R的数据类型有数值型num,字符型chr,逻辑型logi等等。
R最常处理的数据结构是:向量,数据框,矩阵,列表。
向量有数值型向量,字符型向量,逻辑型向量等,字符型向量就是反应属性或类别的变量,比如年级有一年级,二年级。若干个向量组合在一起就是数据框。可以简单理解为数据框其实就是我们常见的excel表格,表格的每一列就是一个向量。以后做数据分析的时候处理的大部分都是数据框。
可以在创建数据框的同时给每一列起名字,比如代码
x

还可以对两个数据框进行合并

结果如图,其中rbind表示按照行来合并数据框

创建数据框使用的是函数data.frame,其中这个函数的参数允许是数据框,也可以是向量,比如上面的代码表示刚上来数据框my_data有三列,然后又调用了一次data.frame把x这一列加了进去,现在的数据框如图

在数据框中添加新的列

在数据框中添加新的列还可以使用$符号,这个符号是索引的意思,一般是用来索引数据框中的某一列,而如果我们给的列名不存在,则会自动创建一列。
提取数据框中的元素可以使用某一行加某一列的下标,也可以直接使用行的下标+列名。比如要提取上面这个数据框中的19.9,可以写my_data[2,3]也可以写my_data[2,"bmi"]
下面是一些示例

如果要修改数据框中的内容可以使用函数edit,比如运行代码edit(my_data)将会弹出一个这样的界面,我们可以直接在这个界面中修改my_data的内容。
但是edit函数修改的结果是通过返回值来修改的,而非直接修改my_data,需要使用变量来接收这个返回结果,如果使用my_data接收,则会覆盖my_data的内容,效果上就是把my_data的内容修改了。
创建矩阵

使用matrix函数创建矩阵的话默认行名和列名就是上面这样,我们可以使用rownames和colnames函数对行名和列名进行修改

列表是一个大杂烩,可以容纳各种数据结构
创建列表并查看其结构如图所示

mylist这个列表中有一个数据框my_data,一个矩阵my_matrix,一个数值型变量num,可以观察到如果不对所创建的列表的名字做任何要求的话默认每个元素的名字是两个中括号加下标。这样的名字可读性不强,让人不知道这个[[1]]代表什么意思,我们可以使用names函数对这个列表的每个元素起名,比如

这样列表mylist的每个元素就有了自己的名字,可读性变强了。调用列表中的元素使用的符号是$,由于列表中的元素可能是数据框等其他数据类型,因此我们通过$拿到列表中某个元素之后还可以继续调用这个元素中的元素,比如

表示调用了列表mylist中名为my_data的元素,这个元素是一个数据框,拿到了这个数据框之后就可以使用提取数据框中某个元素的方法来获取需要的元素了,这里是提取了数据框my_data中第一行,bmi列的元素。
字符串
只要某块内容加了单引号或者双引号,那这块内容就是字符串,实际上在R中一个数据只要不是字符串,那他必然就是数值。如果一个数据我们需要的是他的数值大小这个属性,而且希望他可以做基本运算比如加减乘除,那么这个数据就肯定不是字符串,因为字符串是无法进行这样的基本运算的。
在进行数据分析的时候我们经常看到这样的信息

饮食偏好这一栏中的信息非常复杂,难以直接分析,我们应该把这个信息整理一下,比如辛辣单独放一列,喜欢吃辛辣就是1,不喜欢就是0。
nchar() 函数计算并返回每个输入字符串的字符数。
运行代码

其中mydata如图所示

代码要统计mydata中职业这一列的每个字符串的长度,R语言中一个汉字是一个字符,运行结果如图

找查字符串中是否包含目标子串
比如在上面的饮食偏好那一列中是否有辛辣,使用的函数是grep或者grepl这个函数,格式分别为grep("目标字符",字符串变量),grepl("目标字符",字符串变量),但是这两个函数的返回值有区别,grep返回的是有辛辣那一行的,而grepl返回的是TRUE和FALSE,在有辛辣的行返回TRUE,没有的行返回FALSE。如图


