返回类型如果是基本类型,可直接写,比如这里的int,如果是引用类型,resultType则需要写完整的包名路径,比如Admin类,则应该写成下面这样:
<select id="count" resultType="cn.codingfire.mybatis.entity.Admin">
select * from admin
</select>
resultMap的使用将在下面来进行说明,不要慌。
最后在测试类中添加测试方法如下:
@Test
public void testCount() {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
AdminMapper adminMapper = ac.getBean(AdminMapper.class);
int count = adminMapper.count();
System.out.println("当前表中有" + count + "条数据");
ac.close();
}执行这段测试代码,执行结果如下:
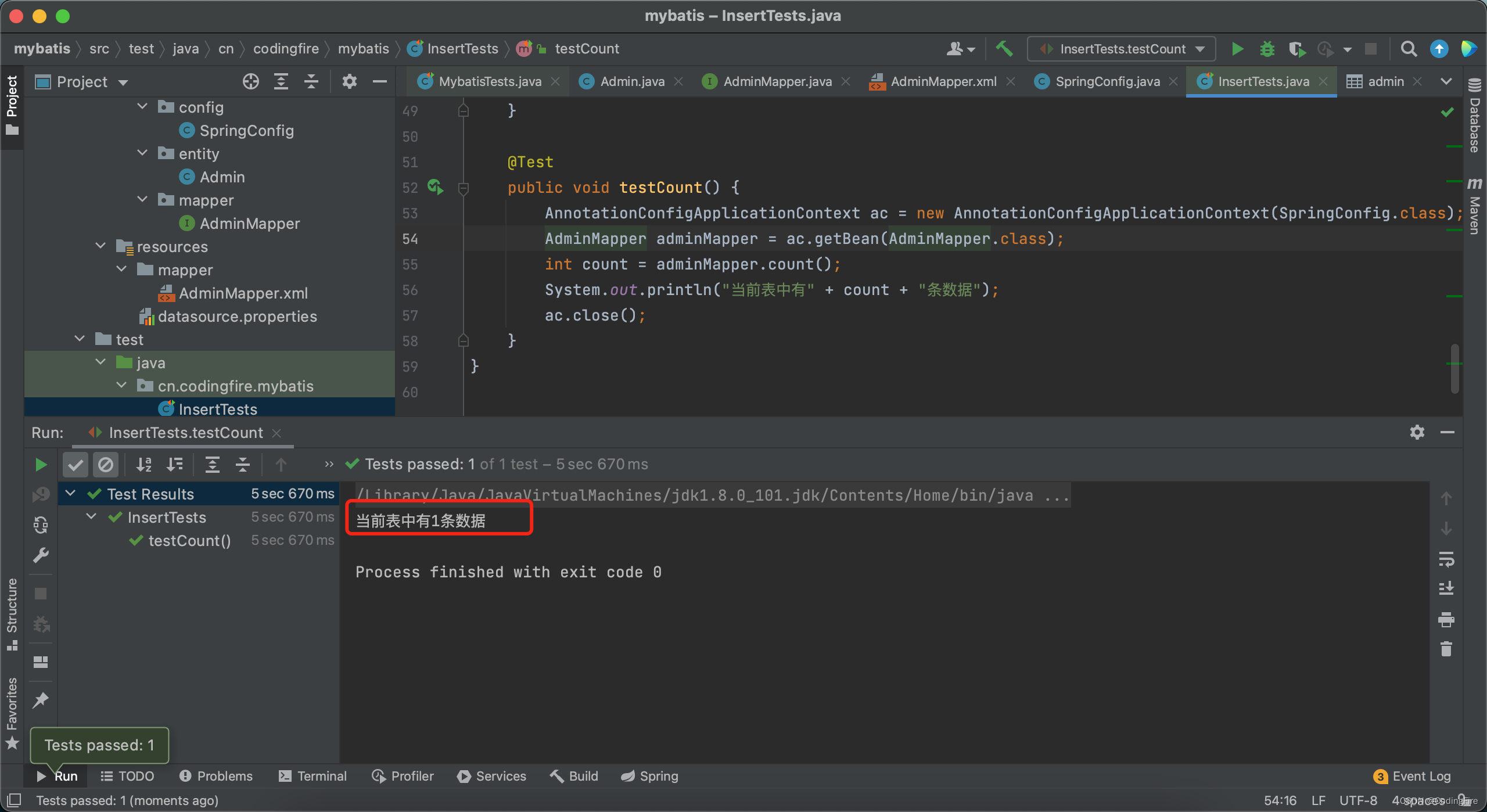
由于博主没有添加额外的数据,所以数据表中只有一条数据,同学们可以多添加点数据来进行测试。
查询具体的数据
增删改查都说过了,但是在查询数据中,我们没有针对返回引用类型的方法进行说明,本来想省略的,但想了想,实际开发都是这么返回的,不讲诉互不合适,所以再增加一条对引用类型的查询的说明。
查询具体的数据,可以是查询某一条数据,也可以是查询很多数据,所以这里做个区分。
查询一条数据
查询id为1的数据,不,应该是2,表中此时这条数据id为2,看看sql:
select * from admin where id=2
添加抽象方法如下:
Admin getById(Long id);添加方法在xml中的sql映射如下:
<select id="getById" resultType="cn.codingfire.mybatis.entity.Admin">
select * from admin where id = #{id}
</select>
这里要说明下,虽然我们确定查询id为2的数据,但却不能直接写死为2,还是要写成可配置的,实际项目中没有写死的数据。
看看,在写resultType的时候是有提醒的,所以一般不会出错,尽量不要自己写:
在测试类中添加测试方法:
@Test
public void testGetById() {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
AdminMapper adminMapper = ac.getBean(AdminMapper.class);
Long id = 2L;
Admin admin = adminMapper.getById(id);
System.out.println(admin);
ac.close();
}执行此测试方法,查看能不能找到2对应的数据:
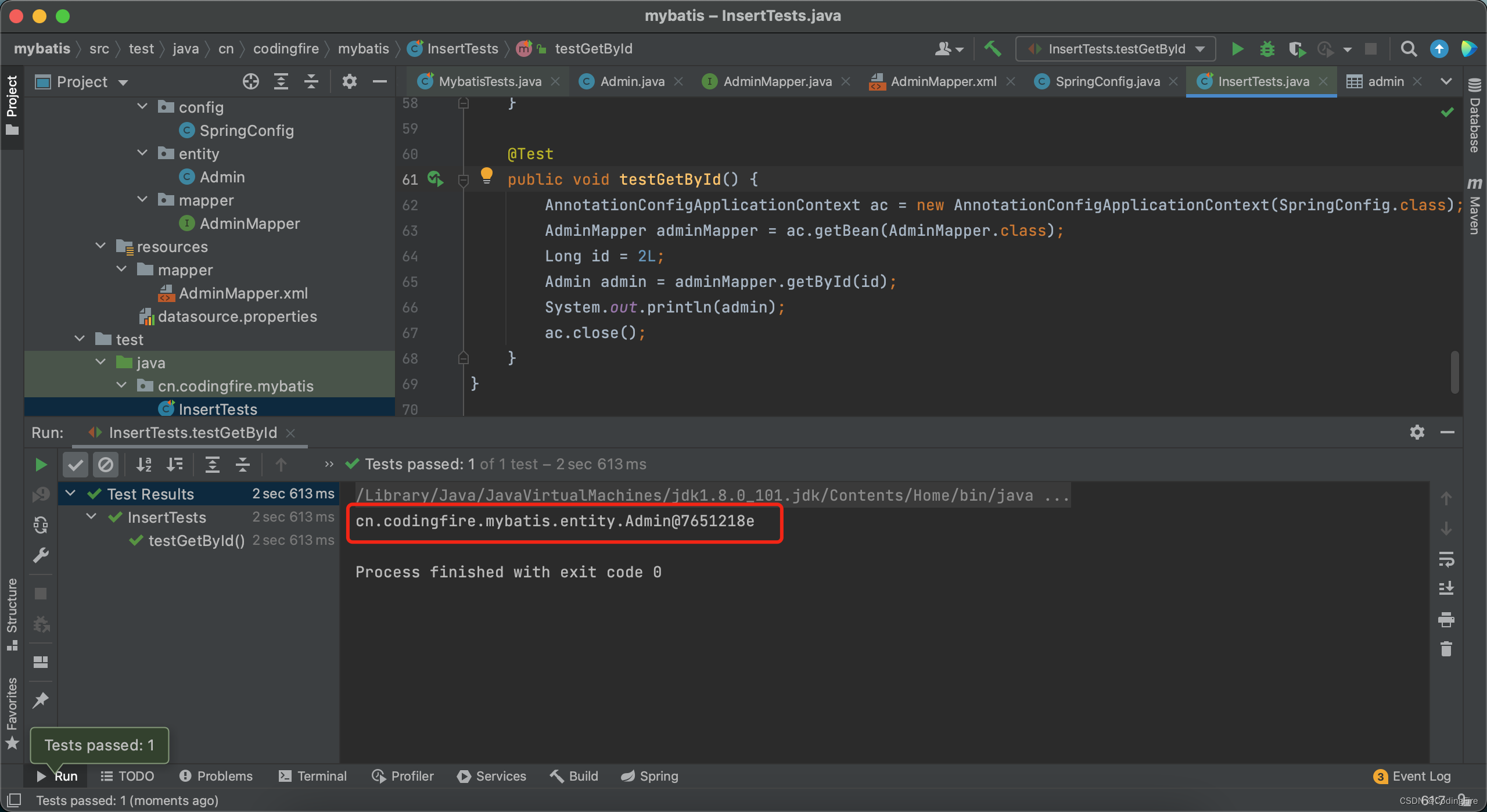
这里没看到真实数据,这时因为没有重写toString方法,我们现在去Admin类中重写toString方法:
@Override
public String toString() {
return "Admin{" +
"id=" + id +
", username='" + username + '\'' +
", password='" + password + '\'' +
", nickname='" + nickname + '\'' +
", avatar='" + avatar + '\'' +
", phone='" + phone + '\'' +
", email='" + email + '\'' +
'}';
}通过编译器自动生成,然后重新运行测试方法:
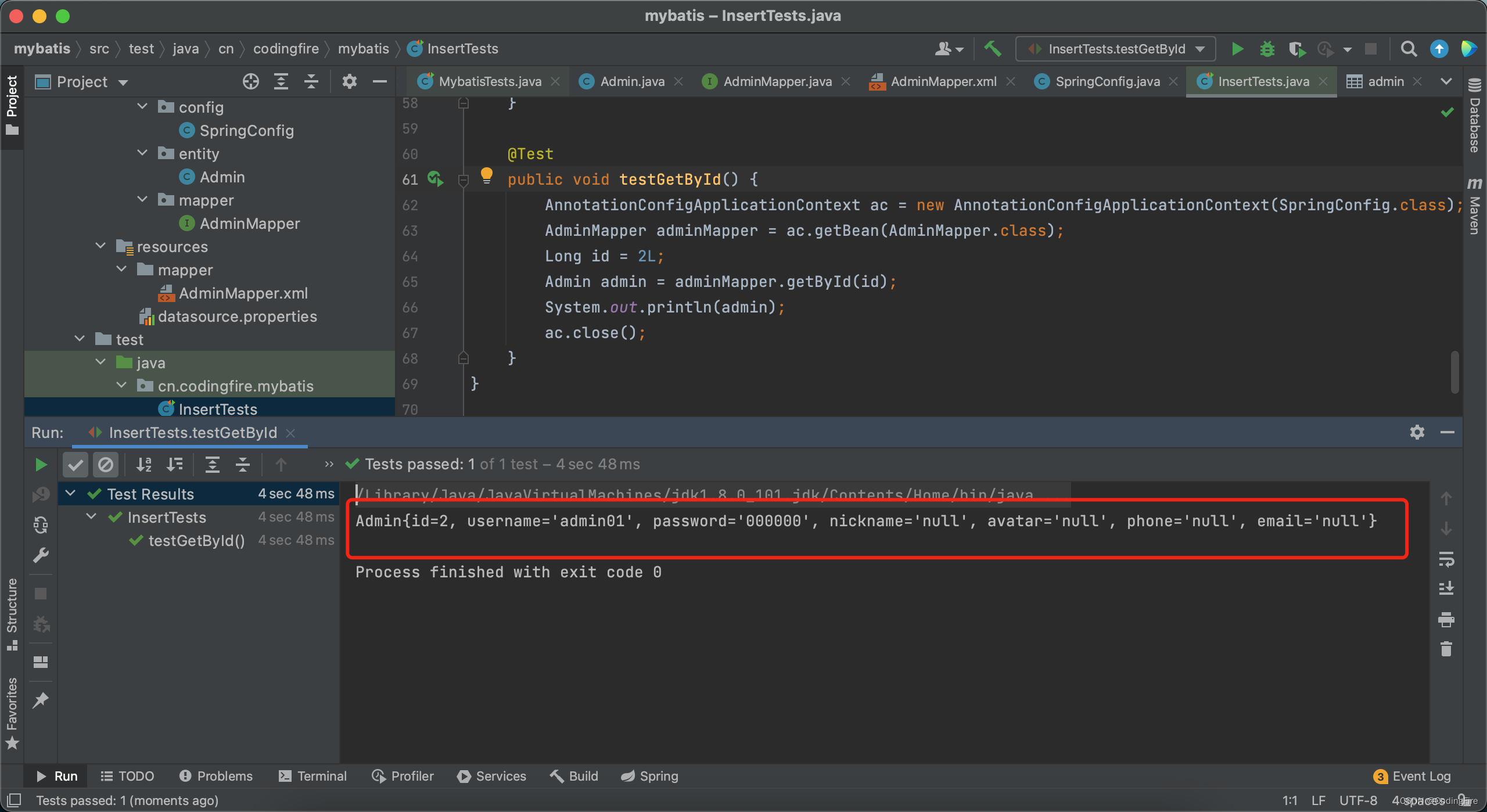
很好,数据已经出来了。查得到则返回,查不到则为null。
查询一组数据
查询一组数据和一条数据其实也很相似,只是返回值做了改变,查询时列名和属性名需一一对应,若是不对应,则此列数据将为null。为了解决此问题,我们将用到上面说到的resultMap,这种方式也是比较推荐使用的,实际开发中数据比较复杂,命名也多种多样,难免出现需要对名字进行匹配的情况,resultMap就是为了解决这种情况而存在的。
sql很简单,和上面查询几乎一样:
select * from admin where id=#{id}
xml重的映射相对要复杂一点点,但是我们的Admin类中没有定义这样的参数,为了使用resultMap,我们需要增加几个属性:
