🏷️个人主页:牵着猫散步的鼠鼠
🏷️系列专栏:Java源码解读-专栏
🏷️个人学习笔记,若有缺误,欢迎评论区指正

目录
1. 前言
2. 原子性问题
3. 乐观锁与悲观锁
4. CAS操作
5. CAS算法带来的三大问题
5.1. ABA问题
5.2. 长时间自旋
5.3. 多个共享变量的原子操作
6. 总结
1. 前言
我们在前面的文章中讲解了AQS的底层原理,Semaphore信号量的底层实现等等,我们可以发现他们都频繁用到了CAS操作,那么这个CAS操作到底是什么,我们就来深入了解学习下。
我们都知道CAS操作可以解决原子性问题,我们首先来了解下什么是原子性问题。
2. 原子性问题
原子性: 一个或者多个操作在 CPU 执行的过程中不被中断的特性;
原子操作: 即最小不可拆分的操作,也就是说操作一旦开始,就不能被打断,直到操作完成。
什么是原子性问题呢?我们这里列举一个小案例。
public class Test {
//计数变量
static volatile int count = 0;
public static void main(String[] args) throws InterruptedException {
//线程 1 给 count 加 10000
Thread t1 = new Thread(() -> {
for (int j = 0; j <10000; j++) {
count++;
}
System.out.println("thread t1 count 加 10000 结束");
});
//线程 2 给 count 加 10000
Thread t2 = new Thread(() -> {
for (int j = 0; j <10000; j++) {
count++;
}
System.out.println("thread t2 count 加 10000 结束");
});
//启动线程 1
t1.start();
//启动线程 2
t2.start();
//等待线程 1 执行完成
t1.join();
//等待线程 2 执行完成
t2.join();
//打印 count 变量
System.out.println(count);
}
}
我们创建了2个线程,分别对count进行加10000操作,理论上最终输出的结果应该是20000对吧,但实际并不是,我们看一下真实输出。
thread t1 count 加 10000 结束
thread t2 count 加 10000 结束
14281
我们可以发现实际输出不为20000,我们接着解析原因
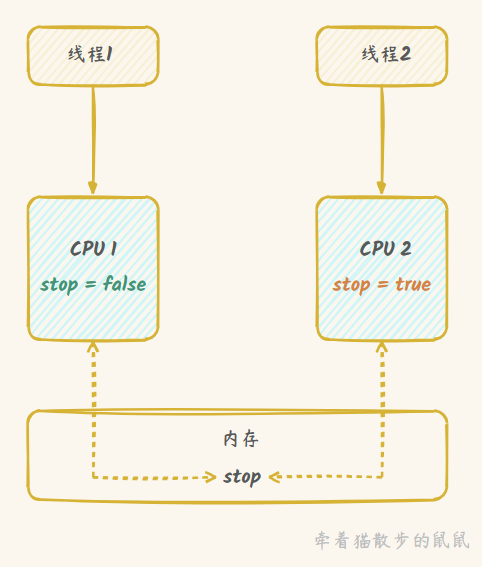
原因: Java 代码中 的 count++ ,至少需要三条CPU指令:
- 指令 1:把变量 count 从内存加载到CPU的寄存器
- 指令 2:在寄存器中执行 count + 1 操作
- 指令 3:+1 后的结果写入CPU缓存或内存
即使是单核的 CPU,当线程 1 执行到指令 1 时发生线程切换,线程 2 从内存中读取 count 变量,此时线程 1 和线程 2 中的 count 变量值是相等,都执行完指令 2 和指令 3,写入的 count 的值是相同的。从结果上看,两个线程都进行了 count++,但是 count 的值只增加了 1。这种情况多发生在cpu占用时间较长的线程中,若单线程对count仅增加100,那我们就很难遇到线程的切换,得出的结果也就是200啦。
解决办法:
可以通过JDK Atomic开头的原子类、synchronized、LOCK解决多线程原子性问题,这其中Atomic开头的原子类就是使用乐观锁的一种实现方式CAS算法实现的,那么在了解CAS算法之前,我们还是要先来聊一聊乐观锁。
3. 乐观锁与悲观锁
乐观锁与悲观锁是一组互反锁。
悲观锁(Pessimistic Lock): 线程每次在处理共享数据时都会上锁,其他线程想处理数据就会阻塞直到获得锁。如 synchronized、java.util.concurrent.locks.ReentrantLock;
public void testSynchronised() {
synchronized (this) {
// 需要同步的操作
}
}
private Lock lock = new ReentrantLock();
lock.lock();
try {
// 需要同步的操作
} finally {
lock.unlock();
}
乐观锁(Optimistic Lock): 相对乐观,线程每次在处理共享数据时都不会上锁,在更新时会通过数据的版本号机制判断其他线程有没有更新数据,或通过CAS算法实现,乐观锁适合读多写少的应用场景。
版本号机制: 所谓版本号机制,一般是在数据表中加上一个数据版本号 version 字段,来记录数据被修改的次数,线程读取数据时,会把对应的version值也读取下来,当发生更新时,会先将自己读取的version值与数据表中的version值进行比较,如果相同才会更新,不同则表示有其他线程已经抢先一步更新成功,自己继续尝试。
两种锁的优缺点:
- 乐观锁适用于读多写少的场景,可以省去频繁加锁、释放锁的开销,提高吞吐量;
- 在写比较多的场景下,乐观锁会因为版本号不一致,不断重试更新,产生大量自旋,消耗 CPU,影响性能。这种情况下,适合悲观锁。
CAS算法: CAS全称为Compare And Swap(比较与交换),是一种算法,更是一种思想,常用来实现乐观锁,通俗理解就是在更新数据前,先比较一下原数据与期待值是否一致,若一致说明过程中没有其他线程更新过,则进行新值替换,否则更新失败,但失败的线程并不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。
4. CAS操作
那么CAS操作是如何实现的呢?其实在Java中并没有直接给与实现,而是通过JVM底层实现,底层依赖于一条 CPU 的原子指令。那我们在Java中怎么使用,或者说哪里准寻CAS的痕迹呢?
