目录
- 1 调优概述
- 2 数据倾斜发生时的现象
- 3 数据倾斜发生的原理
- 4 如何定位导致数据倾斜的代码
-
- 4.1 某个 task 执行特别慢的情况
- 4.2 某个 task 莫名其妙内存溢出的情况
- 5 查看导致数据倾斜的 key 的数据分布情况
- 6 数据倾斜的解决方案
-
- 6.1 使用 Hive ETL 预处理数据
- 6.2 过滤少数导致倾斜的 key
- 6.3 提高 shuffle 操作的并行度
- 6.4 两阶段聚合(局部聚合+全局聚合)
- 6.5 将 reduce join 转为 map join
- 6.6 采样倾斜 key 并分拆 join 操作
- 6.7 使用随机前缀和扩容 RDD 进行 join
1 调优概述
有的时候,我们可能会遇到大数据计算中一个最棘手的问题 —— 数据倾斜,此时 Spark 作业的性能会比期望差很多。数据倾斜调优,就是使用各种技术方案解决
不同类型的数据倾斜问题,以保证 Spark 作业的性能。
2 数据倾斜发生时的现象
绝大多数 task 执行得都非常快,但个别 task 执行极慢。比如,总共有 1000 个
task,997 个 task 都在 1 分钟之内执行完了,但是剩余两三个 task 却要一两个
小时。这种情况很常见。原本能够正常执行的 Spark 作业,某天突然报出 OOM(内存溢出)异常,观察异常栈,是我们写的业务代码造成的。这种情况比较少见。
3 数据倾斜发生的原理
数据倾斜的原理很简单:在进行 shuffle 的时候,必须将各个节点上相同的 key
拉取到某个节点上的一个 task 来进行处理,比如按照 key 进行聚合或 join 等操
作。此时如果某个 key 对应的数据量特别大的话,就会发生数据倾斜。比如大部分 key 对应 10 条数据,但是个别 key 却对应了 100 万条数据,那么大部分 task
可能就只会分配到 10 条数据,然后 1 秒钟就运行完了;但是个别 task 可能分配
到了 100 万数据,要运行一两个小时。因此,整个 Spark 作业的运行进度是由运
行时间最长的那个 task 决定的。
因此出现数据倾斜的时候,Spark 作业看起来会运行得非常缓慢,甚至可能因为
某个 task 处理的数据量过大导致内存溢出。
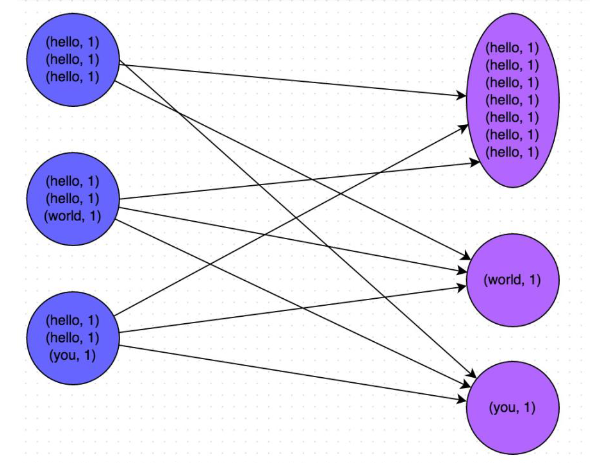
下图就是一个很清晰的例子:hello 这个 key,在三个节点上对应了总共 7 条数
据,这些数据都会被拉取到同一个 task 中进行处理;而 world 和 you 这两个 key
分别才对应 1 条数据,所以另外两个 task 只要分别处理 1 条数据即可。此时第
一个 task 的运行时间可能是另外两个 task 的 7 倍,而整个 stage 的运行速度也
由运行最慢的那个 task 所决定。
4 如何定位导致数据倾斜的代码
数据倾斜只会发生在 shuffle 过程中。常用的并且可能会触
发 shuffle 操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、
join、cogroup、repartition 等。出现数据倾斜时,可能就是你的代码中使用
了这些算子中的某一个所导致的。
4.1 某个 task 执行特别慢的情况
首先要看的,就是数据倾斜发生在第几个 stage 中。
- 如果是用
yarn-client模式提交,那么本地是直接可以看到 log 的,可以在 log 中找到当前运行到了第几个stage; - 如果是用
yarn-cluster模式提交,则可以通过 Spark Web UI 来查看当前运行到了第几个 stage。
补充知识:driver 主要负责管理整个集群的作业任务调度,executor 是一个JVM进程,专门用于计算的节点。在
yarn-client模式下,driver运行在客户端,在yarn-cluster模式下,driver运行在yarn集群。
此外,无论是使用 yarn-client 模式还是 yarn-cluster 模式,我们都可以在
Spark Web UI 上深入看一下当前这个 stage 各个 task 分配的数据量,从而进一
步确定是不是 task 分配的数据不均匀导致了数据倾斜。
比如下图中,倒数第三列显示了每个 task 的运行时间。明显可以看到,有的 task
运行特别快,只需要几秒钟就可以运行完;而有的 task 运行特别慢,需要几分
钟才能运行完,此时单从运行时间上看就已经能够确定发生数据倾斜了。此外,
倒数第一列显示了每个 task 处理的数据量,明显可以看到,运行时间特别短的
task 只需要处理几百 KB 的数据即可,而运行时间特别长的 task 需要处理几千
KB 的数据&


![Amazon云计算AWS之[5]关系数据库服务RDS](https://img-blog.csdnimg.cn/direct/c7e33d19d32141df9eeb3f9714c4bd2e.png)