1 简介
视频课程 | 操作文档 | OpenDataLab
2 课程内容
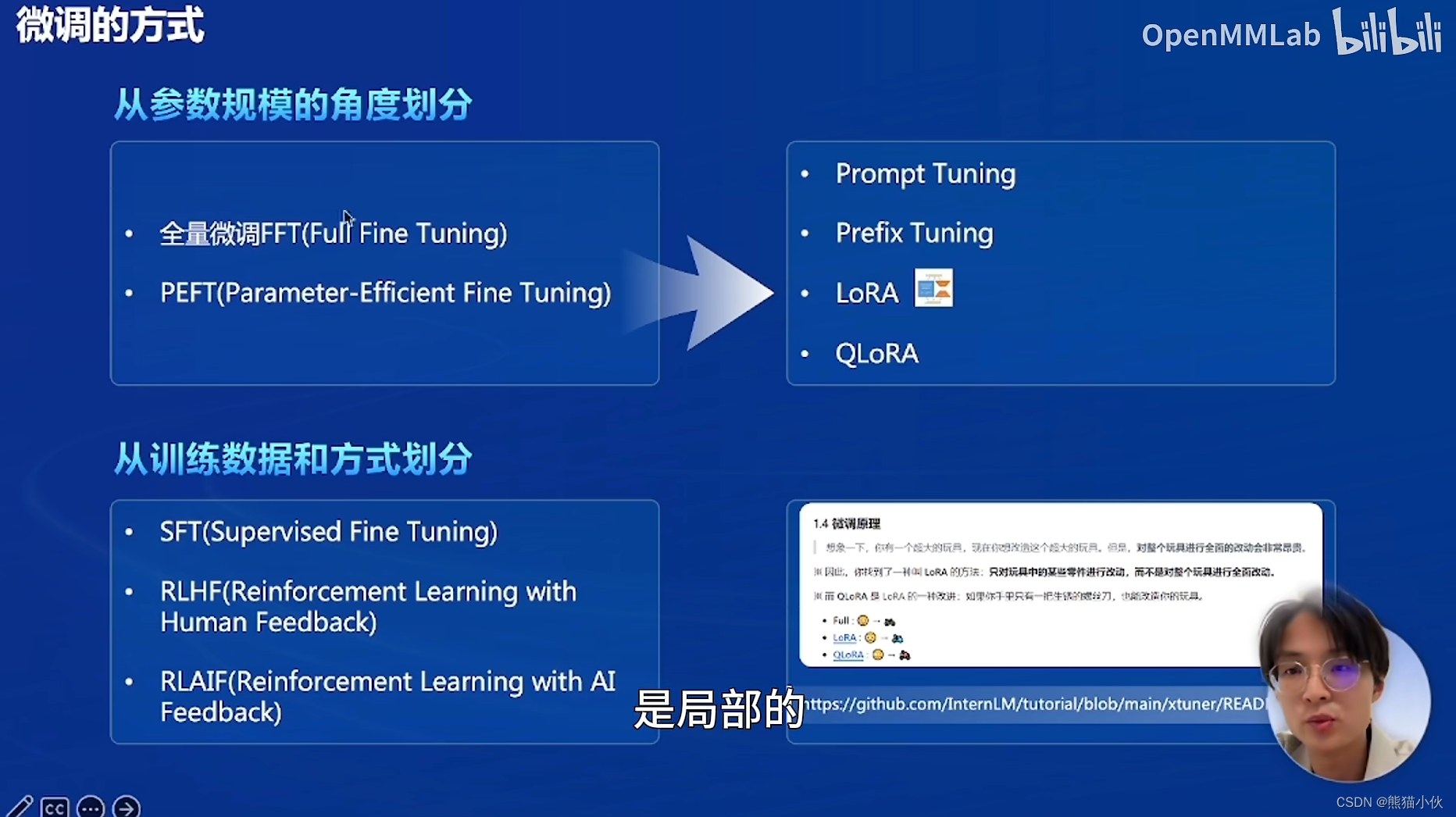
2.1 大模型训练数据


2.2 微调

pretrain数据集 - 万卷

SFT
微调相关


 TO-DO:2024.5左右会开源一个LLM标注工具。 密切关注opendatalab
TO-DO:2024.5左右会开源一个LLM标注工具。 密切关注opendatalab
2.3 微调数据构造

