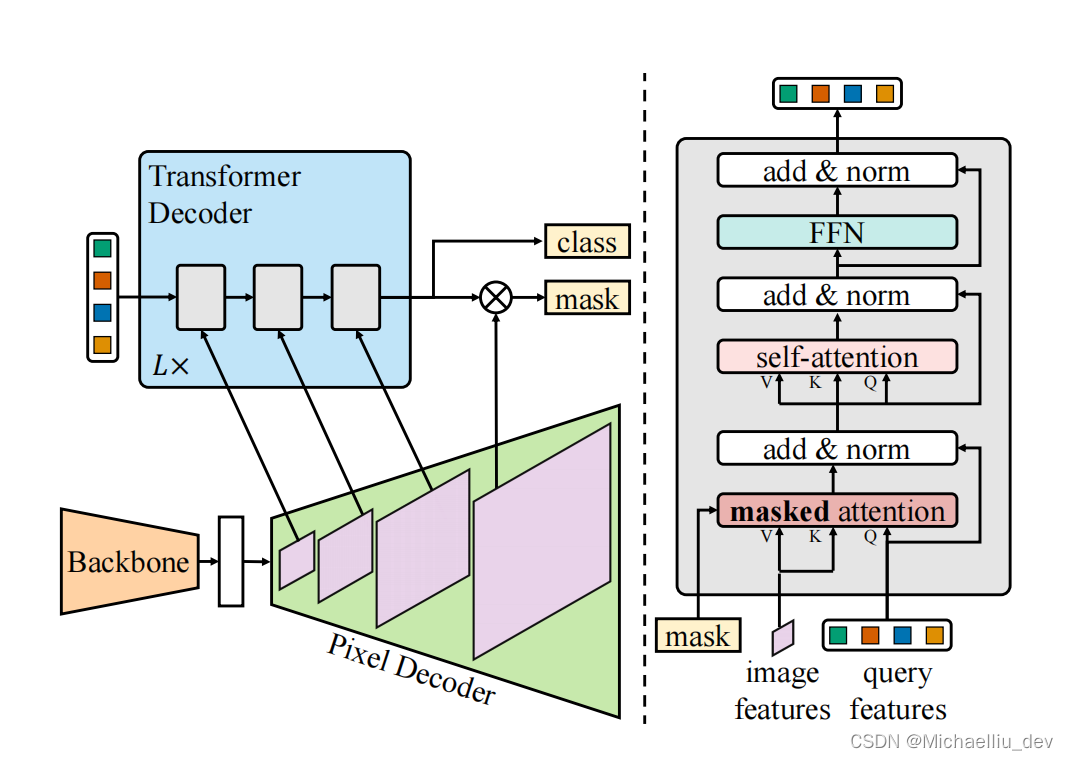
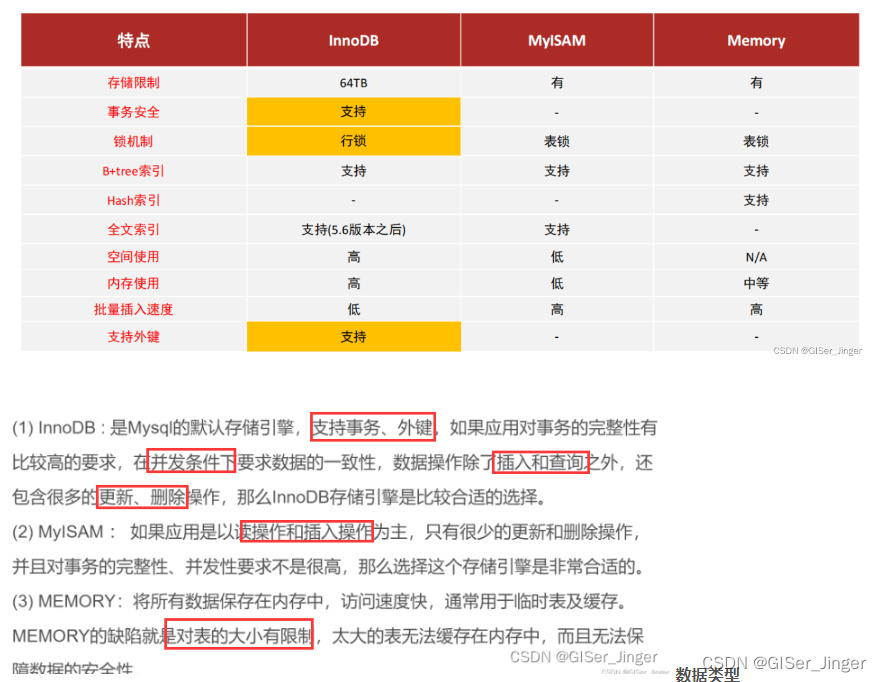
直接阅读原始论文可能有点难和复杂,所以导师直接推荐我阅读周志华的《西瓜书》!!然后仔细阅读其中的第六章:支持向量机
间隔与支持向量
- ==**问题一:什么叫法向量?为什么是叫法向量**==
- 什么是法向量?
- 超平面的数学表示
- 超平面和SVM
- 向量和高维空间
- 法向量 w \mathbf{w} w 和数据维度
- 为什么法向量 w \mathbf{w} w 要转置呢?
- 矩阵乘法的维度匹配原则
- 转置以进行点积
- 几何和数学意义
- 结论
- ==**问题二:x到平面的距离怎么计算?原理是啥?**==
- 计算点到平面的距离
- 距离计算公式的原理:
- 平面方程的向量表示
- 如何转化为垂直距离
- 将点到平面的距离公式应用于SVM
- SVM 中的距离应用
- ==**问题三:为什么这里设置y的值是+1/-1,如何理解这个式子呢?**==
- ==**问题四:两个异类支持向量到超平面的距离怎么计算的?**==
- ==**问题五:为什么等价于最小化 ∥ ω ∥ 2 \left \| \omega \right \|^2 ∥ω∥2?**==
- ==**问题六:为什么最后得到的是 1 2 ∣ ∣ ω ∣ ∣ 2 ?? \frac{1}{2} ||\omega||^2?? 21∣∣ω∣∣2??==
- 附录一:凸函数讲解
- 什么是凸函数
- 直观解释
- 图形实例
- 关键点说明:
- 凸函数的性质:
- 为什么这一性质重要:
- 凸函数的另一种定义
- 一阶导数和二阶导数的关系
- 二阶导数非负与函数性质
- 为什么平方函数是凸函数
问题一:什么叫法向量?为什么是叫法向量
在这个线性方程中,很容易理解的是一个一次函数,也就是
a
x
+
b
=
0
ax+b=0 \\
ax+b=0
但是为什么这里是法向量,而且还有一个T,这个T又是f什么意思?