private boolean isLogin;
private String loginIp;并声称其setter和getter方法。接着我们去写其在xml中resultMap中的内容,在此之前,有些东西我们是要知道的:类中,属性名为驼峰式命名,数据库中,column名字为下划线式的,你要问能不能不这么干?我觉得类中可以不用驼峰命名法,数据库表中我还真没试过,不怕死的可以去试试。总之按照博主说的肯定没错,目前很多公司也是有这种硬性规定的,也是业内默认的。至于出处,可以自己去查查了解下。
接下来看看xml中映射怎么写:
<select id="getById" resultMap="SelectResultMap">
select *
from admin
where id = #{id}
</select>
<resultMap id="SelectResultMap" type="cn.codingfire.mybatis.entity.Admin">
<result column="is_login" property="isLogin"/>
<result column="login_ip" property="loginIp"/>
</resultMap>
由于数据库表中我们并没有is_login和login_ip属性,所以还需要额外向表中新增这两列,考验大家sql的时候到了:
alter table admin add is_login tinyint unsigned default 0 comment '是否登录,1=登录,0=未登录'; alter table admin add login_ip varchar(50) default null comment '登录ip';
运行之后,查看表中有没有多了这两列:
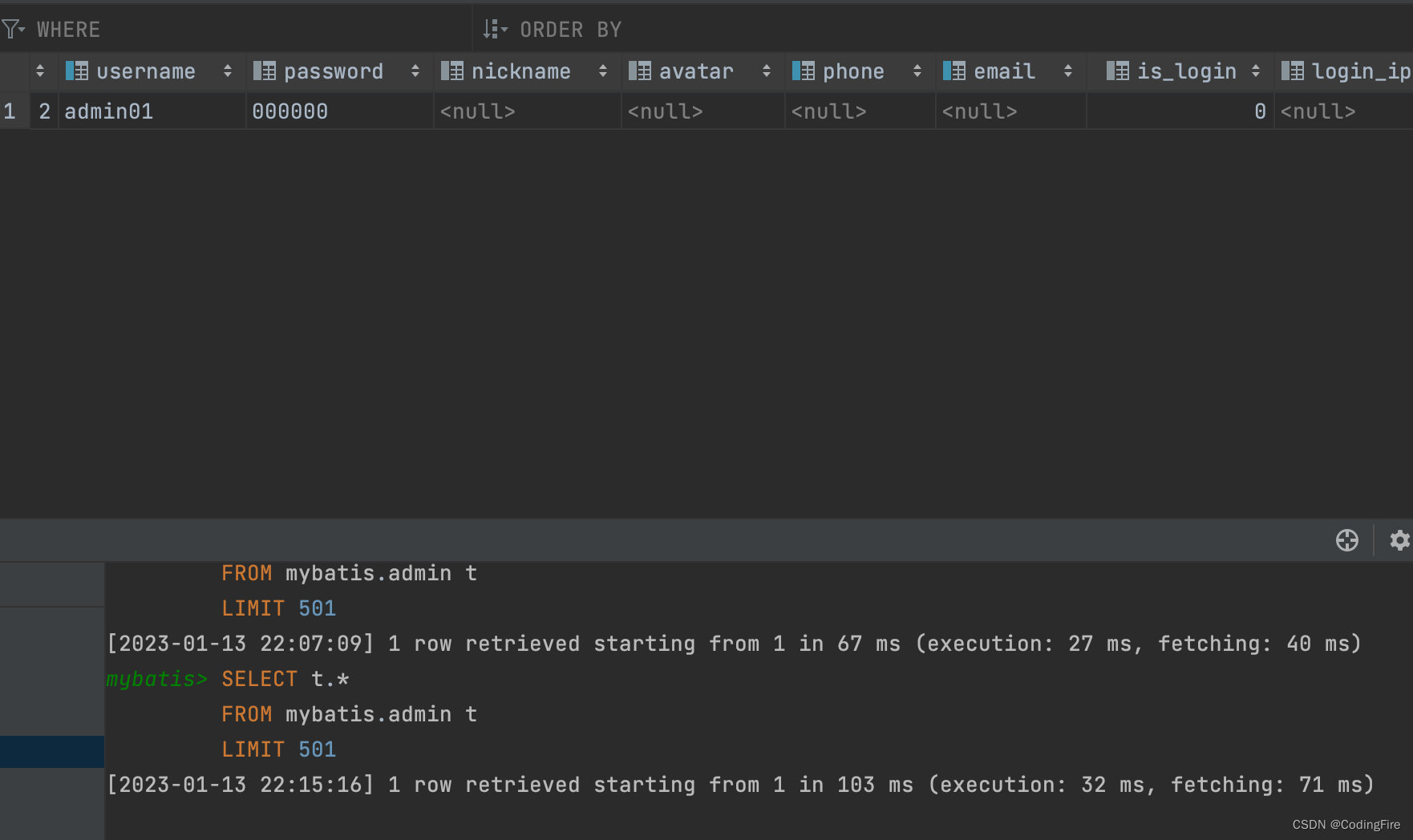
可以看到,已经成功增加了这两列,接着,我们就可以去编写抽象方法了:
List<Admin> list();这个没啥好说的,xml的sql上面已经写过了,那我们直接去写测试代码:
@Test
public void testList() {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
AdminMapper adminMapper = ac.getBean(AdminMapper.class);
List<Admin> list = adminMapper.list();
for (Admin admin : list) {
System.out.println(admin);
}
ac.close();
}运行此代码查看测试结果:
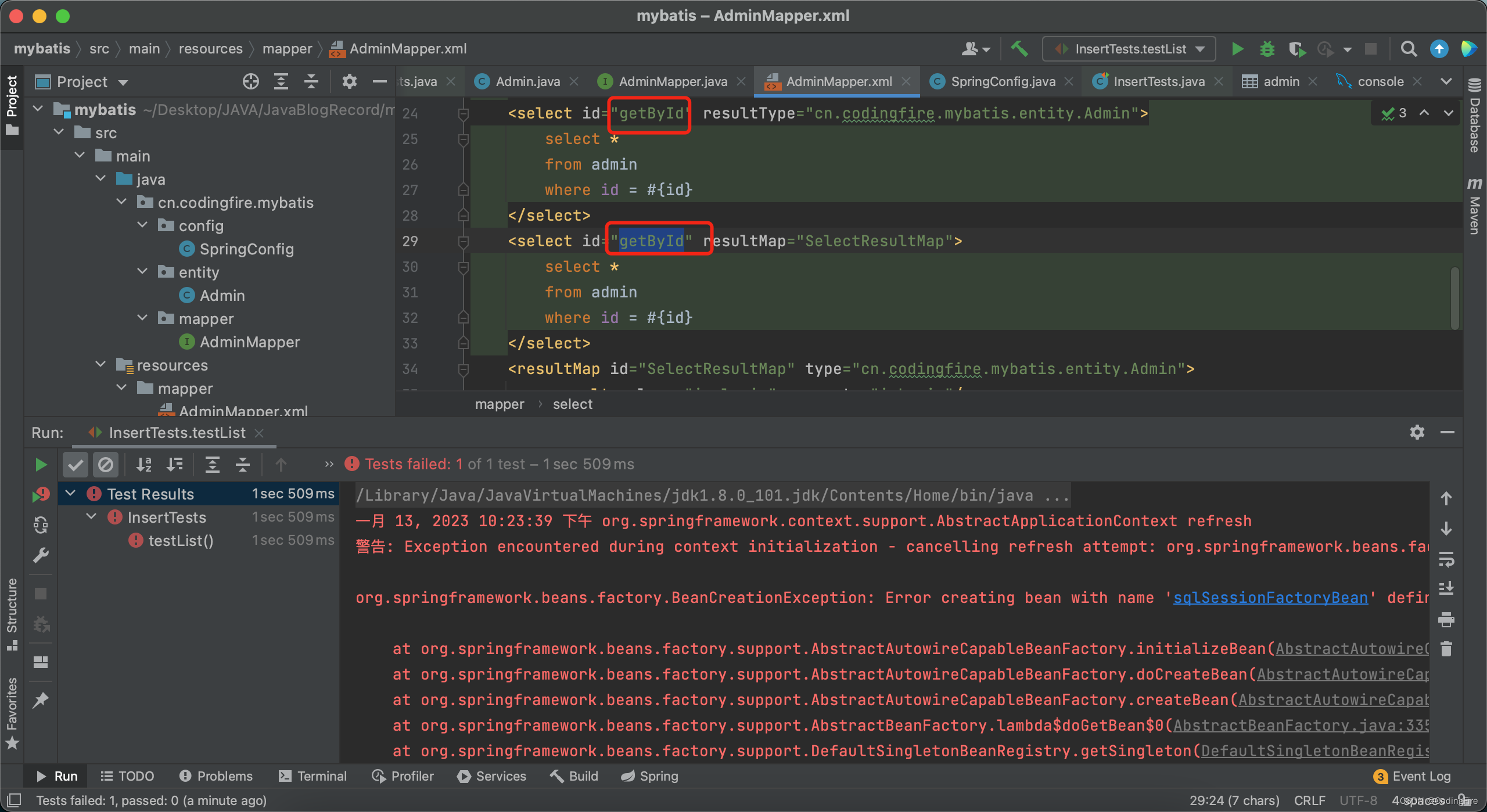
发现报错,仔细一看,发现是映射的id复制过来的之后没有改,赶紧改下,再次运行:
发现虽然没报错,但是没有任何输出。再仔细看看,发现sql语句也没改,尴尬了,赶紧改改:
<select id="list" resultMap="SelectResultMap">
select *
from admin
</select>
<resultMap id="SelectResultMap" type="cn.codingfire.mybatis.entity.Admin">
<result column="is_login" property="isLogin"/>
<result column="login_ip" property="loginIp"/>
</resultMap>
再次运行,要是海报错真的要撞墙了,为了让数据更加饱满,多跑几次插入数据后再运行:
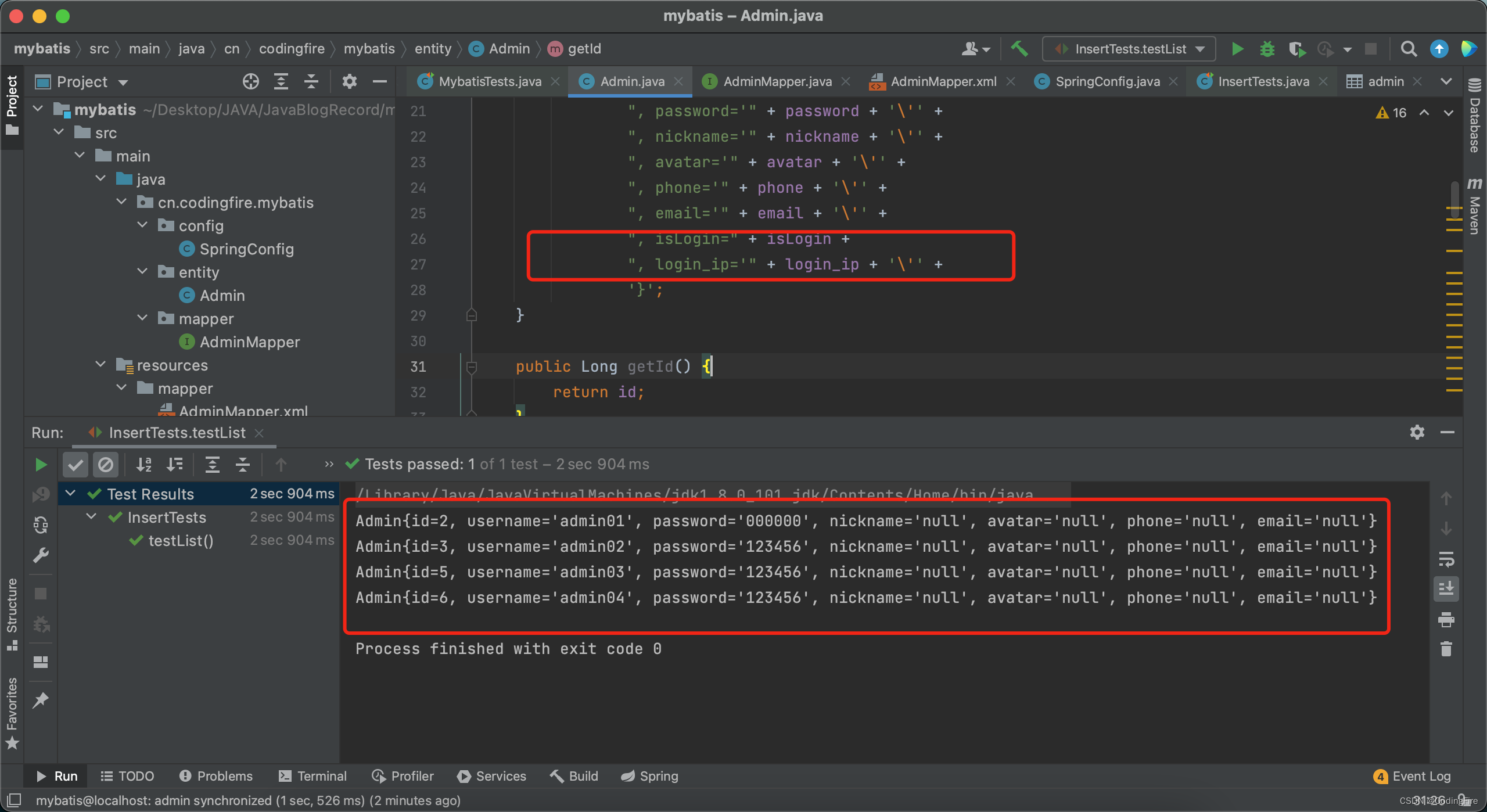
数据成果获取到,虽然成功获取,发现新添加的两个属性没有打印出来,这是因为toString方法中美与哦这两个属性,所以删除toString方法,重新生成一下,再次运行:
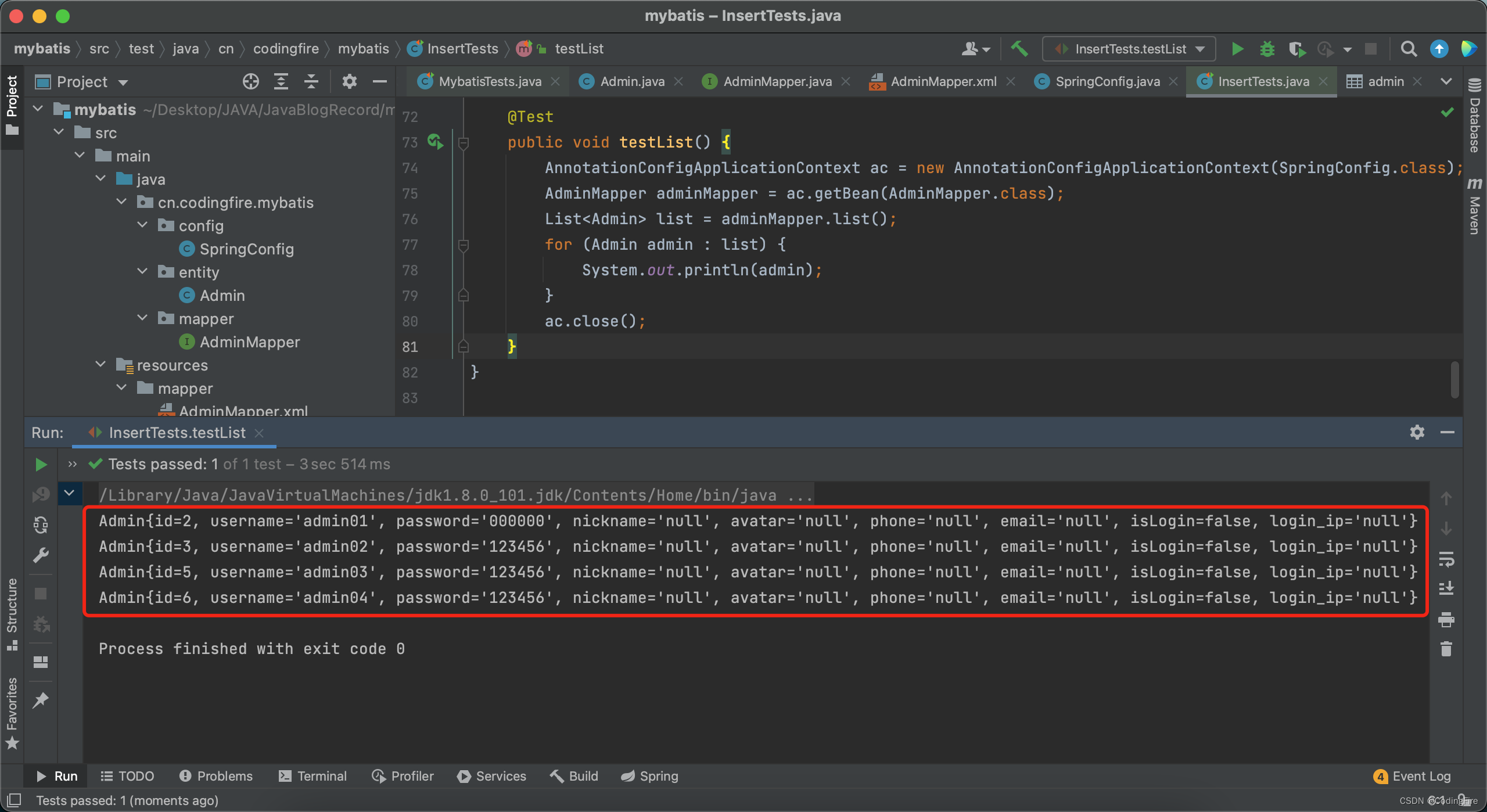
这就是我们想要的数据,到这里,你已经学会了如何返回具体的引用类型,不管是单个对象还是一个数组包含的多个对象。 但,关于xml中sql映射的学习依然没有结束,接下来,让我们继续吧。
动态sql
在Mybatis中,动态sql可以根据参数的不同,生成不同的sql语句,比如我们代码中常写的if...else...,比如需要对数组进行遍历来执行某些具体的操作。
以for...each...为例:
需求:一次性删除多条数据。
sql语句:
delete from admin where id in (?,?)
其中,id是个未知数,也许只有一个,也许有很多,我们无从得知。
