Linux网络抓包工具tcpdump是如何实现抓包的,在哪个位置抓包的?
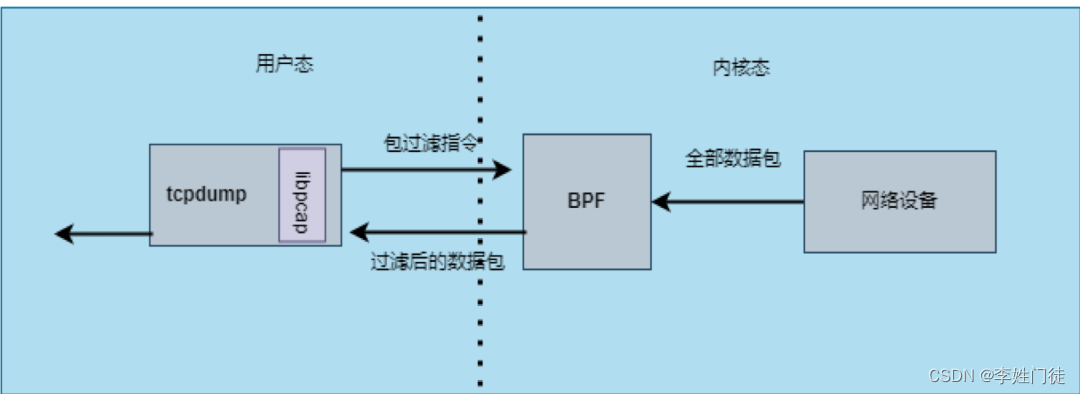
- 1. tcpdump抓包架构
- 2. BPF介绍
- 3. 从内核层面看tcpdump抓包流程
- 3.1. 创建socket套接字
- 3.2. 挂载BPF程序
- 4. 网络收包抓取
- 5. 网络发包抓取
- 6. 疑问和思考
- 6.1 tcpdump抓包跟网卡、内核之间的顺序是怎么样的?
- 6.2 tcpdump抓包分析到服务端响应ping延迟,怎么判断是是客户端到服务端的传输过程慢还是服务端的内核处理慢?
- 7. 参考文档
随着G行架构从集中式体系向分布式式体系转型,行内系统服务快速增多,不同的服务短期内需要在集中式体系、分布式体系之间互相调用,调用链复杂,网络通讯相关问题时有发生。系统管理员在排查网络问题时就用到一款网络抓包工具tcpdump,该工具可以将网络中传送的数据包完全截获下来进行分析,能有效的排查复杂环境的网络问题。本文将从原理的角度分析tcpdump在Linux系统的实现。
主要是希望能够分析实现原理,以协助判断tcpdump抓的是网卡的包,还是经过内核处理后的包?对于分析服务器处理网络包过程有很大帮助。
1. tcpdump抓包架构
tcpdump由C语言开发,主要功能通过libpcap库实现,而libpcap是linux平台下的一个网络数据包捕获功能包, 通过内核BPF技术实现数据过滤功能。tcpdump使用BPF虚拟机的指令集定义过滤器表达式,然后传递给内核,并由解释器执行,这使得包过滤可以在内核中进行,避免了向用户态进程复制全部数据包,从而提升数据包的过滤性能。tcpdump将包过滤指令注入到内核,返回按条件过滤的数据包,提供多种输出功能将抓取的报文格式化处理能力。
tcpdump的包过滤指令由BPF代码实现,通过对libpcap库的调用可以把一个输入输出的逻辑表达式变为BPF代码,实现在用户输入的命令行和BPF代码之间的转换。tcpdump 程序支持使用 -d参数来 dump 出过滤规则转化后的BPF指令字节码。
2. BPF介绍