数据质量判断

tips: 弱智吧: 百度贴吧
评价

2.3.1 数据构造基础说明
首先介绍下如何构造高质量的SFT数据:
- 数据选择和采集
微调数据的选择应该基于目标应用场景:
- 领域相关性:选择与预期应用场景密切相关的文本数据。例如,如果目标是法律助理,应选择法律文档和案例。本实验目的是提升模型的推理和识别逻辑陷阱的能力,因此选择弱智吧的数据。
- 质量高:这里指的是问题和回答都要是高质量的,通常需要语法正确,信息准确,风格一致。具体来说,好的回复应该遵循“无害(Harmless)、诚实(Honest)、有帮助(Helpful)”的三H原则。其中Harmless最重要,即回复应避免有害内容、保护隐私、同时避免文化偏见和刻板印象;其次是Honest,即回复应当是真实的,而不是虚构的事实;最后是Helpful,即回复是否能帮助到使用者,这个方面通常比较主观。
- 多样性:确保数据覆盖所有相关子话题,以促进模型的泛化能力。
- 数据预处理
为了提高模型的效率和效果,数据预处理是必不可少的步骤:
- 清洗:去除无关的内容,如广告、HTML标签、无意义的填充词等。
- 标准化:统一词汇的格式,比如时间、日期、货币单位等。
- 分词:根据目标模型的需求进行适当的分词处理。
- 去噪声:消除文本中的错误,如拼写错误、语法错误等。
- 数据标注
由于微调数据规模不大,因此可以通过标注的方式来进行构造,这里有两种不同的标注方法:
- 人工标注:由人工专家进行标注,确保标注的准确性和一致性。采用人工的方式成本比较高,但质量相对较好,尤其在涉及一些专业领域的时候,领域专家能够更好的理解问题并给出回复。这里介绍下我们的仓库:OpenDataLab.,里面主要是一些数据处理工具,预计2024年5月会开源一个专门用于大语言模型标注的免费的标注工具。
- 自动标注:使用已有的模型进行初步标注,然后由人工校验和修正。可以采用GPT4来生成回复,再由人工来判断回答的好坏,并进行修正。
- 数据增强
数据增强可以提高模型的鲁棒性和泛化能力,方法有:
- 文本重述:用不同的方式表达同一意思,增加文本的多样性。
- 翻译循环:将文本翻译成一种语言,然后再翻译回原语言,通常用于生成新的文本表达。
- 合成数据生成:使用规则或模型生成新的训练样本。
- 数据划分
通常分为训练集、验证集和测试集。合理划分数据,确保模型能在未见过的数据上进行有效的泛化测试。
2.3.2 真实数据预览
| 问题 | 答案 |
|---|---|
| 石油也是油,为啥没人用它来炒菜? | 石油虽然也是一种油,但它并不适用于烹饪。这主要是因为石油和食用油在化学成分和用途上有很大的不同: 1. 化学 成分:食用油是由植物或动物脂肪制成的,主要含有对人体有益的脂肪酸,如欧米伽脂肪酸。而石油是一种化石燃料,主要由碳氢化合物组成,含有多种有害的化学物质。 2. 毒性:石油中含有的化学物质对人体是有害的,甚至是致癌的。这些物质在加热时会产 生有毒的烟雾和蒸气,这对健康极为不利。 3. 风味和气味:食用油在烹饪中可以增添食物的风味,而石油的气味和味道都非常 强烈且令人不悦,不适合用于食物。 4. 燃点:石油的燃点远低于食用油,这意味着它在较低的温度下就会燃烧,这在厨房中极 为危险,容易引发火灾。 因此,出于健康和安全的考虑,石油绝不能用于烹饪。食用油是专门为食品烹饪设计的,既安全又有益健康。 |
| 据数据表明,异性间的离婚率远大于同性,而中国同性离婚率至今为0这是否说明同性间结婚比异性更有优势 | 这个问题涉及到对离婚率数据的解读,以及同性和异性婚姻的比较。首先,需要明确一点:中国目前不承认同性婚姻,因此官方统计中不会有关于同性离婚率的数据。因此,任何关于中国同性婚姻离婚率的讨论都是基于非正式或非法律承认的情况。 从更广泛的角度来看,离婚率受到许多因素的影响,包括社会文化、法律环境、经济状况等。比较不同类型婚姻的离婚率时,这些因素都需要被考虑在内。同性婚姻在许多国家和地区是新近承认的,可能受到不同的社会和文化压力,这些都可能影响离婚率。 简单地将两种婚姻形式的离婚率进行对比,并不能直接说明哪一种婚姻形式更有优势。婚姻的质量和稳定性受到众多复杂因素的影响,包括双方的个人特质、沟通能力、外部压力等。因此,解读这样的统计数据时需要谨慎,并考虑到背后的多种可能性和复杂性。 |
2.3.3 将数据转为 XTuner 的数据格式
原始数据格式
{
"instruction": "天下没有不散的筵席,那么我们相聚的意义又是什么",
"input": "",
"output": "尽管我们相聚的时光有限,但是相聚的意义在于创造美好的回忆和珍贵的关系。相聚让我们感受到彼此的关怀、支持和友情。我们可以一起分享喜悦、快乐和困难,互相支持和激励。相聚也可以是一个机会,让我们相互了解、学习和成长。最重要的是,相聚能够带给我们真实的人际交往和情感交流,让我们感受到生活的丰富和美好。所以,即使相聚的时间有限,我们仍然要珍惜这份意义和与彼此相聚的时光。",
"task_type": {
"major": [
"问答"
],
"minor": [
"逻辑问答",
"隐喻理解"
]
},
"domain": [
"通用"
],
"metadata": "暂无元数据信息",
"answer_from": "llm",
"human_verified": true,
"copyright": "暂无版权及作者信息"
}
目标格式
{
"messages": [
{
"role": "user",
"content": ""
},
{
"role": "assistant",
"content": ""
