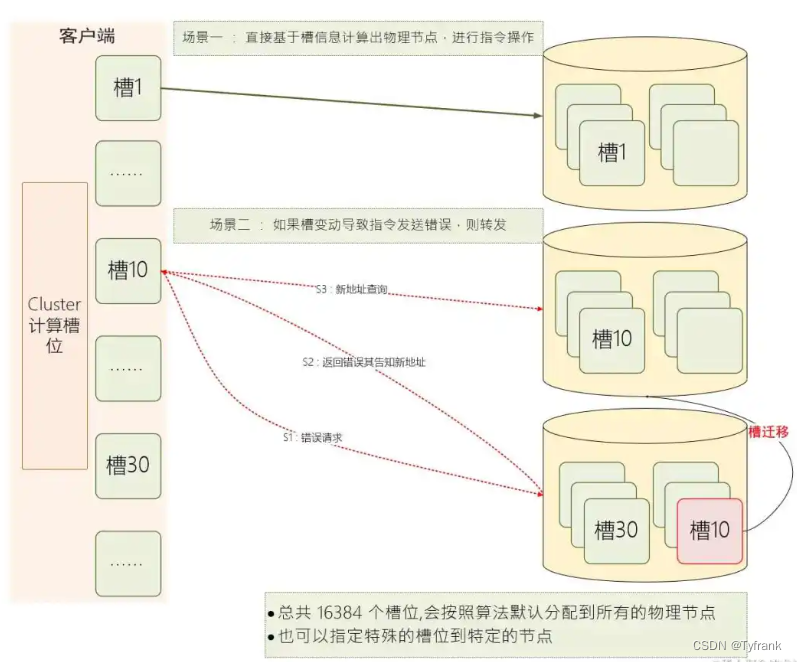
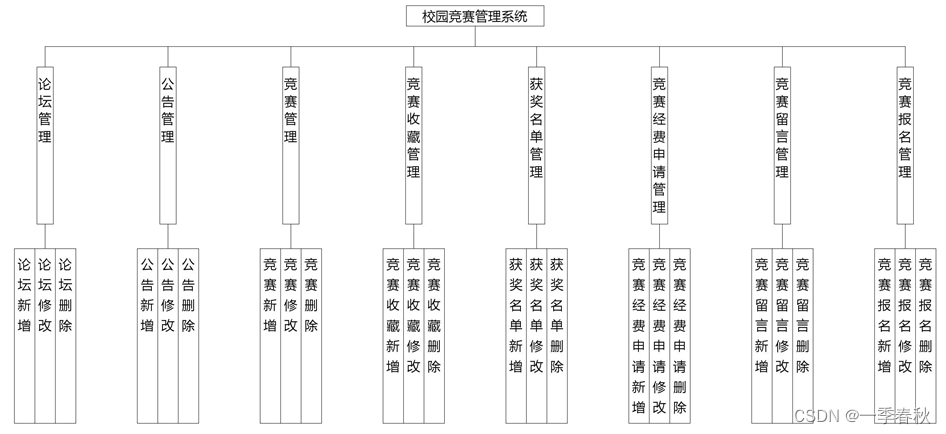
VoxAtnNet:三维点云卷积神经网络
- 摘要
- Introduction
- Proposed VoxAtnNet 3D Face PAD
- 3D face point cloud presentation attack Dataset (3D-PCPA)
VoxAtnNet: A 3D Point Clouds Convolutional Neural Network for
摘要
面部生物识别是智能手机确保可靠和可信任认证的重要组件。然而,面部生物识别系统容易受到呈现攻击(PAs)的影响,且随着更复杂的呈现攻击工具,如3D硅胶面部面具的可用性,攻击者可以轻易欺骗面部识别系统。
在这项工作中,作者提出了一种基于智能手机前置摄像头捕获的3D点云的新型呈现攻击检测(PAD)算法,以检测呈现攻击。
所提出的PAD算法VoxAtnNet处理3D点云以获得 Voxel 化以保留空间结构。然后,使用新型卷积注意力网络对 Voxel 化的3D样本进行训练,以在智能手机上检测PAs。
在由真实样本和两种不同的3D PAs(3D硅胶面部面具和包裹式照片面具)组成的新构建的3D面部点云数据集上进行了大量实验,共3480个样本。
将所提出的方法的性能与现有方法进行了比较,以使用三种不同的评估协议来基准检测性能。实验结果表明,所提出的方法在检测已知和未知面部呈现攻击方面都表现出改进的性能。
Introduction
面部生物识别是智能手机应用中需要安全可靠认证的主要构建块。智能手机应用包括解锁手机、下载应用程序、银行交易和金融应用程序。面部生物识别的广泛采用可以归因于其在智能手机应用中所需的高度精确性能和可用性。面部生物识别的普及导致截至2019年部署了超过9600万部智能手机,预计到2024年将增长到8亿部智能手机[1]。
智能手机上面部识别系统的广泛部署启用了一些应用,但同时也遭遇了一系列呈现(或欺骗)攻击。呈现攻击(PAs)的目标是呈现合法用户的面部工件(或呈现攻击工具(PAI))以未经授权访问智能手机或智能手机应用程序。PAI可以使用不同类型的工件材料生成,例如打印攻击、电子显示攻击、包裹攻击(将打印照片包裹在脸上)和3D硅胶面部口罩攻击。一位消费者权益倡导者最近的分析[2]测试了2019年发布的43款新智能手机,结果显示有40%(19款智能手机)可以轻易地被简单的打印攻击欺骗。因此,检测PAs对于在智能手机应用程序中实现可靠认证至关重要。
在文献中对面部呈现攻击检测(PAD)进行了广泛研究,这导致了智能手机数据上的几种技术。实现可靠面部PAD的基本挑战是开发一个对不同生成PA的材料不可知的系统。
因此,检测未知的攻击工具是PAD算法成功的关键贡献。此外,开发的PAD算法必须对环境变化和肤色鲁棒,以实现在不同的捕获条件和人口统计数据之间的一般性。
现有的面部PAD技术可以广泛分类为:
基于纹理、频率、运动或时间以及基于深度学习的方法。早期的PAD方法基于使用局部二值模式(LBP)[16, 5]、方向梯度直方图(HOG)[17]、加速稳健特征(SURF)[4]、二值化统计图像特征(BSIF)[24]和尺度不变特征变换(SIFT)[21]。提取的纹理特征使用二分类器(如支持向量机(SVM))进行分类,以做出最终决策。
尽管基于纹理的特征在已知攻击上表现出可接受的性能,但它们无法检测未见过的攻击。基于纹理方法的局限性导致了基于频率或时间-频率特征的其他类型特征的研究[24, 6]。尽管这些特征在检测电子显示攻击时显示出鲁棒性,但它们对其他类型攻击的检测性能有所下降。对时间或运动特征的使用已被广泛研究以检测PAs,特别是远程光电容积描记图(rPPG)[35]在检测打印攻击方面显示出有希望的结果。然而,随着视频重放攻击,检测精度下降,这些方法计算成本高且对外部照明变化敏感。
基于深度学习的PAD技术已被广泛研究。早期的深度学习方法基于使用预训练网络进行特征提取,然后分类以检测PAs。在中提出了多个预训练CNN的融合,这在使用不同手机和环境条件收集的智能手机数据集上显示出优越的性能。
后来的深度学习方法基于多通道CNN、基于像素的监督、注意力模型和 Transformer 模型,这些方法在已知攻击上显示出改进的性能,而这些技术仍然难以对未知攻击显示出鲁棒性。最近,引入了基于域适应、自监督学习和元学习开发的面部PAD方法。然而,这些PAD方法计算成本高,并需要更多数据以实现对未见攻击的良好检测性能。
利用辅助信息,如深度信息,对于从智能手机数据中进行人脸伪造攻击检测(PAD)已经得到了深入的研究。早期采用深度信息的工作在中提出,其中使用了双流CNN学习整体深度图和基于 Patch 的图像。基于深度和rPPG信号的二进制监督在中提出,使用CNN-RNN架构,这表明在跨数据集评估中检测性能有所提升。在[32]中引入了深度监督的残差空间梯度块,使用对比深度损失,这表明在照片攻击中性能有所提高。[13]中提出了从给定视频生成3D点云,这表明在基于2D的攻击工具上性能有所提高。尽管用作辅助信息的深度重建在检测性能上有所提升,但重建的深度表示的是伪深度信息。值得注意的是,伪3D信息并不反映真实的深度信息,并且在呈现攻击时,攻击者通过引入伪深度来欺骗。
最近,在中首次提出了使用点云进行人脸伪造攻击检测的工作,其中使用了iPad收集LiDAR数据(来自iPad后置摄像头),包括真实和伪造的PA。使用了三种不同类型的PA,分别是打印纸、显示屏和刚性面膜,这些数据在不同光照条件下收集。提出了一种双流串行CNN架构,以结合RGB和(点云&深度)数据来检测呈现攻击。
在12个数据主体上获得的结果表明,点云对光照条件的变化不太敏感,在用相同类型的攻击进行训练和测试时,提高了检测准确性。

图1:使用苹果iPhone 12 Pro前置摄像头捕获的3D点云示例(a)真实的(b)3D硅胶面膜(c)包装纸攻击(d)打印纸攻击(e)显示屏攻击。可以看出,由于缺乏深度信息,像打印纸攻击和显示屏攻击这样的2D伪迹很容易被检测到。