在R语言中TREU代表1,FALSE代表0,我们可以把grepl的结果转成0和1表示,使用的函数是as.numeric,如图

我们还可以基于这个结果在原来的数据框上添加一列:
mydata$辛辣
此时数据框如图

找查某个子串在字符串中的位置使用的函数为regexpr函数,格式为regexpr("查找内容",字符串,fixed=TRUE),fixed=TRUE表示精确查找。如果在使用regexpr函数的时候无法得到我们的预期结果,那么不妨试试加上fixed=TRUE这个参数。
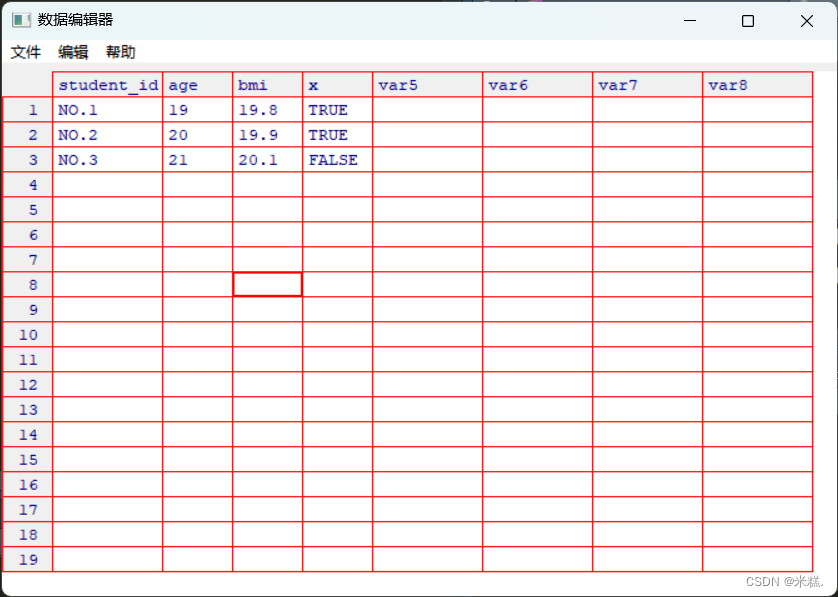
依据下标提取字符串中的子串使用的函数为substr,格式为substr(字符串,开始下标,结束下标)。这个函数还可以用来把某个子串修改成别的内容,比如我们想要隐匿身份证号中代表年份的四位也就是7到10位,可以先这样写

先在数据框中创建新的一列,然后提取出这一列下标7~10的元素并修改成xxxx,效果如图,确实完成了隐匿日期的作用,
替换字符串中内容的函数是gsub,格式为gsub("被替换的内容","替换内容",要操作的字符串)。如果替换内容为空,则会起到一个删除被替换内容的效果。比如姓名编号这一列,我想要把这些编号删掉,只留下张三,李四这样的名字,也可以使用gsub函数

具体写法为mydata$姓名编号

注意gsub函数的结果是以返回值的形式给出的,不是直接修改原来的字符串,如果想要修改原来的字符串,我们应该使用原来字符串对应的那一列来接收这个返回值,让然也可以单独生成一列来接收这个结果。
如果是要删掉姓名编号中的汉字只留下阿拉伯数字,可以这样写mydata$编号

把两个字符串粘贴在一起使用的函数是paste和paste0函数,格式为paste(变量1,变量2,"连接符号"),paste0(变量1,变量2),这两个函数的区别在于paste函数可以指定连接字符串的时候以什么符号作为分隔,而paste0函数表示不做任何分隔。比如mydata$连接

当然也可以把sep这个参数指定为空字符,这样连接的字符串之间就没有分割符号了。等价于paste0(变量1,变量2)。
拆分字符串使用的函数是strsplit,格式为strsplit(要操作的字符串,split=某字符串,fixed=TRUE),表示按照参数split指定的字符串或者字符来分割要操作的字符串。比如有这样一列
使用代码tmp

如何把使用strsplit得到的这个列表变成数据框类型呢?直接使用函数as.data.frame吗?执行代码tmp

虽然是转换成了数据框类型,但好像并不符合我们的预期,因为这样横着的格式显然不能够与原来的mydata合并。下面介绍把tmp转换成数据框的正确方式
首先介绍两个函数,第一个是do.call函数,
基本语法为do.call(function, args),其中function是一个函数,args是一个列表或者向量,如果把列表或者向量中的每一个元素都作为调用function的参数,举个例子,do.call(sum, list(1, 2, 3))就表示把列表中所有元素作为sum函数的参数,并调用sum函数,也就是说这句代码等价于sum(1,2,3),结果为6。当只有少量参数的时候我们写sum(1,2,3)和do.call(sum,list(1,2,3))都可以,但是如果列表中有很多元素,使用do.call函数就有了巨大的优势。实际上do.call函数主要就是用于这样的参数很多而不好列举的情形。即使循环调用sum函数也可以完成累加的效果,但是执行效率和简洁性就没有do.call函数好。
再介绍rbind函数,在R语言中,rbind是一个用于按行(row-wise)绑定两个或多个向量、矩阵或数据框(data frame)的函数。
rbind的基本语法为rbind(x, ...)
其中,x 是第一个要绑定的对象,... 表示你可以传递任意数量的其他对象进行行绑定。
示例
向量行绑定
vec1
vec2
rbind_result
这将返回一个矩阵:

