系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
目录
- 系列篇章💥
- 前言
- 一、Model类型概览
- 二、Model Head详解
- 三、Model API调用实践
- 1、模型的保存
- 2、模型的加载
- 3、模型加载参数
- 4、模型调用
- 5、不带Model Head的模型调用
- 6、带Model Head的模型调用
- 总结
前言
随着自然语言处理(NLP)领域的不断发展,各种预训练模型层出不穷。其中,基于Transformer架构的预训练模型在各种任务中取得了显著的成果。Hugging Face的transformers库提供了丰富的预训练模型和相关组件,使得研究人员和开发者能够轻松地使用这些模型进行各种NLP任务。本文将介绍transformers库中的Model组件,包括不同类型的预训练模型、Model Head以及如何调用这些模型进行推理。通过本文的介绍,大家可以更好地理解和应用transformers库中的Model组件。
一、Model类型概览
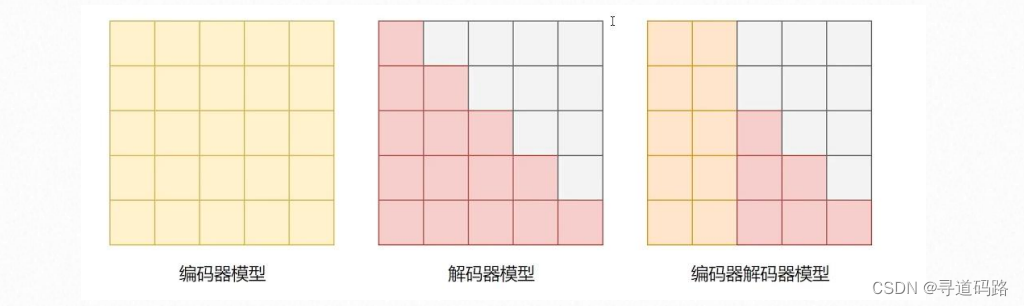
目前基于Transformer的模型主要存在以下三种:
1)仅仅包含Transformer的编码器模型(自编码模型):使用Encoder,可以从两个方向进行编码,拥有双向的注意力机制,即计算每一个词的特征时都看到完整上下文。常见仅仅存在编码器的预训练模型有:ALBERT、BERT、DistilBERT、RoBERTa等。经常被用于的任务:文本分类,命名实体识别,阅读理解等。
2)仅仅存在Transformer的解码器模型:(自回归模型),使用Decoder,拥有单向的注意力机制,即计算每一个词的特征时都只能看到上文,无法看到下文。常见的预训练模型:GPT、GPT-2、GPT-3、Bloom、LLaMA等。经常被用于文本生成中。
3)具有Transformers的编码器-解码器:(序列到序列模型),使用Encoder+Decoder,Encoder部分使用双向的注意力,Decoder部分使用单向注意力。常见的预训练模型为:BART、T5、mBART、GLM等。被用于文本摘要和机器翻译中。
二、Model Head详解
Model head是模型架构中用于处理特定任务的关键组件,它负责将模型编码的表示映射到任务所需的输出格式:(它们在预训练模型的基础上添加了一层或多层额外的网络结构,以适应任务需求,比如针对特定任务设计分类、问答或生成)
1)ForCausalLM:这是带有因果语言建模头的模型,通常用于解码器(Decoder)类型的任务。这种类型的任务包括文本生成或文本完成,其中生成的每个新词都依赖于之前生成的所有词。
2)ForMaskedLM:这是带有掩码语言建模头的模型,用于编码器(Encoder)类型的任务。这种任务涉及预测文本中被掩盖或隐藏的词,BERT模型就是这种类型的一个例子。
3)ForSeq2SeqLM:这是带有序列到序列语言建模头的模型,适用于需要编码器和解码器共同工作的任务,如机器翻译或文本摘要。
4)ForMultiplechoice:这是用于多项选择任务的模型,它处理包含多个候选答案的输入,并预测正确答案的索引。
5)ForQuestionAnswering:这是问答任务的模型,它从给定的文本中抽取答案。这种模型通常包括一个编码器来理解问题和上下文,然后是一个答案抽取机制。
6)ForSequenceClassification:这是用于文本分类任务的模型,它将整个输入序列映射到一个或多个标签。例如,情感分析或主题分类。
7)ForTokenClassification:这是用于标记分类任务的模型,如命名实体识别(NER),它将序列中的每个标记映射到一个预定义的标签。
这些Model Head提供了一种方便的方法来加载预训练的模型,并针对特定任务进行微调或直接使用。在transformers库中,这些类允许研究人员和开发者快速实现和测试不同的NLP任务,而无需从头开始设计和实现模型架构。
三、Model API调用实践
1、模型的保存
1)直接使用git将模型下载到本地
git clone "https://huggingface.co/hfl/rbt3"
2)save_pretrained保存训练模型
一旦模型被训练完成,你可以使用模型的save_pretrained方法来保存模型和分词器。这通常涉及指定一个保存模型的目录路径。以下是如何保存模型和分词器的示例:
# 假设model是一个已经训练好的模型实例
# 假设tokenizer是与model相对应的分词器实例
# 指定保存模型和分词器的目录路径
model_save_path = "path_to_save_model"
tokenizer_save_path = "path_to_save_tokenizer"
# 保存模型
model.save_pretrained(model_save_path)
# 保存分词器
tokenizer.save_pretrained(tokenizer_save_path)
在这个例子中,model_save_path和tokenizer_save_path是你希望保存模型和分词器的目录路径。运行这段代码后,模型和分词器的状态将被保存在指定的目录中,每个目录通常包含多个文件,例如模型的权重文件、配置文件等
2、模型的加载
