B树:原理、操作及应用
- 一、引言
- 二、B树概述
- 1. 定义与性质
- 2. B树与磁盘I/O
- 三、B树的基本操作
- 1. 搜索(B-TREE-SEARCH)
- 2. 插入(B-TREE-INSERT)
- 3. 删除(B-TREE-DELETE)
- 四、B树的C代码实现示例
- 五、总结
一、引言
在现代计算机科学中,高效的数据存储和检索是许多应用程序成功的关键。B树(B-tree)是一种自平衡的树,它能够保持数据稳定有序,其插入与查询的时间复杂度都是对数级别的,非常适合于磁盘等辅助存储器的存取系统。本文将详细介绍B树的基本原理、基本操作,并通过伪代码和C代码示例来解释其实现。
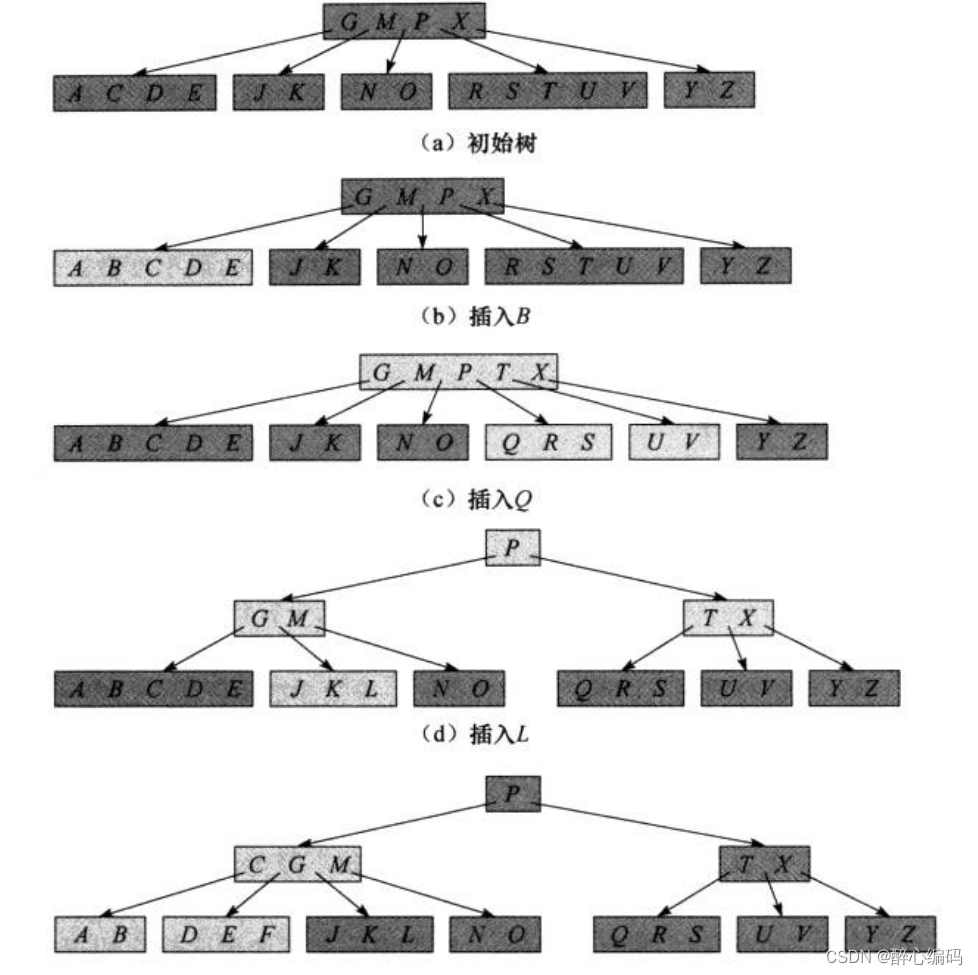
二、B树概述
1. 定义与性质
B树是一种多叉树,每个节点可以包含多个关键字和多个子节点。一个m阶的B树(m≥2)满足以下性质:
- 每个节点至多有m个孩子。
- 除了根节点外,每个非叶子节点至少有⌈m/2⌉个孩子。
- 根节点至少有两个孩子,除非它是叶子节点。
- 所有叶子节点都在同一层,并且不带信息(可以视为外部节点或查找失败的节点)。
- 非叶子节点包含n个关键字信息(K₁, K₂, …, Kₙ),且满足K₁ < K₂ < … < Kₙ。
- 非叶子节点的第i个子树中的所有关键字都在K_{i-1}和K_i之间(其中,K₀表示一个比该节点所有关键字都小的值,K_{n+1}表示一个比该节点所有关键字都大的值)。
2. B树与磁盘I/O
由于磁盘I/O操作通常比内存操作慢得多,因此,在设计和实现数据结构时,尽量减少磁盘I/O次数是关键。B树的设计充分考虑了磁盘的存取特性,通过增加树的扇出(即每个节点的子节点数)来降低树的高度,从而减少了查找过程中所需的磁盘I/O次数。
三、B树的基本操作
1. 搜索(B-TREE-SEARCH)
B树的搜索操作与二叉搜索树类似,从根节点开始,根据关键字的大小决定向下搜索的路径,直到找到目标关键字或到达叶子节点为止。以下是B树搜索的伪代码示例:
B-TREE-SEARCH(x, k)
i = 1
while i ≤ x.n and k > x.key[i]
i = i + 1
if i ≤ x.n and k == x.key[i]
return (x, i) // 返回包含关键字的节点和关键字在节点中的位置
elseif x.leaf
return NIL // 关键字不在树中
else DISK-READ(x, c[i]) // 读取子节点
return B-TREE-SEARCH(x.c[i], k) // 递归搜索子树
2. 插入(B-TREE-INSERT)
向B树中插入关键字的过程相对复杂,因为需要维护B树的性质。当向满节点插入新关键字时,需要进行分裂操作。以下是B树插入操作的伪代码框架:
B-TREE-INSERT(T, k)
r = T.root
if r.n == 2t - 1 // 根节点满了
s = ALLOCATE-NODE() // 分配新节点作为根节点的子节点
T.root = s
s.leaf = FALSE
s.n = 0
s.c[1] = r
B-TREE-SPLIT-CHILD(s, 1) // 分裂根节点
B-TREE-INSERT-NONFULL(s, k) // 向非满的新根节点插入关键字
else
B-TREE-INSERT-NONFULL(r, k) // 直接向根节点插入关键字
// 辅助过程,向非满节点插入关键字
B-TREE-INSERT-NONFULL(x, k)
// ... 省略具体实现细节,包括分裂操作等 ...
3. 删除(B-TREE-DELETE)