接下来,我们通过详细的操作来说明foreach的使用。
和上面一样,先在AdminMapper中写抽象方法:
int deleteByIds(Long... ids);括号中参数的表示有好几种,可以修改成如下格式:
Long[] ids
List<Long> ids
此处写的为可变参数,但可变参数的本质是数组,解惑下某些同学的疑问。为了测试方便,我们选择 参数为List<Long> ids ,接着写xml文件中的映射:
<delete id="deleteByIds">
delete from admin where id in
(
<foreach collection="list" item="id" separator=",">
#{id}
</foreach>
)
</delete>
这段sql引入了新的知识,所以还是要说一说的:
- <foreach>标签用于遍历集合或数组类型的对象
- collection属性是被遍历的参数对象,当抽象方法的参数只有1个且没有添加@Param注解时,如果参数是List类型则此属性值为list,如果参数是数组类型(包括可变参数)则此属性值为array,当抽象方法的参数有多个或添加了@Param注解时,则此属性值为@Param注解中配置的值,这个值也是针对数组的值,不要以为需要遍历多个值,多个值时,其他值可能为条件
- item属性是自定义的名称,表示遍历过程中每个元素的变量名,一般我们就按照实际需要的参数来写,增加sql的可读性,然后在<foreach>内使用#{变量名}来表示这个数据
- separator属性是定义的分隔符,将自动添加到遍历的各元素之间
接着来写测试代码:
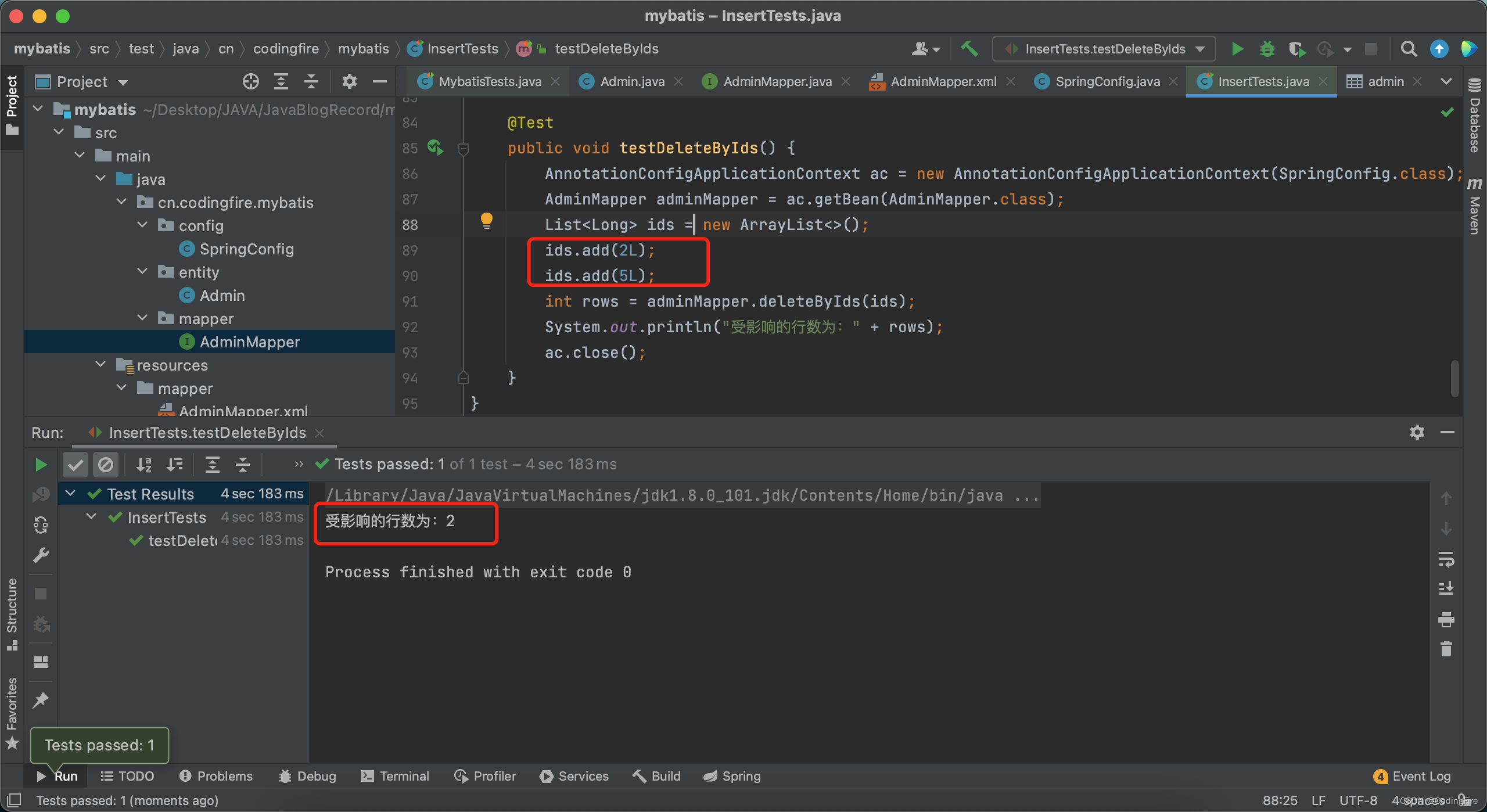
@Test
public void testDeleteByIds() {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(SpringConfig.class);
AdminMapper adminMapper = ac.getBean(AdminMapper.class);
List<Long> ids = new ArrayList<>();
ids.add(2L);
ids.add(5L);
int rows = adminMapper.deleteByIds(ids);
System.out.println("受影响的行数为:" + rows);
ac.close();
}由于博主的表中数据如下:

所以我们选择删除id为2和5的数据,执行测试代码看看结果:
查看用户表中的数据:

id为2和5的数据已经删除,动态sql测试成功。
除了foreach之外,还有<if>,<choose>,<when>等,后续再补充吧,使用方法其实都很简单,为了篇幅不至于太长,这里把理念传达给大家,可根据需要自行了解。
关联查询
关联查询是一个比较痛苦的过程,它远比我们上面学过的东西要复杂,首先,仅表就是多张,为了方便说明,我们此处以经典的RBAC设计思路来给大家讲解,大家可照猫画虎,做一些其他的尝试,毕竟实际开发中,仅单独使用一张表的情况少之又少。
上面说到RBAC,那什么是RBAC呢?RBAC是经典的用户权限管理的设计思路,全称是Role Based Access Control(基于角色的访问控制),在这种设计中,会存在三张表,分别是用户,角色,权限,也是用户模块比较常见的一种设计方式,比如我们常用的视频类app,购买VIP就有了角色,有了角色,就有了角色对应的权限,用户和角色,角色和权限,一般来说都是多对多的,我们可以想象,VIP用户也有普通用户的权限,甚至VIP之间还存在不同的种类,为了使他们彼此之间能够关联起来,我们就需要第三和第四张表了。
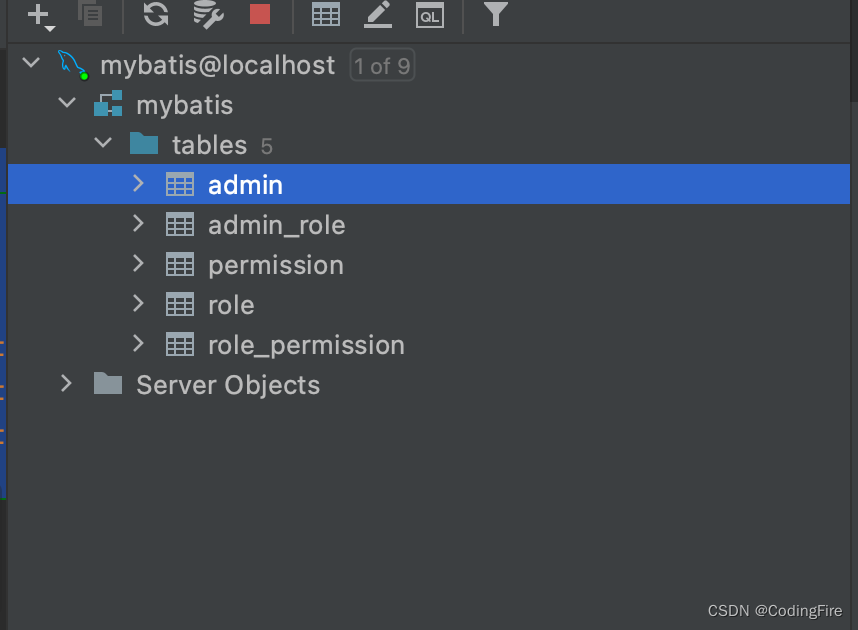
用户表已存在,我们需要在创建角色表,权限表,用户角色表,角色权限表,由于篇幅有限,参数不给太多,大家可酌情增加其他参数。
建表
角色表:
create table role
(
id bigint unsigned auto_increment,
name varchar(50) default null comment '名称',
create_time datetime default null comment '创建时间',
primary key (id)
) comment '角色' charset utf8mb4;
权限表:
create table permission
(
id bigint unsigned auto_increment,
name varchar(50) default null comment '名称',