因此,中报告的结果并未包含对未见攻击的检测性能,且PA仅限于3D刚性面具。此外,RGB和点云之间的检测性能没有显著差异,这可能归因于低质量的PA工具。
在这项工作中,作者首次提出了使用点云数据处理来检测智能手机上的人脸伪造攻击,这些点云数据是通过苹果iPhone 12Pro的前置摄像头收集的(参见图1,捕获的示例3D点云)。
作者考虑了3D PAI,如硅胶面膜和包装纸,因为像打印和电子显示屏攻击这样的其他类型的PAI是基于2D的,并不显示如图1所示的深度。
因此,基于2D的PAI很容易(也很明显)通过点云检测。点云通过进行 Voxel 化来确保丰富的空间结构,然后输入到所提出的3DCNN网络中检测PA。
与相比,所提出的方法有所不同:
点云是通过前置摄像头捕获的;因此,用户可以自行捕获脸部样本,从而提高可用性。
所提出的方法采用 Voxel 化和3DCNN,而不是将RGB和深度分离考虑的多流网络。因此,所提出的方法基于单流CNN,可以直接处理点云。
针对未见PA攻击场景的3D PAI基准测试结果。本研究的主要贡献如下:
提出了一种利用智能手机前置摄像头记录的3D点云检测面部呈现攻击的新方法。据作者所知,这是首次探索使用智能手机前置摄像头获取的密集3D点云用于面部PAD的实用性。
提出了一种基于 Voxel 化和3DCNN注意力模型的新算法,用于可靠检测未见呈现攻击工具。
使用苹果iPhone 12 Pro收集了一个新的点云数据集,包含30个真实受试者,生成了1014个点云以及两种不同的PAI,分别是包裹照片攻击和3D硅胶面具。整个数据集由3480个3D点云样本组成。这个数据库将用于研究目的(https://sites.google.com/view/speciblab/research/3d-pcpa?authuser=1)。
进行了大量实验,以将所提出的方法与四种不同的现有基于点云的方法的检测性能进行基准测试。
Proposed VoxAtnNet 3D Face PAD
设计网络涉及无穷无尽的参数选择;然而,早期的工作已经在点云上探索了不同的3D CNN架构,表明使用低参数化模型可能导致最佳性能。因此,作者提出了一种新颖的轻量级卷积神经网络(CNN),用于基于点云的人脸PAD。图2展示了作者提出的3D人脸呈现攻击检测方法(VoxAtnNet)的模块图。所提出的VoxAtnNet将3D点云作为 Voxel 占用网格( Voxel )使用3D卷积注意力网络进行处理,以可靠地检测人脸呈现攻击。VoxAtnNet可以由两个构建块组成:(a) 3D点云的 Voxel 化,(b) 3D卷积注意力网络以检测呈现攻击。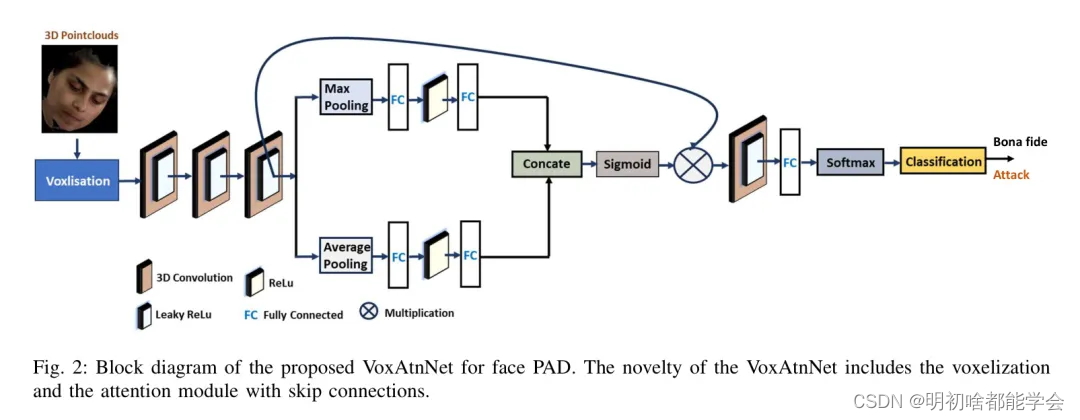