BPF(Berkeley Packet Filter ),中文翻译为伯克利包过滤器,是类 Unix 系统上数据链路层的一种原始接口,提供一种网络数据包过滤方法。随着技术的发展,人们在BPF的基础上又提出了eBPF(extended BPF)。经过重新设计,eBPF 演进为一个通用执行引擎,在不更改内核代码的前提下,实时获取和修改操作系统的行为,可基于此开发性能分析工具、软件定义网络等诸多场景,而原来的BPF则称为cBPF(classic BPF)。
现在,Linux 内核只运行eBPF,内核会将加载的cBPF字节码透明地转换成 eBPF再执行。eBPF新的设计针对现代硬件进行了优化,eBPF 生成的指令集比旧的 BPF 解释器生成的机器码执行得更快。扩展版本也增加了虚拟机中的寄存器数量,将原有的2个32位寄存器增加到10个64位寄存器。
eBPF 程序需要挂载到某个内核路径(挂载点)才能被执行,常见的挂载点有:系统调用,内核函数进入/退出,内核跟踪点,网络数据包等等,根据挂载点功能的不同,可以分为以下四类,tcpdump挂载点即为第二类:
- 性能跟踪(kprobes/uprobes/tracepoints)
- 网络(socket/xdp)
- 容器(cgroup)
- 安全(seccomp)
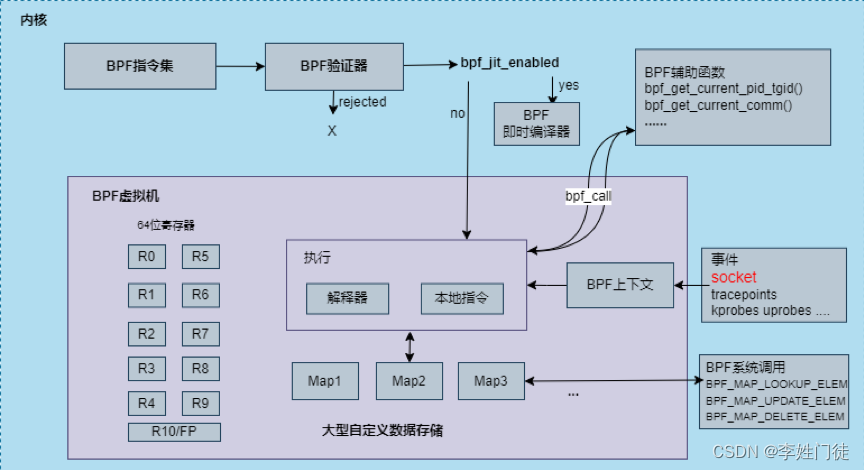
cpdump使用的包过滤指令即为cBPF,内核将提交来的cBPF字节码转化成eBPF代码加载进BPF虚拟机中,使用系统调用函数setsockopt()将BPF 程序挂载在 socket套接字上,进而过滤数据包,而BPF代码是则由内核调用BPF运行函数__bpf_prog_run()来执行。
3. 从内核层面看tcpdump抓包流程
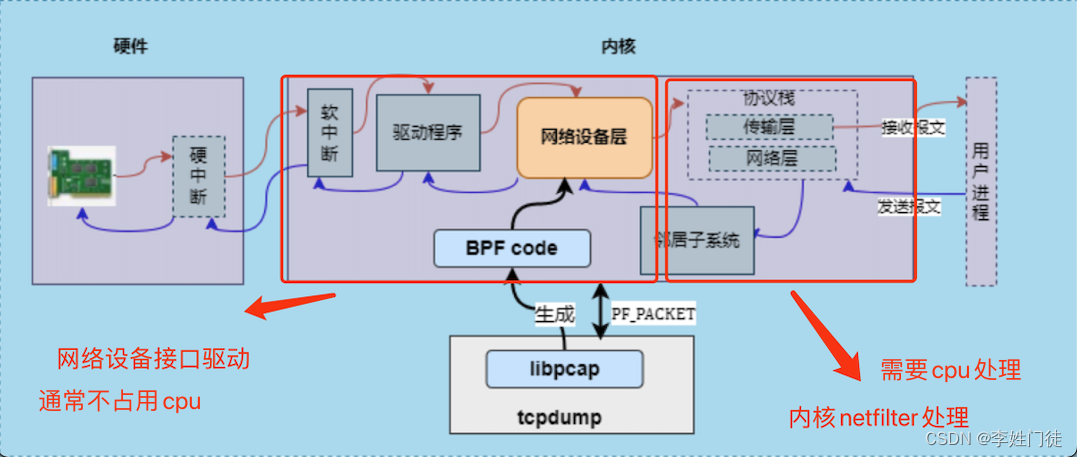
众所周知,应用在接收报文的时候,硬件的硬中断首先触发内核的 软中断 ,通过 内核驱动程序 进入 网络设备层 进行数据包的处理,然后数据包进入 协议栈 的网络层和传输层,最后被用户进程接收。