create_time datetime default null comment '创建时间',
primary key (id)
) comment '权限' charset utf8mb4;
用户角色关联表:
create table admin_role
(
id bigint unsigned auto_increment,
admin_id bigint unsigned default null comment '用户id',
role_id bigint unsigned default null comment '角色id',
create_time datetime default null comment '创建时间',
primary key (id)
) comment '用户角色关联' charset utf8mb4;
角色权限关联表:
create table role_permission
(
id bigint unsigned auto_increment,
role_id bigint unsigned default null comment '角色id',
permission_id bigint unsigned default null comment '权限id',
create_time datetime default null comment '创建时间',
primary key (id)
) comment '角色权限关联' charset utf8mb4;
执行完这些sql之后的表情况见下图:
插入数据
现在,我们需要给已创建的表插入一些数据,然后才能做关联查询。为了保证表中数据不出问题,我们需要将用户表中的数据清空,然后再重新插入几条数据:
用户表:
truncate admin;
insert into admin (username, password) values ('admin001', '123456');
insert into admin (username, password) values ('admin002', '123456');
insert into admin (username, password) values ('admin003', '123456');
insert into admin (username, password) values ('admin004', '123456');
insert into admin (username, password) values ('admin005', '123456');
角色表:
insert into role (name) values ('svip'), ('sysvip'), ('pvip'), ('ovip');
权限表:
insert into permission (name)
values ('单频道观看'),
('单频道可筛选'),
('单频道可删除'),
('全频道读取'),
('全频道可筛选'),
('全频道可删除');
用户角色表:
insert into admin_role (admin_id, role_id)
values (1, 1),
(1, 2),
(1, 3),
(1, 4),
(2, 1),
(2, 2),
(2, 3),
(3, 1),
(3, 2),
(4, 1);
角色权限表:
insert into role_permission (role_id, permission_id)
values (1, 1),
(1, 2),
(1, 3),
(1, 4),
(1, 5),
(1, 6),
(2, 4),
(2, 5),
(2, 6),
(3, 1),
(3, 2),
(3, 3),
(4, 1);
到这里,数据就全都插入完毕,呼,造假数据真实累的很,有时候可能还不太合理,但方法就是这么个方法,我们就权当这是合理的数据,接着往下看吧。
注意事项
在创建新的数据类之前,我们需要先做几件事:
- 需要修改配置信息,将此前指定的XML文件由AdminMapper.xml改为*.xml
- 把SpringConfig类中sqlSessionFactoryBean()方法的第2个参数由Resource类型改为 Resource[]类型
- 创建新的XML文件,用于配置抽象方法对应的SQL语句
- 创建新的测试类
- 创建新的数据模型类
- 创建新的mapper类
在此不再一一赘述,大家按照注意事项创建新类,博主把自己的类贴一下给大家,方便大家使用。
创建类
Role:
package cn.codingfire.mybatis.entity;
import java.io.Serializable;
import java.time.LocalDateTime;