鉴于使用iPhone 12Pro的前置摄像头扫描的3D点云,第一步是将点云表示为使用 Voxel 化[19]的占用网格。这一步对于将点云的不规则空间采样转换为规则采样结构至关重要。在本研究中,作者采用了 Voxel 化,它允许点云的密集表示,从而在空间和范围测量方面实现有效的表示。此外,密集表示的使用使得卷积操作变得实用,因为它们在空间域中代表规则采样的数据。重要的是, Voxel 化能够捕捉到人脸图像丰富的空间结构,这可以揭示真实与人造人脸呈现之间的差异。 Voxel 化通过使用均匀离散化 Voxel 网格空间将每个点云点(x,y,z)映射到离散 Voxel 坐标(i,j,k)。 Voxel 化的结果取决于 Voxel 网格空间的原始点、方向和分辨率。在本研究中,作者采用了[19]中提到的过程来计算参数。原始点被认为是输入,方向被认为是将网格框架与重力方向对齐。为了保持围绕z轴的目标的一致方向,作者通过将输入点云旋转360°来创建副本,从而在训练过程中对数据集进行调整。对于分辨率,作者使用了一个固定的占用网格 646464Voxel ,确保在 Voxel 较大时捕获形状信息并避免混叠。图3显示了与真实样本和攻击样本对应的 Voxel 化示例,展示了空间结构上的视觉区别。
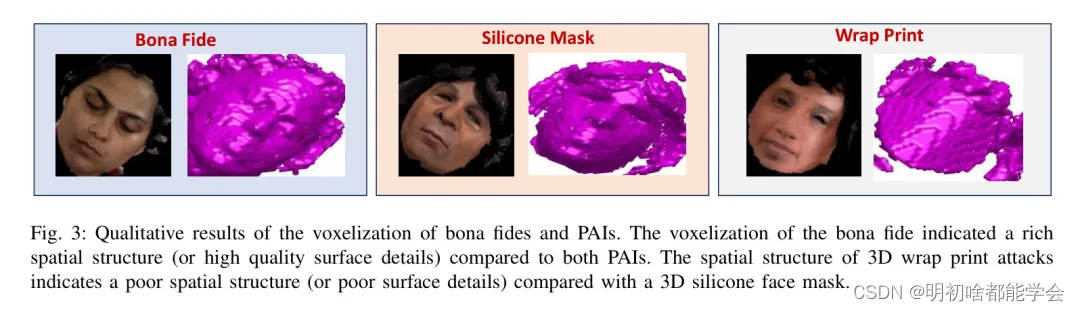
图2:所提出的人脸PAD的VoxAtnNet模块图。VoxAtnNet的新颖之处包括 Voxel 化和带有跳跃连接的注意力模块。
对应的点云经过Voxel化后获得的的空间结构被送入到设计用于检测人脸呈现攻击的新颖CNN架构中。图2展示了所提出的VoxAtnNet的结构,它有23层以残差方式连接。VoxAtnNet的初始或早期层是一系列3D卷积和带泄露的ReLU层的ConCat,可以有效编码不同方向上的平面和角落。堆积的卷积层具有不同的滤波器大小、滤波器数量和步长,这些使得构建输入占用网格的分层特征成为可能。第一个卷积层的滤波器大小为5×5×5,滤波器数量为64,步长为,而第二和第三卷积层的滤波器大小为3×3×3,滤波器数量为32,步长为。在第二阶段,作者引入了一个注意力网络,指导学习专注于给定占用网格中的重要空间结构。
所提出的注意力单元与现有的空间注意力略有不同,因为该方法在最大池化和平均池化上独立添加了一系列的全连接和ReLU,然后进行拼接。因此,使用全连接和ReLU层强调了注意力的区域,可以帮助VoxAtnNet在占用地图的空间结构中找到欺骗模式。拼接后的特征通过sigmoid层,并与来自卷积-3层的跳跃连接相乘,这可以进一步表示丰富的特征。网络的最后部分通过卷积(3×3,滤波器数量为32,步长为[1,1,1])、带泄露的ReLU和全连接层的ConCat处理乘法后的特征,在进行softmax层的分类之前。
VoxAtnNet的训练使用带有动量的随机梯度下降(SGDM)和交叉嫡损失。SGDM的初始学习率为0.01。在训练过程中动态进行数据增强,为每个实例添加随机扰动的副本(增加抖动噪声、镜像和偏移)。本研究中使用的迷你批处理大小为32。所提出的方法VoxAtnNet有35.7M个可学习参数。
3D face point cloud presentation attack Dataset (3D-PCPA)
