目录
- 一、分类问题概述
- (一)分类规则挖掘
- (二)分类规则评估
- (三)分类规则应用
- 二、k-最近邻分类法
一、分类问题概述
动物分类:设有动物学家陪小朋友林中散步,若有动物突然从小朋友身边跑过就会问“ 这是什么动物?”,动物学家说是“松鼠”呀!这就是所谓动物的分类问题。
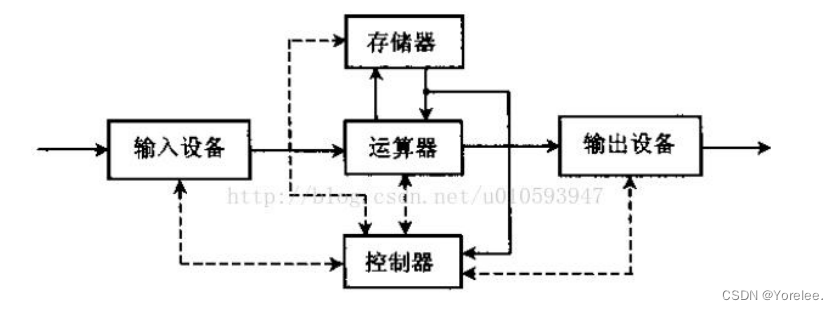
数据分类 (Data Classification) :对于一个未知类别标号的数据对象 Z u Z_u Zu,给出它的类别名称或标号。相当于动物学家看到一个动物会说出动物的名称,是因为他经历了长时间的学习,并记住了各种类动物的特性或分类规则。数据分类器是指若干分类规则的集合 (图9-1)。

分类分析 (Classification Analysis) 的三个步骤:挖掘分类规则 (建立分类器或分类模型),分类规则评估和分类规则应用。
(一)分类规则挖掘
先将一个已知类别标号的数据样本集 (也称为示例数据库) 随机地划分为训练集 S S S (通常占2/3) 和测试集 T T T 两个部。通过分析 S S S 中的所有样本点 (数据对象),为每个类别做出准确的特征描述,或建立分类模型,或挖掘出分类规则。这一步也称为有监督的 (supervised) 学习,即在模型建立之前就被告知每个训练样本。
训练集 S = { X 1 , X 2 , ⋯ , X n } S=\{X_1,X_2, \cdots, X_n\} S={X1,X2,⋯,Xn} 且每个样本点 X i X_i Xi 都对应一个已知的类别标号 C j C_j Cj(表9-1)。其中 A 1 , A 2 , ⋯ , A d A_1,A_2,\cdots,A_d A1,A2,⋯,Ad 称为样本集 S S S 的 d d d 个条件属性 (简称属性) , C C C 称为类别属性或决策属性, C j ( i = 1 , 2 , ⋯ , k ) C_j(i=1,2,\cdots,k) Cj(i=1,2,⋯,k) 又称为类别属性值或决策属性值或类别标识,并将 C = { C 1 , C 2 , ⋯ , C k } (9-1) C=\{C_1,C_2,\cdots,C_k\}\tag{9-1} C={C1,C2,⋯,Ck}(9-1) 称为 S S S 的类别属性集,也称为 S S S 的分类集。

