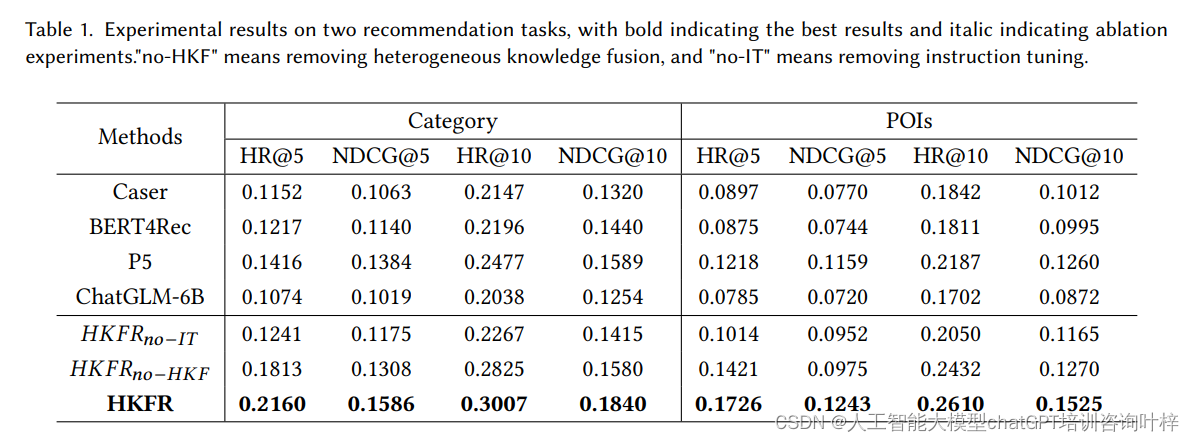
RAG
- 参考地址
- 语义模型地址
- 选择该模型
- 使用方法
- 方法二
- 安装方法
- 下载模型到本地
- 材料
- 材料处理
- 语义分割
- 计算得分
- 根据得分 分割文本
- 构建向量数据库
- 问答匹配
- 问答整合
参考地址
RAG简单教程
分割策略
语义模型地址
hf

选择该模型
gte
使用方法
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
input_texts = [
"中国的首都是哪里",
"你喜欢去哪里旅游",
"北京",
"今天中午吃什么"
]
tokenizer = AutoTokenizer.from_pretrained("thenlper/gte-large-zh")
model = AutoModel.from_pretrained("thenlper/gte-large-zh")
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = outputs.last_hidden_state[:, 0]
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
方法二
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
sentences = ['That is a happy person', 'That is a very happy person']
model = SentenceTransformer('thenlper/gte-large-zh')
embeddings = model.encode(sentences)
print(cos_sim(embeddings[0], embeddings[1]))
安装方法
Sentence Transformers 是一个基于 PyTorch 的开源库,用于计算句子、段落或文档之间的语义相似度。它提供了多种预训练模型,可以用于各种自然语言处理任务,如文本分类、信息检索、文本聚类等。
以下是安装 Sentence Transformers 的基本步骤:
- 安装Python环境:首先确保你的系统中安装了Python。Sentence Transformers 要求Python 3.6或更高版本。
- 安装PyTorch:Sentence Transformers 依赖于PyTorch。你可以通过访问PyTorch的官方网站获取适合你系统的安装命令。PyTorch官网会根据你的系统和CUDA版本(如果你使用GPU)提供相应的安装指令。
- 使用pip安装Sentence Transformers:在安装了PyTorch之后,你可以使用pip来安装Sentence Transformers。打开命令行(终端)并输入以下命令:
pip install -U sentence-transformers
-U参数确保pip更新到最新版本。
