📢📢📢📣📣📣
哈喽!大家好,我是【IT邦德】,江湖人称jeames007,10余年DBA工作经验
一位上进心十足的【大数据领域博主】!😜😜😜
中国DBA联盟(ACDU)成员,目前从事DBA及程序编程
擅长主流数据Oracle、MySQL、PG 运维开发,备份恢复,安装迁移,性能优化、故障应急处理等。
✨ 如果有对【数据库】感兴趣的【小可爱】,欢迎关注【IT邦德】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
文章目录
- 前言
- 📣 1.数值类型
- ✨ 1.1 整数类型
- ✨ 1.2 任意精度型
- ✨ 1.3 序列整型
- ✨ 1.4 浮点类型
- 📣 2. 布尔类型
- 📣 3. 字符类型
- 📣 4. 二进制类型
- 📣 5. 日期/时间类型
- ✨ 5.1 日期输入
- ✨ 5.2 时间段输入
- 📣 6. 几何类型
- 📣 7. 网络地址类型
- 📣 8. 位串类型
- 📣 9. 文本搜索类型
- ✨ 9.1 tsvector
- ✨ 9.2 tsquery
- 📣 10. UUID数据类型
- 📣 11. JSON/JSONB类型
- 📣 12. HLL数据类型
- 📣 13. 范围类型
- 📣 14.XML类型
前言
本篇介绍了openGauss的数据类型及应用📣 1.数值类型
✨ 1.1 整数类型
| 名称 | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| TINYINT | 微整数,别名为INT1 | 1字节 | 0 ~ 255 |
| SMALLINT | 小范围整数,别名为INT2 | 2字节 | -32,768 ~ +32,767 |
| INTEGER | 常用的整数,别名为INT4 | 4字节 | -2,147,483,648 ~ +2,147,483,647 |
| BINARY_INTEGER | 常用的整数INTEGER的别名 | 4字节 | -2,147,483,648 ~ +2,147,483,647 |
| BIGINT | 大范围的整数,别名为INT8 | 8字节 | -9,223,372,036,854,775,808 ~ +9,223,372,036,854,775,807 |
✨ 1.2 任意精度型
| 名称 | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| NUMERIC[(p[,s])], DECIMAL[(p[,s])] | 精度p取值范围为[1,1000],标度s取值范围为[0,p]。 说明: p为总位数,s为小数位数。 | 用户声明精度 | 未指定精度的情况下,小数点前最大131,072位, 小数点后最大16,383位 |
| NUMBER[(p[,s])] | NUMERIC类型的别名 | 用户声明精度 | 未指定精度的情况下,小数点前最大131,072位, 小数点后最大16,383位 |
✨ 1.3 序列整型
| SMALLSERIAL | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| SMALLSERIAL | 二字节序列整型 | 2字节 | -32,768 ~ +32,767 |
| SERIAL | 四字节序列整型 | 4字节 | -2,147,483,648 ~ +2,147,483,647 |
| BIGSERIAL | 八字节序列整型 | 8字节 | -9,223,372,036,854,775,808 ~ +9,223,372,036,854,775,807 |
| LARGESERIAL | 十六字节序列整型 | 16字节 | -170,141,183,460,469,231,731,687,303,715,884,105,728 ~ +170,141,183,460,469,231,731,687,303,715,884,105,727 |
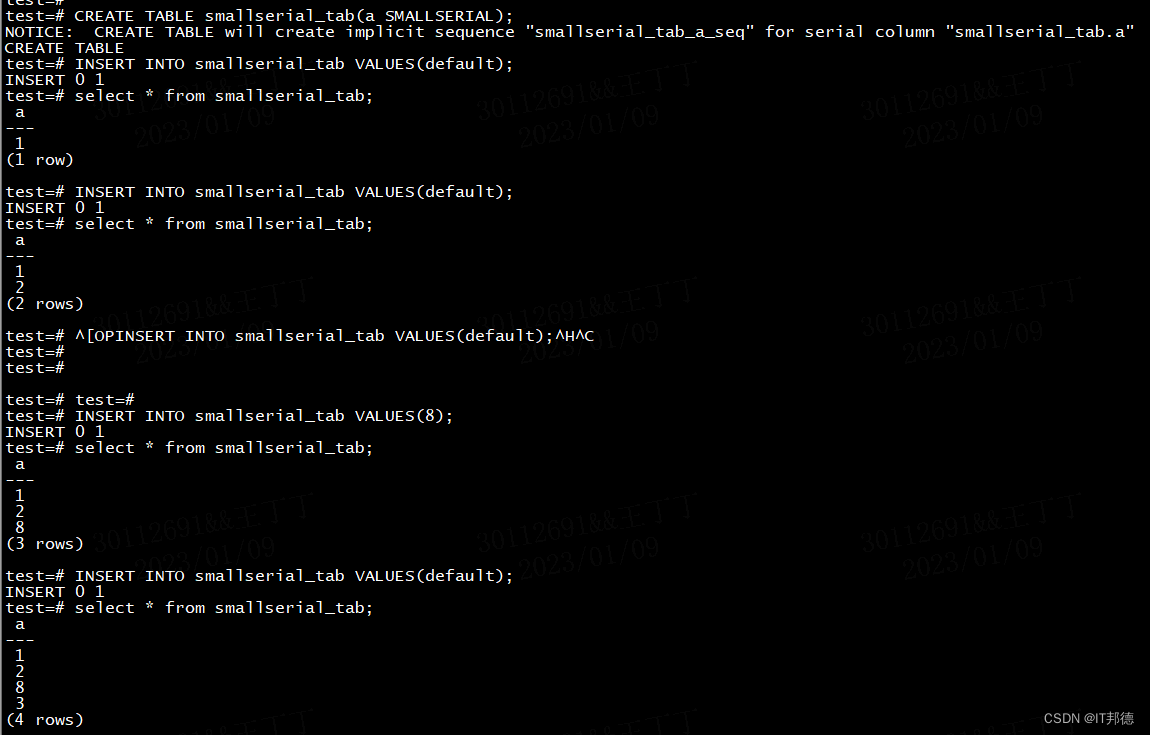
案例说明:
test=# CREATE TABLE smallserial_tab(a SMALLSERIAL);
–插入数据。
openGauss=# INSERT INTO smallserial_tab VALUES(default);
