🍨 本文为:[🔗365天深度学习训练营] 中的学习记录博客
🍖 原作者:[K同学啊 | 接辅导、项目定制]
要求:
- 了解LSTM是什么,并使用其构建一个完整的程序;
- R2达到0.83;
一、 基础配置
- 语言环境:Python3.7
- 编译器选择:Pycharm
- 深度学习环境:TensorFlow2.4.1
- 数据集:私有数据集
二、 前期准备
1.设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]],"GPU")
# 打印显卡信息,确认GPU可用
print(gpus)根据个人设备情况,选择使用GPU/CPU进行训练,若GPU可用则输出:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]由于在设备上安装的CUDA版本与TensorFlow版本不一致,故这里直接安装了CPU版的TensorFlow,无上述输出。
2. 导入数据
本项目所采用的数据集未收录于公开数据中,故需要自己在文件目录中导入相应数据集合,并设置对应文件目录,以供后续学习过程中使用。
运行下述代码,实现文件写入:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df_1 = pd.read_csv("./data/woodpine2.csv")3.数据可视化
通过运行下述代码
plt.rcParams['savefig.dpi'] = 500
plt.rcParams['figure.dpi'] = 500
fig,ax = plt.subplots(1,3,constrained_layout = True , figsize = (14,3))
sns.lineplot(data=df_1["Tem1"],ax=ax[0])
sns.lineplot(data=df_1["CO 1"],ax=ax[1])
sns.lineplot(data=df_1["Soot 1"],ax=ax[2])
plt.show()可以得到如下输出:
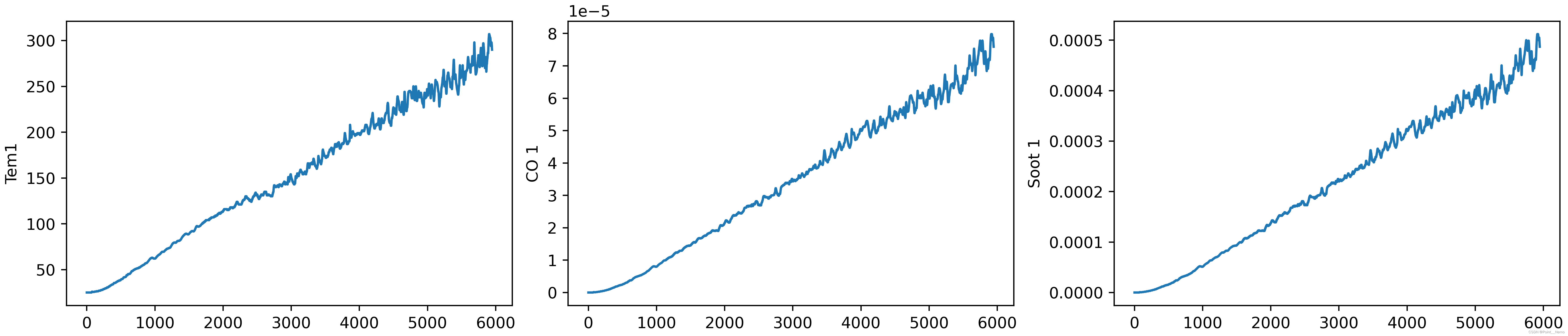
三、数据预处理
1.设置X,y
首先通过下面代码,将数据集一列的时间行去除(即保留第二列值最后一列的所有列),并按照序号的形式排列:
dataFrame = df_1.iloc[:,1:]
print(dataFrame)得到如下输出:
Tem1 CO 1 Soot 1
0 25.0 0.000000 0.000000
1 25.0 0.000000 0.000000
2 25.0 0.000000 0.000000
3 25.0 0.000000 0.000000
4 25.0 0.000000 0.000000
... ... ... ...