而应用在发送报文时,首先经过内核的 协议层 ,由邻居子系统实现L3层ip地址转化为L2层mac地址,然后进入 网络设备层 ,数据包处理完成后,经 驱动程序 流转,最后由 硬件 将报文发出。
tcpdump为了能抓取数据包,首先需要创建socket套接字,用于在应用系统接收和发送报文时获取抓取的数据包,然后将过滤条件也就是对应的BPF程序注入到内核网络设备层,获取过滤后的数据包后再进行格式化处理。
在
说明
在生产中常见的,如果单个cpu核心被持续打满,会影响内核将网络包从队列中取出,并存放到协议栈,从而导致机器响应包延迟
在硬件接收到网络包,触发硬中断后,将相关网络包存放到内部队列,队列满后出发软中断通知内核接受相关的流量包,内核接收流量包后,对应的队列清空以继续接收后续的流量包,这个过程占用的cpu很少。
内核接收到软中断信号后,会调用cpu资源以接收相关的流量包,放到协议栈并进行后续的处理。如果软中断很频繁,内核就需要频繁的调用cpu响应,会很需要消耗cpu资源。特别是如果内核响应软中断的cpu绑定到固定某个cpu核时,表现更为明显
3.1. 创建socket套接字
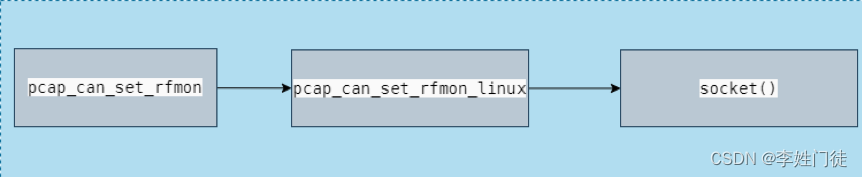
tcpdump首先通过libpcap库,调用socket()函数创建PF_PACKET套接字,该套接字提供L2层抓包分析能力,所有的底层L2包都会给到PF_PACKET 模块的回调处理函数即下文的网络收包和发包都用到的内核函数packet_rcv()函数,通过该函数将数据包写入到缓存队列,libpcap库使用系统调用函数recvfrom ()复制一份数据给tcpdump。
3.2. 挂载BPF程序
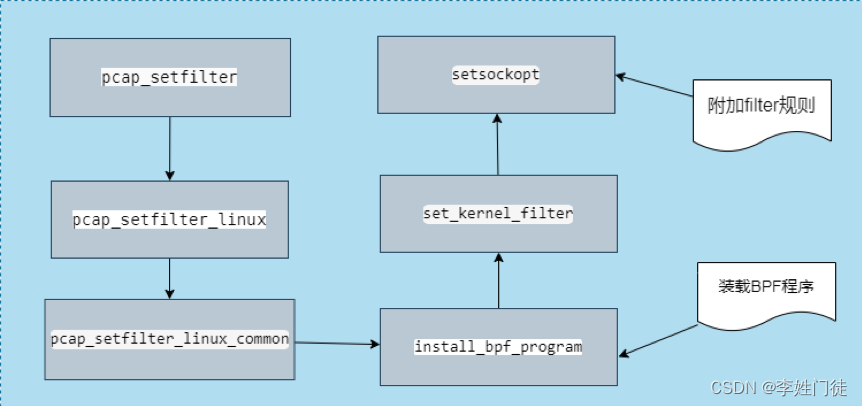
tcpdump使用libpcap库的pcap_compile()函数将用户制定的过滤策略转换为BPF代码,然后使用pcap_setfilter()函数调用install_bpf_program()函数装载BPF程序,install_bpf_program()函数调用系统调用函数setsockopt(),设置SO_ATTACH_FILTER参数将BPF程序下发给内核底层,将规则注入到内核,设置过滤器,从而让规则生效。