–再次插入数据。
openGauss=# INSERT INTO smallserial_tab VALUES(default);
test=# INSERT INTO smallserial_tab VALUES(8);
test=# INSERT INTO smallserial_tab VALUES(default);
✨ 1.4 浮点类型
| 名称 | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| REAL,FLOAT4 | 单精度浮点数,不精准 | 4字节 | -3.402E+38~3.402E+38,6位十进制数字精度 |
| DOUBLE PRECISION,FLOAT8 | 浮点数,不精准。精度p取值范围为[1,53] 说明:p为精度,表示总位数 | 4字节或8字节 | -1.79E+308~1.79E+308,15位十进制数字精度 |
| FLOAT[§] | 常用的整数,别名为INT4 | 4字节 | -2,147,483,648 ~ +2,147,483,647 |
| BINARY_DOUBLE | 是DOUBLE PRECISION的别名 | 8字节 | -1.79E+308~1.79E+308,15位十进制数字精度 |
| DEC[(p[,s])] | 精度p取值范围为[1,1000],标度s取值范围为[0,p]。 说明:p为总位数,s为小数位位数。 | – | 未指定精度的情况下,小数点前最大131,072位, 小数点后最大16,383位。 |
| INTEGER[(p[,s])] | 精度p取值范围为[1,1000],标度s取值范围为[0,p] | 4字节 | -2,147,483,648 ~ +2,147,483,647 |
📣 2. 布尔类型
| 名称 | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| BOOLEAN | 布尔类型 | 1字节 | true:真 false:假 null:未知(unknown) |
📣 3. 字符类型
| SMALLSERIAL | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| CHAR(n) CHARACTER(n) NCHAR(n) | 定长字符串,不足补空格。n是指字节长度,如不带精度n,默认精度为1 | 最大为10MB。 | – |
| VARCHAR(n) CHARACTER VARYING(n) | 变长字符串。n是指字节长度 | 最大为10MB | – |
| VARCHAR2(n) | 变长字符串。是VARCHAR(n)类型的别名。n是指字节长度 | 最大为10MB | – |
| NVARCHAR2(n) | 变长字符串。n是指字符长度 | 最大为10MB | – |
| TEXT | 变长字符串 | 最大为1GB-1 | – |
| CLOB | 文本大对象,是TEXT类型的别名 | 最大为1GB-1 | – |
📣 4. 二进制类型
| 名称 | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| BLOB | 二进制大对象 | 最大为1GB-8203字节 | - |
| RAW | 变长的十六进制类型 | 最大为1GB-8203字节 | - |
| BYTEA | 变长的二进制字符串 | 最大为1GB-8203字节 | - |
📣 5. 日期/时间类型
说明: 如果其他的数据库时间格式和openGauss的时间格式不一致,可通过修改配置参数DateStyle的值来保持一致。
| 名称 | 描述 | 存储空间 | 范围 |
|---|---|---|---|
| DATE | 日期和时间 | 4字节 | - |
| TIME [§] [WITHOUT TIME ZONE] | 只用于一日内时间 p表示小数点后的精度,取值范围为0~6 | 8字节 | - |
| TIME [§] [WITH TIME ZONE] | 只用于一日内时间,带时区 p表示小数点后的精度,取值范围为0~6 | 12字节 | - |
