大家好,最近看到京东云的一位大佬分享的接口优化方案,感觉挺不错的,拿来即用。建议收藏一波或者整理到自己的笔记本中,随时查阅!
下面是正文。
一、背景
针对老项目,去年做了许多降本增效的事情,其中发现最多的就是接口耗时过长的问题,就集中搞了一次接口性能优化。本文将给小伙伴们分享一下接口优化的通用方案。
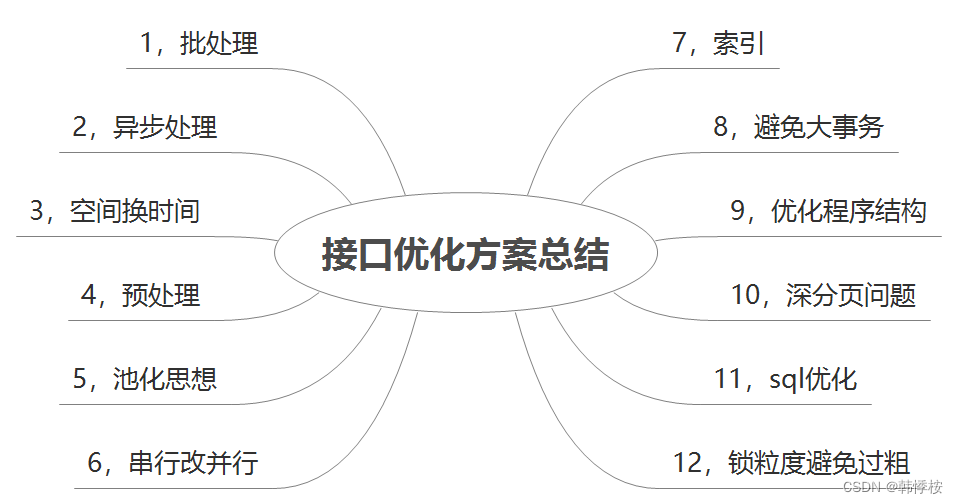
二、接口优化方案总结
2.1.批处理
批量思想:批量操作数据库,这个很好理解,我们在循环插入场景的接口中,可以在批处理执行完成后一次性插入或更新数据库,避免多次 IO。
//for循环单笔入库
list.stream().forEatch(msg->{
insert();
});
//批量入库
batchInsert();
2.2. 异步处理
异步思想:针对耗时比较长且不是结果必须的逻辑,我们可以考虑放到异步执行,这样能降低接口耗时。
例如一个理财的申购接口,入账和写入申购文件是同步执行的,因为是 T+1 交易,后面这两个逻辑其实不是结果必须的,我们并不需要关注它的实时结果,所以我们考虑把入账和写入申购文件改为异步处理。如图所示:

至于异步的实现方式,可以用线程池,也可以用消息队列,还可以用一些调度任务框架。
2.3. 空间换时间
一个很好理解的空间换时间的例子是合理使用缓存,针对一些频繁使用且不频繁变更的数据,可以提前缓存起来,需要时直接查缓存,避免频繁地查询数据库或者重复计算。
需要注意的事,这里用了合理二字,因为空间换时间也是一把双刃剑,需要综合考虑你的使用场景,毕竟缓存带来的数据一致性问题也挺令人头疼。
这里的缓存可以是 R2M,也可以是本地缓存、memcached,或者 Map。
举一个股票工具的查询例子:
因为策略轮动的调仓信息,每周只更新一次,所以原来的调接口就去查库的逻辑并不合理,而且拿到调仓信息后,需要经过复杂计算,最终得出回测收益和跑赢沪深指数这些我们想要的结果。如果我们把查库操作和计算结果放入缓存,可以节省很多的执行时间。如图:

2.4. 预处理
也就是预取思想,就是提前要把查询的数据,提前计算好,放入缓存或者表中的某个字段,用的时候会大幅提高接口性能。跟上面那个例子很像,但是关注点不同。
举个简单的例子:理财产品,会有根据净值计算年化收益率的数据展示需求,利用净值去套用年化收益率计算公式计算的逻辑我们可以采用预处理,这样每一次接口调用直接取对应字段就可以了。
2.5. 池化思想
我们都用过数据库连接池,线程池等,这就是池思想的体现,它们解决的问题就是避免重复创建对象或创建连接,可以重复利用,避免不必要的损耗,毕竟创建销毁也会占用时间。
池化思想包含但并不局限于以上两种,总的来说池化思想的本质是预分配与循环使用,明白这个原理后,我们即使是在做一些业务场景的需求时,也可以利用起来。
比如:对象池
2.6. 串行改并行
串行就是,当前执行逻辑必须等上一个执行逻辑结束之后才执行,并行就是两个执行逻辑互不干扰,所以并行相对来说就比较节省时间,当然是建立在没有结果参数依赖的前提下。
比如,理财的持仓信息展示接口,我们既需要查询用户的账户信息,也需要查询商品信息和 banner 位信息等等来渲染持仓页,如果是串行,基本上接口耗时就是累加的。如果是并行,接口耗时将大大降低。
如图:

2.7. 索引
加索引能大大提高数据查询效率,这个在接口设计之出也会考虑到,这里不再多赘述,随着需求的迭代,我们重点整理一下索引不生效的一些场景,希望对小伙伴们有所帮助。
具体不生效场景不再一一举例,后面有时间的话,单独整理一下。

2.8. 避免大事务
所谓大事务问题,就是运行时间较长的事务,由于事务一致不提交,会导致数据库连接被占用,影响到别的请求访问数据库,影响别的接口性能。
举个例子:
@Transactional(value ="taskTransactionManager", propagation =Propagation.REQUIRED, isolation =Isolation.READ_COMMITTED, rollbackFor ={RuntimeException.class,Exception.class})
publicBasicResultpurchaseRequest(PurchaseRecordrecord){
BasicResult result =newBasicResult();
//插入账户任务
taskMapper.insert(ManagerParamUtil.buildTask(record,TaskEnum.Task_type.pension_account.type(),TaskEnum.Account_bizType.purchase_request.type()));
//插入同步任务
taskMapper.insert(ManagerParamUtil.buildTask(record,TaskEnum.Task_type.pension_sync.type(),TaskEnum.Sync_bizType.purchase.type()));
//插入影像件上传任务
taskMapper.insert(ManagerParamUtil.buildTask(record,TaskEnum.Task_type.pension_sync.type(),TaskEnum.Sync_bizType.cert.type()));
result.setInfo(ResultInfoEnum.SUCCESS);
return result;
}
上面这块代码主要是申购申请完成后,执行一系列的后续操作,如果现在新增申购完成后,发送 push 通知用户的需求。很有可能我们会在后面直接追加,如下图所示:事务中嵌套 RPC 调用,即非 DB 操作,这些非 DB 操作如果耗时较大的话,可能会出现大事务问题。大数据引发的问题主要有:死锁、接口超时、主从延迟等。
@Transactional(value ="taskTransactionManager", propagation =Propagation.REQUIRED, isolation =Isolation.READ_COMMITTED, rollbackFor ={RuntimeException.class,Exception.class})
publicBasicResultpurchaseRequest(PurchaseRecordrecord){
BasicResult result =newBasicResult();
...
pushRpc.doPush(record);
result.setInfo(ResultInfoEnum.SUCCESS);
return result;
}
所以为避免大事务问题,我们可以通过以下方案规避:
- RPC 调用不放到事务里面
- 查询操作尽量放到事务之外
- 事务中避免处理太多数据
2.9. 优化程序结构
程序结构问题一般出现在多次需求迭代后,代码叠加形成。会造成一些重复查询、多次创建对象等耗时问题。在多人维护一个项目时比较多见。解决起来也比较简单,我们需要针对接口整体做重构,评估每个代码块的作用和用途,调整执行顺序。
2.10. 深分页问题
深分页问题比较常见,分页我们一般最先想到的就是 limit ,为什么会慢,我们可以看下这个 SQL:
select*from purchase_record where productCode ='PA9044'andstatus=4orderby orderTime desclimit100000,200
limit 100000,200 意味着会扫描 100200 行,然后返回 200 行,丢弃掉前 100000 行。所以执行速度很慢。一般可以采用标签记录法来优化,比如:
select*from purchase_record where productCode ='PA9044'andstatus=4and id >100000limit200
这样优化的好处是命中了主键索引,无论多少页,性能都还不错,但是局限性是需要一个连续自增的字段
2.11.SQL 优化
sql 优化能大幅提高接口的查询性能,由于本文重点讲述接口优化的方案,具体 sql 优化不再一一列举,小伙伴们可以结合索引、分页、等关注点考虑优化方案。
2.12. 锁粒度避免过粗
锁一般是为了在高并发场景下保护共享资源采用的一种手段,但是如果锁的粒度太粗,会很影响接口性能。
关于锁粒度:就是你要锁的范围有多大,不管是 synchronized 还是 redis 分布式锁,只需要在临界资源处加锁即可,不涉及共享资源的,不必要加锁,就好比你要上卫生间,只需要把卫生间的门锁上就可以,不需要把客厅的门也锁上。
错误的加锁方式:
//非共享资源
privatevoidnotShare(){
}
//共享资源
privatevoidshare(){
}
privateintwrong(){
synchronized(this){
share();
notShare();
}
}
正确的加锁方式:
//非共享资源
privatevoidnotShare(){
}
//共享资源
privatevoidshare(){
}
privateintright(){
notShare();
synchronized(this){
share();
}
}
三、最后
我相信很多接口的效率问题不是一朝一夕形成的,在需求迭代的过程中,为了需求快速上线,采取直接累加代码的方式去实现功能,这样会造成以上这些接口性能问题。
变换思路,更高一级思考问题,站在接口设计者的角度去开发需求,会避免很多这样的问题,也是降本增效的一种行之有效的方式。