from transformers import AutoConfig, AutoModel, AutoTokenizer
1)在线加载
model = AutoModel.from_pretrained("hfl/rbt3", force_download=True)

2)离线加载
model = AutoModel.from_pretrained("/root/代码/Model组件/rbt3")
3、模型加载参数
模型加载
从预训练模型的权重文件中加载整个模型,包括模型的结构、权重等信息。这样可以在需要使用预训练模型进行推理或者继续训练时,直接加载整个模型。
model = AutoModel.from_pretrained("/root/代码/Model组件/rbt3")
model.config
输出
BertConfig {
"_name_or_path": "/root/代码/Model组件/rbt3",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 3,
"output_past": true,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"position_embedding_type": "absolute",
"transformers_version": "4.35.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 21128
}
加载配置信息
是从预训练模型的配置文件中加载配置信息,而不是整个模型。这样可以在不下载整个模型的情况下,仅加载模型的配置信息
config = AutoConfig.from_pretrained("/root/代码/Model组件/rbt3")
Config
输出
BertConfig {
"_name_or_path": "/root/代码/Model组件/rbt3",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 3,
"output_past": true,
"pad_token_id": 0,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"position_embedding_type": "absolute",
"transformers_version": "4.35.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 21128
}
4、模型调用
sen = "今天天气不错,我的心情也不错!"
tokenizer = AutoTokenizer.from_pretrained("/root/代码/Model组件/rbt3")
inputs = tokenizer(sen, return_tensors="pt")
inputs
输出
{'input_ids': tensor([[ 101, 4696, 679, 7231, 8013, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1]])}
5、不带Model Head的模型调用
下面代码从指定路径加载一个预训练的模型,并在加载时设置了output_attentions=True。这意味着模型在推理时不仅会输出最终的logits或预测结果,还会输出每个层的注意力权重。这通常用于调试或分析模型的内部工作机制。
model = AutoModel.from_pretrained("/root/代码/Model组件/rbt3", output_attentions=True)
output = model(**inputs)
output
输出
BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=tensor([[[ 0.3299, 0.8761, 1.1550, ..., -0.2296, 0.3674, 0.1555],
[ 0.6773, -0.5668, 0.0701, ..., -0.3799, -0.2055, -0.2795],
[ 0.0841, -0.0825, 0.5001, ..., -0.3421, -0.8017, 0.3085],
[ 0.0224, 0.4439, -0.1954, ..., -0.0618, -0.2570, -0.1142],
[ 0.1476, 0.7324, -0.2727, ..., -0.1874, 0.1372, -0.3034],
[ 0.3260, 0.8858, 1.1529, ..., -0.2277, 0.3656, 0.1587]]],
grad_fn=<NativeLayerNormBackward0>), pooler_output=tensor([[ 2.3760e-02, -9.9773e-01, -9.9995e-01, -7.9692e-01, 9.9645e-01,
1.8497e-01, -2.9150e-01, -1.9350e-02, 9.9650e-01, 9.9989e-01,
1.6279e-01, -1.0000e+00, -3.5968e-02, 9.9875e-01, -9.9999e-01,