- b可以理解,是位移项,决定
超平面和原点的距离
会不会是因为 a x + b = 0 ax+b=0 ax+b=0是一次函数,但是在这个SVM中其实是一个超平面去划分的,所以是另一个参数来代表,那又要如何理解这里提到的超平面的方向呢?
在支持向量机(SVM)中,法向量是一个非常重要的概念。这里我们首先要澄清一下线性方程和超平面的关系,以及法向量的意义。
什么是法向量?
在数学和物理中,一个平面或超平面的法向量是一个垂直于 该平面 的向量。在SVM的上下文中,超平面是 决策边界 ,用来划分不同类别的数据点。
超平面的数学表示
在二维空间中,一个直线可以表示为 ( ax + by + c = 0 )。其中,向量 (a, b) 就是这条直线的法向量,指向垂直于直线的方向。
在更高维度,比如三维空间,一个平面可以用方程 ( ax + by + cz + d = 0 ) 来描述,这里 ( a, b, c ) 是这个平面的法向量。
超平面和SVM
在SVM中,我们通常处理的是 高维空间 中的数据,超平面的方程可以推广为:
w
T
x
+
b
=
0
\mathbf{w}^T \mathbf{x} + b = 0
wTx+b=0
这里:
- w \mathbf{w} w 是超平面的法向量,它定义了超平面的方向。
-
(
x
)
( \mathbf{x} )
(x) 是数据点的向量表示。它包含了一个数据点在
所有维度上的坐标。例如,在二维空间中,一个点可以表示为 ( x 1 , x 2 ) ( x_1, x_2 ) (x1,x2),在三维空间中,它可以是 ( x 1 , x 2 , x 3 ) (x_1, x_2, x_3) (x1,x2,x3),而在更高的维度,比如 ( n ) 维,它就是 ( x 1 , x 2 , … , x n ) (x_1, x_2, \ldots, x_n) (x1,x2,…,xn)。 - ( b ) 是位移项,决定了超平面相对于原点的位置。
- 上述方程中的 ( T ) 表示转置操作,确保 w \mathbf{w} w 和 x \mathbf{x} x 以内积的形式相乘,从而这个乘积结果是一个标量(数值)。
向量和高维空间
当我们说到一个向量 x \mathbf{x} x 时,它实际上就是一个由多个坐标组成的列表或数组,每个坐标对应数据空间中的一个维度。这意味着在SVM的数学表述中,不需要单独考虑每一个维度,因为它们已经全部包含在 x \mathbf{x} x 这个向量中了。这样的表述使得算法可以很容易地 扩展到任意维度 的数据处理。
法向量 w \mathbf{w} w 和数据维度
法向量 w \mathbf{w} w 也是一个向量,它在每个维度上都有一个分量,这些分量在数学上与 x \mathbf{x} x 中相应的维度分量相对应。如果 x \mathbf{x} x 是 ( n ) 维的,那么 w \mathbf{w} w 也是 ( n ) 维的。这样,当我们计算 w T x \mathbf{w}^T \mathbf{x} wTx 时,实际上是在计算两个 ( n ) 维向量的点积,结果是一个标量。
为什么法向量 w \mathbf{w} w 要转置呢?
主要是因为矩阵和向量的 维度必须匹配 以执行乘法运算。
矩阵乘法的维度匹配原则
在矩阵乘法中,当你想要乘两个矩阵(或向量)时,第一个矩阵的列数必须等于第二个矩阵的行数。具体来说:
- 如果 w \mathbf{w} w 是一个 n × 1 n \times 1 n×1 的列向量(意味着 w \mathbf{w} w 有 ( n ) 行和 1 列),而
- x \mathbf{x} x 也是一个 n × 1 n \times 1 n×1 的列向量,
那么你 不能直接将两个向量相乘 ,因为 w \mathbf{w} w 的列数(1)不匹配 x \mathbf{x} x 的行数(n )。
转置以进行点积
为了进行点积运算, w \mathbf{w} w 需转置为 1 × n 1 \times n 1×n 的行向量(即 w T \mathbf{w}^T wT),使得与 x \mathbf{x} x 的 n × 1 n \times 1 n×1 列向量的维度匹配,从而实现两个向量的内积,计算结果为一个标量。
几何和数学意义
从几何和数学的角度来看,这种乘法(点积)有特殊的意义:
- 几何意义:点积 w T x \mathbf{w}^T \mathbf{x} wTx 表示 x \mathbf{x} x 在 w \mathbf{w} w 方向上的投影长度乘以 w \mathbf{w} w 的长度。
- 数学意义:点积用于衡量两个向量之间的 相似度,其值越大表明两个向量越“接近”。
这种操作是线性代数中常见的做法,用于简化计算并提供一种统一的方法来处理数据,特别是在支持向量机(SVM)这类涉及高维数据的算法中。
这种计算方式非常适用于高维数据,因为它允许我们在非常广泛的维度上简单快速地评估数据点与决策边界的关系。
点积作为一种计算方法,在SVM中是决定数据点分类的 核心机制 。
结论
-
线性方程与超平面:
- 在低维(如二维或三维)空间中,线性方程 ( ax + by + c = 0 ) 或 ( ax + by + cz + d = 0 ) 表示一个线或平面。在高维空间中,这种线性方程推广为 w T x + b = 0 \mathbf{w}^T \mathbf{x} + b = 0 wTx+b=0,其中 w \mathbf{w} w 和 x \mathbf{x} x 都是向量。
- 这个方程定义了一个超平面,它在 ( n ) 维空间中将点分成不同的类别。
-
参数与向量:
- 方程中的 w \mathbf{w} w 是一个向量,代表了超平面的法向量,即垂直于超平面的方向。
- x \mathbf{x} x 是数据点的 位置向量 ,也是 ( n ) 维的。
-
矩阵乘法的维度匹配:
- 在线性方程中,为了计算 w T x \mathbf{w}^T \mathbf{x} wTx(即 w \mathbf{w} w 的转置与 x \mathbf{x} x 的点积),需要对 w \mathbf{w} w 进行转置。这是因为两个都是列向量,直接乘法是不符合矩阵乘法的维度规则的。
- 转置后, w T \mathbf{w}^T wT 成为一个行向量,可以与 x \mathbf{x} x 进行点积运算,结果是一个标量(数值)。
-
计算与结果的意义:
- 计算出的标量 w T x + b \mathbf{w}^T \mathbf{x} + b wTx+b 用来判断点 x \mathbf{x} x 相对于超平面的位置,即其分类。
- 结果的正负性决定了 x \mathbf{x} x 的类别(正类或负类)。
这个框架不仅是理解支持向量机的基础,也是很多其他机器学习算法中使用的基本线性代数应用。
问题二:x到平面的距离怎么计算?原理是啥?