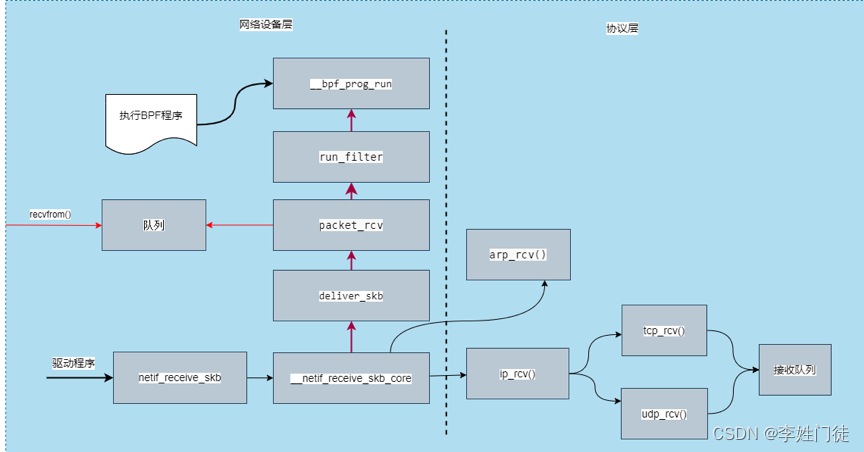
4. 网络收包抓取
应用接收报文时,在网络设备层,驱动程序首先调用内核函数netif_receive_skb(),通过deliver_skb()调用回调函数packet_rcv(),并使用BPF运行函数__bpf_prog_run(),来执行BPF程序过滤数据包,然后将数据包存入队列,最终复制数据包给tcpdump。而应用接收数据包则根据包的协议,选择udp或者tcp将报文送到用户进程。
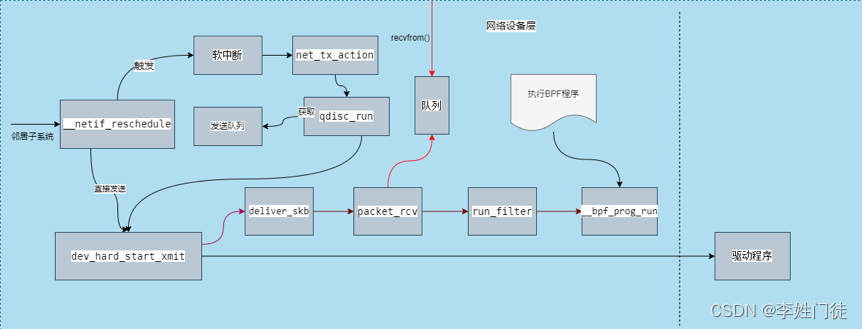
5. 网络发包抓取
应用在发送报文时,首先通过邻居子系统进入网络设备层,然后调用内核函数dev_hard_start_xmit(),该函数同样使用网络收包流程中使用的deliver_skb()函数调用回调函数packet_rcv(),并通过调用BPF运行函数__bpf_prog_run(),来执行BPF程序过滤数据包,然后将数据包存入队列,最终复制数据包给tcpdump。而应用发送数据包则通过驱动程序发送出去。
6. 疑问和思考
6.1 tcpdump抓包跟网卡、内核之间的顺序是怎么样的?
TCPDump实际上是通过libpcap库来实现的,它可以在网卡和内核之间获取数据包。
当你运行tcpdump时,它会使用libpcap库来打开一个网络接口,这样就可以捕获该接口上的数据包。libpcap库通过操作系统提供的类似于BPF(Berkeley Packet Filter)的机制来实现这一点。这种机制允许libpcap指定一组过滤规则,以便仅捕获符合这些规则的数据包。一旦数据包被捕获,libpcap会将其传递给TCPDump进行进一步处理,最终以用户友好的方式呈现给用户。
所以,tcpdump获取的数据包实际上是在 网卡和内核之间 获取的,它通过libpcap库利用操作系统提供的网络抓包机制来实现。
6.2 tcpdump抓包分析到服务端响应ping延迟,怎么判断是是客户端到服务端的传输过程慢还是服务端的内核处理慢?