4. 验证安装:安装完成后,你可以通过运行一个简单的示例脚本来验证安装是否成功。例如,使用预训练的模型来计算两个句子之间的相似度:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
sentence1 = 'The cat sits on the mat'
sentence2 = 'The cat is sitting on the carpet'
embedding1 = model.encode(sentence1)
embedding2 = model.encode(sentence2)
cos_sim = util.pytorch_cos_sim(embedding1, embedding2)
print("Cosine-Similarity:", cos_sim)
这段代码会下载预训练的模型并计算两个句子之间的余弦相似度。
6. 额外的依赖:Sentence Transformers 库可能还需要其他依赖,如scikit-learn、numpy等。如果运行示例代码时出现错误,提示缺少某个库,可以使用pip来安装它们。
7. 更新pip、setuptools和wheel:在安装新的Python包之前,最好更新pip、setuptools和wheel,以确保你安装的是最新版本的库。
pip install --upgrade pip setuptools wheel
请根据你的操作系统和Python环境调整上述步骤。如果在安装过程中遇到任何问题,可以查看Sentence Transformers的官方文档或GitHub页面以获取帮助。
下载模型到本地
下载方法参考
当然可以直接点击多次下载
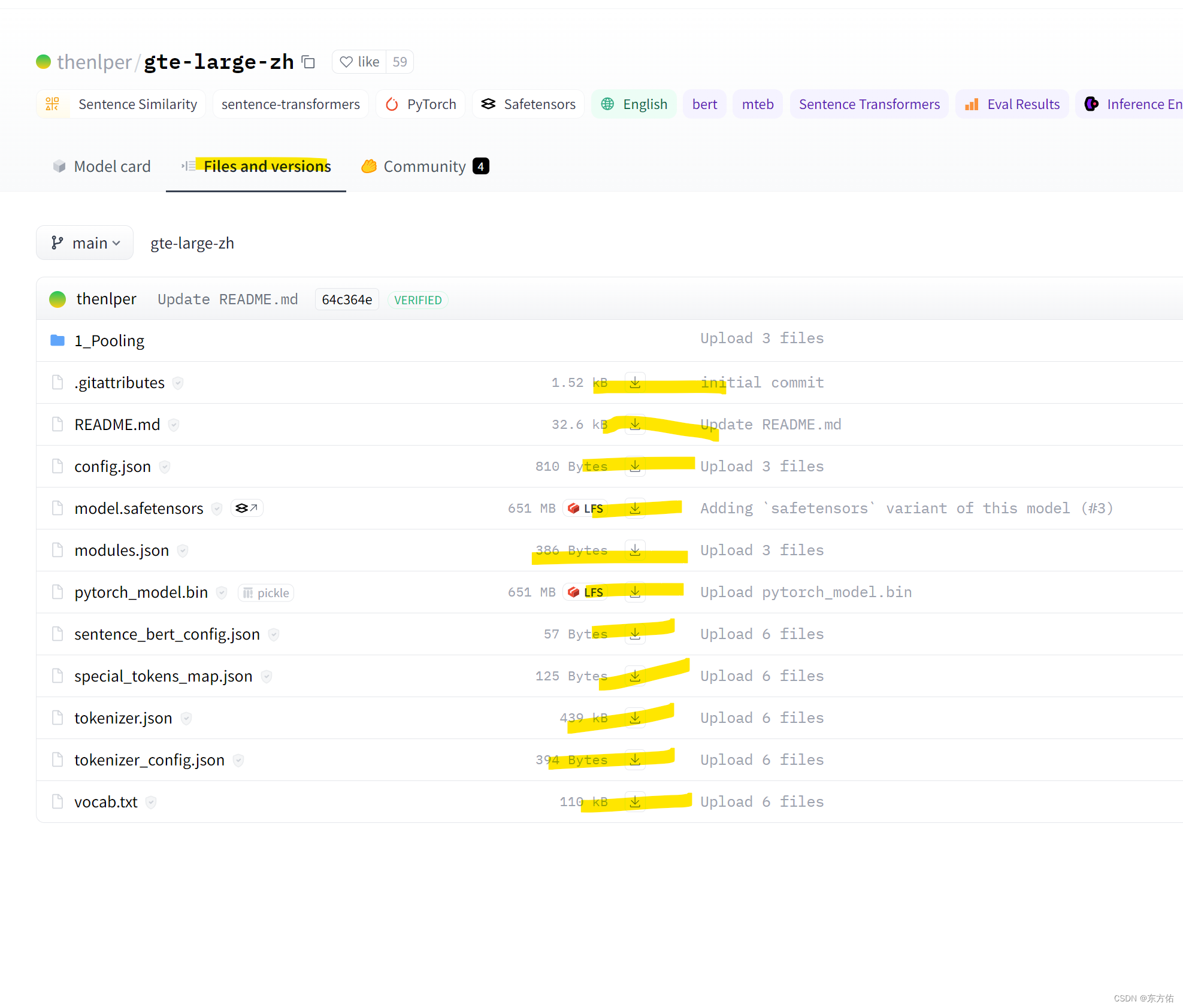
可以从这里下载模型文件
材料
随便下一个压缩包例子
材料处理
from glob import glob
import pandas as pd
from tqdm import tqdm
texts_path=glob("F:/rag/novel5/*.txt")
total_dict=[]
for one in tqdm(texts_path[:10]):
with open(one,'r',encoding='utf-8') as f:
one_data=f.read()
new_data=[]
for i in one_data.split():
if i.count("。")>1:
new_data+=i.split("。")
else:
new_data.append(i)
total_dict.append({one:new_data})
pd.to_pickle(total_dict,"total_data.pkl")
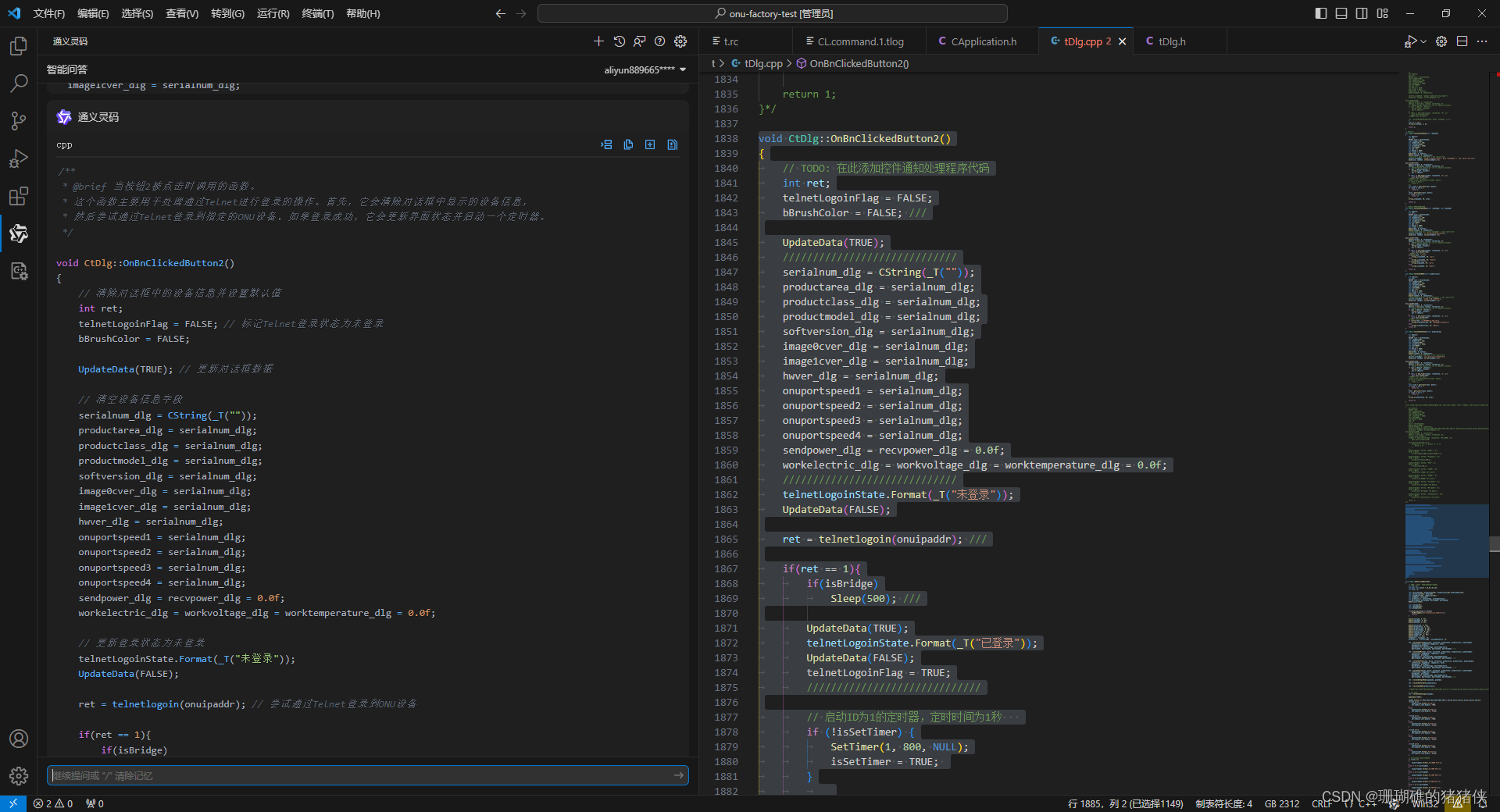
语义分割
计算得分
import pandas as pd
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
from tqdm import tqdm
import torch