计算点到平面的距离
假设有一个点
P
(
x
0
,
y
0
,
z
0
)
P(x_0, y_0, z_0)
P(x0,y0,z0) 和一个平面,平面的方程为:
A
x
+
B
y
+
C
z
+
D
=
0
Ax + By + Cz + D = 0
Ax+By+Cz+D=0
其中 ( A, B, C ) 是平面的法向量的分量,( D ) 是常数项。点 ( P ) 到这个平面的距离 ( d ) 可以通过以下公式计算:
d
=
∣
A
x
0
+
B
y
0
+
C
z
0
+
D
∣
A
2
+
B
2
+
C
2
d = \frac{|Ax_0 + By_0 + Cz_0 + D|}{\sqrt{A^2 + B^2 + C^2}}
d=A2+B2+C2∣Ax0+By0+Cz0+D∣
这个公式的分子 ∣ A x 0 + B y 0 + C z 0 + D ∣ |Ax_0 + By_0 + Cz_0 + D| ∣Ax0+By0+Cz0+D∣ 给出了点 ( P ) 到由平面方程 A x + B y + C z + D = 0 Ax + By + Cz + D = 0 Ax+By+Cz+D=0 定义的平面的有向距离,而分母是平面法向量 ( (A, B, C) ) 的长度,确保我们计算的是垂直距离。
距离计算公式的原理:
平面方程的向量表示
平面方程通常表示为 ( Ax + By + Cz + D = 0 ),这可以转换为向量形式的线性方程,即:
w
T
x
+
b
=
0
\mathbf{w}^T \mathbf{x} + b = 0
wTx+b=0
这里:
- w = ( A , B , C ) \mathbf{w} = (A, B, C) w=(A,B,C) 是平面的法向量,指向垂直于平面的方向。
- x = ( x , y , z ) \mathbf{x} = (x, y, z) x=(x,y,z) 是任意点的位置向量。
- ( b = D ) 是与平面的位置相对于原点的偏移量有关的标量。
当我们谈到 A x 0 + B y 0 + C z 0 + D Ax_0 + By_0 + Cz_0 + D Ax0+By0+Cz0+D 时,实际上我们是在做以下事情:
- 点积运算: w T x 0 \mathbf{w}^T \mathbf{x}_0 wTx0,其中 x 0 = ( x 0 , y 0 , z 0 ) \mathbf{x}_0 = (x_0, y_0, z_0) x0=(x0,y0,z0) 是点 ( P ) 的坐标。这个点积计算了 x 0 \mathbf{x}_0 x0 在法向量 w \mathbf{w} w 方向上的投影长度。几何意义是 x 0 \mathbf{x}_0 x0 在 w \mathbf{w} w 方向上的投影长度乘以 w \mathbf{w} w 的长度。这意味着这个值不仅反映了 ( P ) 在 w \mathbf{w} w 方向上的位置,而且其大小还与 w \mathbf{w} w 的长度成比例。
- 考虑平面偏移:加上 ( D ) 是为了将平面沿法向量 w \mathbf{w} w 移动 ( D ) 单位长度,从而调整平面与原点的相对位置。
点积的组成
当你计算两个向量 w \mathbf{w} w 和 x 0 \mathbf{x}_0 x0 的点积 w ⋅ x 0 \mathbf{w} \cdot \mathbf{x}_0 w⋅x0 时,根据点积的定义和性质,这个点积实际上等于:
w ⋅ x 0 = ∥ w ∥ ∥ x 0 ∥ cos ( θ ) \mathbf{w} \cdot \mathbf{x}_0 = \|\mathbf{w}\| \|\mathbf{x}_0\| \cos(\theta) w⋅x0=∥w∥∥x0∥cos(θ)
其中:
- ∥ w ∥ \|\mathbf{w}\| ∥w∥ 是法向量的模(长度)。
- ∥ x 0 ∥ \|\mathbf{x}_0\| ∥x0∥ 是点 ( P ) 的位置向量的模。
- θ \theta θ 是向量 ( \mathbf{w} ) 与 ( \mathbf{x}_0 ) 之间的夹角。
投影的计算
点积 ∥ w ∥ ∥ x 0 ∥ cos ( θ ) \|\mathbf{w}\| \|\mathbf{x}_0\| \cos(\theta) ∥w∥∥x0∥cos(θ) 中的 ∥ x 0 ∥ cos ( θ ) \|\mathbf{x}_0\| \cos(\theta) ∥x0∥cos(θ) 部分代表 x 0 \mathbf{x}_0 x0 在 w \mathbf{w} w 方向上的投影长度。这是因为 cos ( θ ) \cos(\theta) cos(θ) 是夹角的余弦值,它给出了 x 0 \mathbf{x}_0 x0 向 w \mathbf{w} w 方向投影的比例因子。
如何转化为垂直距离
为了从这个有向距离获得真实的垂直距离,我们需要:
- 取绝对值:将有向距离的绝对值取出,不考虑 ( P ) 在平面的哪一侧,以得到无方向的距离量度。
- 归一化:通过除以 ∥ w ∥ \|\mathbf{w}\| ∥w∥ 来归一化这个距离,因为原始的投影长度 A x 0 + B y 0 + C z 0 Ax_0 + By_0 + Cz_0 Ax0+By0+Cz0 是点积放大了的,具体放大了法向量长度的倍数。归一化后的结果才是真正的垂直距离。
将点到平面的距离公式应用于SVM
在支持向量机中,你通常有一个超平面来进行分类,其方程可以表示为:
w
T
x
+
b
=
0
\mathbf{w}^T \mathbf{x} + b = 0
wTx+b=0
这里
w
\mathbf{w}
w 是法向量,( b ) 是位移项,
x
\mathbf{x}
x 是数据点。在这种情况下,超平面的方程与前面提到的平面方程类似,其中
w
\mathbf{w}
w 相当于法向量的分量 (A, B, C );( b ) 相当于 D。
因此,数据点
x
0
\mathbf{x}_0
x0 到超平面的距离可以用类似的公式计算:
d
=
∣
w
T
x
0
+
b
∣
∥
w
∥
d = \frac{|\mathbf{w}^T \mathbf{x}_0 + b|}{\|\mathbf{w}\|}
d=∥w∥∣wTx0+b∣
这里
∥
w
∥
\|\mathbf{w}\|
∥w∥ 是法向量
w
\mathbf{w}
w 的欧几里得范数,计算方式为:
∥
w
∥
=
w
1
2
+
w
2
2
+
⋯
+
w
n
2
\|\mathbf{w}\| = \sqrt{w_1^2 + w_2^2 + \dots + w_n^2}
∥w∥=w12+w22+⋯+wn2
SVM 中的距离应用
在SVM中,计算数据点到超平面的距离不仅有助于确定数据点的分类(基于其正负符号),还有助于优化超平面的位置。SVM的目标之一是最大化数据点(特别是支持向量)到超平面的最小距离,这种距离也称为“间隔”。最大化间隔可以帮助提高模型的泛化能力,从而在未见数据上表现更好。
问题三:为什么这里设置y的值是+1/-1,如何理解这个式子呢?