public class Role implements Serializable {
private Long id;
private String name;
private LocalDateTime createTime;
@Override
public String toString() {
return "Role{" +
"id=" + id +
", name='" + name + '\'' +
", createTime=" + createTime +
'}';
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public LocalDateTime getCreateTime() {
return createTime;
}
public void setCreateTime(LocalDateTime createTime) {
this.createTime = createTime;
}
}
AdminDetailVO:
package cn.codingfire.mybatis.vo;
import cn.codingfire.mybatis.entity.Role;
import java.io.Serializable;
import java.util.List;
public class AdminDetailVO implements Serializable {
private Long id;
private String username;
private String password;
private String nickname;
private String avatar;
private String phone;
private String email;
private boolean isLogin;
private String loginIp;
private List<Role> roles;
@Override
public String toString() {
return "AdminDetailVO{" +
"id=" + id +
", username='" + username + '\'' +
", password='" + password + '\'' +
", nickname='" + nickname + '\'' +
", avatar='" + avatar + '\'' +
", phone='" + phone + '\'' +
", email='" + email + '\'' +
", isLogin=" + isLogin +
", loginIp='" + loginIp + '\'' +
", roles=" + roles +
'}';
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String getNickname() {
return nickname;
}
public void setNickname(String nickname) {
this.nickname = nickname;
}
public String getAvatar() {
return avatar;
}
public void setAvatar(String avatar) {
this.avatar = avatar;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public boolean isLogin() {
return isLogin;
}
public void setLogin(boolean login) {
isLogin = login;
}
public String getLoginIp() {
return loginIp;
}
public void setLoginIp(String loginIp) {
this.loginIp = loginIp;
}
public List<Role> getRoles() {
return roles;
}
public void setRoles(List<Role> roles) {
this.roles = roles;
}
}
VO类可以理解为view object,可以认为是返回给客户端的数据模型,一般都是要聚合数据的。
最后看下项目的结构:
为了大家能够更加容易理解,类暂且不创建那么多,我们的抽象方法和sql还是写在原来的地方,方便我们查看和后续的练习。
关联查询练习
然后,我们来练习查询用户有哪些角色,先写抽象方法如下:
AdminDetailsVO getDetailsById(Long id);接着来写sql语句:
select * from admin left join admin_role on admin.id=admin_role.admin_id left join role on admin_role.role_id=role.id where admin.id=1
这里就存在问题了,查询出来的数据非常多,且不易观看,所以在查询时严禁直接使用*,而要使用具体要查询的字段明。
下面,我们来写xml中的映射sql,大家要仔细看了:
<select id="getDetailsById" resultMap="AdminDetailResultMap">
select admin.id,
admin.username,
admin.password,
admin.nickname,
admin.avatar,
admin.phone,
admin.email,
admin.isLogin,
admin.loginIp,
role.id,
role.name,
role.creatTime
from admin
left join admin_role on admin.id = admin_role.admin_id
left join role on admin_role.role_id = role.id
where admin.id = #{id};
</select>
<resultMap id="AdminDetailResultMap" type="cn.codingfire.mybatis.vo.AdminDetailVO">
<result column="id" property="id"/>
<result column="username" property="username"/>
<result column="password" property="password"/>
<result column="nickname" property="nickname"/>
<result column="avatar" property="avatar"/>
<result column="phone" property="phone"/>
<result column="email" property="email"/>
<result column="is_login" property="isLogin"/>
<result column="login_ip" property="loginIp"/>
<collection property="roles" ofType="cn.codingfire.mybatis.entity.Role">
<result column="id" property="id"/>
<result column="name" property="name"/>
<result column="create_time" property="createTime"/>
</collection>
</resultMap>
这里说明下几个知识点:
- collection可以指定数据的结构和类型
- ofType定义数据的引用类型
这里额外要知道的就是带下划线的字段的处理,前面也有用过,这里再次提及,大家要注意。
有没有发现什么问题?
是的,博主留坑了,看collection中的id,和上面的id一样,会不会冲突呢?答案是肯定的,Mybatis在处理关联查询时,结果集中出现相同的id就会认为已经处理过,则会跳过。所以要取别名,不能再使用result节点来写,那怎么写呢,我们看下面:
<select id="getDetailsById" resultMap="AdminDetailResultMap">
select admin.id,
admin.username,
admin.password,
admin.nickname,
admin.avatar,
admin.phone,
admin.email,
admin.isLogin,
admin.loginIp,
role.id AS role_id,
role.name,
role.creatTime
from admin
left join admin_role on admin.id = admin_role.admin_id
left join role on admin_role.role_id = role.id
where admin.id = #{id};
</select>
<resultMap id="AdminDetailResultMap" type="cn.codingfire.mybatis.vo.AdminDetailVO">