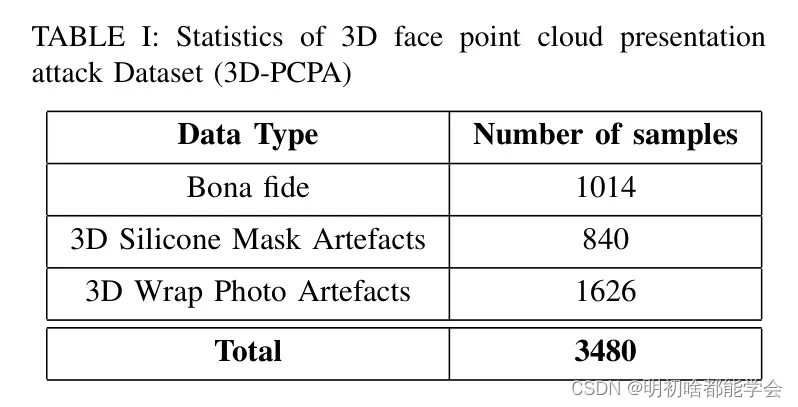
本节描述了一个使用iPhone 12 Pro智能手机获取的新构建的3D-PCPA数据库。用户通过与iPhone 12 Pro的前置摄像头互动,自行捕捉3D点云。用户在面部和智能手机之间15-20厘米的距离自行捕捉3D扫描。3D-PCPA数据库包括真实和演示攻击人脸3D点云,以捕捉在多个会话中获取的点云。与每个类别获取相关的细节将在以下小节中总结。每个类别下获取的样本数量的总结详见表1,图4展示了来自3D-PCPA数据集的点云示例。
Bona fide subset of 3D-PCPA Database
三维PCPA数据库的真实子集
来自3D-PCPA数据库的bonafide面部点云数据是在室内办公环境中从30位不同的数据主体(16位男性和14位女性)收集的。每位主体被要求在多个会话中使用智能手机扫描他/她自己的脸部,数据收集在1-3周的时间内完成。总共获取了1014个面部点云,这相当于每位数据主体有30到33个3D点云样本。
来自3D-PCPA数据库的面部点云数据是在室内办公环境中从30位不同的数据主体(16位男性和14位女性)收集的.)每位主体被要求在多个会话中使用智能手机扫描他/她自己的脸部,数据收集在1-3周的时间内完成.总共获取了1014个面部点云,这相当于每位数据主体有30到33个3D点云样本。Presentation attack subsets for 3D-PCPA database
在这项工作中,作者测试了3D PAIs相对于2D PAIs的有效性,以有效解决3D PAD技术对3D PAIs的攻击潜力。因此,作者考虑了两种不同的3D PAIs:(a)3D硅胶面具和(b)3D包裹纸照片攻击。本研究中使用的高质量面部口罩是定制的,对人脸识别系统(FRS)具有更高的易受攻击性。包裹纸照片攻击是通过将打印照片包裹在攻击者的脸上以模拟伪深度来生成的。
3D硅胶面部伪装艺术品:作者使用了四个(2名男性和2名女性受试者)独特的3D硅胶面部面具来捕捉3D点云。这些3D硅胶面具由数据主体佩戴,并单独进行扫描以捕捉3D点云。数据收集在不同的会话中进行了三周,期间15个不同的数据主体戴了这四张面具。总共,3D硅胶PAI有840个点云扫描,对应于四个独特的面具。
3D包裹照片艺术品:3D包裹照片打印攻击的生成有三个步骤(1)作者使用数码单反相机捕捉了15个不同数据主体(10名男性和5名女性)的高分辨率照片;(2)将数字照片使用彩色激光打印机(型号:柯尼卡美能达的bizhub C360i)打印在高质量纸张上;(3)然后将打印的照片包裹在脸上,并使用智能手机的前置摄像头自行捕捉以获得点云。攻击是通过20个不同的数据主体在多个会话中佩戴这15个独特的包裹生成的,会话时间从1周到3周不等,产生了1626个3D包裹照片艺术品。
图3:真实样本和PAIs Voxel 化的定性结果。真实样本的 Voxel 化显示出丰富的空间结构(或高质量的表面细节),与两种PAIs相比。与3D硅胶面部伪装相比,3D包裹照片攻击的空间结构表明空间结构较差(或表面细节较差)。