矩阵行绑定
mat1
mat2
rbind_result
这将返回一个新的矩阵,其中包含了mat1和mat2按行绑定的结果:

数据框行绑定
df1
df2
rbind_result
这将返回一个新的数据框,其中包含了df1和df2按行绑定的结果:

注意事项
- 当你使用rbind来绑定矩阵或数据框时,它们必须具有相同的列数。
- 如果绑定的对象是向量,它们将被转换成列数为1的矩阵。
- 如果对象是数据框,rbind会保持数据框的结构,但会将新行添加到数据框的末尾。
接下来开始介绍如何正确把上面的tmp转换成数据框类型,执行代码

do.call(rbind,tmp)表示把tmp列表中的所有元素都作为调用rbind的参数,也就是说这句代码等价于rbind("张三""12535"......)其中rbind中共计90个参数,这90个元素每一个元素都是一个字符串,字符串是向量类型的某一种,把这些向量按照行进行合并,得到了一个矩阵,随后使用as.data.frame函数把这个矩阵转换成数据框类型并覆盖掉tmp,转换后的tmp如图所示

但是此时的数据框名字是V1,V2,于是使用colnames函数把列名修改为编号1与编号2,最后使用data.frame把tmp数据框与mydata数据框合并起来。
此时的mydata如图,刚才tmp的两列也就是姓名1与编号1已经被加进去了

总结
调用多参数函数的工具:do.call(函数名,列表或者向量),表示把列表或者向量中的所有元素作为要调用的函数的参数。
在弹窗中修改数据框内容:edit(数据框的名字),调用之后弹出一个窗口,可以直接在窗口里面对数据框的内容进行修改,但是修改的结果是以返回值的形式给出的,不会直接修改原数据框,应该使用原数据框来接收这个返回值以覆盖原来数据框打到修改原数据框的效果。
统计字符串长度:nchar(字符串)
检查字符串中是否包含目标子串grep("目标字符",字符串变量),grepl(目标字符,字符串变量),表示在字符串变量中寻找目标字符,其中grep函数返回哪些行有目标字符,grepl函数的返回值是逻辑值,有目标字符的行对应位置返回TREU,没有的返回FALSE,由于在R语言中T和F代表1和0,因此通过把基于grepl函数的结果借助as.numeric函数转换成数值型之后,可以在原有数据框添只有1,0的列,当然不转换成数值型也可以,那就添加的是T和F的列。
找查某个子串在字符串中的位置regexpr("查找内容",字符串,fixed=TRUE),表示在字符串中找查指定的内容,返回值是对应内容的下标,其中参数fixed表示精准查找。经常与substr函数配合使用。
substr函数用于提取处指定下标的元素,语法为substr(字符串,开始下标,结束下标),利用该函数可以替换掉某一部分子串,比如substr(mystr,1,3)
替换字符串内容gsub,语法为gsub("被替换的内容","替换内容",要操作的字符串),当替换内容为空时,效果为删除被替换的内容。
连接字符串paste(字符串1,字符串2,sep="某字符"),表示以“某字符”为标志连接字符串1和字符串2,paste0表示直接连接两个字符串,中间无任何标志。
拆分字符串strsplit(要操作的字符串,split=某字符串,fixed=TRUE),表示以某字符串为标准分割掉要操作的字符串。该函数的结果为一个列表,要转换成数据框可以使用as.data.frame(do.call(rbind,mylist)),其中mylist为strsplit函数的返回结果。
日期变量Date(注意第一个字母是大写)与时间变量POSIXct(注意最后两个字母是小写)
实际上日期类型和时间变量都字符串类型的一种,我们实际上无法直接创建日期类型的变量,需要把按照对应格式创建的字符串转换成日期变量。日期变量的格式为YYYY-mm-dd表示年月日,时间变量的格式是YYYY-mm-dd HH:MM:SS注意在日期和时间之间有一个空格。分别代表年 月 日 小时 分钟 秒,之所以要存在日期变量和时间变量,是因为字符串类型是无法直接进行运算的,而我们有时候还需要计算两个日期之差来得到中间有多少天,所以时间变量和日期变量应运而生。
lubridate包是一个针对时间日期进行操作的R包

首先定义了字符串x和字符串y,并把他们分别转换成日期变量和时间变量,然后调用lubridate包中的函数,分别用于查看是哪一年,哪个月,哪一天,哪一季度,这里示例使用的是日期变量x,如果换成时间变量y也是可以的,同时对于时间变量还可以查看小时,分钟,秒,如图