<result column="id" property="id"/>
<result column="username" property="username"/>
<result column="password" property="password"/>
<result column="nickname" property="nickname"/>
<result column="avatar" property="avatar"/>
<result column="phone" property="phone"/>
<result column="email" property="email"/>
<result column="is_login" property="isLogin"/>
<result column="login_ip" property="loginIp"/>
<collection property="roles" ofType="cn.codingfire.mybatis.entity.Role">
<id column="role_id" property="id"/>
<result column="name" property="name"/>
<result column="create_time" property="createTime"/>
</collection>
</resultMap>
由于查询的字段名可能会重复在其他sql使用,我们需要将其提取出来,最终的sql如下:
<sql id="adminFields">
<if test="true">
admin.id,
admin.username,
admin.password,
admin.nickname,
admin.avatar,
admin.phone,
admin.email,
admin.isLogin,
admin.loginIp,
role.id AS role_id,
role.name,
role.creatTime
</if>
</sql>
<select id="getDetailsById" resultMap="AdminDetailResultMap">
select <include refid="adminFields"/>
from admin
left join admin_role on admin.id = admin_role.admin_id
left join role on admin_role.role_id = role.id
where admin.id = #{id};
</select>
<resultMap id="AdminDetailResultMap" type="cn.codingfire.mybatis.vo.AdminDetailVO">
<result column="id" property="id"/>
<result column="username" property="username"/>
<result column="password" property="password"/>
<result column="nickname" property="nickname"/>
<result column="avatar" property="avatar"/>
<result column="phone" property="phone"/>
<result column="email" property="email"/>
<result column="is_login" property="isLogin"/>
<result column="login_ip" property="loginIp"/>
<collection property="roles" ofType="cn.codingfire.mybatis.entity.Role">
<id column="role_id" property="id" />
<result column="name" property="name"/>
<result column="create_time" property="createTime"/>
</collection>
</resultMap>
最后我们去测试类中写测试代码:
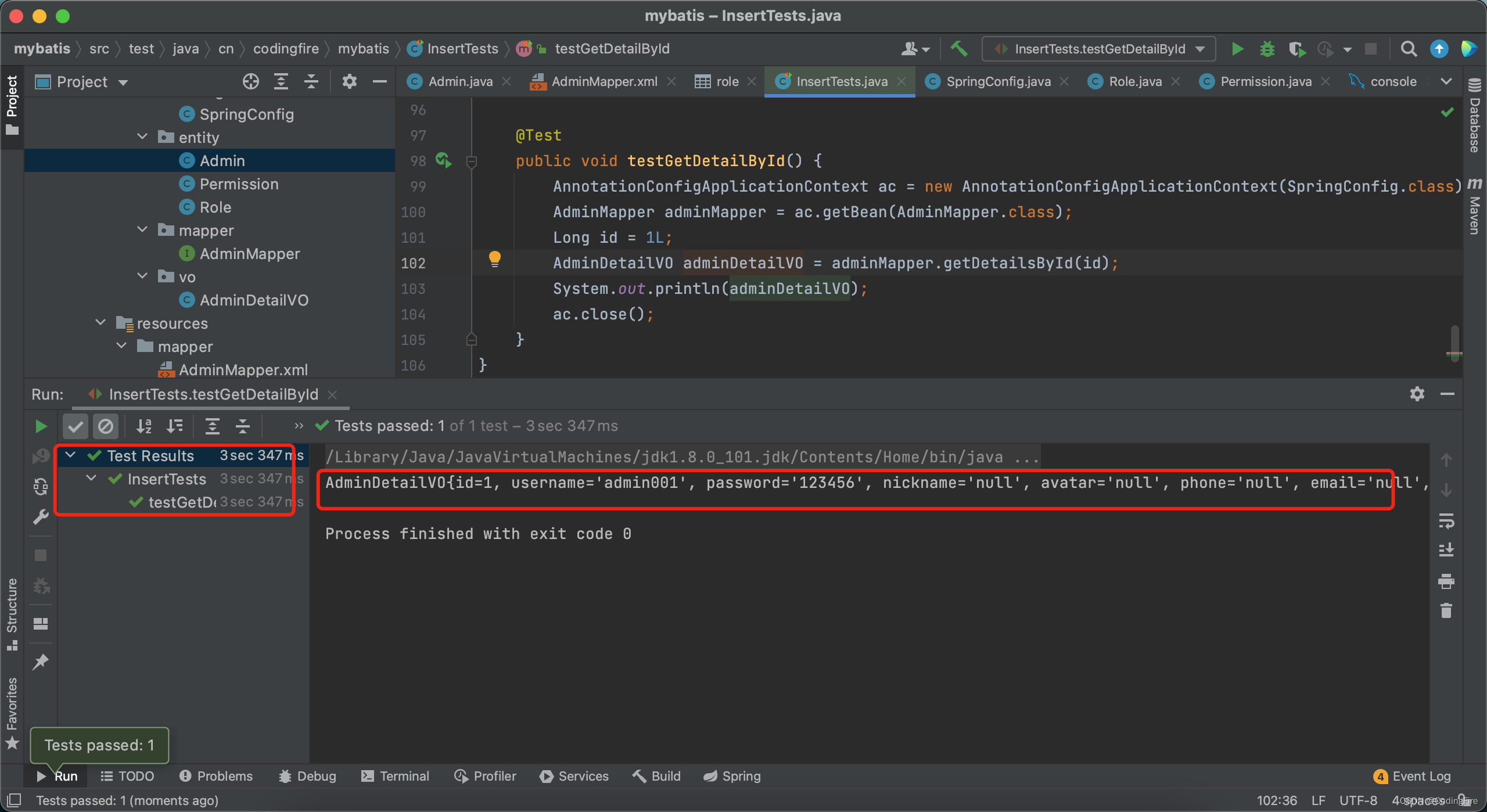
测试成功,为了查看输出数据的结构,我们用json工具转换成json格式来看一下:
{
id=1,
username='admin001',
password='123456',
nickname='null',
avatar='null',