| TIMESTAMP[§] [WITHOUT TIME ZONE] | 日期和时间 p表示小数点后的精度,取值范围为0~6 | 8字节 | - |
| TIMESTAMP[§][WITH TIME ZONE] | 日期和时间,带时区。TIMESTAMP的别名为TIMESTAMPTZ p表示小数点后的精度,取值范围为0~6 | 8字节 | - |
| SMALLDATETIME | 日期和时间,不带时区 精确到分钟,秒位大于等于30秒进一位 | 8字节 | - |
| INTERVAL DAY (l) TO SECOND § | 时间间隔,X天X小时X分X秒 l:天数的精度,取值范围为06<br>p:秒数的精度,取值范围为06 | 16字节 | - |
| INTERVAL [FIELDS] [ § ] | 时间间隔 fields:可以是YEAR,MONTH,DAY,HOUR,MINUTE,SECOND等 p:秒数的精度,取值范围为0~6,且fields为SECOND,DAY TO SECOND等 | 12字节 | - |
| reltime | 相对时间间隔,格式为: X years X mons X days XX:XX:XX | 4字节 | - |
| abstime | 日期和时间。格式为: YYYY-MM-DD hh:mm:ss+timezone | 4字节 | - |
案例示范:
1.date类型
openGauss=# CREATE TABLE date_type(coll date);
openGauss=# INSERT INTO date_type VALUES (date '01-14-2023');
openGauss=# select * from date_type;
coll
---------------------
2023-01-14 00:00:00
2.TIME/TIMESTAMP类型
openGauss=# CREATE TABLE time_type (da time without time zone ,dai time with time zone,dfgh timestamp without time zone,dfga timestamp with time zone, vbg smalldatetime);
openGauss=# INSERT INTO time_type VALUES ('21:21:22','21:21:22 pst','2022-12-12','2022-12-11 pst','2022-04-12 04:05:06');
openGauss=# select * from time_type;
da | dai | dfgh | dfga | vbg
----------+-------------+---------------------+------------------------+---------------------
21:21:22 | 21:21:22-08 | 2022-12-12 00:00:00 | 2022-12-11 16:00:00+08 | 2022-04-12 04:05:00
3.INTERVAL 类型
openGauss=# CREATE TABLE day_type_tab (a int,b INTERVAL DAY(3) TO SECOND (4));
openGauss=# INSERT INTO day_type_tab VALUES (1, INTERVAL '3' DAY);
openGauss=# select * from day_type_tab;
a | b
---+--------
1 | 3 days
openGauss=# CREATE TABLE year_type_tab(a int, b interval year (6));
openGauss=# INSERT INTO year_type_tab VALUES(1,interval '2' year);
openGauss=# SELECT * FROM year_type_tab;
a | b
---+---------
1 | 2 years
✨ 5.1 日期输入
系统支持按照日、月、年的顺序自定义日期输入。如果把DateStyle参数设置为MDY就按照“月-日-年”解析,设置为DMY就按照“日-月-年”解析,设置为YMD就按照“年-月-日”解析。