对于时间日期,做加法是加在秒上,对于日期变量,做加法是加在天上。
再来看一个示例

有这样一个数据框,数据如上,通过str函数可以查看数据框每一列的类型,如图

入院日期,手术日期,出院日期应该是Date类型,手术开始和结束的时间应该是POSIXct类型,这些类型都对不上,因此我们现在来修改一下类型

这里修改类型使用的是来自lubridate包中的ymd函数,顾名思义就是年月日,ymd(某变量)可以把该变量转换成Date类型,ymd_hms顾名思义就是年月日小时分钟秒,可以把变量转换成POSIXct类型。而R中的POSIXct类型要求是年月日空格小时分钟秒的格式,但是表格中就只有小时分钟秒,因此我们应该先使用paste函数把手术日期和手术开始时间连接起来。最终调整后的数据类型如图

类型全都修改对了之后就可以进行日期时间的差的计算了。使用的函数式difftime函数,语法为difftime(日期(时间)1,日期(时间)2,units=单位),返回值是日期1减去日期2,这个结果以什么形式展示就要看后面的参数units是days还是hours等。比如执行mydata$手术等待时间

缺失值NA
summary用于反应数据集的整体概况,其中包括了缺失值的个数,因此我们可以使用summary来查看缺失值的个数。如果要查看缺失值的位置,可以使用is.na函数,语法为is.na(变量),返回结果是在变量对应下标位置返回TRUE或者FALSE。搭配which函数就可以直接查看到缺失值的下标了。如图

发现x中下标1和下标4的元素是缺失值。
在计算平均值的时候是不允许出现NA的,要忽略掉NA对剩余元素求平均值,可以使用函数na.omit,比如mean(na.omit(x))就是计算的1,2,5这三个数的平均值
缺失值NA的处理
对于连续型变量的缺失值处理:
缺失值NA比较少的情况,如果变量服从正态分布,通常使用均值填充缺失值,如果变量不服从正态分布,通常使用中位数来填充缺失值。
对于缺失值比较多的情况,可以直接把该列删掉,例如数据框mydata的第六列缺失值很多,执行mydata
检验数据集是否服从正态分布使用函数shapiro.test(向量/数据框的某一列列名)
如果p值小于0.05就说明不服从正态分布。从而决定是否要使用均值来填充缺失值。
运行代码x[which(is.na(x))]
which(is.na(x))表示NA的下标,x[which(is.na(x))]提取到了缺失值,mean(na.omit(x))表示忽略缺失值,求其余元素的均值,因此最终代码的意思就是把这个均值填充到原来NA的位置。
x[which(is.na(x))]
对于分类型变量的缺失值处理:
对于中文的分类变量,比如这里的男和女,使用summary直接查看并不能看出有无缺失值。这是因为在有中文的分类变量里面缺失值NA会被解读成一个字符。

正确的处理方式是导入的数据的时候使用阿拉伯数字代表某种分类的含义,比如用1代表男,用2代表女,然后使用函数factor函数把x转换成因子类型,并同时指定每种levels代表的标签含义,如图

结果如图

对于分类型变量的缺失值应该使用众数来填补。在modeest包中,有一个mode()函数可以用来计算众数。或者可以使用names(which.max(table(x)))这句代码来找到分类变量中的出现频次最高的label也就是所谓的众数
其中table(x)会创建一个频率表,里面有各个levels出现的次数,然后调用which.max找出出现频率最高的那个levels,但如果此时把这个结果填充,将填充1或者2,而不是男/女,因此我们再使用names函数将这个索引转换为对应的类别名称。
重新编码
有这样一个问卷

问卷的调差结果如下

维度2表示行为不当,比如第一题说很少学习,如果选5就表示行为不当,但是同样属于维度1的题目第10题,如果选5就表示行为很得当,而选1才表示行为不当,对于这样的数据,我们经常要进行逆处理,从而与维度中其他选项的方向保持一致。也就是说我们现在要把Q10这一列的12345对应转成54321。逆向的重新编码,使用的函数是recode,这个函数所在的R包是car。
运行代码mydata$Q10_逆

此时的Q10逆在第25列,我们想要让他在Q10的后面一列也就是第15列,应该写mydata
调整完之后这几个代表不当行为的题目就是相同方向的了,也就是说得分越高说明行为越不得当,我们就可以把这些题目对应的列加起来取一个平均值,从而就能得到每个学生不当行为的得分这样一列。
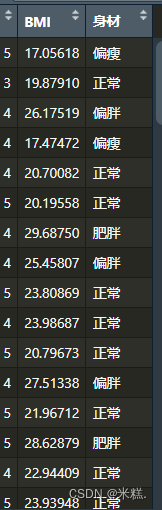
我们还可以对数据进行一些预处理,比如调查问卷中给出了身高体重,我们就可以计算出每个学生的BMI,然后根据BMI的数值来判断学生身材。代码如下

其中mydata$身材[mydata$BMI
结果如图