表1:3D人脸点云呈现攻击数据集(3D-PCPA)的统计信息
IV Experiments and Results
在本节中,作者介绍了所提出的三维人脸防伪(PAD)方法在新收集的三维点云人脸数据集(3D-PCPA)上的性能评估协议和定量结果。由于直接采用三维点云进行人脸防伪检测,作者将提出的方法与三种不同的基于点云的分类技术进行了比较,这些技术包括PointNet ,PointNet++ ,VoxNet 以及Masked AutoEncoders (Point-MAE) 。三维PAD算法的定量性能是根据ISO/IEC 30107-3 指标进行评估的。‘攻击呈现分类错误率(APCER)被定义为错误地将攻击呈现分类为真实呈现的比例,而BPCER被定义为错误地将真实呈现分类为攻击呈现的部分’。此外,作者还使用检测等错误率(D-EER)和检测错误权衡(DET)曲线呈现定量结果。
Performance evaluation protocol
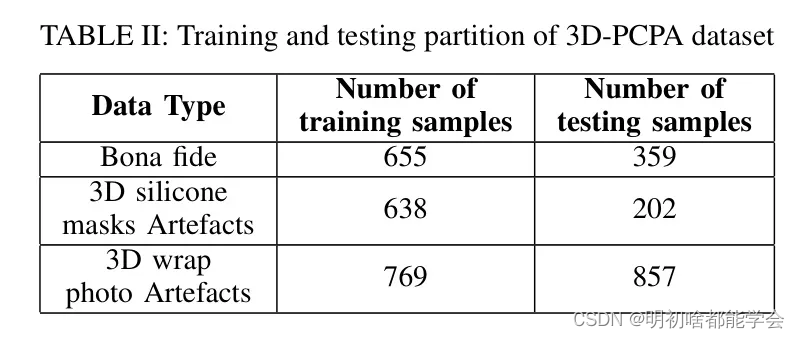
三维PAD技术的性能是通过将3D-PCPA数据集划分为两个不重叠的集合来评估的,即训练集和测试集。30个独特数据主体的真实数据被分配为训练集中有20个独特数据主体,剩下的10个在测试集中。这导致了训练中有655个点云样本,测试中有359个点云样本。对于3D硅胶面具,作者选择了两个独特的面具(一个男性和一个女性)用于训练,剩下的两个独特的面具用于测试集。这导致了训练中有638个点云样本,测试中有202个点云样本。对于3D包裹照片面具,从15个独特的包裹照片制品中,选择了八个(5个男性和3个女性)用于训练,剩下的七个(5个男性和2个女性)用于测试集。这导致了训练集中有769个点云样本,测试集中有857个点云样本。表2显示了训练和测试分区的统计信息。
为了有效地评估针对人脸PAD的提出的和最先进的3D点云技术,作者提出了三种不同的评估协议。内部协议使用相同类型的PAI对3D点云进行训练和测试。该协议对已知类型PAI的PAD技术的性能进行基准测试。交叉协议使用一种类型的PAI训练PAD技术,用另一种类型的PAI进行测试。该协议表示PAD技术在未见攻击下的性能。两者协议,即使用两种PAI进行PAD的训练和测试。该协议对PAD技术在训练和测试中使用不同类型PAI时的性能进行基准测试。
Results and discussion
表3展示了所提出的VoxAttNet和现有方法在不同性能评估协议下的定量性能。图4(a),4(b),4©,4(d)和4(e)展示了在内部协议下,所提出方法与现有方法的DET曲线。以下是内部协议结果的重要观察: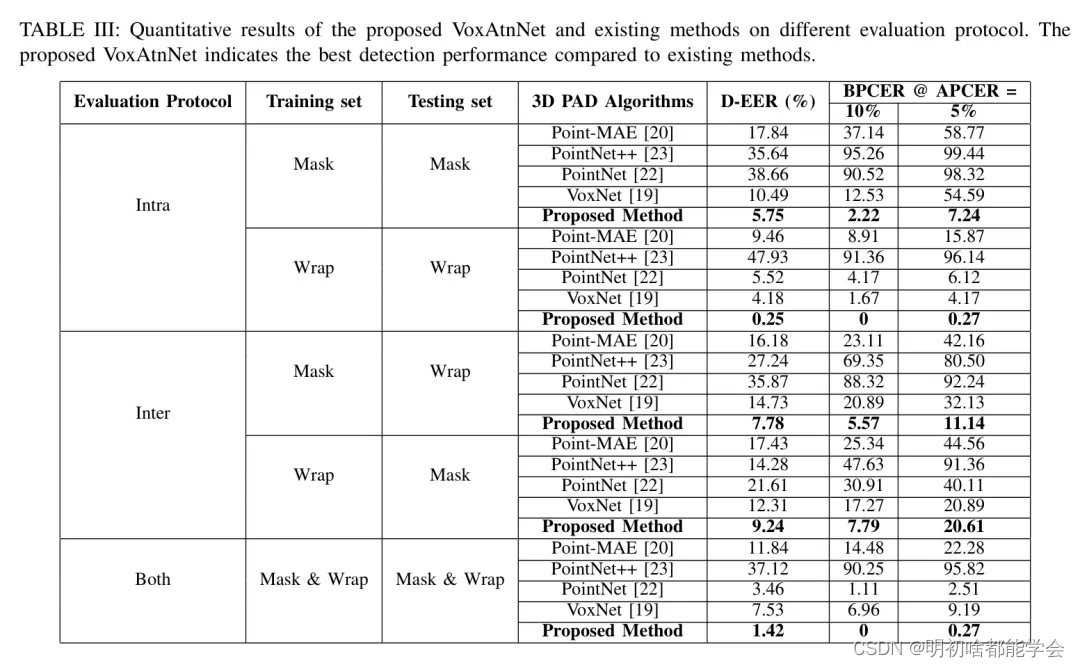