x是数据值,y是得到的结果,那意思说yi=+1就是被正确分类,=-1就是错误分类;那为什么整个式子就是>0的呢?
这张图片展示了支持向量机(SVM)中用于定义 最优决策边界 的基本概念。在SVM中,我们通过找到一个最大化两个类别间隔的超平面来进行数据分类。图中的公式表达了如何利用超平面来决定数据点的分类。现在让我们深入理解这个公式及其背后的逻辑。
SVM中的标签编码 ( y i ) ( y_i ) (yi)
在SVM中,数据点的类别用 y i y_i yi 来表示, y i y_i yi 只能取两个值:+1 或 -1。
- y i = + 1 y_i = +1 yi=+1 表示数据点 x i x_i xi 属于正类。
- y i = − 1 y_i = -1 yi=−1 表示数据点 x i x_i xi 属于负类。
这种方式称为标签的二元编码,它简化了数学处理过程,并允许我们使用符号函数来描述数据点是否被正确分类。
分类准则
在 SVM 中,分类准则基于数据点相对于超平面的位置。具体地:
- 如果对于一个数据点 x i \mathbf{x}_i xi,计算结果 w T x i + b \mathbf{w}^T \mathbf{x}_i + b wTxi+b 大于 0,那么按照 SVM 的规则,该点被预测为正类,即 y i = + 1 y_i = +1 yi=+1。
- 反之,如果计算结果小于 0,则该点被预测为负类,即 y i = − 1 y_i = -1 yi=−1。
这是分类决策的基础,决定了数据点应当属于 哪个类别 。
间隔边界设定
对于间隔边界的定义,我们不仅关心数据点是否被正确分类,还 关心它们与决策边界的距离 。在 SVM 中,最优化问题不仅要找到一个分隔两类的超平面,还要最大化该超平面到最近数据点的距离,这就是所谓的间隔。
为了具体化这个最大化问题,SVM 采用以下策略:
- 对于正类的支持向量
x
i
\mathbf{x}_i
xi(即
最靠近超平面的正类点),我们希望它们满足 w T x i + b ≥ + 1 \mathbf{w}^T \mathbf{x}_i + b \geq +1 wTxi+b≥+1 。 - 对于负类的支持向量
x
i
\mathbf{x}_i
xi(即
最靠近超平面的负类点),我们希望它们满足 w T x i + b ≤ − 1 \mathbf{w}^T \mathbf{x}_i + b \leq -1 wTxi+b≤−1 。
为什么要用 ≥ + 1 \geq +1 ≥+1 和 ≤ − 1 \leq -1 ≤−1,而不是 ≥ 0 \geq 0 ≥0?
-
距离度量:
使用+1和-1而不是0作为边界,可以使得支持向量(即 最靠近超平面的点 )到超平面的距离成为一个固定的度量。在这个约束下,所有支持向量到决策边界的距离都是相等的,这为间隔提供了一个具体的度量标准。 -
几何间隔:
几何间隔是数据点到超平面的距离,可以表示为点到平面的距离公式 d = ∣ w T x 0 + b ∣ ∥ w ∥ d = \frac{|\mathbf{w}^T \mathbf{x}_0 + b|}{\|\mathbf{w}\|} d=∥w∥∣wTx0+b∣。对于支持向量来说,当 w T x 0 + b \mathbf{w}^T \mathbf{x}_0 + b wTx0+b 的绝对值等于1时,这个公式简化为 d = 1 ∥ w ∥ d = \frac{1}{\|\mathbf{w}\|} d=∥w∥1。 -
优化简化:
使用+1和-1为间隔的约束,允许SVM优化问题的目标函数变为最小化 ∥ w ∥ 2 \|\mathbf{w}\|^2 ∥w∥2,这简化了拉格朗日乘子法的应用,并使得对偶问题成为凸二次规划问题,这类问题存在高效的求解算法。
1的意义
在间隔的上下文中,这个1实际上是任意选择的一个正数,它代表了规范化的间隔大小 。我们选择1是因为这个数值在数学上方便处理,但实际上,选择任何其他正数并适当缩放
w
\mathbf{w}
w 和 ( b ) 都会得到相同的最优超平面。这是因为超平面的定义是由
w
\mathbf{w}
w 的方向以及点到超平面的距离决定的,而不是由具体的数值决定。
总结
SVM 的目标是构建一个具有最大间隔的决策边界,而间隔边界的设定 ≥ + 1 \geq +1 ≥+1 和 ≤ − 1 \leq -1 ≤−1 为了确保数学模型的一致性,并简化优化过程。这种方式定义的间隔是所有支持向量到超平面的最小距离,最大化这个距离帮助SVM提高分类器的泛化能力。
距离超平面最近的几个训练标本使上面不等式中的等号成立,这几个训练样本被称为“支持向量”(support vector)
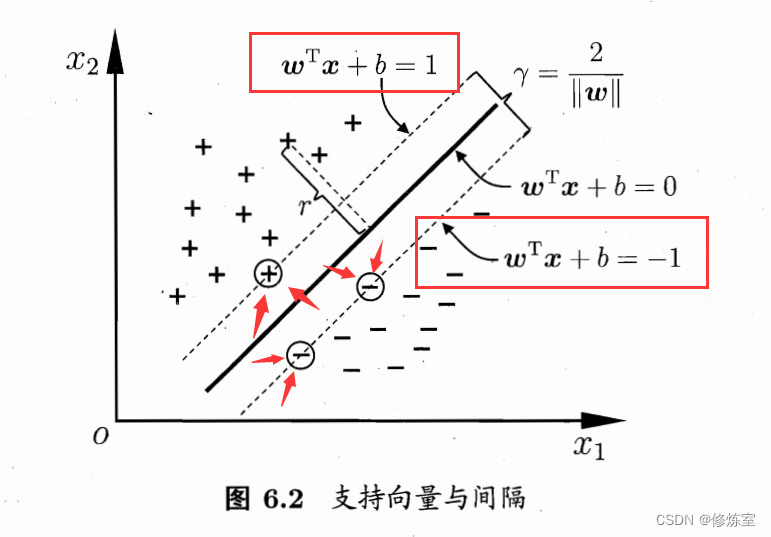
问题四:两个异类支持向量到超平面的距离怎么计算的?
