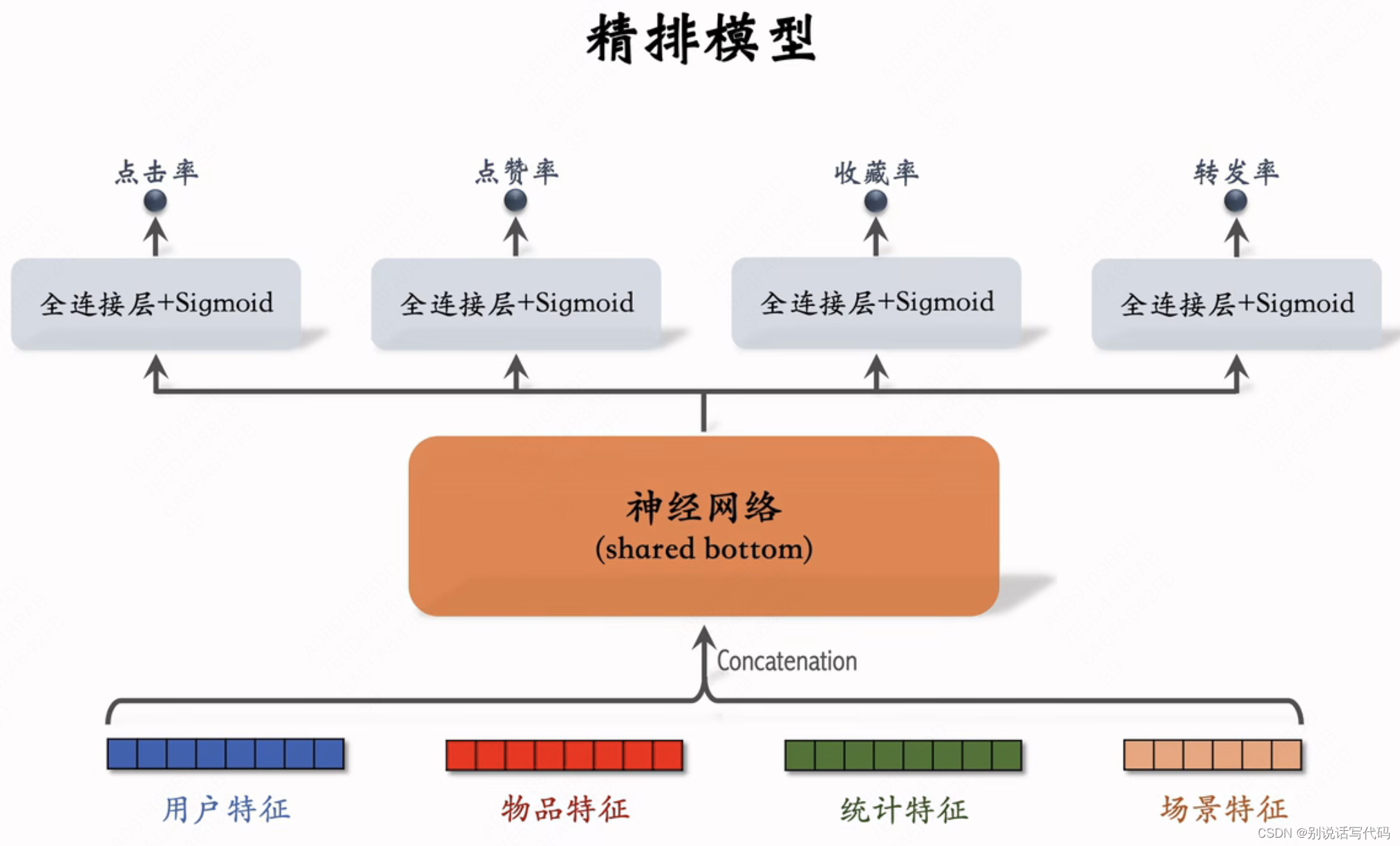
前期融合:先对所有特征做concat,再输入DNN,一般常见于精排模型
特点:线上推理代价大,若有n个候选item需要做n次模型计算
后期融合:把用户和物品特征分别输入不同的神经网络,不对用户和物品做融合,常见于召回双塔
特点:线上计算量小,用户塔只需要做一次线上推理,计算用户表征a,物品表征b事先存储在向量数据库,物品塔在线上不做推理;预估准确性不如精排模型。

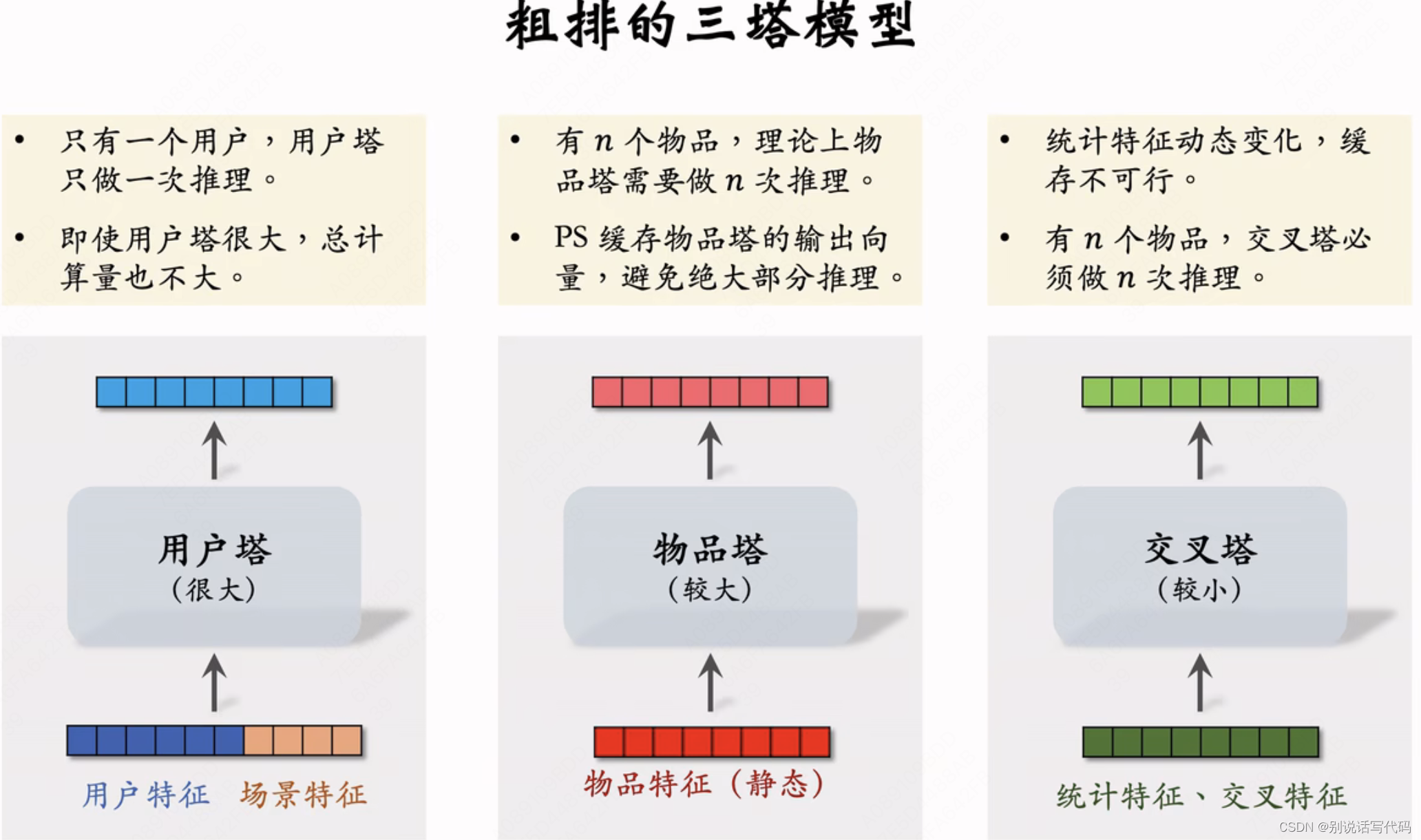
粗排模型:一般介于前期融合和后期融合之间,比如三塔模型
前期:
- 用户塔:只有一个用户,线上推理一次,即时用户塔计算量很大也费不了多少资源
- 物品塔:有n个物品理论上要做n次推理,PS缓存物品塔输出向量,避免绝大部分推理
- 交叉塔:统计特征动态变化缓存不可行,有n个物品交叉塔必须做n次推理
后期:
- 有n个物品模型上层需要做n次推理,粗排模型推理大部分计算量在模型上层

引申问题:双塔在召回和粗排有啥区别?
双塔模型在召回和粗排的区别-CSDN博客