在两种不同的PAI中,与3D包裹照片攻击相比,检测3D硅胶人脸攻击的准确性降低了。无论是PointNet [22]还是所提出的方法,性能都出现了下降。检测3D硅胶面具的挑战可以归因于它和真实人脸具有相似的面部结构和几何特征。然而,使用3D包裹照片只能生成伪深度,因为它用于覆盖的并不反映实际人脸的实际深度和形状的照片。这可以在图3中观察到,其中包裹攻击只能模拟伪深度,并不提供与面部特征(例如,鼻子,嘴巴)相关的深度。
与本文中使用的两种类型PAI相比,所提出的方法比现有方法表现出更好的性能。性能的改进可以归因于使用了 Voxel 化作为可以有效编码反映PAI中面部几何不连续性的空间结构的特征。
所提出的方法在内部协议上针对3D硅胶面具的D-EER = 5.75%,针对3D包裹照片PAI的D-EER = 0.25%。
在现有方法中,VoxNet [19]比PointNet变体显示出更好的结果。
图5(a),5(b),5©,5(d)和5(e)展示了在跨协议评估中,所提出方法和现有方法的检测性能的DET曲线。根据表3中列出的结果,以下是可以注意到的: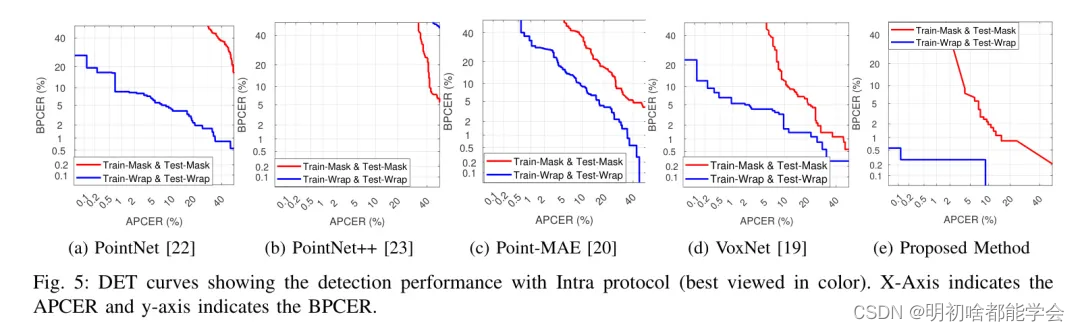
PointNet [22]技术比所提出方法的性能有所下降。使用3D硅胶面具进行训练,使用3D包裹照片PAI进行测试表明有更高的性能退化,这可以归因于PAI之间不同的3D信息类型。
图5:使用Intra协议的检测性能DET曲线(彩色查看最佳)。横轴表示APCER,纵轴表示BPCER。
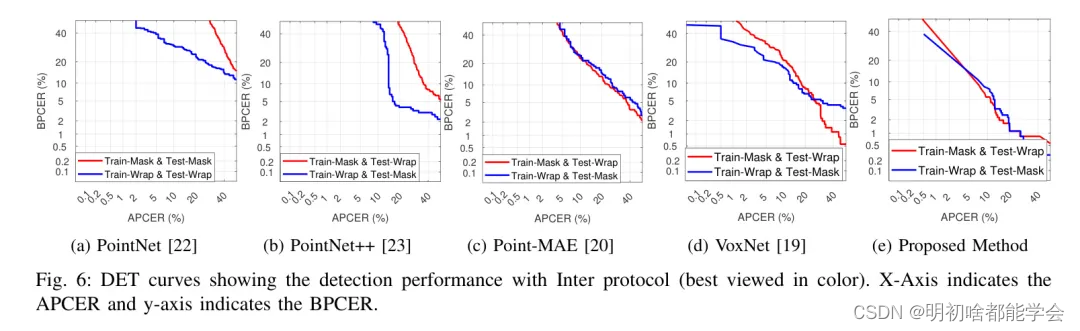
图6:使用Inter协议的检测性能DET曲线(彩色查看最佳)。横轴表示APCER,纵轴表示BPCER。
图8展示了“两种协议”的DET曲线,其中两个PAI都用于训练和测试。有趣的是,PointNet [22]的表现在检测准确性上有较大的提升。这种性能的改进是由于3D包装PAI(857个)的数量大于3D面具PAI(202个)。这是因为如上讨论并在表3中所示,PointNet [22]在检测3D包装PAI相对于3D面具PAI方面显示出较高的准确性。提出的方法在两种协议下均展现出最佳性能,D-EER = 1.42%。
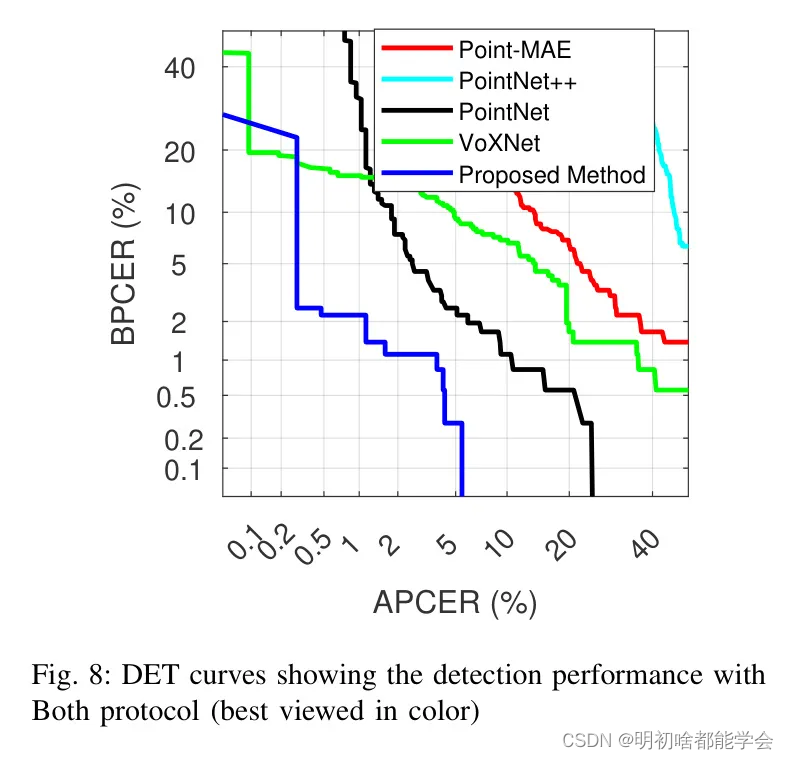
根据上述一系列实验报告,提出的方法在所有三种性能评估协议上均表现出最佳性能。提出的方法还在性能上显示出较小的下降,指示了与现有方法相比,提出方法的泛化特性。
表3:不同评估协议上提出VoxAtnNet和现有方法的定量结果。提出的VoxAtnNet相较于现有方法显示了最佳的检测性能。
所提出方法的误分类示例,如图9所示,并通过协议内评估进行了说明。需要注意的是,图9(c)仅展示了一个示例,因为所提出的方法仅导致了一次误分类。尽管很难得出确切的结论,但作者认为,在自拍过程中环境噪声的存在可能导致生成了低质量的点云,最终导致了误分类。
Ablation Study
