🚀Write In Front🚀
📝个人主页:令夏二十三
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏:深度学习
💬总结:希望你看完之后,能对你有所帮助,不足请指正!共同学习交流 🖊
文章目录
文章目录
1.1 训练集、验证集和测试集
1.2 偏差和方差
1.4 正则化
1.1 训练集、验证集和测试集
本周开始的第二门课我们将学习如何有效运行神经网络,内容涉及超参数调优,如何构建数据集,以及如何确保优化算法快速运行,从而使学习算法在合理时间内完成自学。
应用深度学习是一个典型的迭代过程,需要多次循环往复,才能为应用程序找到一个称心的神经网络,因此循环该过程的效率是决定项目进展的一个关键因素,而创建高质量的训练集、验证集和测试集也有助于提高循环效率。
在深度学习中,训练集、验证集和测试集是三个不同的数据集,它们在模型的开发、评估和测试阶段扮演着关键角色:
训练集(Training Set):
- 目的:训练集用于训练模型,即调整模型的参数(如权重和偏置)。
- 使用:在训练过程中,模型通过前向传播计算预测,然后通过反向传播更新参数,以最小化预测和实际标签之间的差异(损失函数)。
- 特点:训练集通常包含大部分可用数据,以便模型能够从中学习到足够的特征和模式。
验证集(Validation Set):
- 目的:验证集用于评估模型在训练过程中的性能,并调整模型的超参数。
- 使用:在训练过程中,模型在验证集上的性能会被定期检查,以监控模型的泛化能力,并防止过拟合。基于验证集的性能,可以调整学习率、改变网络结构或应用正则化等技术。
- 特点:验证集是独立于训练集的,它不用于训练模型的参数。验证集的大小通常小于训练集,但足够代表数据的多样性。
测试集(Test Set):
- 目的:测试集用于评估最终模型的性能,它提供了一个无偏的评估,反映了模型对未知数据的泛化能力。
- 使用:在模型的超参数调整完成后,使用测试集对模型进行最终评估。测试集的性能是模型泛化能力的最终指标。
- 特点:测试集应该是模型从未见过的数据,它不应该用于任何形式的模型训练或超参数调整。测试集的大小通常足够大,以确保评估结果的统计显著性。
总结来说,训练集用于学习模型参数,验证集用于调整超参数和监控过拟合,而测试集用于评估模型的最终性能。这三个数据集的区分和使用是确保模型有效性和可靠性的重要步骤。
在机器学习中,我们通常将数据样本划分成训练集、验证集和测试集三部分,传统的划分比例是6 :2 :2,对于规模较大的数据集,验证集和测试集要小于数据总量的20%或10%。
1.2 偏差和方差
如果训练出一个网络,首先可以观察一下网络在训练集上的正确率,如果在训练集上表现很差,说明神经网络陷入欠拟合(高偏差),这就需要考虑更换网络结构,比如使用更深层的网络或者增长训练时间等,来解决高偏差问题;
在实现了训练集上的高正确率以后,就可以检测网络在测试集上的性能,如果网络在测试集上表现不好,说明网络陷入过拟合(高方差问题),此时可以考虑使用更多的数据集或加入正则化来解决,不过有时候也可以考虑更换网络结构。
以下三张图分别为欠拟合、适度拟合和过拟合:
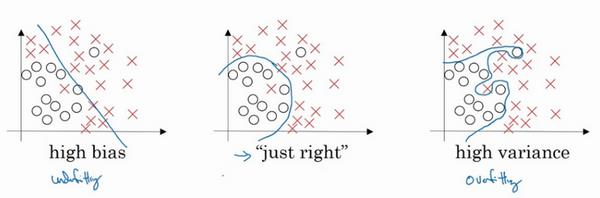
其实欠拟合就是高偏差,过拟合就是高方差,可以通过以下智谱生成的内容来进一步了解:
在机器学习中,偏差(Bias)和方差(Variance)是描述模型预测误差的两个关键概念。它们是统计学习理论中的基本概念,用于解释模型在不同数据集上的表现。
偏差:
- 定义:偏差是指模型在多次训练过程中,预测结果的期望与真实结果的差异。它反映了模型在学习数据时的拟合能力。
- 高偏差:如果模型在训练集上的表现不佳,说明模型可能存在高偏差,即模型可能过于简单,无法捕捉数据的复杂性和规律,这种情况被称为欠拟合(Underfitting)。
- 例子:假设我们用一个线性模型来拟合非线性的数据,由于线性模型的表达能力有限,它可能无法很好地捕捉数据的真实关系,导致高偏差。
方差:
- 定义:方差是指模型在不同训练数据集上的表现差异,它反映了模型对训练数据的敏感程度。
- 高方差:如果模型在训练集上的表现很好,但在验证集或测试集上的表现不佳,说明模型可能存在高方差,即模型可能过于复杂,对训练数据中的随机噪声也进行了学习,这种情况被称为过拟合(Overfitting)。
- 例子:一个拥有大量参数和深度的神经网络在训练集上可能能够达到非常高的准确率,但如果直接将其应用于未见过的数据,其表现可能会大幅下降,这是因为模型学习到了训练数据中的特定特征和噪声,而没有捕捉到更一般的规律。
为了更好地理解偏差和方差,可以考虑以下例子:
例子1:线性回归模型
- 偏差:如果数据本身是非线性的,线性回归模型可能无法很好地捕捉数据的真实关系,导致高偏差。
- 方差:如果线性回归模型包含大量的特征(可能包括一些无关的特征),并且没有适当的正则化,它可能会对训练数据中的噪声进行学习,导致高方差。
例子2:决策树模型
- 偏差:一个浅层的决策树可能无法很好地捕捉数据的复杂关系,导致高偏差。
- 方差:一个深层的决策树可能会对训练数据中的特定样本和噪声进行过度拟合,导致高方差。
在实际应用中,我们希望找到一个平衡点,即模型既不过于简单也不过于复杂,以实现良好的泛化能力。这通常涉及到模型选择、特征工程和正则化等技术。
1.4 正则化
神经网络陷入过拟合,可以通过加入正则化来解决,下面是关于正则化的介绍:
在深度学习中,正则化是一种用于防止模型过拟合的技术。过拟合发生在模型对训练数据学习得太好,以至于它捕捉到了数据中的噪声和特定特征,而无法泛化到新的、未见过的数据。正则化通过对模型施加一些约束或惩罚,鼓励模型学习更简单的、泛化能力更强的模式。
正则化的主要目的是减少模型的复杂性,使得模型不会过分依赖于训练数据中的特定特征。这样,模型就能更好地识别数据中的潜在模式,并在面对新数据时表现得更加稳健。
常见的正则化方法包括:
L1正则化(Lasso Regularization):
- 通过添加权重向量的绝对值之和的惩罚项来减少模型复杂性。
- 可以导致某些特征的权重变为零,从而实现特征选择。
L2正则化(Ridge Regularization):
- 通过添加权重向量的平方之和的惩罚项来减少模型复杂性。
- 会使权重分散到多个特征上,而不是集中在少数特征上。
L1/L2正则化(Elastic Net Regularization):
- 是L1和L2正则化的结合,通过混合惩罚项来减少模型复杂性。
- 允许同时进行特征选择和权重分散。
Dropout:
- 在训练过程中随机地将网络中的一部分神经元暂时从网络中移除。
- 强制网络学习更加鲁棒的特征,减少对特定神经元的依赖。
早停(Early Stopping):
- 在验证集上的性能不再提高时停止训练。
- 防止模型在训练数据上过度训练,从而减少过拟合的风险。
数据增强(Data Augmentation):
- 通过对训练数据进行各种变换(如旋转、缩放、裁剪等)来增加数据的多样性。
- 使得模型能够从更多的角度和场景中学习特征,提高泛化能力。
常见的正则化分为L2正则化和L1正则化,前者使用的是参数的二范数而后者使用的是一范数:

L1 正则化会导致参数的稀疏化(就是存在比较多的0),因此现在越来越多会使用 L2 正则化。而在描述矩阵的时候这个范数则被称为 Frobenius 范数,描述的是矩阵中每个元素的平方和。
加入正则化项以后的代价函数可以被写作:

还有一种比较实用的正则化方法是 Dropout(随机失活)正则化方法,整体思路就是对网络中的节点随机分配概率,按照分配的概率随机地将网络中部分节点进行失活从而得到一个规模更小的网络来降低过拟合可能性。这里介绍一种比较常用的部署方法——反向随机失活(Inverted dropout):
比如现在需要有一个3层网络,那么在每一轮训练过程(一次前向传播+一次反向传播)中,分别给三层神经网络的每个神经元计算一个是否丢弃的随机数,这里以第二层为例来说明,比如第二层共有5个神经元,那么就可以随机5个在[0,1]之间均匀分布的随机数,然后给定一个keep_prob对刚刚的随机数组进行0-1二值化,此时得到的0-1数组就作为该层神经元的“掩码”,0对应的神经元在本次训练中就不起作用。不过为了补偿神经元数量衰减造成的网络输出均值的改变,这里会手动给该层神经元剩余网络的输出除以**keep_prob**。每次训练的时候都会对每个层重新计算这个随机数组,使得每次参与训练的神经元数目都不会特别多,神经网络“更加简单”,以此来降低过拟合可能性。
不过要注意的就是上述正则化方法只在训练的时候有用,不要在测试的使用启用随机失活正则化。从直观上来理解,随机失活机制的存在强迫神经元不能过分信任上一级任何一个神经元的输出,而是应该更加平均地“多听取各方意见”从而起到缩减范数的效果,这一点和 F 范数正则化在思路上其实是比较类似的。

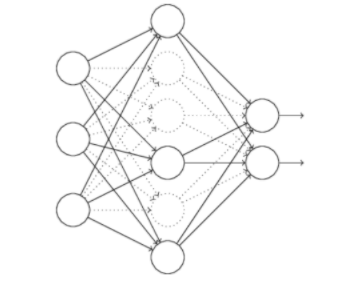
在进行随机失活正则化的时候,每一层神经网络的keep_prob可以选择得不一样,这一点相较于范数正则化更加灵活。一般而言不会对输入层神经元进行随机失活。
不过随机失活正则化会带来的问题就是代价函数的定义就显得不是很明确,所以调试神经网络性能的时候就会比较痛苦()。
还有一些其他的正则化方法,比如数据增强其实也是一种正则化手段:

还有一种正则化方法是在训练过程中寻找合适的实际提早结束训练(Early stopping),这种时机的查找一般通过观测验证集表现来实现,当发现验证集误差开始上升的时候就说明网络已经逐渐开始过拟合了所以可以停止训练了。
为了加快训练速度还需要做的一步就是对输入数据进行归一化,这里主要做的就是平移(零均值)和缩放(同方差),这在机器学习中提及过,也就不再赘述。