日期的文本输入需要加单引号包围,语法如下:
type [ ( p ) ] ‘value’
可选的精度声明中的p是一个整数,表示在秒域中小数部分的位数
--创建表。
openGauss=# CREATE TABLE date_type_tab(coll date);
--插入数据。
openGauss=# INSERT INTO date_type_tab VALUES (date '12-10-2022');
--查看数据。
openGauss=# SELECT * FROM date_type_tab;
coll
---------------------
2022-12-10 00:00:00
(1 row)
--查看日期格式。
openGauss=# SHOW datestyle;
DateStyle
-----------
ISO, MDY
(1 row)
--设置日期格式。
openGauss=# SET datestyle='YMD';
SET
--插入数据。
openGauss=# INSERT INTO date_type_tab VALUES(date '2022-12-11');
--查看数据。
openGauss=# SELECT * FROM date_type_tab;
coll
---------------------
2022-12-10 00:00:00
2022-12-11 00:00:00
(2 rows)
--删除表。
openGauss=# DROP TABLE date_type_tab;
✨ 5.2 时间段输入
reltime的输入方式可以采用任何合法的时间段文本格式,包括数字形式(含负数和小数)及时间形式,其中时间形式的输入支持SQL标准格式、ISO-8601格式、POSTGRES格式等。另外,文本输入需要加单引号。
--创建表。
openGauss=# CREATE TABLE reltime_type_tab(col1 character(30), col2 reltime);
--插入数据。
openGauss=# INSERT INTO reltime_type_tab VALUES ('90', '90');
openGauss=# INSERT INTO reltime_type_tab VALUES ('-366', '-366');
openGauss=# INSERT INTO reltime_type_tab VALUES ('1975.25', '1975.25');
openGauss=# INSERT INTO reltime_type_tab VALUES ('-2 YEARS +5 MONTHS 10 DAYS', '-2 YEARS +5 MONTHS 10 DAYS');
openGauss=# INSERT INTO reltime_type_tab VALUES ('30 DAYS 12:00:00', '30 DAYS 12:00:00');
openGauss=# INSERT INTO reltime_type_tab VALUES ('P-1.1Y10M', 'P-1.1Y10M');
--查看数据。
openGauss=# SELECT * FROM reltime_type_tab;
col1 | col2
--------------------------------+-------------------------------------
90 | 3 mons
-366 | -1 years -18:00:00
1975.25 | 5 years 4 mons 29 days
-2 YEARS +5 MONTHS 10 DAYS | -1 years -6 mons -25 days -06:00:00
30 DAYS 12:00:00 | 1 mon 12:00:00
P-1.1Y10M | -3 mons -5 days -06:00:00
--删除表。
openGauss=# DROP TABLE reltime_type_tab;
📣 6. 几何类型
| 名称 | 存储空间 | 说明 | 表现形式 |
|---|---|---|---|