从B树中删除关键字同样需要维护B树的性质。删除操作可能比插入操作更复杂,因为可能需要合并节点或重新调整关键字。以下是B树删除操作的一个简要描述:
- 如果要删除的关键字在叶子节点中,直接删除并调整节点大小。
- 如果要删除的关键字在内部节点中,找到其前驱或后继替代该关键字,并递归删除前驱或后继。
- 如果删除操作导致节点大小低于最小要求,可能需要从相邻兄弟节点借调关键字,或者合并节点。
四、B树的C代码实现示例
由于完整的B树C代码实现较长且复杂,这里仅提供一个简化的框架和关键部分的代码示例,以便读者理解其实现思路。
首先,我们定义B树节点的结构体和一些辅助函数:
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define MAX_KEYS 5
#define MAX_CHILDREN 6
typedef int KeyType;
typedef struct BTreeNode {
int n; // 关键字数量
KeyType keys[MAX_KEYS]; // 关键字数组
struct BTreeNode *children[MAX_CHILDREN]; // 子节点指针数组
bool is_leaf; // 是否为叶子节点
} BTreeNode;
// 创建新节点
BTreeNode* createNode(bool is_leaf) {
BTreeNode* node = (BTreeNode*)malloc(sizeof(BTreeNode));
node->n = 0;
node->is_leaf = is_leaf;
for (int i = 0; i < MAX_CHILDREN; i++) {
node->children[i] = NULL;
}
return node;
}
// 分裂节点
void splitNode(BTreeNode* parent, int index, BTreeNode* child) {
// 创建新节点,并分配中间关键字之后的元素
BTreeNode* newNode = createNode(child->is_leaf);
newNode->is_leaf = child->is_leaf;
int mid = MAX_KEYS / 2;
for (int i = mid + 1; i <= MAX_KEYS; i++) {
newNode->keys[newNode->n] = child->keys[i];
newNode->n++;
}
if (!child->is_leaf) {
for (int i = mid + 1; i <= MAX_CHILDREN; i++) {
newNode->children[newNode->n] = child->children[i];
newNode->n++;
}
}
// 将中间关键字上升到父节点
parent->keys[index] = child->keys[mid];
child->n = mid;
// 插入新节点为父节点的一个子节点
for (int i = parent->n; i > index; i--) {
parent->keys[i] = parent->keys[i - 1];
parent->children[i + 1] = parent->children[i];
}
parent->children[index + 1] = newNode;
parent->n++;
}
// 插入非满节点
void insertNonFull(BTreeNode* node, KeyType key) {
int i = node->n - 1;