5943 295.0 0.000077 0.000496
5944 294.0 0.000077 0.000494
5945 292.0 0.000077 0.000491
5946 291.0 0.000076 0.000489
5947 290.0 0.000076 0.000487
[5948 rows x 3 columns]因为需要实现:使用1-8时刻段预测9时刻段,则通过下述代码做好长度的确定:
width_X = 8
width_y = 1接着,我们根据刚刚确定的长度,对数据进行划分:
X = []
y = []
in_start = 0
for _,_ in df_1.iterrows():
in_end = in_start + width_X
out_end = in_end + width_y
if out_end < len(dataFrame):
X_ = np.array(dataFrame.iloc[in_start:in_end,])
X_ = X_.reshape((len(X_)*3))
y_ = np.array(dataFrame.iloc[in_end:out_end,0])
X.append(X_)
y.append(y_)
in_start += 1
X = np.array(X)
y = np.array(y)
print(X.shape,y.shape)得到如下输出:
(5939, 24) (5939, 1)2.归一化
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler(feature_range=(0,1))
X_scaled = sc.fit_transform(X)
print(X_scaled.shape)得到如下输出:
(5939, 24)通过运行下述代码:
X_scaled = X_scaled.reshape(len(X_scaled),width_X,3)
print(X_scaled.shape)得到如下输出:
(5939, 8, 3)3.划分数据集
取5000之前的数据作为训练集,5000之后的数据作为验证集:
X_train = np.array(X_scaled[:5000]).astype('float64')
y_train = np.array(y[:5000]).astype('float64')
X_test = np.array(X_scaled[5000:]).astype('float64')
y_test = np.array(y[5000:]).astype('float64')
print(X_train.shape)得到如下输出:
(5000, 8, 3)四、构建模型
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,LSTM
model_lstm = Sequential()
model_lstm.add(LSTM(units=64,activation='relu',return_sequences=True,input_shape=(X_train.shape[1],3)))
model_lstm.add(LSTM(units=64,activation='relu'))
model_lstm.add(Dense(width_y))通过上述代码,构建了一个包含两个LSTM层和一个全连接层的LSTM模型。这个模型将接受形状为 (X_train.shape[1], 3) 的输入,其中 X_train.shape[1] 是时间步数,3 是每个时间步的特征数。
五、 编译模型
通过下列示例代码:
model_lstm.compile(loss='mean_squared_error',
optimizer=tf.keras.optimizers.Adam(1e-3))六、训练模型
通过下列示例代码:
history = model_lstm.fit(X_train,y_train,
epochs = 40,
batch_size = 64,
validation_data=(X_test,y_test),
validation_freq= 1)
运行得到如下输出:
Epoch 1/40
79/79 [==============================] - 2s 8ms/step - loss: 17138.3194 - val_loss: 387.7700
Epoch 2/40
79/79 [==============================] - 0s 5ms/step - loss: 156.8192 - val_loss: 84.9699
Epoch 3/40
79/79 [==============================] - 0s 5ms/step - loss: 81.8648 - val_loss: 68.5054
Epoch 4/40
79/79 [==============================] - 0s 5ms/step - loss: 68.0213 - val_loss: 59.3978
Epoch 5/40
79/79 [==============================] - 0s 5ms/step - loss: 55.6423 - val_loss: 47.6963
Epoch 6/40
79/79 [==============================] - 0s 5ms/step - loss: 38.9104 - val_loss: 22.8840
Epoch 7/40
79/79 [==============================] - 0s 5ms/step - loss: 20.2978 - val_loss: 17.1035
Epoch 8/40
79/79 [==============================] - 0s 5ms/step - loss: 13.7244 - val_loss: 12.1882
Epoch 9/40
79/79 [==============================] - 0s 5ms/step - loss: 10.3110 - val_loss: 8.4652
Epoch 10/40
79/79 [==============================] - 0s 5ms/step - loss: 7.0844 - val_loss: 7.8640
Epoch 11/40
79/79 [==============================] - 0s 5ms/step - loss: 7.1910 - val_loss: 5.8354
Epoch 12/40
79/79 [==============================] - 0s 5ms/step - loss: 6.7678 - val_loss: 7.7343
Epoch 13/40
79/79 [==============================] - 0s 5ms/step - loss: 6.6999 - val_loss: 5.7382
Epoch 14/40
79/79 [==============================] - 0s 5ms/step - loss: 7.1541 - val_loss: 5.1997
Epoch 15/40
79/79 [==============================] - 0s 5ms/step - loss: 6.5144 - val_loss: 6.5061
Epoch 16/40
79/79 [==============================] - 0s 5ms/step - loss: 7.3389 - val_loss: 5.5619
Epoch 17/40
79/79 [==============================] - 0s 5ms/step - loss: 5.2598 - val_loss: 6.1282
Epoch 18/40