| point | 16字节 | 平面中的点 | (x,y) |
| lseg | 32字节 | (有限)线段 | ((x1,y1),(x2,y2)) |
| box | 32字节 | 矩形 | ((x1,y1),(x2,y2)) |
| path | 16+16n字节 | 闭合路径(与多边形类似) | ((x1,y1),…) |
| path | 16+16n字节 | 开放路径 | [(x1,y1),…] |
| polygon | 40+16n字节 | 多边形(与闭合路径相似) | ((x1,y1),…) |
| circle | 24 字节 | 圆 | <(x,y),r> (圆心和半径) |
openGauss提供了一系列的函数和操作符用来进行各种几何计算,如拉伸、转换、旋转、计算相交等。
📣 7. 网络地址类型
openGauss提供用于存储IPv4、IPv6、MAC地址的数据类型。
用这些数据类型存储网络地址比用纯文本类型好,因为这些类型提供输入错误检查和特殊的操作和功能。
| 名称 | 存储空间 | 说明 | 表现形式 |
|---|---|---|---|
| cidr | 7或19字节 | IPv4或IPv6网络 | 192.168.0.0/24 |
| inet | 7或19字节 | IPv4或IPv6主机和网络 | address/y,address表示IPv4或者IPv6地址 y是子网掩码的二进制位数 |
| macaddr | 6字节 | MAC地址 | ‘08:00:2b:01:02:03’ |
📣 8. 位串类型
位串就是一串1和0的字符串。它们可以用于存储位掩码。
openGauss支持两种位串类型:bit(n)和bit varying(n),这里的n是一个正整数。
bit类型的数据必须准确匹配长度n,如果存储短或者长的数据都会报错。
bit varying类型的数据是最长为n的变长类型,超过n的类型会被拒绝。一个没有长度的bit等效于bit(1),
没有长度的bit varying表示没有长度限制。
📣 9. 文本搜索类型
openGauss提供了两种数据类型用于支持全文检索。tsvector类型表示为文本搜索优化的文件格式,tsquery类型表示文本查询。
tsvector类型表示一个检索单元,通常是一个数据库表中一行的文本字段或者这些字段的组合,tsvector类型的值是一个标准词位的有序列表,标准词位就是把同一个词的变型体都标准化成相同的,在输入的同时会自动排序和消除重复。to_tsvector函数通常用于解析和标准化文档字符串。
✨ 9.1 tsvector
tsvector的值是唯一分词的分类列表,把一句话的词格式化为不同的词条,
在进行分词处理的时候tsvector会自动去掉分词中重复的词条,按照一定的顺序录入。如:
openGauss=# SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector;
tsvector
----------------------------------------------------
'a' 'and' 'ate' 'cat' 'fat' 'mat' 'on' 'rat' 'sat'
✨ 9.2 tsquery
tsquery类型表示一个检索条件,存储用于检索的词汇,并且使用布尔操作符&(AND),|(OR)和!(NOT)来组合他们,括号用来强调操作符的分组。to_tsquery函数及plainto_tsquery函数会将单词转换为tsquery类型前进行规范化处理。
openGauss=# SELECT 'fat & rat'::tsquery;
tsquery
---------------
'fat' & 'rat'
(1 row)
openGauss=# SELECT 'fat & (rat | cat)'::tsquery;
tsquery
---------------------------
'fat' & ( 'rat' | 'cat' )
(1 row)
openGauss=# SELECT 'fat & rat & ! cat'::tsquery;
tsquery
------------------------
'fat' & 'rat' & !'cat'
(1 row)