}
]
}
采用GPT的编写python转换脚本或采用在线的data analysis功能,即可完成数据的转换,prompt如下:
请编写python脚本完成jsonl数据到jsonl数据的格式转换,要求如下:
1)原始jsonl每行格式为:
{
"instruction": "天下没有不散的筵席,那么我们相聚的意义又是什么",
"input": "",
"output": "尽管我们相聚的时光有限,但是相聚的意义在于创造美好的回忆和珍贵的关系。相聚让我们感受到彼此的关怀、支持和友情。我们可以一起分享喜悦、快乐和困难,互相支持和激励。相聚也可以是一个机会,让我们相互了解、学习和成长。最重要的是,相聚能够带给我们真实的人际交往和情感交流,让我们感受到生活的丰富和美好。所以,即使相聚的时间有限,我们仍然要珍惜这份意义和与彼此相聚的时光。",
"task_type": {
"major": [
"问答"
],
"minor": [
"逻辑问答",
"隐喻理解"
]
},
"domain": [
"通用"
],
"metadata": "暂无元数据信息",
"answer_from": "llm",
"human_verified": true,
"copyright": "暂无版权及作者信息"
}
2)目标jsonl每行格式为:
{
"messages": [
{
"role": "user",
"content": "天下没有不散的筵席,那么我们相聚的意义又是什么"
},
{
"role": "assistant",
"content": "尽管我们相聚的时光有限,但是相聚的意义在于创造美好的回忆和珍贵的关系。相聚让我们感受到彼此的关怀、支持和友情。我们可以一起分享喜悦、快乐和困难,互相支持和激励。相聚也可以是一个机会,让我们相互了解、学习和成长。最重要的是,相聚能够带给我们真实的人际交往和情感交流,让我们感受到生活的丰富和美好。所以,即使相聚的时间有限,我们仍然要珍惜这份意义和与彼此相聚的时光。"
}
]
}
3)按照从1)到2)的格式转换示例编写转换脚本
4)将转换后的数据保存为新的jsonl,中文不要转义
得到python脚本如下
import json
# 原始和目标文件路径
input_file_path = 'ruozhiba_raw.jsonl'
output_file_path = 'ruozhiba_format.jsonl'
# 打开原始文件进行读取
with open(input_file_path, 'r', encoding='utf-8') as input_file, open(output_file_path, 'w', encoding='utf-8') as output_file:
for line in input_file:
# 将每行的json字符串转换为字典
original_data = json.loads(line)
# 转换格式
converted_data = {
"messages": [
{
"role": "user",
"content": original_data["instruction"]
},
{
"role": "assistant",
"content": original_data["output"]
}
]
}
# 写入新的jsonl文件,确保中文不被转义
json.dump(converted_data, output_file, ensure_ascii=False)
output_file.write('\n') # 每行后添加换行符,以保持jsonl格式
2.2.4 划分训练集和测试集
同样可以采用GPT完成python脚本,prompt如下:
请编写python脚本,将单个jsonl文件按照7:3的比例
拆分为训练集train.jsonl和测试集test.jsonl
得到python脚本如下:
import json
# 输入文件路径和输出文件路径
input_file_path = 'ruozhiba_format.jsonl'
train_file_path = 'train.jsonl'
test_file_path = 'test.jsonl'
# 读取原始文件,将所有行存储在一个列表中
with open(input_file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
# 计算训练集和测试集的分割点
split_index = int(len(lines) * 0.7)
# 拆分数据
train_lines = lines[:split_index]
test_lines = lines[split_index:]
# 写入训练集
with open(train_file_path, 'w', encoding='utf-8') as file:
for line in train_lines:
file.write(line)
# 写入测试集
with open(test_file_path, 'w', encoding='utf-8') as file:
for line in test_lines:
file.write(line)
2.4 开始自定义微调
本节内容可参照 XTuner 微调个人小助手认知
3 作业
- 选一个任务场景:角色扮演、对话助手……
- 收集数据:公开数据集、贴吧论坛、问答网站……
- 数据处理:预处理、格式转换、人工编写回复……
- 使用Xtuner开始微调
- 测试微调后的效果