9.9879e-01, 9.9744e-01, 8.8014e-01, -9.8801e-01, 8.8588e-03,
-9.3252e-01, -7.1405e-01, 2.3119e-01, 9.7772e-01, 9.9352e-01,
-9.9826e-01, -9.9987e-01, -7.6323e-02, -8.6268e-01, -9.9992e-01,
。。。
-1.0000e+00, -1.0385e-02, 3.3378e-01, -9.7509e-01, -3.8623e-01,
-9.2922e-01, 1.8362e-01, 9.9848e-01, -6.6866e-01, 9.1038e-01,
-9.6579e-01, -9.9962e-01, 1.7735e-01, -9.9997e-01, 9.8384e-01,
1.0000e+00, -1.6213e-01, 9.7850e-01, -9.0667e-01, 1.2217e-01,
-9.9999e-01, -9.9999e-01, 8.7128e-01, 9.9946e-01, 1.0102e-01,
-9.9855e-01, 1.5214e-01, -9.9987e-01, -2.8880e-01, 5.7587e-01,
9.9336e-01, -9.9998e-01, 9.9947e-01, -6.4215e-01, 1.2852e-01,
9.8215e-01, -1.0000e+00, 8.4377e-01, -9.9904e-01, 9.9924e-01,
-1.0000e+00, 9.9885e-01, 9.1444e-02, 2.1949e-01, 3.0374e-01,
9.7917e-01, -9.9957e-01, -1.9862e-01, 9.8820e-01, 9.9878e-01,
-4.6083e-01, 9.8808e-01, 2.5509e-02]], grad_fn=<TanhBackward0>), hidden_states=None, past_key_values=None, attentions=(tensor([[[[5.6623e-01, 8.2719e-04, 7.1828e-04, 3.0170e-04, 3.7589e-04,
4.3154e-01],
[1.0803e-02, 1.0227e-01, 1.1626e-01, 2.4532e-01, 5.2110e-01,
4.2390e-03],
[4.1117e-02, 1.4175e-01, 2.8284e-01, 2.3116e-01, 2.9142e-01,
1.1724e-02],
[3.2763e-02, 1.7774e-01, 8.3885e-02, 1.2232e-01, 5.7365e-01,
9.6361e-03],
[9.1095e-02, 8.2052e-02, 7.2211e-02, 6.6084e-02, 6.5778e-01,
3.0778e-02],
[6.0973e-01, 1.3369e-03, 1.1642e-03, 7.6050e-04, 1.2266e-03,
3.8578e-01]],
...
[[4.1663e-01, 2.5743e-02, 3.3069e-02, 2.7573e-02, 4.8997e-02,
4.4799e-01],
[9.3001e-01, 2.1486e-02, 2.9548e-02, 5.0943e-03, 5.1063e-03,
8.7589e-03],
[5.5021e-02, 8.8170e-01, 3.0817e-02, 7.5048e-03, 2.2834e-02,
2.1212e-03],
[3.3265e-02, 1.9535e-02, 9.0744e-01, 1.3685e-02, 1.4819e-02,
1.1257e-02],
[1.7344e-01, 1.0500e-01, 1.1638e-01, 5.0705e-01, 7.0892e-02,
2.7225e-02],
[7.2889e-02, 9.4428e-03, 1.2270e-02, 2.8002e-02, 4.1791e-01,
4.5948e-01]]]], grad_fn=<SoftmaxBackward0>), tensor([[[[4.5796e-01, 9.9558e-03, 1.0020e-02, 2.2092e-02, 6.5916e-02,
4.3405e-01],
[4.3907e-01, 8.2675e-03, 1.1408e-01, 9.8204e-03, 6.1844e-03,
4.2258e-01],
[2.1006e-01, 5.2901e-01, 3.7502e-03, 1.8742e-03, 3.6851e-02,
2.1846e-01],
[3.0209e-01, 1.3334e-04, 3.6354e-01, 1.5319e-03, 4.1311e-02,
2.9139e-01],
[8.7918e-02, 2.8945e-02, 3.2605e-03, 7.6759e-01, 2.3085e-02,
8.9203e-02],
[4.5857e-01, 9.8717e-03, 9.9597e-03, 2.0971e-02, 6.6149e-02,
4.3448e-01]],
...