📣 10. UUID数据类型
UUID数据类型用来存储RFC 4122,ISO/IEF 9834-8:2005以及相关标准定义的通用唯一标识符(UUID)。这个标识符是一个由算法产生的128位标识符,确保它不可能使用相同算法在已知的模块中产生的相同标识符。
UUID是一个小写十六进制数字的序列,由分字符分成几组,一组8位数字+三组4位数字+一组12位数字,总共32个数字代表128位,标准的UUID示例如下:
a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11
openGauss同样支持以其他方式输入:大写字母和数字、由花括号包围的标准格式、省略部分或所有连字符、在任意一组四位数字之后加一个连字符。示例如下:
A0EEBC99-9C0B-4EF8-BB6D-6BB9BD380A11
{a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11}
a0eebc999c0b4ef8bb6d6bb9bd380a11
a0ee-bc99-9c0b-4ef8-bb6d-6bb9-bd38-0a11
📣 11. JSON/JSONB类型
JSON(JavaScript Object Notation)数据,可以是单独的一个标量,也可以是一个数组,也可以是一个键值对象,其中数组和对象可以统称容器(container):
标量(scalar):单一的数字、bool、string、null都可以叫做标量。
数组(array):[]结构,里面存放的元素可以是任意类型的JSON,并且不要求数组内所有元素都是同一类型。
对象(object):{}结构,存储key:value的键值对,其键只能是用“”包裹起来的字符串,值可以是任意类型的JSON,对于重复的键,按最后一个键值对为准。
openGauss内存在两种数据类型JSON和JSONB,可以用来存储JSON数据。其中JSON是对输入的字符串的完整拷贝,使用时再去解析,所以它会保留输入的空格、重复键以及顺序等;JSONB解析输入后保存的二进制,它在解析时会删除语义无关的细节和重复的键,对键值也会进行排序,使用时不用再次解析。
因此可以发现,两者其实都是JSON,它们接受相同的字符串作为输入。它们实际的主要差别是效率。JSON数据类型存储输入文本的精确拷贝,处理函数必须在每个执行上重新解析; 而JSONB数据以分解的二进制格式存储, 这使得它由于添加了转换机制而在输入上稍微慢些,但是在处理上明显更快, 因为不需要重新解析。同时由于JSONB类型存在解析后的格式归一化等操作,同等的语义下只会有一种格式,因此可以更好更强大的支持很多其他额外的操作,比如按照一定的规则进行大小比较等。JSONB也支持索引,这也是一个明显的优势。
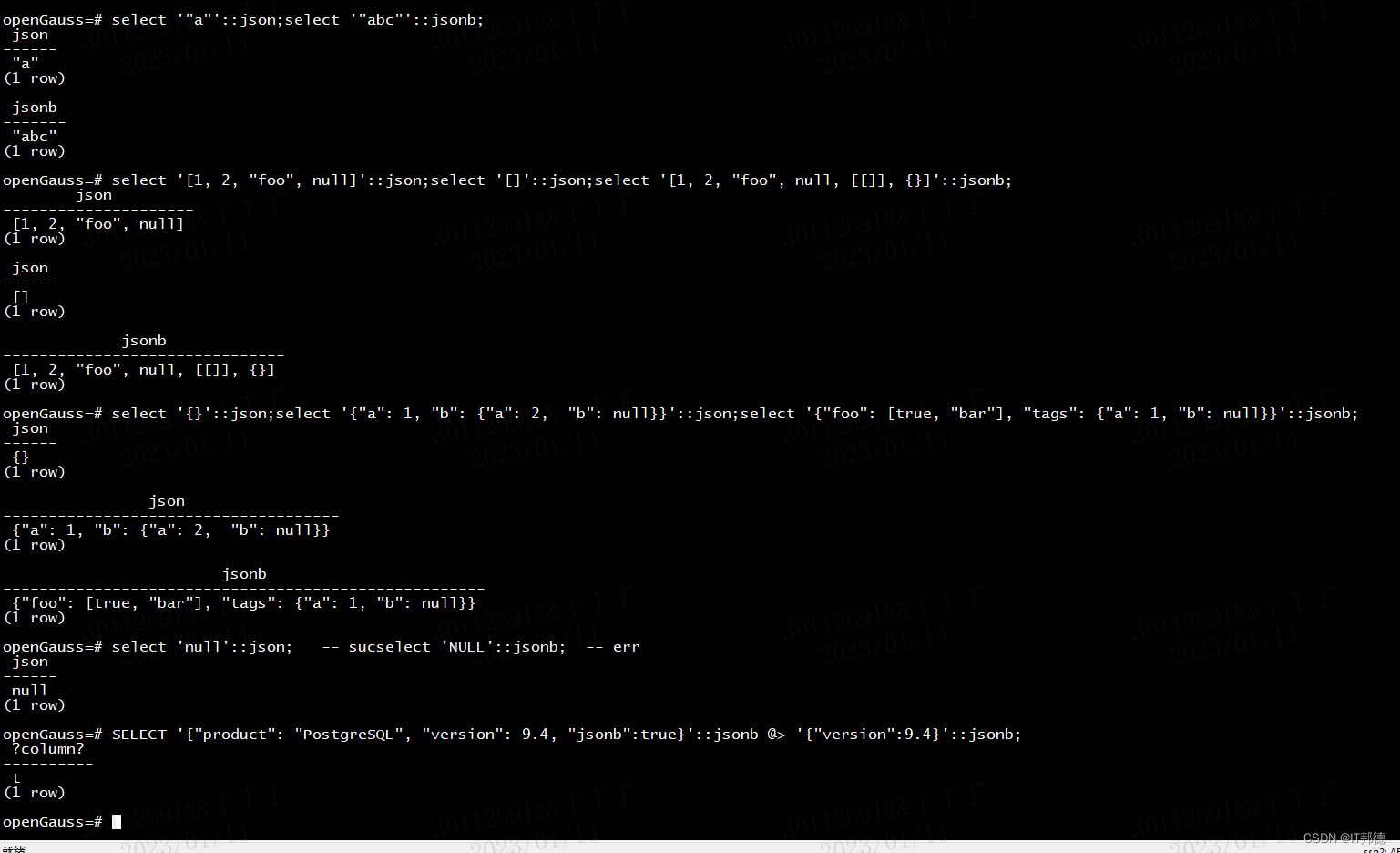
输入必须是一个符合JSON数据格式的字符串,此字符串用单引号’’声明。
null(null-json):仅null,全小写。
select 'null'::json; -- sucselect 'NULL'::jsonb; -- err
数字(num-json):正负整数、小数、0,支持科学计数法。
select '1'::json;select '-1.5'::json;select '-1.5e-5'::jsonb, '-1.5e+2'::jsonb;select '001'::json, '+15'::json, 'NaN'::json;
布尔(bool-json):仅true、false,全小写。
select 'true'::json;select 'false'::jsonb;
字符串(str-json):必须是加双引号的字符串。
select '"a"'::json;select '"abc"'::jsonb;
数组(array-json):使用中括号[]包裹,满足数组书写条件。数组内元素类型可以是任意合法的JSON,且不要求类型一致。
select '[1, 2, "foo", null]'::json;select '[]'::json;select '[1, 2, "foo", null, [[]], {}]'::jsonb;