在支持向量机(SVM)中,两个异类支持向量到超平面的距离是由超平面的定义决定的。这个距离实际上就是我们常说的“间隔”(margin),而这个间隔对于所有的支持向量来说是相同的。
对于一个给定的超平面,其方程可以表示为 w T x + b = 0 \mathbf{w}^T \mathbf{x} + b = 0 wTx+b=0,其中:
- w \mathbf{w} w 是超平面的法向量。
- ( b ) 是偏移项。
- x \mathbf{x} x 是任意点在特征空间中的位置向量。
一个点 x i \mathbf{x}_i xi 到这个超平面的距离可以通过以下公式计算:
distance = ∣ w T x i + b ∣ ∥ w ∥ \text{distance} = \frac{|\mathbf{w}^T \mathbf{x}_i + b|}{\|\mathbf{w}\|} distance=∥w∥∣wTxi+b∣
在SVM中,支持向量是最靠近这个超平面的点,对于正类的支持向量 x + \mathbf{x}_+ x+ 和负类的支持向量 x − \mathbf{x}_- x−,他们分别满足:
w
T
x
+
+
b
=
1
\mathbf{w}^T \mathbf{x}_+ + b = 1
wTx++b=1
w
T
x
−
+
b
=
−
1
\mathbf{w}^T \mathbf{x}_- + b = -1
wTx−+b=−1
注意,这里的 1 和 -1 是函数间隔的值,对应于我们之前提到的固定间隔标准。因此,任何一个支持向量
x
i
\mathbf{x}_i
xi 到超平面的距离可以简化为:
distance = 1 ∥ w ∥ \text{distance} = \frac{1}{\|\mathbf{w}\|} distance=∥w∥1
这是因为 ( |1| ) 和 ( |-1| ) 的绝对值都是 1。
对于两个异类支持向量,我们可以把它们各自到超平面的距离加起来得到间隔,即:
margin = distance + + distance − = 1 ∥ w ∥ + 1 ∥ w ∥ = 2 ∥ w ∥ \text{margin} = \text{distance}_{+} + \text{distance}_{-} = \frac{1}{\|\mathbf{w}\|} + \frac{1}{\|\mathbf{w}\|} = \frac{2}{\|\mathbf{w}\|} margin=distance++distance−=∥w∥1+∥w∥1=∥w∥2
所以最终能得到间隔表达为:
γ = 2 ∥ ω ∥ \gamma = \frac{2}{\left \| \omega \right \| } γ=∥ω∥2
问题五:为什么等价于最小化 ∥ ω ∥ 2 \left \| \omega \right \|^2 ∥ω∥2?
如果我们要最大化这个间隔 γ = 2 ∥ ω ∥ \gamma = \frac{2}{\left \| \omega \right \| } γ=∥ω∥2,那也就是让 ω \omega ω最小,同样的,我们转换一下格式,就是仅需要 ∥ ω ∥ − 1 \\{\left \| \omega \right \| }^{-1} ∥ω∥−1最大化即可;
但是为什么等价于最小化 ∥ ω ∥ 2 {\left \| \omega \right \| }^2 ∥ω∥2???
在支持向量机(SVM)中,最大化间隔 γ = 2 ∥ ω ∥ \gamma = \frac{2}{\|\omega\|} γ=∥ω∥2 的目标确实可以转化为最小化 ∥ ω ∥ \|\omega\| ∥ω∥。但是,在实际的优化过程中,我们通常选择最小化 ∥ ω ∥ 2 \|\omega\|^2 ∥ω∥2 而不是直接最小化 ∥ ω ∥ \|\omega\| ∥ω∥。这样做有几个数学上的好处和实际的便利性:
为什么最小化 ∥ ω ∥ 2 \|\omega\|^2 ∥ω∥2 而不是 ∥ ω ∥ \|\omega\| ∥ω∥
-
微分便利性:
- 最小化
∥
ω
∥
2
\|\omega\|^2
∥ω∥2 相比于
∥
ω
∥
\|\omega\|
∥ω∥ 在数学处理上
更为简便。函数 ∥ ω ∥ 2 \|\omega\|^2 ∥ω∥2 是平方和形式,其导数(梯度)容易计算,而 ∥ ω ∥ \|\omega\| ∥ω∥ 的导数在 ω = 0 \omega = 0 ω=0 时 不可导 ,这可能在数学优化中带来问题。
- 最小化
∥
ω
∥
2
\|\omega\|^2
∥ω∥2 相比于
∥
ω
∥
\|\omega\|
∥ω∥ 在数学处理上
-
凸优化问题:
-
∥
ω
∥
2
\|\omega\|^2
∥ω∥2 是一个 凸函数 ,确保了优化问题
有全局最小解。这是因为平方和形式保证了函数的二次导数始终为正,从而形成一个凸函数。在支持向量机的优化中,这种性质特别重要,因为它保证找到的解是全局最优的。
-
∥
ω
∥
2
\|\omega\|^2
∥ω∥2 是一个 凸函数 ,确保了优化问题
关于凸函数,见文章末尾《附录一:凸函数讲解》
-
简化对偶问题的求解:
- 在将 SVM 的优化问题转换为对偶形式时,原始问题(即普拉特问题)中 ∥ ω ∥ 2 \|\omega\|^2 ∥ω∥2 形式的目标函数转换成对偶问题中更为简洁和易于处理的形式。对偶问题中涉及的是样本的内积,这可以通过核函数有效地计算,适用于处理线性不可分的情况。
-
避免除法运算:
- 在计算机编程和数值计算中,避免除法(求逆运算)可以提高计算的稳定性和效率。通过最小化 ∥ ω ∥ 2 \|\omega\|^2 ∥ω∥2 而非最大化 1 ∥ ω ∥ \frac{1}{\|\omega\|} ∥ω∥1,我们可以避免在 ∥ ω ∥ \|\omega\| ∥ω∥ 接近零时 可能出现的 数值不稳定 问题。
数学表达
具体来说,目标函数转换过程可以这样理解:
- 最大化间隔( γ = 2 ∥ ω ∥ \gamma = \frac{2}{\|\omega\|} γ=∥ω∥2) 相当于最大化 1 ∥ ω ∥ \frac{1}{\|\omega\|} ∥ω∥1。
- 因为最大化 1 ∥ ω ∥ \frac{1}{\|\omega\|} ∥ω∥1 等价于最小化 ∥ ω ∥ \|\omega\| ∥ω∥。
- 最小化
∥
ω
∥
\|\omega\|
∥ω∥ 直接等价于最小化
∥
ω
∥
2
\|\omega\|^2
∥ω∥2,因为
∥
ω
∥
\|\omega\|
∥ω∥ 和
∥
ω
∥
2
\|\omega\|^2
∥ω∥2 都是随
∥
ω
∥
\|\omega\|
∥ω∥
单调增加的。
通过这样的转换,SVM的优化问题既可以保证数学的严谨性,也便于在实际的机器学习应用中进行高效的数值求解。
**问题六:为什么最后得到的是 1 2 ∣ ∣ ω ∣ ∣ 2 ?? \frac{1}{2} ||\omega||^2?? 21∣∣ω∣∣2??

之前不是为了方便微分和凸优化吗?那现在这个
1
2
\frac{1}{2}
21是什么意思?哪来的???