79/79 [==============================] - 0s 5ms/step - loss: 5.5437 - val_loss: 5.1723
Epoch 19/40
79/79 [==============================] - 0s 5ms/step - loss: 5.5292 - val_loss: 5.1508
Epoch 20/40
79/79 [==============================] - 0s 5ms/step - loss: 6.0629 - val_loss: 6.0754
Epoch 21/40
79/79 [==============================] - 0s 5ms/step - loss: 6.0709 - val_loss: 6.4894
Epoch 22/40
79/79 [==============================] - 0s 5ms/step - loss: 6.0648 - val_loss: 21.8828
Epoch 23/40
79/79 [==============================] - 0s 5ms/step - loss: 8.5592 - val_loss: 5.8904
Epoch 24/40
79/79 [==============================] - 0s 5ms/step - loss: 6.3601 - val_loss: 5.2167
Epoch 25/40
79/79 [==============================] - 0s 5ms/step - loss: 5.5161 - val_loss: 9.1012
Epoch 26/40
79/79 [==============================] - 0s 5ms/step - loss: 7.0404 - val_loss: 5.1254
Epoch 27/40
79/79 [==============================] - 0s 5ms/step - loss: 5.1161 - val_loss: 5.8873
Epoch 28/40
79/79 [==============================] - 0s 5ms/step - loss: 5.6961 - val_loss: 5.6163
Epoch 29/40
79/79 [==============================] - 0s 5ms/step - loss: 5.9653 - val_loss: 4.9996
Epoch 30/40
79/79 [==============================] - 0s 5ms/step - loss: 7.2178 - val_loss: 6.9434
Epoch 31/40
79/79 [==============================] - 0s 5ms/step - loss: 6.4113 - val_loss: 24.5538
Epoch 32/40
79/79 [==============================] - 0s 5ms/step - loss: 12.1477 - val_loss: 5.6929
Epoch 33/40
79/79 [==============================] - 0s 5ms/step - loss: 6.0340 - val_loss: 8.0783
Epoch 34/40
79/79 [==============================] - 0s 5ms/step - loss: 8.2311 - val_loss: 6.0748
Epoch 35/40
79/79 [==============================] - 0s 5ms/step - loss: 6.2481 - val_loss: 14.7295
Epoch 36/40
79/79 [==============================] - 0s 5ms/step - loss: 11.7388 - val_loss: 5.4054
Epoch 37/40
79/79 [==============================] - 0s 5ms/step - loss: 5.7323 - val_loss: 6.3847
Epoch 38/40
79/79 [==============================] - 0s 5ms/step - loss: 7.3201 - val_loss: 5.1389
Epoch 39/40
79/79 [==============================] - 0s 5ms/step - loss: 5.7554 - val_loss: 5.1562
Epoch 40/40
79/79 [==============================] - 0s 5ms/step - loss: 5.4301 - val_loss: 5.4044模型训练结果为:loss大致回归
六、 模型评估
1.Loss与Accuracy图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(5, 3),dpi=120)
plt.plot(history.history['loss'],label = 'LSTM Training Loss')
plt.plot(history.history['val_loss'],label = 'LSTM Validation Loss')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.show()得到的可视化结果:
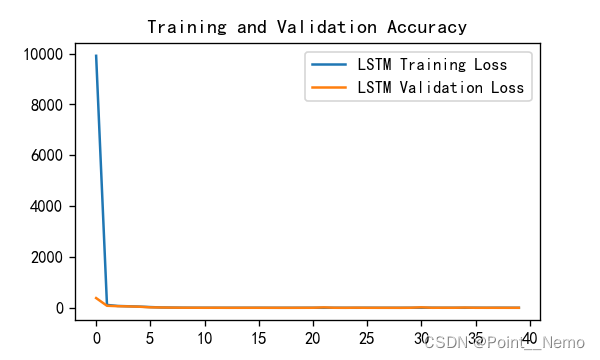
2.调用模型进行预测
通过:
predicted_y_lstm = model_lstm.predict(X_test)
y_tset_one = [i[0] for i in y_test]
predicted_y_lstm_one = [i[0] for i in predicted_y_lstm]
plt.figure(figsize=(5,3),dpi=120)
plt.plot(y_tset_one[:1000],color = 'red', label = '真实值')
plt.plot(predicted_y_lstm_one[:1000],color = 'blue', label = '预测值')
plt.title('Title')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()得到:

3. 查看误差
通过:
from sklearn import metrics
RMSE_lstm = metrics.mean_squared_error(predicted_y_lstm,y_test)**0.5
R2_lstm = metrics.r2_score(predicted_y_lstm,y_test)
print('均方根误差:%.5f' % RMSE_lstm)
print('R2:%.5f' % R2_lstm)得到:
均方根误差:2.32473
R2:0.99873可见,R2 = 0.99873,优于要求中的 0.83。
七、个人理解
本项目为通过LSTM来实现火灾的预测,需要根据给定的CSV文件来实现该目标。
- 本项目中,实现了对表格数据的可视化及异步预测,即通过前一段时刻得到的数据预测后续某一特定时刻的数据情况;
- LSTM可以理解为升级版的RNN,传统的RNN中存在着“梯度爆炸”和“短时记忆”的问题,向RNN中加入了遗忘门、输入门及输出门使得困扰RNN的问题得到了一定的解决;
- 关于LSTM的实现流程:(1、单输出时间步)单输入单输出、多输入单输出、多输入多输出(2、多输出时间步)单输入单输出、多输入单输出、多输入多输出;
- 针对本项目中的拔高要求,目前未能实现;