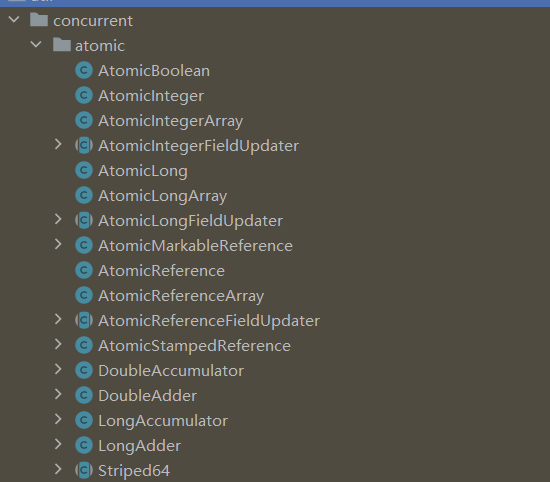
我们在上面提到了JDK Atomic开头的原子类可以解决原子性问题,那我们就跟进去一探究竟,首先,进入到 java.util.concurrent.atomic 中,里面支持原子更新数组、基本数据类型、引用、字段等,如下图:
现在,我们以比较常用的AtomicInteger为例,选取其getAndAdd(int delta)方法,看一下它的底层实现。
/**
* Atomically adds the given value to the current value.
*
* @param delta the value to add
* @return the previous value
*/
public final int getAndAdd(int delta) {
return unsafe.getAndAddInt(this, valueOffset, delta);
}这里调用了Unsafe类的getAndAddInt()方法,传入了三个参数,分布是AtomicInteger自己的对象引用,valueOffset值的地址偏移量,delta我们传入要添加的值
valueOffset的地址偏移量的获取如下,通过 Unsafe 类的 objectFieldOffset 方法获得,也就是需要修改的具体内存地址,我们这里是修改AtomicInteger内部的一个value值:

我们接下来继续深入Unsafe类的getAndAddInt()方法,Unsafe类在sun.misc包中。我们继续根据方法中看源码:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}首先,在这个方法中采用了do-while循环,通过getIntVolatile(var1, var2)获取当前对象指定的字段值,并将其存入var5中作为预期值,这里的getIntVolatile方法可以保证读取的可见性(禁止指令重拍和CPU缓存,这个之前的文章里解释过,不然冗述);
然后,在while中调用了Unsafe类的compareAndSwapInt()方法,进行数据的CAS操作。其实在这个类中有好几个CAS操作的实现方法,如下:
/**
* CAS
* @param o 包含要修改field的对象
* @param offset 对象中某field的偏移量
* @param expected 期望值
* @param update 更新值
* @return true | false
*/
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object update);
public final native boolean compareAndSwapInt(Object o, long offset, int expected,int update);
public final native boolean compareAndSwapLong(Object o, long offset, long expected, long update);看一看到这几个方法都被native修饰,都是native方法,相关的实现是通过 C++ 内联汇编的形式实现的(JNI 调用),因此,和cpu与操作系统都有关系,所以经常说CAS失败后,大量自旋会带来CPU消耗严重的原因。
当我们进入到compareAndSwapInt(var1, var2, var5, var5 + var4)方法中来,我们通过var1对象在var2内存地址上的值与先查到的预期值比较一致性,若相等,则将var5 + var4更新到对应地址上,返回true,否则不做任何操作返回false。CAS操作也是读取值,比较值,修改值这几步,但是因为CAS是一条CPU原子指令,在执行过程中不允许被中断,就不会存在原子性问题。
如果 CAS 操作成功,说明我们成功地将 var1 对象的 var2 偏移量处的字段的值更新为 var5 + var4,并且这个更新操作是原子性的,因此我们跳出循环并返回原来的值 var5。
