看《计算机体系结构 量化研究方法》做的笔记,接着上一篇写
计算机体系结构:向量体系结构介绍-CSDN博客
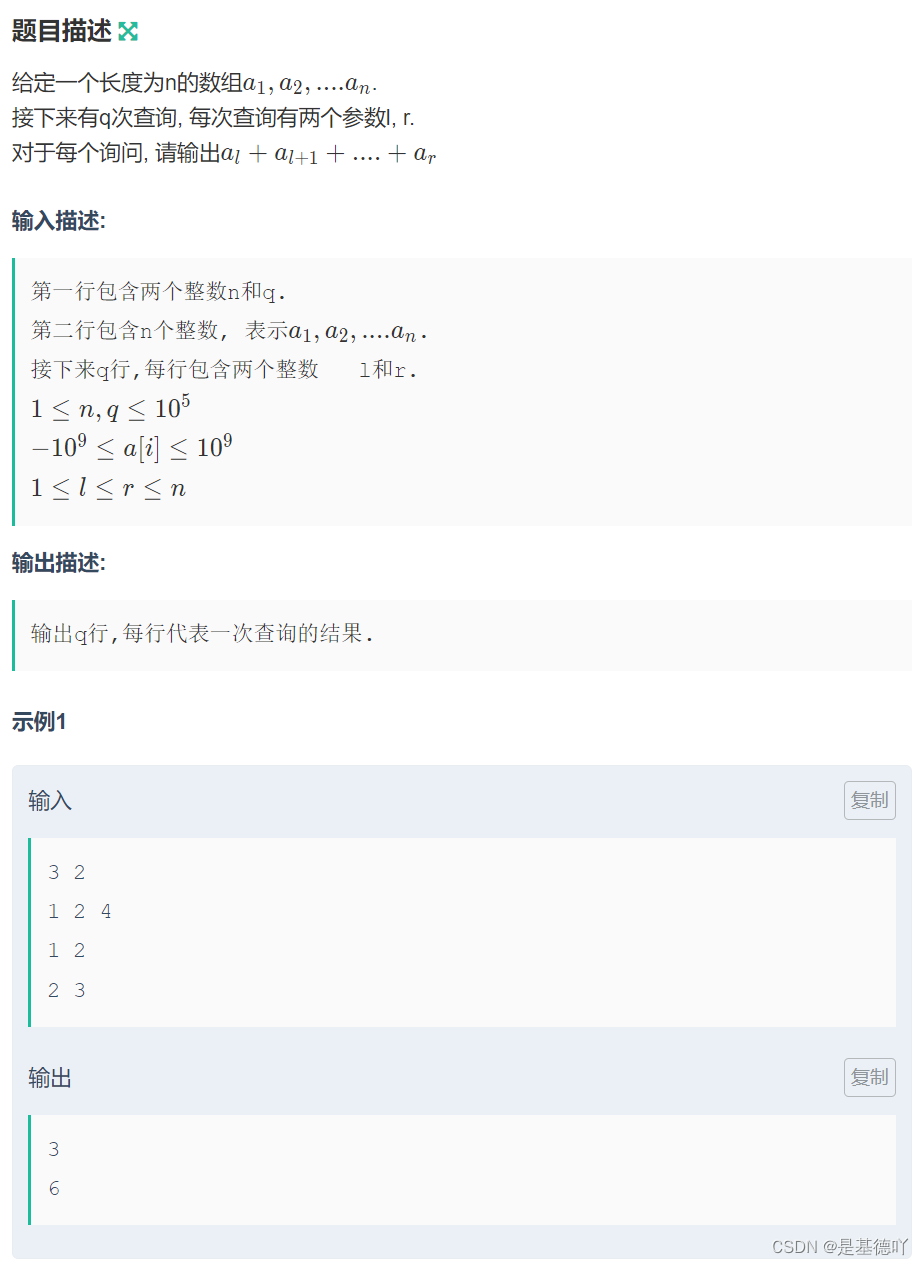
向量处理器工作的示例
aX+YSAXPY代表“单精度a×X加Y”,进行单精度浮点数的运算,其中a是一个标量,X和Y是向量。运算过程是对向量X的每个元素乘以标量a,然后将结果加到对应位置的向量Y的元素上。
DAXPY是“双精度a×X加Y”,双精度浮点数相比于单精度有更高的精度,占用更多的存储空间。
这两个操作是衡量向量处理器性能的经典案例。


传统MIPS处理器与向量处理器(如VMIPS)在执行效率的比较:
(1)向量处理器能够显著减少执行特定任务所需的指令数量。同样的向量运算任务,MIPS可能需要执行大约600条指令,而向量处理器VMIPS只需要6条。这是由于向量处理器能够并行处理向量中的所有元素(本例为64个),因此一条向量指令就能完成对整个向量的操作,大大减少了指令的开销。
(2)向量化代码:当编译器针对这类重复的向量操作优化代码时,它会产生“已向量化”或“可向量化”的代码,意味着代码能够直接利用向量处理器的特性,大部分执行时间都在高效的向量运行模式下进行。如果循环中的迭代之间没有依赖关系(循环间无关),那么这些循环就很适合向量化处理。
(3)在MIPS处理器中,由于指令依赖性,比如加法(ADD.D)必须等待乘法(ML.D)的结果,存数(S.D)必须等待加法完成(ADD.D),这导致了频繁的流水线停顿。向量处理器通过“链接”(chaining)机制,仅在处理向量的第一个元素时发生停顿,之后的元素连续处理,无需每次操作都停顿。这样,每条向量指令引起的停顿次数大大减少,相比MIPS减少了约64倍。
(4) 尽管如循环展开和流水线可以在一定程度上减轻MIPS处理器的流水线停顿问题,但它们难以从根本上缩小与向量处理器在指令带宽需求上的巨大差距。向量处理器在处理大规模同质运算时有明显的优势。
向量的执行时间
向量执行时间的影响因素:向量长度、操作间的结构冒险(如指令间的依赖关系导致的执行障碍)以及数据相关性(如写后读冲突)。
给定一个向量单元每周期能处理一个元素的初始速率(向量单元接受新操作数并生成新结果的速率),一条向量指令的执行时间大致等于向量的长度。这意味着,对于更长的向量,尽管处理单元可能有多条流水线,但执行时间主要由向量长度决定。执行时间可以通过计算护航指令组来估算。