这个问题涉及到SVM的目标函数形式。
在SVM中,我们的目标是最大化间隔,等价于最小化
1
∣
∣
ω
∣
∣
\frac{1}{||\omega||}
∣∣ω∣∣1。但是直接最小化
1
∣
∣
ω
∣
∣
\frac{1}{||\omega||}
∣∣ω∣∣1 不容易处理,因为它的导数会随着
ω
\omega
ω 接近零时变得无穷大,这在计算上是不稳定的。
相反,最小化 ∣ ∣ ω ∣ ∣ 2 ||\omega||^2 ∣∣ω∣∣2 就容易得多,因为 ∣ ∣ ω ∣ ∣ 2 ||\omega||^2 ∣∣ω∣∣2 是一个光滑的凸函数,有良好的数学性质,使得求解更稳定、更容易。
此外,我们选择最小化
1
2
∣
∣
ω
∣
∣
2
\frac{1}{2} ||\omega||^2
21∣∣ω∣∣2 而不仅仅是
∣
∣
ω
∣
∣
2
||\omega||^2
∣∣ω∣∣2 是为了计算方便。
在求导时,
1
2
\frac{1}{2}
21 这个系数能够 正好抵消掉导数中的2 ,从而简化了后续的计算。这是在数学优化中常用的技巧,通过微小的调整目标函数来简化导数的计算过程。
附录一:凸函数讲解
什么是凸函数
在数学中,一个函数 ( f(x) ) 被称为凸函数(或凸向下的函数),如果在其定义域中的任意两点
x
1
x_1
x1 和
x
2
x_2
x2 上,满足以下条件:
f
(
λ
x
1
+
(
1
−
λ
)
x
2
)
≤
λ
f
(
x
1
)
+
(
1
−
λ
)
f
(
x
2
)
for all
λ
∈
[
0
,
1
]
f(\lambda x_1 + (1 - \lambda) x_2) \leq \lambda f(x_1) + (1 - \lambda) f(x_2) \quad \text{for all} \quad \lambda \in [0, 1]
f(λx1+(1−λ)x2)≤λf(x1)+(1−λ)f(x2)for allλ∈[0,1]
直观地讲,这个定义意味着函数的图形在 任何两点之间的线段始终位于或等于这两点在函数图形上的连线之下 。这个性质对于确保函数在全局最小值处是单调的(即不会有局部最小值,只有一个全局最小值)非常关键。
直观解释
凸函数定义,实际上是在描述函数的一种
“线性内插”性质。
步骤1: 两点选择
假设你有一个函数 f ( x ) f(x) f(x),比如 f ( x ) = x 2 f(x) = x^2 f(x)=x2,它的图形是一条曲线。现在,我们在这条曲线上随机选择两个点:
- 第一个点: x 1 x_1 x1,在这点上函数的值是 f ( x 1 ) f(x_1) f(x1)。
- 第二个点: x 2 x_2 x2,在这点上函数的值是 f ( x 2 ) f(x_2) f(x2)。
步骤2: 连线
想象一下,如果你用笔在这两点之间直接画一条直线。这条直线会穿过这两个点,看起来就像是用尺子在纸上画的直线一样。
步骤3: 内插点的选择
现在,我们要在这条直线上选择一个新的点。这个点不是随机选择的,而是用一个 特定的比例 来确定:
- 假设 λ \lambda λ 是一个介于 0 到 1 之间的数(比如 0.25, 0.5, 0.75等),这个数决定了你新点的位置更靠近 x 1 x_1 x1 还是 x 2 x_2 x2
- 计算新点的 ( x ) 坐标:
λ
x
1
+
(
1
−
λ
)
x
2
\lambda x_1 + (1 - \lambda) x_2
λx1+(1−λ)x2。这个公式的意思是,新点的 ( x ) 坐标是
x
1
x_1
x1 和
x
2
x_2
x2 坐标的
加权平均。如果 λ \lambda λ 是 0.5,新点就正好在 x 1 x_1 x1 和 x 2 x_2 x2 的中间;如果 λ \lambda λ 更大,新点更靠近 x 2 x_2 x2;如果 λ \lambda λ 更小,新点更靠近 x 1 x_1 x1。
想象你在一条直线上有两个点,一个在左边 x 1 x_1 x1 ,一个在右边 x 2 x_2 x2。通过调整 λ \lambda λ,你可以沿着这条直线在这两点之间
“滑动”,找到任意位置的点。