[[5.0059e-01, 1.7413e-03, 9.1523e-04, 5.8339e-03, 6.8815e-03,
4.8404e-01],
[4.3327e-01, 3.0781e-02, 1.8540e-02, 4.1750e-02, 4.3144e-02,
4.3252e-01],
[4.6648e-01, 1.6748e-02, 2.3486e-03, 4.6985e-02, 7.2329e-03,
4.6021e-01],
[4.6306e-01, 8.3569e-03, 5.8932e-03, 5.5269e-02, 1.3125e-02,
4.5429e-01],
[4.5754e-01, 3.4543e-02, 7.7011e-03, 2.6113e-02, 2.0748e-02,
4.5336e-01],
[5.0072e-01, 1.7318e-03, 9.1770e-04, 5.7174e-03, 6.6844e-03,
4.8423e-01]]]], grad_fn=<SoftmaxBackward0>), tensor([[[[3.1533e-01, 6.1664e-02, 3.2057e-02, 7.3921e-02, 2.0709e-01,
3.0993e-01],
[3.5292e-01, 9.7867e-02, 7.6420e-02, 5.6472e-02, 6.7811e-02,
3.4851e-01],
[3.7263e-01, 1.6694e-01, 4.0402e-02, 3.4887e-02, 1.7787e-02,
3.6736e-01],
[4.6658e-01, 3.5042e-02, 9.0006e-03, 1.9572e-02, 1.0726e-02,
4.5908e-01],
[3.6866e-01, 7.5453e-02, 4.1273e-02, 4.2048e-02, 1.1026e-01,
3.6231e-01],
[3.1706e-01, 6.0658e-02, 3.1613e-02, 7.3170e-02, 2.0586e-01,
3.1164e-01]],
...
[[2.7216e-01, 1.2583e-01, 5.1468e-02, 8.0823e-02, 2.0379e-01,
2.6593e-01],
[1.3690e-01, 3.7407e-02, 4.5398e-01, 2.0540e-01, 3.1681e-02,
1.3463e-01],
[2.4628e-01, 1.2131e-02, 9.3940e-03, 3.9019e-01, 9.8574e-02,
2.4343e-01],
[4.4038e-01, 3.6646e-03, 3.7501e-03, 2.5508e-02, 8.7129e-02,
4.3957e-01],
[3.6957e-01, 3.0530e-02, 6.2554e-02, 1.2588e-01, 4.2998e-02,
3.6847e-01],
[2.7344e-01, 1.2471e-01, 5.0839e-02, 8.0282e-02, 2.0355e-01,
2.6718e-01]]]], grad_fn=<SoftmaxBackward0>)), cross_attentions=None)
6、带Model Head的模型调用
下面代码使用AutoModelForSequenceClassification类加载一个用于序列分类任务的预训练模型。这个类是专门用于文本分类任务的,如情感分析或主题分类,它期望输出是整个输入序列的分类结果。它从指定路径加载模型,并使用inputs进行推理。
from transformers import AutoModelForSequenceClassification, BertForSequenceClassification
clz_model = AutoModelForSequenceClassification.from_pretrained("/root/代码/Model组件/rbt3")
clz_model(**inputs)
输出
SequenceClassifierOutput(loss=None, logits=tensor([[0.2360, 0.2302]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)
1)这段代码中的模型调用使用了带有特定Model Head的模型。在Transformer模型架构中,Model Head(模型头部)是指模型主体结构之后的输出层,它根据具体任务对模型的输出进行适配和映射。Model Head通常包含了一些额外的全连接层或其他特定于任务的结构
2)AutoModelForSequenceClassification:这个类是transformers库提供的,用于自动选择适合序列分类任务的预训练模型。它在加载预训练模型权重后,会添加一个适合分类任务的头部(Model Head)
3)当使用AutoModelForSequenceClassification进行推理时,模型不仅执行了特征提取和编码,还通过Model Head进行了分类预测,输出通常是每个类别的得分或概率,你可以直接根据这些得分或概率进行标签的预测。
指定参数加载模型
clz_model = AutoModelForSequenceClassification.from_pretrained("/root/代码/Model组件/rbt3", num_labels=2)
输出:10
这段代码与上面代码类似,但它在加载模型时额外指定了num_labels=2参数。这个参数对于序列分类模型是重要的,因为它告诉模型输出层期望的输出尺寸,即分类标签的数量。如果模型被微调用于一个具有两个标签的分类任务(如正面情感和负面情感),这个参数是必须的。如果没有正确设置num_labels,模型的输出可能无法正确映射到标签空间。
总结
通过上述步骤,展示了如何使用Hugging Face的transformers库中的Model组件来执行各种NLP任务。Model组件的选择和使用对于实现高效和准确的NLP模型至关重要。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!