护航指令组
比喻:在高速公路上开车,如果路况顺畅,没有施工、事故等阻碍(可以类比为计算中的“结构冒险”),就能一直保持高速行驶,不需要减速或停下来。护航指令组指的是那些能够连续执行而不被打断的向量指令集合。这些指令之间没有相互依赖,一个指令的执行不会等待另一个指令的结果,因此它们可以作为一个整体同时处理,简化了对程序执行速度的预估。计算这些无依赖指令组的数量,就可以大概知道整个程序需要多少时间来完成其向量计算部分。
结构冒险与分组执行
结构冒险指的是指令执行顺序上的障碍,比如某些指令的执行必须等待前一条指令完成特定的操作。在向量计算中,如果存在这样的依赖关系,那么这些指令就不能放在同一个护航指令组里,因为它们不能连续执行。
存在 “写后读”数据依赖(即一个指令写入的数据被后续指令立即读取)的指令会被分配到不同的护航指令组中,确保每一组都能独立、无阻地执行。但是链接操作可以让他们在一个护航指令组中。
链接操作
链接操作是一种硬件设计技术,用于优化处理器内部的数据流动,特别是在向量处理器中处理存在数据依赖关系的操作时尤为重要。
想象一下,在一家快递公司工作,负责处理一系列包裹的发送。每个包裹都需要先从一个处理点(比如打包区)移动到另一个处理点(比如发货区)。正常情况下,如果一个包裹的处理需要等待前一个包裹的某个信息(比如标签),那么整个流程就会暂停,直到所需的信息就绪。
链接操作就像操是在快递公司的不同处理区域之间建立了直接的传送带。 当一个包裹(代表计算中的数据)在打包区完成贴标签(一个作),这个标签(数据结果)能立即通过传送带传送到相邻的发货区,而不需要等待整个包裹物理移动完成。这样,即便后面的包裹(后续操作)需要这个标签信息,它也不必等待前一个包裹完全离开打包区,而是可以直接从传送带上获取所需的信息,立刻开始自己的处理流程。
这种“传送带”机制就是硬件层面的数据转发。当一个向量操作产生结果时,这个结果能够立即被“转发”给下一个依赖于该结果的操作,而不需要等待整个向量操作完成后再存储和重新加载数据。这种即时转发显著减少了数据等待时间,提升了处理器的效率,尤其是在执行大量数据并行操作的向量计算中。
链接操作是一种加速数据流动的技术,它允许处理器在处理有依赖关系的操作时,通过硬件直接传递数据,从而避免了不必要的等待时间,让计算流程更加顺畅高效。
(这个地方似懂非懂,比较抽象,硬件中链接的过程是什么,为什么链接可以让不同指令处于有一个护航指令组?护航指令组由谁划分的?)