步骤4: 比较函数值与直线的高度
- 现在我们已经有了新点的 ( x ) 坐标,接着要计算这个点在函数 f ( x ) f(x) f(x) 上的真实 ( y ) 值,即 f ( λ x 1 + ( 1 − λ ) x 2 ) f(\lambda x_1 + (1 - \lambda) x_2) f(λx1+(1−λ)x2)。
- 同时,计算这个点在 直线上的 ( y ) 值 ,即 λ f ( x 1 ) + ( 1 − λ ) f ( x 2 ) \lambda f(x_1) + (1 - \lambda) f(x_2) λf(x1)+(1−λ)f(x2)
步骤5: 判断凸性
- 凸函数的定义说的是,对于函数上任意两点,直线上的任何点的 ( y ) 值都应该大于或等于函数曲线上相应 ( x ) 坐标的 ( y ) 值。
也就是说,如果直线上的点总是在函数曲线上的点的上方或与之相等,那么这个函数就是凸函数。
图形实例
让我们绘制一个简单的凸函数例子 ( f(x) = x^2 ),并在图中展示两点之间的连线与函数值的关系,以帮助理解这一定义。
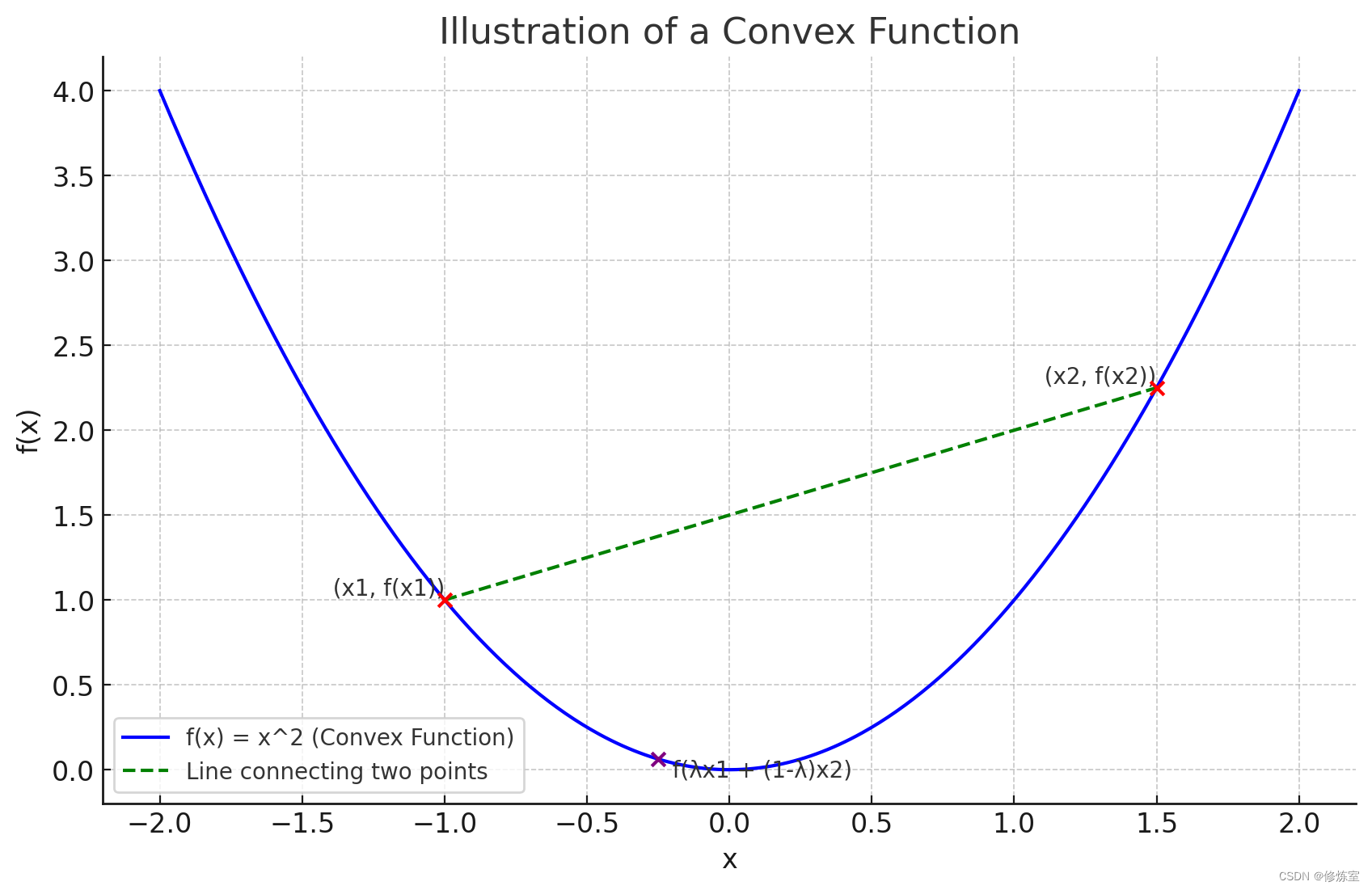
在这张图中,我们展示了凸函数
f
(
x
)
=
x
2
f(x) = x^2
f(x)=x2 的性质。图中蓝色曲线表示函数
f
(
x
)
=
x
2
f(x) = x^2
f(x)=x2,它是一个标准的凸函数。
关键点说明:
-
红色点:选择的两个点 ( − 1 , f ( − 1 ) ) (-1, f(-1)) (−1,f(−1)) 和 ( 1.5 , f ( 1.5 ) ) (1.5, f(1.5)) (1.5,f(1.5)) 在函数曲线上标记为红色。这两个点用来演示凸函数的定义。
-
绿色虚线:这条线连接了两个红色点,代表这 两点间直线 。
-
紫色点:这个点表示当 λ = 0.7 \lambda = 0.7 λ=0.7 时,两个红点的凸组合 λ x 1 + ( 1 − λ ) x 2 \lambda x_1 + (1 - \lambda) x_2 λx1+(1−λ)x2 在函数上的值 f ( λ x 1 + ( 1 − λ ) x 2 ) f(\lambda x_1 + (1 - \lambda) x_2) f(λx1+(1−λ)x2)。
紫色点明显位于绿色连接线的 下方 ,符合凸函数的定义。
凸函数的性质:
凸函数的定义是,对于其定义域中的任意两点 x 1 x_1 x1 和 x 2 x_2 x2,以及任意 λ \lambda λ 在 0 和 1 之间,函数值 f ( λ x 1 + ( 1 − λ ) x 2 ) f(\lambda x_1 + (1 - \lambda) x_2) f(λx1+(1−λ)x2) 总是小于或等于这两点的直线上相应点的值 λ f ( x 1 ) + ( 1 − λ ) f ( x 2 ) \lambda f(x_1) + (1 - \lambda) f(x_2) λf(x1)+(1−λ)f(x2)。这意味着函数图形始终位于连接任何两点的线段之下,正如图中紫色点所展示的那样。
为什么这一性质重要:
这一性质表明凸函数 不会有局部最小值,只有全局最小值 。因此,在优化问题中,如果目标函数是凸的,那么任何局部最优解也是全局最优解。这使得在凸优化问题中找到最优解变得可行和高效。
对于 SVM 中的 ∥ ω ∥ 2 \|\omega\|^2 ∥ω∥2,它是 ω \omega ω 各分量平方和 的形式,因此它也是一个凸函数。这保证了我们可以通过优化技术有效地找到最小化该函数的 ω \omega ω 值,进而最大化分类间隔。
凸函数的另一种定义
另一种定义凸函数的方式是通过其二阶导数:如果一个函数的二阶导数非负
(
f
′
′
(
x
)
≥
0
)
( f''(x) \geq 0 )
(f′′(x)≥0)在其定义域中的每一点上,那么这个函数是凸函数。这个性质表明函数的 斜率(导数)随 ( x ) 的增加而增加 。
一阶导数和二阶导数的关系
-