# sentences = ['That is a happy person', 'That is a very happy person']
model = SentenceTransformer('F:/rag/gte_large_zh')
model.to("cuda")
data = pd.read_pickle("total_data.pkl")
batch_size = 3
total_list= []
for one in tqdm(data):
for name, texts in one.items():
texts=[i for i in texts if len(i)>1]
one_dict = {name: {"data": [], "score": []}}
score_list=[]
for i in tqdm(range(0, len(texts) - 1, batch_size)):
j = i + batch_size
sentences = texts[i:j +1]
embeddings0 = model.encode(["。".join(sentences[:-1])])
embeddings1 = model.encode(["。".join(sentences[1:])])
out=cos_sim(embeddings0,embeddings1)
score=out.tolist()[0]
del out
del embeddings0
del embeddings1
del sentences
torch.cuda.empty_cache()
score_list+=score
one_dict[name]["score"]=score_list
one_dict[name]["data"]=texts
total_list.append(one_dict)
pd.to_pickle( total_list,"total_score_one_data.pkl")
根据得分 分割文本
import pandas as pd
import numpy as np
from tqdm import tqdm
batch_size = 3
data = pd.read_pickle("total_score_one_data.pkl")
total_list=[]
for one in data:
data_list = []
for name, two in one.items():
score = two["score"]
text = two["data"]
for ii,i in tqdm(enumerate(range(0, len(text) - 1, batch_size))):
j = i + batch_size
if ii==0:
sentences = text[i:j+1 ]
else:
sentences = text[i+1:j + 1]
data_list+=sentences
if score[ii] > 0.9:
data_list += ["#chunk#"]
total_list.append(data_list)
pd.to_pickle(total_list,"total_list.pkl")
构建向量数据库