phone='null',
email='null',
isLogin=false,
loginIp='null',
roles=[{
id=1,
name='svip',
createTime=null
},{
id=2,
name='sysvip',
createTime=null
},{
id=3,
name='pvip',
createTime=null
},{
id=4,
name='ovip',
createTime=null
}]
}
符合我们的预期,动态sql到这里就结束了,只要你稍懂sql,就可以自己写案例来练习。比如,可以查询某个用户有哪些权限,某权限对应的用户有哪些,对应的角色有哪些,某角色对应的权限等等,考验的是写sql的能力,博主不再一一带着大家来练习了。
关于占位符
我们在写sql的时候用到了占位符#{},还有另一个占位符${},虽然#{}已经多次使用,但还是有些知识点要分享给大家,另外要说明下${}的使用。
#{}占位符:使用大家依然明了,使用此占位符时,Mybatis在处理时会使用预编译,所以也不需要担心类型的问题,可以看到我们使用时没有定义类型,最最重要的一点,不存在sql注入的风险,它只能用于表示某个值,而不能表示SQL语句片段!关于这一点,如果你用过jdbc来直接写sql,应该是了解的。
${}占位符:使用此占位符,Mybatis的做法是,先将参数值代入到sql语句中,然后再执行编译相关过程,那么你就需要关心参数类型的问题,最让我们担心的是:有sql注入的风险,抛开这点不说,它可以表示sql片段。
综上所述,我们开发中更推荐使用#{}占位符,但却不排除一些特殊的情况,需要使用sql片段,此时要考虑sql注入的风险,比如,可采取正则匹配的方式来避免,方法有多种,大家可自行去详细了解。
关于Mybatis的缓存机制
缓存很多东西都有,Mybatis也不例外,缓存是一种临时存储的数据,既是临时存储,那就一定会在某个时间点删除。缓存存在的意义是提高读写的效率,但其并不是必须的,比如博主早起做移动端,那时候很多公司都做缓存,因为那时流量贵,网速慢。但随着4G,5G及Wi-Fi的普及,网速加快,流量也不再那么贵,甚至很多人还用无线流量的卡,这就导致现在做缓存的公司已经不是很多了。
缓存从某种意义来讲,也是会占用空间的,这并不是我们希望看到的,在Java中,基于此,我们有一句话来说明:用时间换空间,用空间换时间。
缓存虽然能提高效率,但要知道的是,从数据库读取数据的效率是很低的,这也是目前放弃使用缓存的一个原因,但此,仅针对移动端和前端的开发,我们后端的一些缓存机制,比如redis,es也算吧,session/JWT这些,都有涉及,却是必不可少的。
Mybatis有两级缓存,我们称之为一级缓存和二级缓存。
一级缓存是基于SqlSession的缓存,也称之为“会话缓存”,仅当是同一个会话、同一个Mapper、同一个抽象方法(同一个SQL语句)、同样的参数值时有效,一级缓存在集成框架中默认是开启的,整个过程不由人为控制,但如果是自行获取SqlSession后,可进行主动清理。
不同于一级缓存,二级缓存缓存默认全局开启,它基于namespace,所以也称为 “namespace缓存”,需要在配置sql语句的XML中添加<cache />节点, 以表示当前XML中的所有查询都允许开通二级缓存,并且,在<select>节 点上配置useCache="true",则对应的<select>节点的查询结果将被二级缓存处理,并且,此查询返回的结果的类型必须是实现了Serializable接口的,一般我们也会这么写,如果使用了<resultMap>配置封装查询结果,则必须使用<id> 节点来封装主键的映射。满足以上条件后,二级缓存将可用,只要是当前 namespace中查询出来的结果,都会根据所执行的SQL语句及参数进行值缓存。
但是有一点,只要发生了增删改操作,不论一级缓存还是二级缓存的数据都将被自动清理。由于此特性不符合开发中的需求,所以一般并不怎么用,更多的是使用redis等缓存工具自定义缓存策略。
结语
这篇文章前前后后历时将近一周才算写完,对于Mybatis框架的使用通过案例的形式进行讲解说明,如果你看到这里,说明是一步步跟下来的,那么此时你已经基本掌握Mybatis框架的使用,虽然学会了,还是要多加练习,就算博主也是长时间不看就忘记的,写完之后,有事没事来看一遍,结合使用,每一次都会有不一样的收获。今天是腊月二十四,话说二十四,扫房子,早上清理垃圾,下午把最后一点赶了出来,终于大功告成。喜欢的就点个赞再走吧。












![[apidoc]Apidoc-文档生成工具](https://img-blog.csdnimg.cn/52459d24cdac447ab41005a53841695b.png)