通过6.1的问题知道了tcpdump是在网卡和内核之间的,通过tcpudump抓包
- 收包还没有经过内核处理
- 发包需要内核协议栈处理后,经过tcpdump到达网卡
因此只需要在服务端和客户端抓包
- 对比相同一个包,在客户端发出后和服务端接收到的时间查,这个是客户端和服务端网卡之间的流量传输过程
- 在对比,服务端抓到的包中,收发2个包之间的时间差,这个时间差就是服务端收到包后的响应时间差
- 对比这两个时间差,就能知道时间主要消耗在哪个层面
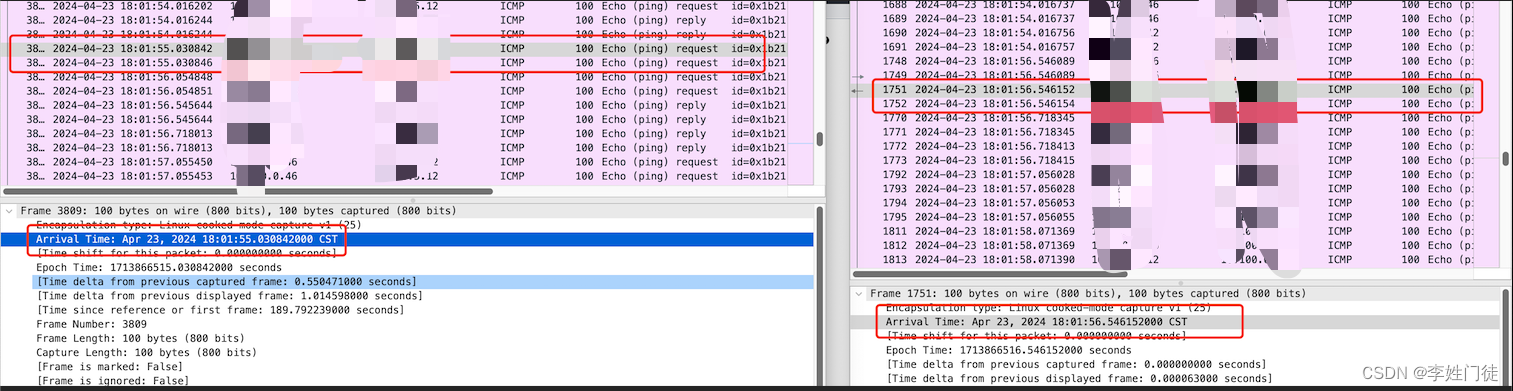
如下图可以获知,客户端到服务端之间传输耗时1s,但是服务端处理很快
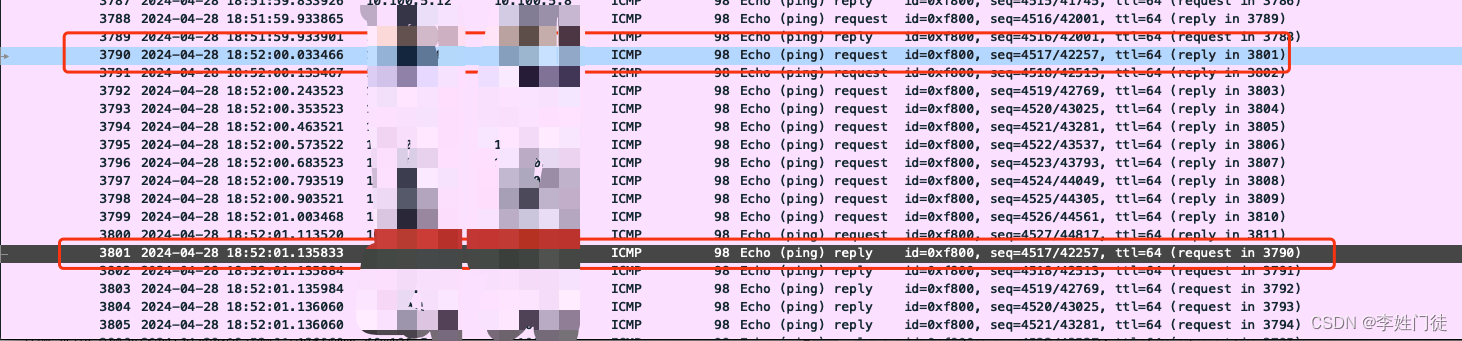
如下图可以获知,服务端接收到网络包后处理时间耗时1s,由于只是做简单的ping命令,因此主要的耗时消耗在内核上,还需要配合排查处理内核中断的cpu使用率是否很高,才能进一步分析问题原因。
7. 参考文档
暂无