一阶导数 f ′ ( x ) f'(x) f′(x):描述的是函数 ( f(x) ) 的斜率,也就是函数在 ( x ) 点的瞬时变化率。当我们说一阶导数时,我们通常关注的是函数在某一点上是增加还是减少。
-
二阶导数 f ′ ′ ( x ) f''(x) f′′(x):描述的是一阶导数的变化率,也就是斜率的斜率,或更正式地说,是函数的曲率。二阶导数反映了函数图形的
“弯曲”程度以及这种弯曲是朝向上还是朝向下。
曲率的方向
- 二阶导数大于零 f ′ ′ ( x ) > 0 f''(x) > 0 f′′(x)>0:当二阶导数为正时,一阶导数 f ′ ( x ) f'(x) f′(x) 随 ( x ) 增加而增加,这表明函数图形是向上凸的(类似于U型)。在物理上,我们可以把这种形状想象为一个向上的弓形,函数在这段区域呈现凹形状态。
- 二阶导数小于零 f ′ ′ ( x ) < 0 f''(x) < 0 f′′(x)<0:当二阶导数为负时,一阶导数 f ′ ( x ) f'(x) f′(x) 随 ( x ) 增加而减少,这表明函数图形是向下凸的(类似于倒U型)。函数在这段区域呈现凸形状态。
例子:考虑函数 f ( x ) = x 3 f(x) = x^3 f(x)=x3。计算它的一阶和二阶导数:
在这些图中,我们可以看到函数 ( f(x) = x^3 ) 及其一阶和二阶导数的行为:
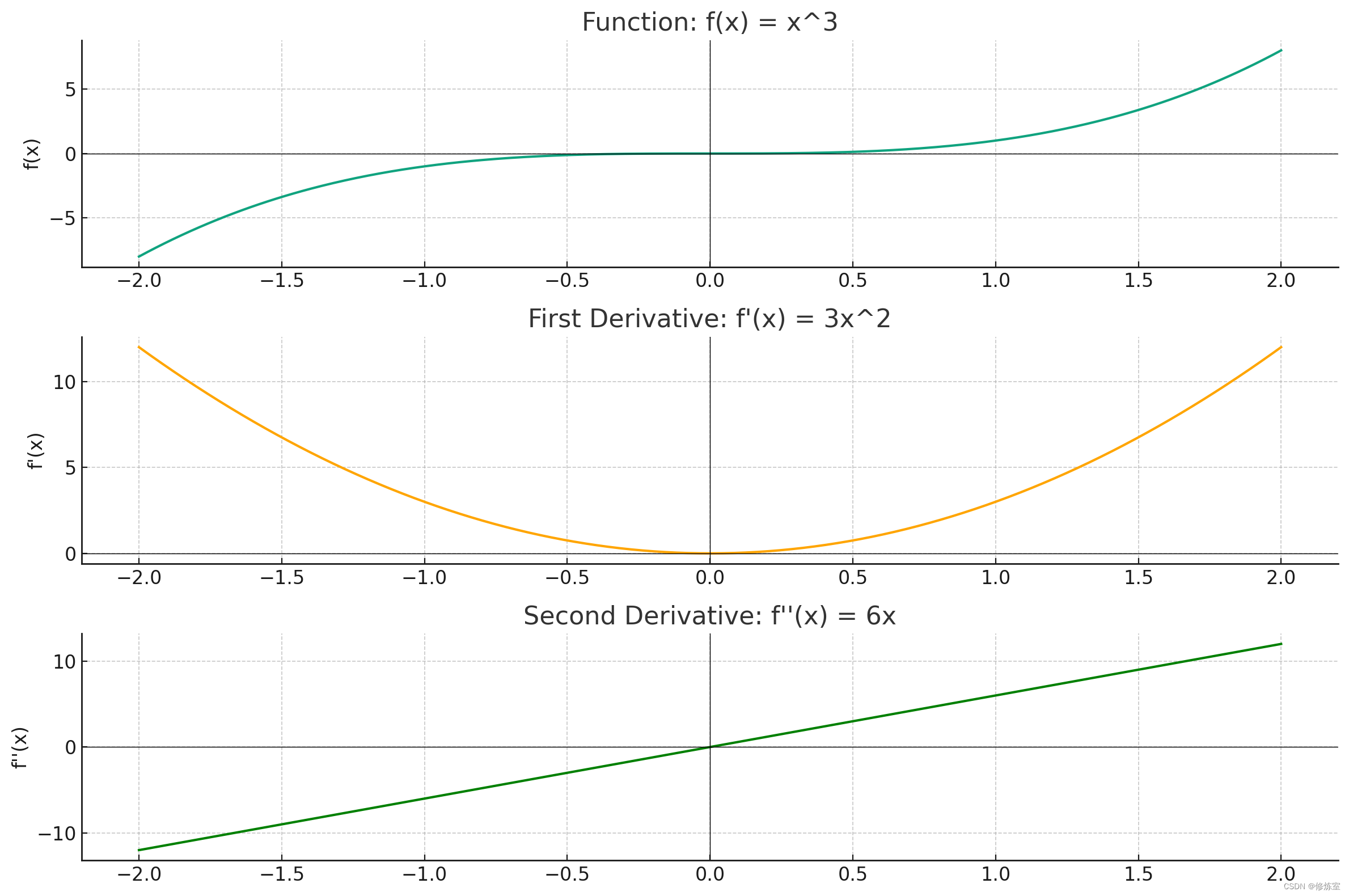
-
函数 f ( x ) = x 3 f(x) = x^3 f(x)=x3:
- 这个函数图形显示了一个立方曲线,其在 ( x = 0 ) 处通过原点,并且在该点附近表现出拐点的特征(从凹变凸)。
-
一阶导数 f ′ ( x ) = 3 x 2 f'(x) = 3x^2 f′(x)=3x2:
- 一阶导数图形显示,当 ( x ) 从负值过渡到正值时,斜率从 0 开始逐渐增加 。该函数在所有 ( x ) 值上都是
非负的,符合 ( x^3 ) 在 ( x = 0 ) 有拐点的特征。
- 一阶导数图形显示,当 ( x ) 从负值过渡到正值时,斜率从 0 开始逐渐增加 。该函数在所有 ( x ) 值上都是
-
二阶导数 f ′ ′ ( x ) = 6 x f''(x) = 6x f′′(x)=6x:
- 二阶导数的图形是一条直线,穿过原点。当 ( x < 0 ) 时,二阶导数为负(向下凸),当 ( x > 0 ) 时,二阶导数为正(向上凸)。这正好说明了 ( x = 0 ) 处的拐点,即曲线在这一点从向下凸变为向上凸。
二阶导数非负与函数性质
-
当 f ′ ′ ( x ) ≥ 0 f''(x) \geq 0 f′′(x)≥0 时,这表明 f ′ ( x ) f'(x) f′(x) 随 ( x ) 的增加而
不减少。换句话说,函数的斜率要么是 增加 的,要么是 恒定 的,但 不会减少 。这意味着函数不会突然从增加转为减少,因此函数 没有局部的下降点 ,只有局部上升点或平坦点。 -
在整个定义域中,如果 f ′ ′ ( x ) ≥ 0 f''(x) \geq 0 f′′(x)≥0 持续成立,函数 f ( x ) f(x) f(x) 不会有局部最小值点之外的其他最小值(即 没有局部最小值,只有可能的全局最小值 )。这是因为函数的图形始终“凸起”(类似于U型或更平坦的形状)。
为什么平方函数是凸函数
考虑一个简单的平方函数 f ( x ) = x 2 f(x) = x^2 f(x)=x2。我们可以通过计算其二阶导数来证明它是一个凸函数:
- 首先, f ( x ) = x 2 f(x) = x^2 f(x)=x2 的一阶导数(斜率)是 f ′ ( x ) = 2 x f'(x) = 2x f′(x)=2x。
- 其二阶导数(斜率的变化率)是 f ′ ′ ( x ) = 2 f''(x) = 2 f′′(x)=2。
由于 f ′ ′ ( x ) = 2 f''(x) = 2 f′′(x)=2 在 ( x ) 的整个实数范围内都是正数,因此 f ( x ) = x 2 f(x) = x^2 f(x)=x2 是一个凸函数。这意味着不管你选择 x 2 x^2 x2 上的哪两点,函数的实际值总是小于或等于这两点的连线上相应点的值。