import pandas as pd
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
from tqdm import tqdm
model = SentenceTransformer('F:/rag/gte_large_zh')
model.to("cuda")
batch_size=1000
data=pd.read_pickle("total_list.pkl")
total_list=[]
for one in tqdm(data):
for name,two in one.items():
data_list=[]
total="。".join(two).split("#chunk#")
for t in tqdm(range(0,len(total),batch_size)):
batch=total[t:t+batch_size]
embeddings = model.encode(batch)
data_list+=embeddings.tolist()
total_list.append({name:{"em":data_list,"data":total}})
pd.to_pickle(total_list,"embedding.pkl")
问答匹配
import pandas as pd
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
import numpy as np
# from tqdm import tqdm
model = SentenceTransformer('F:/rag/gte_large_zh')
model.to("cuda")
batch_size=1000
data=pd.read_pickle("embedding.pkl")
text="修仙小说"
text_em=model.encode(text)
total_list=[]
for one in data:
for name,data_em in one.items():
sim=cos_sim(text_em,data_em["em"])
score,ids=sim[0].topk(5)
top_text=np.array(data_em["data"])[ids.numpy()]
res=pd.DataFrame({"name":[name]*top_text.size,"score":score.numpy().tolist(),"text":top_text.tolist(),"ids":ids.numpy().tolist()})
total_list.append(res)
result=pd.concat(total_list)
result=result.sort_values("score",ascending=False)
result=str(result[["name","score","text"]].values[:3])
prompt="问题:{},参考:{} 答案:".format(text,result)
问答整合
rwkv 使用参考