在本节中,作者进行了一项消融研究,考察了各种参数以及注意力模块在所提出的VoxAttNet中的作用。表4展示了对VoxAttNet框架内不同卷积滤波器尺寸的超参数研究。在提出的VoxAttNet架构中评估了三种不同的滤波器尺寸,分别为3×3、5×5和7×7。表4呈现了与面具、包裹及两者兼备的内部评估协议的定量结果。获得的结果表明,在面对包裹攻击时,3×3的滤波器尺寸显示出更高的检测准确性。相反,5×5的滤波器尺寸在检测硅胶面具攻击方面表现出色,而7×7的滤波器尺寸在检测PA方面的检测准确性不如其他尺寸的滤波器。VoxAttNet架构设计为结合3×3和5×5滤波器,这证明了它在检测硅胶面具和包裹攻击方面的有效性,从而验证了所选滤波器尺寸的适宜性。
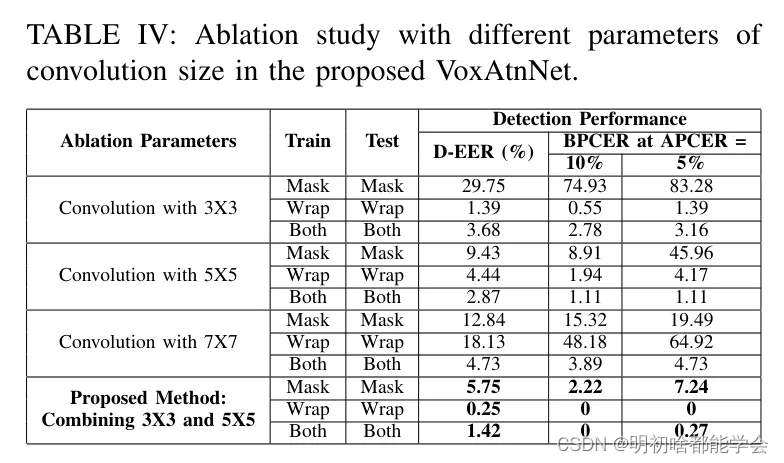
表5展示了所提出的VoxAttNet的消融研究,比较了包含和不包含注意力模块时的性能。结果显示,加入注意力模块显著提高了所提模型的检测准确性和泛化能力。没有注意力模块时,网络的性能严重下降,特别是在包裹攻击中,导致对未见3D PAI的检测准确性和泛化能力大幅降低。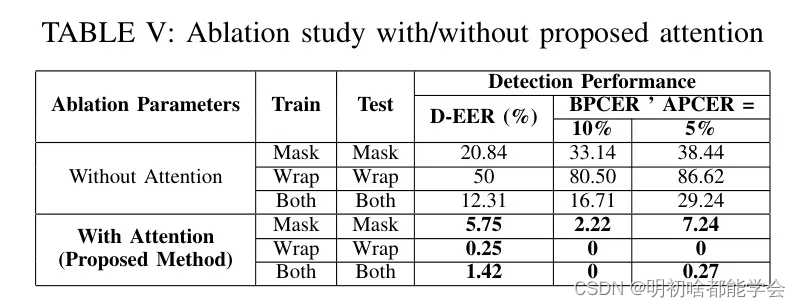
V Limitations
在本工作中,作者引入了一种新颖的方法,利用苹果iPhone 12 Pro前置摄像头获取的3D点云来检测面部伪仿制品(PAs)。作者通过一系列针对3D伪仿制品(PAIs)的评估协议,展示了所提出的VoxAttNet的有效性。
然而,需要注意的是,作者在室内办公环境中收集了一个包含3480个3D点云的数据集。因此,有必要在一个大规模数据集上评估性能,考虑其他能反映真实生活场景的光照条件。此外,数据集还必须扩展到其他带有深度传感器(除了iPhone之外)的智能手机上,以更好地评估所提出的VoxAttNet的鲁棒性。实验结果表明,由3D包裹照片伪仿制品引入的伪深度,使用所提出的VoxAttNet检测起来较为容易。因此,伪仿制品检测(PAD)技术的泛化能力必须扩展到其他能反映面部几何的3D面部面具。
VI Conclusion
在本工作中,作者提出了一种新颖的3D人脸PAD算法,用于检测智能手机上的呈现攻击。所提方法的一个重要组成部分是 Voxel 化,以从点云中捕捉空间结构,同时还有一系列卷积层中提出的新的注意力框架。所提出的VoxAttNet处理来自iPhone的输入3D点云,随后进行 Voxel 化,并通过具有23层和一个总共3570万可学习参数的3D卷积网络。
在这项工作中,作者还引入了一个新的3D人脸点云呈现攻击数据集(3D-PCPA),包含3480个样本,对应于真实、3D硅膜PAI和3D包裹照片PAI。
作者展示了三种不同性能评估协议的广泛实验,这些实验表明与四种不同现有方法相比,攻击检测性能有所提高。获得的结果表明,所提出的方法性能卓越,从而表明使用从智能手机捕获的3D点云进行泛化的PAD。

![[ACTF2020 新生赛]BackupFile 1 [极客大挑战 2019]BuyFlag 1 [护网杯 2018]easy_tornado 1](https://img-blog.csdnimg.cn/direct/e60cd9b6fbec4010b847bc1597c9d9ad.png)