如果 CAS 操作失败,说明在我们尝试更新值的时候,有其他线程修改了该字段的值,所以我们继续循环,重新获取该字段的值,然后再次尝试进行 CAS 操作。
5. CAS算法带来的三大问题
文章写到这里,终于进入了关键,CAS虽然作为一种不加锁就可以实现高效同步的手段,但它并非完美,仍然存在着很多问题,主要分为三个,分别是:ABA问题、长时间自旋、多个共享变量的原子操作,这三个问题也是面试官提及CAS时常问的,希望大家能够理解记住。
5.1. ABA问题
这是CAS非常经典的问题,由于CAS是否执行成功,是需要将当前内存中的值与期望值做判断,根据是否相等,来决定是否修改原值的,若一个变量V在初始时的值为A,在赋值前去内存中检查它的值依旧是A,这时候我们就想当然认为它没有变过,然后就继续进行赋值操作了,很明显这里是有漏洞的,虽然赋值的操作用时可能很短,但在高并发时,这个A值仍然有可能被其他线程改为了B之后,又被改回了A,那对于我们最初的线程来说,是无法感知的。
很多人可能会问,既然这个变量从A->B->A,这个过程中,它不还是原来的值吗,过程不同但结果依旧没变呀,会导致什么问题呢?我们看下面这个例子:
小明在提款机,提取了50元,因为提款机卡住了,小明点击后,又点击了一次,产生了两个修改账户余额的线程(可以看做是线程1和线程2),假设小明账户原本有100元,因此两个线程同时执行把余额从100变为50的操作。 线程1(提款机):获取当前值100,期望更新为50。 线程2(提款机):获取当前值100,期望更新为50。 线程1成功执行,CPU并没有调度线程2执行, 这时,小华给小明转账50,这一操作产生了线程3,CPU调度线程3执行,这时候线程3成功执行,余额变为100。之后,线程2被CPU调度执行,此时,获取到的账户余额是100,CAS操作成功执行,更新余额为50!此时可以看到,实际余额应该为100(100-50+50),但是实际上变为了50(100-50+50-50)。
这就是ABA问题带来的错误,而对于一个金融公司来说,发生这种问题可以说是灾难性的,会大大降低客户对于这家银行的信任程度!
在JDK1.5之后加入了版本号机制解决Atomic原子类下的ABA问题,我们每次更新原子类中的value的同时也要更新版本号,修改的时候,不止要比较修改值有没有变,还要比较版本号有没有变
5.2. 长时间自旋
我们在前面说过CAS适用于读多写少的场景,若被使用在写多的场景,必然会产品大量的版本号不一致情况,从而导致很多线程自旋等待,这对CPU来说很糟糕,让JVM 能支持处理器提供的 pause 指令,这样对效率会有一定的提升。
PAUSE指令提升了自旋等待循环(spin-wait loop)的性能。当执行一个循环等待时,Intel P4或Intel Xeon处理器会因为检测到一个可能的内存顺序违规(memory order violation)而在退出循环时使性能大幅下降。PAUSE指令给处理器提了个醒:这段代码序列是个循环等待。处理器利用这个提示可以避免在大多数情况下的内存顺序违规,这将大幅提升性能。因为这个原因,所以推荐在循环等待中使用PAUSE指令。
5.3. 多个共享变量的原子操作
当对一个共享变量执行操作时,CAS 能够保证该变量的原子性。但是对于多个共享变量,CAS 就无法保证操作的原子性,这时通常有两种做法:
- 使用AtomicReference类保证对象之间的原子性,把多个变量放到一个对象里面进行 CAS 操作;
- 使用锁。锁内的临界区代码可以保证只有当前线程能操作。
6. 总结
CAS(Compare And Swap)作为一种无锁编程技术,被广泛应用于Java的并发编程中。它通过利用CPU指令在操作数据时先比较内存值是否发生变化,如未变化则更新,否则重试循环直到成功为止,从而实现非阻塞的原子操作。
CAS操作的优势在于避免了传统悲观锁导致的线程阻塞和切换开销,适用于读操作远多于写操作的应用场景。但它也存在着经典的ABA问题、无法保证多个共享变量的原子性以及在高并发写操作时自旋会导致CPU时钟周期浪费等缺陷。
在JDK1.5之后,通过版本号机制来解决了ABA问题。对于长时间自旋的问题,我们可以通过让JVM 能支持处理器提供的 pause 指令。对于多个共享变量之间的原子操作,我们可以结合其他数据结构或同步机制来实现。