钟鸣
根据上面护航指令组的概念,可以引入一个时间度量:钟鸣
钟鸣是衡量护航指令组执行时间的单位,一个钟鸣代表一组护航指令的执行周期。对于VMIPS而言,若向量长度为n,且每个护航指令组在理想情况下视为一个单位时间,则m个护航指令组的执行时间大约为m*n个时钟周期。钟鸣忽略了某些特定开销,尤其对长向量的近似更为准确。
开销考虑与钟鸣的局限性:使用钟鸣作为时间度量时,未考虑的开销包括单个周期内向量指令启动的限制。实际中,如果处理器每周期只能启动一条向量指令,钟鸣数可能低估实际执行时间。然而,由于向量长度通常远超单个护航指令组的指令数,将护航指令组视为一次钟鸣执行提供了一个简化的性能评估视角。
举例:

在性能分析时,尽管钟鸣模型提供了一种简化的方法来估算整体执行时间,但它通常不直接考虑这些启动延迟等具体开销。因此,虽然钟鸣数能够提供对程序执行时间的粗略估计,但在精确评估时还需考虑像启动时间这样的额外因素。
向量启动时间指的是从向量指令开始执行到其产生的第一个结果可用所需的时间。这部分时间主要受向量功能单元(负责执行向量运算的硬件部分)的流水线延迟影响。流水线是现代处理器中常见的设计,它通过将复杂操作分解成多个步骤,使得每个步骤可以在不同的时钟周期并行执行,从而加速整体处理速度。然而,每个步骤之间存在一定的延迟,尤其是在流水线的不同阶段之间,这就构成了启动时间的一部分。
以VMIPS为例,其中向量功能单元的流水线深度(即完成一个操作所需的时钟周期数)如下:
浮点加法: 6个时钟周期、浮点乘法: 7个时钟周期、浮点除法: 20个时钟周期、向量装载: 12个时钟周期
比如执行一个浮点加法操作,从读取操作数开始到得到第一个加法结果,至少需要等待6个时钟周期。
之后章节讨论的内容:
如何实现单个向量的高速执行:探讨向量处理器如何实现每个时钟周期处理多于一个元素的能力,以此提升处理速度。
处理非标准向量长度的程序:面对向量长度与处理器向量寄存器长度不匹配的情况(如VMIPS中寄存器长度为64),如何设计高效的策略来兼容和优化这类程序执行。
向量化代码中的条件语句处理:分析如何有效处理含有条件分支(IF语句)的代码,使之能够向量化,从而扩展向量化的应用范围。
存储器系统的需求:讨论向量处理器在执行过程中对存储器带宽的需求,强调没有足够的内存访问速度,向量性能提升将受限。
多维矩阵的向量化处理:探索如何有效向量化多维矩阵运算,这是科学计算和工程应用中常见的数据结构。
稀疏矩阵的向量化:研究向量处理器如何高效处理稀疏矩阵,这类数据结构在许多领域普遍存在,但其特殊性对向量化提出了挑战。
向量计算机的编程方法:强调编程技术和编译器优化对于发挥向量体系结构优势的重要性,指出只有编程实践与硬件创新相结合,才能实现技术的广泛应用和接受。