对象(object-json):使用大括号{}包裹,键必须是满足JSON字符串规则的字符串,值可以是任意合法的JSON。
select '{}'::json;select '{"a": 1, "b": {"a": 2, "b": null}}'::json;select '{"foo": [true, "bar"], "tags": {"a": 1, "b": null}}'::jsonb;
📣 12. HLL数据类型
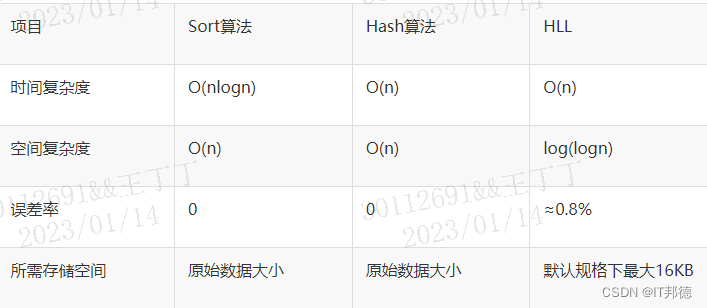
HLL(HyperLoglog)是统计数据集中唯一值个数的高效近似算法。它有着计算速度快,节省空间的特点,不需要直接存储集合本身,而是存储一种名为HLL的数据结构。每当有新数据加入进行统计时,只需要把数据经过哈希计算并插入到HLL中,最后根据HLL就可以得到结果。
-- 创建hll类型的表,不指定入参
openGauss=# create table t1 (id integer, set hll);
openGauss=# \d t1
Table "public.t1"
Column | Type | Modifiers
--------+---------+-----------
c1 | integer |
c2 | hll |
-- 创建hll类型的表,指定前两个入参,后两个采用默认值
openGauss=# create table t2 (id integer, set hll(12,4));
Table "public.t2"
Column | Type | Modifiers
--------+----------------+-----------
c1 | integer |
c2 | hll(12,4,12,0) |
--创建hll类型的表,指定第三个入参,其余采用默认值
openGauss=# create table t3(id int, set hll(-1,-1,8,-1));
openGauss=# \d t3
Table "public.t3"
Column | Type | Modifiers
--------+----------------+-----------
c1 | integer |
c2 | hll(14,10,8,0) |
--创建hll类型的表,指定入参不合法报错
openGauss=# create table t4(id int, set hll(5,-1));
ERROR: log2m = 5 is out of range, it should be in range 10 to 16, or set -1 as default
📣 13. 范围类型
范围类型是表达某种元素类型(称为范围的_subtype_)的一个值的范围的数据类型。例如,timestamp的范围可以被用来表达一个会议室被保留的时间范围。在这种情况下,数据类型是tsrange(“timestamp range”的简写)而timestamp是 subtype。subtype 必须具有一种总体的顺序,这样对于元素值是在一个范围值之内、之前或之后就是界线清楚的。
范围类型非常有用,因为它们可以表达一种单一范围值中的多个元素值,并且可以很清晰地表达诸如范围重叠等概念。用于时间安排的时间和日期范围是最清晰的例子;但是价格范围、一种仪器的量程等等也都有用。
📣 14.XML类型
openGauss支持XML类型,使用示例如下。
openGauss= CREATE TABLE xmltest ( id int, data xml );
openGauss= INSERT INTO xmltest VALUES (1, 'one');
openGauss= INSERT INTO xmltest VALUES (2, 'two');
openGauss= SELECT * FROM xmltest ORDER BY 1;
id | data
----+--------------------
1 | one
2 | two
(2 rows)
openGauss= SELECT xmlconcat('', NULL, '');
xmlconcat
(1 row)
openGauss= SELECT xmlconcat('', NULL, '');
xmlconcat
(1 row)