定义9-1 对于给定的训练样本集
S
S
S 和分类属性
C
=
{
C
1
,
C
2
,
⋯
,
C
k
}
C=\{C_1,C_2,\cdots,C_k\}
C={C1,C2,⋯,Ck},如果能找到一个函数
f
f
f 满足:
①
f
:
S
→
C
f : S→C
f:S→C,即
f
f
f 是
S
S
S 到
C
C
C 的一个映射;
② 对于每个
X
i
∈
S
X_i\in S
Xi∈S 存在唯一
C
k
C_k
Ck 使
f
(
X
i
)
=
C
j
f(X_i)=C_j
f(Xi)=Cj,并记
C
j
=
{
X
i
∣
f
(
X
i
)
=
C
j
,
1
≤
j
≤
k
,
X
i
∈
S
}
C_j=\{X_i | f(X_i)=C_j, 1≤j≤k, X_i\in S\}
Cj={Xi∣f(Xi)=Cj,1≤j≤k,Xi∈S}。
则称函数
f
f
f 为分类器,或分类规则,或分类方法,其寻找过程称为分类规则挖掘等。
类别标号 C j C_j Cj 其实也代表属于该类的样本点集合,比如,我们说样本点 X 1 , X 2 , X 3 X_1 , X_2, X_3 X1,X2,X3 是 C 1 C_1 C1 类的,表示样本点 X 1 , X 2 , X 3 X_1, X_2, X_3 X1,X2,X3 属于 C 1 C_1 C1,即 C 1 = { X 1 , X 2 , X 3 } C_1=\{X_1, X_2, X_3\} C1={X1,X2,X3}。因此, C 1 C_1 C1 既是一个类别标号 (分类属性的取值),又表示属于该类所有样本点的集合。
(二)分类规则评估
对测试集 T T T 中的样本点,若有 N N N 个样本点被分类模型正确地分类,则分类模型在测试集 T T T 上的准确率定义为 “正确预测数/预测总数”,即 准确率 = N / ∣ T ∣ 准确率 = N / |T| 准确率=N/∣T∣。
由于 T T T 中的样本点已有分类标识,很容易统计分类器对 T T T 中样本进行正确分类的准确率,加之 T T T 中样本是随机选取的,且完全独立于训练集 S S S,其测试准确率高就说明分类模型是可用的。
如果直接使用训练集 S S S 进行评估,则其评估结果完全可能是乐观的,即准确率很高,但因为分类模型是由 S S S 学习而得到的,它会倾向于过分拟合训练集 S S S,而对 S S S 以外的其它数据对象进行分类却可能很不准确。因此,交叉验证法来对模型进行评估是更合理的方法。
(三)分类规则应用
如果评估分类模型的准确率可以接受,接下来就是利用这个分类器对没有类别标号的数据集 Z Z Z(表9-2)进行分类。

即从
Z
Z
Z 中任意取出一个样本点
Z
u
Z_u
Zu,将其输入分类器,所得的类别标号就是
Z
u
Z_u
Zu 所属的类别集合。
二、k-最近邻分类法
k k k-最近邻 ( k k k-Nearest Neighbour, k k kNN) 分类法是一种基于距离的分类算法,它既不需要事先建立分类模型,也无需对分类模型进行评估,而仅利用有类别标号的样本集,直接对没有类别标号的数据对象 Z u Z_u Zu 进行分类,即确定其类别标号。
假定样本集 S S S 中每个数据点都有一个唯一的类别标号,每个类别标识 C j C_j Cj 中都有多个数据对象。对于一个没有标识的数据点 Z u Z_u Zu, k k k-最近邻分类法遍历搜索样本集 S S S,找出距离 Z u Z_u Zu 最近的 k k k 个样本点,即 k k k-最近邻集 N N N,并将其中多数样本的类别标号分配给 Z u Z_u Zu。
算法9-1 k k k-最近邻分类算法
输入:已有类别标号的样本数据集 S S S,最近邻数目 k k k,一个待分类的数据点 Z u Z_u Zu
输出:输出类别标号 C u C_u Cu
(1)初始化 k k k-最近邻集: N = ϕ N=\phi N=ϕ;
(2)对每一个 X i ∈ S X_i\in S Xi∈S,分两种情况判断是否将其并入 N N N
① 如果 ∣ N ∣ ≤ k |N|≤k ∣N∣≤k,则 N = N ∪ { X } N=N\cup\{X\} N=N∪{X}
② 如果 ∣ N ∣ > k |N|>k ∣N∣>k,存在 d ( Z u , X j ) = m a x { d ( Z u , X r ) ∣ X r ∈ N } d(Z_u,X_j)=max\{d(Z_u,X_r)|X_r\in N\} d(Zu,Xj)=max{d(Zu,Xr)∣Xr∈N}且 d ( Z u , X j ) > d ( Z u , X i ) d(Z_u,X_j)>d(Z_u,X_i) d(Zu,Xj)>d(Zu,Xi)
则 N = N − { X j } ; N = N ∪ { X i } N=N-\{X_j\};N=N\cup\{X_i\} N=N−{Xj};N=N∪{Xi};
(3)若 X u X_u Xu是 N N N中数量最多的数据对象,则输出 X u X_u Xu的类别标号 C u C_u Cu,即 Z u Z_u Zu的类别标号为 C u C_u Cu
例9-1 设某公司现有15名员工的基本信息,包括其个子为高个、中等、矮个的分类标识。

公司现刚招进一位名叫刘平的新员工
Z
1
Z_1
Z1,令
k
=
5
k=5
k=5,试采用
k
k
k-最近邻分类算法判断员工刘萍的个子属于哪一类?