// 找到新关键字的插入位置
while (i >= 0 && key < node->keys[i]) {
node->keys[i + 1] = node->keys[i];
i--;
}
node->keys[i + 1] = key;
node->n++;
}
// B树插入操作
void insert(BTreeNode** root, KeyType key) {
BTreeNode* node = *root;
// 如果树为空,创建一个新节点
if (node == NULL) {
*root = createNode(true);
insertNonFull(*root, key);
return;
}
BTreeNode* current = node;
BTreeNode* parent = NULL;
int index = 0;
// 查找插入位置
while (!current->is_leaf) {
index = 0;
while (index < current->n && key > current->keys[index]) {
index++;
}
parent = current;
current = current->children[index];
}
// 插入到叶子节点
insertNonFull(current, key);
// 检查是否需要分裂
while (current->n == MAX_KEYS + 1) {
splitNode(parent, index, current);
if (parent == NULL) {
// 根节点满了,创建一个新的根节点
*root = createNode(false);
(*root)->children[0] = node;
splitNode(*root, 0, node);
return;
}
index = 0;
while (parent->keys[index] < current->keys[0]) {
index++;
}
current = parent;
parent = parent->children[0] == current ? NULL : current->children[index + 1];
}
}
// 主函数,用于测试
int main() {
BTreeNode* root = NULL;
// 插入一些关键字进行测试
insert(&root, 10);
insert(&root, 20);
insert(&root, 5);
insert(&root, 15);
insert(&root, 7);
// ... 可以继续插入其他关键字进行测试 ...
// 这里可以添加代码来遍历和打印B树的内容,以验证插入操作的正确性
return 0;
}
这个示例代码实现了B树的插入操作,包括节点的分裂和根节点的提升。请注意,这个代码是为了教学目的而简化的,并没有处理所有的边界情况,也没有实现删除和查找等操作。在实际应用中,还需要进一步完善和优化。
五、总结
B树作为一种高效的数据结构,广泛应用于数据库和文件系统的索引中。其自平衡的特性保证了高效的插入、删除和搜索操作,尤其适用于磁盘等辅助存储器的存取系统。通过伪代码和C代码示例的介绍,我们可以更深入地理解B树的原理和实现细节。在实际应用中,根据具体需求和场景,可以对B树进行适当的变种和优化,以进一步提高其性能。
![[基础] Unity Shader:顶点着色器(vert)函数](https://img-blog.csdnimg.cn/direct/7a37aa91bbdd4ba78d23fe22cc4b6d4c.gif)