解:只有身高才是与个子高矮相关的属性,因此用
X
i
X_i
Xi表示第
i
i
i个员工的身高。
首先从 X X X中选择5个员工作为初始 k k k-最近邻集 N N N。不失一般性,取 N = { X 1 = 1.60 , X 2 = 2.00 , X 3 = 1.90 , X 4 = 1.88 , X 5 = 1.70 } N=\{X_1=1.60, X_2=2.00, X_3=1.90,X_4=1.88,X_5=1.70\} N={X1=1.60,X2=2.00,X3=1.90,X4=1.88,X5=1.70}(1)对 S S S的 X 6 = 1.85 X_6=1.85 X6=1.85,身高 X 2 = 2.00 X_2=2.00 X2=2.00是 N N N中与身高 Z 1 = 1.62 Z_1=1.62 Z1=1.62差距最大的员工,且有 d ( Z 1 , X 2 ) > d ( Z 1 , X 6 ) d(Z_1,X_2)>d(Z_1,X_6) d(Z1,X2)>d(Z1,X6),因此,在 N N N中用 X 6 X_6 X6替换 X 2 X_2 X2得到 N = { X 1 = 1.60 , X 6 = 1.85 , X 3 = 1.90 , X 4 = 1.88 , X 5 = 1.70 } N=\{X_1=1.60, X_6=1.85, X_3=1.90, X_4=1.88, X_5=1.70\} N={X1=1.60,X6=1.85,X3=1.90,X4=1.88,X5=1.70}(2)同理,用 S S S中 X 7 = 1.59 X_7=1.59 X7=1.59替换 N N N中身高距离 Z 1 = 1.65 Z_1=1.65 Z1=1.65最大的员工 X 3 = 1.90 X_3=1.90 X3=1.90,得到 N = { X 1 = 1.60 , X 6 = 1.85 , X 7 = 1.59 , X 4 = 1.88 , X 5 = 1.70 } N=\{X_1=1.60, X_6=1.85, X_7=1.59, X_4=1.88, X_5=1.70\} N={X1=1.60,X6=1.85,X7=1.59,X4=1.88,X5=1.70}(3)用 X 8 = 1.70 > X_8=1.70> X8=1.70>替换 N N N中距离 Z 1 Z_1 Z1最大的员工 X 6 = 1.85 X_6=1.85 X6=1.85,得到 N = { X 1 = 1.60 , X 8 = 1.70 , X 7 = 1.59 , X 4 = 1.88 , X 5 = 1.70 } N=\{X_1=1.60, X_8=1.70, X_7=1.59, X_4=1.88, X_5=1.70\} N={X1=1.60,X8=1.70,X7=1.59,X4=1.88,X5=1.70};
(4)因为 S S S中的 X 9 = 2.20 X_9=2.20 X9=2.20和 X 10 = 2.10 X_{10}=2.10 X10=2.10,故根据算法, N N N不需要改变。
(5)用 X 11 = 1.8 X_{11}=1.8 X11=1.8替换 N N N中 X 11 = 1.88 X_{11}=1.88 X11=1.88得 N = { X 1 = 1.60 , X 8 = 1.70 , X 7 = 1.59 , X 11 = 1.80 , X 5 = 1.70 } N=\{X_1=1.60, X_8=1.70, X_7=1.59, X_{11}=1.80, X_5=1.70\} N={X1=1.60,X8=1.70,X7=1.59,X11=1.80,X5=1.70}(6)因为 S S S中的 X 12 = 1.95 , X 13 = 1.90 , X 14 = 1.80 X_{12}=1.95, X_{13}=1.90, X_{14}=1.80 X12=1.95,X13=1.90,X14=1.80,故 N N N不需要改变。
(7)用 X 15 = 1.75 X_{15}=1.75 X15=1.75替换 N N N中 X 11 = 1.8 X_{11}=1.8 X11=1.8得 N = { X 1 = 1.60 , X 8 = 1.70 , X 7 = 1.59 , X 15 = 1.75 , X 5 = 1.70 } N=\{X_1=1.60, X_8=1.70, X_7=1.59, X_{15}=1.75, X_5=1.70\} N={X1=1.60,X8=1.70,X7=1.59,X15=1.75,X5=1.70}(8)在第(7)步所得 N N N中,有5个身高最接近 Z 1 = 1.62 Z_1=1.62 Z1=1.62的员工,且其 X 1 = 1.60 , X 8 = 1.70 , X 7 = 1.59 , X 5 = 1.70 X_1=1.60,X_8=1.70,X_7=1.59,X_5=1.70 X1=1.60,X8=1.70,X7=1.59,X5=1.70 这4个员工的类别都是 “矮个”,仅有 X 15 = 1.75 X_{15}=1.75 X15=1.75的类别是 “中等”;因此,新员工 Z 1 = 刘平 Z_1=刘平 Z1=刘平 的个子为矮个。