论文:Dense Passage Retrieval for Open-Domain Question Answering
⭐⭐⭐⭐⭐
EMNLP 2020, Facebook Research
Code: github.com/facebookresearch/DPR
文章目录
- 一、论文速读
- 二、DPR 的训练
- 2.1 正样本和负样本的选取
- 2.2 In-batch negatives 技巧
- 三、实验
- 3.1 数据集的选用
- 3.2 使用的模型
- 3.3 Main Result
- 3.4 模型训练的消融实验
- 3.5 DPR 对比 BM25
- 四、总结
一、论文速读
本篇文章提出的 DPR 模型是最早提出使用嵌入向量来实现文档检索的模型,也是目前 RAG 中 Retriever 的经典实现方案。
在文档检索上,有两大流派:
- Sparse Retrieval:使用 TF-IDF 或者 BM25 来实现检索
- Dense Retrieval:向量检索
本文的 DPR 就属于 dense retrieval。
问题形式:我们有一堆文档 D = { d 1 , d 2 , … , d D } D = \{ d_1, d_2, \dots, d_D \} D={d1,d2,…,dD},将这里面的每个文档切分为多个等长的 passages,passage 就是检索结果的基本单元。这些切分后的 passages 构成了我们的 corpus C = { p 1 , p 2 , … , p M } C = \{ p_1, p_2, \dots, p_M \} C={p1,p2,…,pM}。而我们的任务是,给定一个 question q q q,我们需要返回与其相关的 passage 集合 C F ∈ C C_F \in C CF∈C。
DPR 是一个 dual-encoder 架构,也就是包含两个 encoder:
- passage encoder E P ( ⋅ ) E_P(\cdot) EP(⋅):是一个 BERT,将任意的 passage 映射为 d d d 维的 embedding 向量
- question encoder E Q ( ⋅ ) E_Q(\cdot) EQ(⋅):也是一个 BERT,将一个 question 映射为 d d d 维的 embedding 向量
首先,DPR 会使用 encoder E P E_P EP 将 corpus 中的所有 passage 映射为 embedding 向量,并存入 FAISS 中离线构建向量索引,之后在运行时,对于到来的一个 user question,先使用 encoder E Q E_Q EQ 将其映射为 embedding 向量,然后通过比较 question embedding 和所有的 passage embedding 的相似性,选出 top-k 个 passages 作为检索结果。
这里计算两个 embedding 相似性使用的是向量点积:
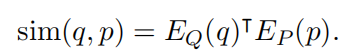
二、DPR 的训练
训练目标:找到这样一个向量空间,在这里面相关的 question 和 passage 比不相关的具有更高的相似度。
训练样本的形式:每一个 training data 的 instance 包含一个 question q i q_i qi、一个正样本 positive passage p i + p_i^+ pi+ 以及 n 个负样本 negative passages p i , j − p_{i,j}^- pi,j−
损失函数:最小化正样本的负对数似然:
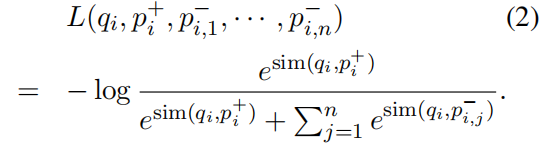
2.1 正样本和负样本的选取
positive passage 比较好选,这往往是 QA 数据集已经给定了,或者可以从 answer 中找到。
而 negative passages 就比较难选了,负样本的使用是为了提高模型识别不相关文档的能力,这就需要让负样本多样化。在这篇论文中,考虑了以下三种类型的负样本类型:
- Random Negatives:从整个文档集合中随机选择的文档作为负样本。
- BM25 Negatives:使用BM25检索系统根据问题检索到的,但不包含答案的文档作为负样本。
- Gold Negatives:来自训练集中,与当前问题不匹配的正样本(即其他问题的正样本)作为负样本。
Gold Negatives 的 Gold 指的是这个样本是高质量的负样本,是特意选出来与当前问题不相关的样本。
2.2 In-batch negatives 技巧
这是一个在语义理解(向量索引)技术中的常见的训练技巧。
以如下 Batch size=4 的训练数据为例:
我手机丢了,我想换个手机 我想买个新手机,求推荐
求秋色之空漫画全集 求秋色之空全集漫画
学日语软件手机上的 手机学日语的软件
侠盗飞车罪恶都市怎样改车 侠盗飞车罪恶都市怎么改车
In-batch Negatives 策略的训练数据为语义相似的 Pair 对,策略核心是在 1 个 Batch 内同时基于 N 个负例进行梯度更新,将同一 Batch 内除自身之外其它所有 Source Text 的相似文本 Target Text 作为负例,例如: 上例中“我手机丢了,我想换个手机” 有 1 个正例(”我想买个新手机,求推荐“),3 个负例(1.求秋色之空全集漫画,2.手机学日语的软件,3.侠盗飞车罪恶都市怎么改车)。
具体来说,In-batch negatives策略的实施步骤如下:
- 选择正样本:首先从当前批次中选择出一个正样本,这个样本是模型需要正确识别的目标样本。
- 选择负样本:然后从同一批次中随机选择或根据特定规则选择一些负样本。这些负样本可以是与正样本相似但被错误标记的样本,也可以是完全不相关的样本。
- 模型训练:将正样本和负样本一起输入模型进行训练。模型需要学会区分正样本和负样本,从而提高推荐或检索的准确性。
In-batch negatives 策略的优势在于:
- 提高模型的区分能力:通过在每个批次中引入负样本,模型被迫学习如何区分正样本和负样本,这有助于提高模型的泛化能力和区分度。
- 利用现有数据:不需要额外的负样本库,可以直接利用当前批次中的数据作为负样本,这在数据有限的情况下尤其有用。
- 减少计算资源消耗:与从全局样本集中采样负样本相比,In-batch negatives可以减少计算资源的消耗,因为它避免了在整个数据集上进行负采样的需要。
然而,In-batch negatives 策略也存在一些潜在的问题,例如:
- 批次大小的限制:如果批次大小较小,可能无法提供足够多样化的负样本,这可能影响模型的学习效果。
- 偏差问题:由于负样本是在同一个批次中选择的,可能会出现某些样本被频繁选为负样本的情况,这可能导致模型学习到的表示存在偏差。
In-batch negatives 已被证明是一个有效的训练 dual-encoder 模型的方法。
In-batch negatives 的更多资料:https://github.com/paddlepaddle/PaddleNLP/tree/develop/applications/neural_search/recall/in_batch_negative
三、实验
文章做了两大类实验:Passage Retrieval 和 Question Answering,在这里我们主要关注 Passage Retrieval 上的实验。
3.1 数据集的选用
学习一下这里是如何构建数据集的。
本工作通过预处理从 Wikipedia 中获取到 21,015,324 篇 passages,然后使用了多个 QA 数据集来构建本工作所用数据:
- Natural Question(NQ)
- TriviaQA
- WebQuestion(WQ)
- CuratedTREC(TREC)
- SQuAD v1.1
具体关于数据集的详细信息,可以参考原论文。
之后,本论文工作从这些数据集中构建出本文模型所需要使用的数据,针对 QA 中的每一个 question,本文使用了 BM25 来检索出相关的 passages,并将最高排名的 passage 作为 positive passage。
3.2 使用的模型
主要使用了三个模型来进行实验:
- BM25:经典的 sparse retrieval 的模型
- DPR:本文的模型
- BM25 + DPR:先分别让 BM25 和 DPR 独立运行,然后将两者的输出进行聚合,使用某种线性组合或者重排序(reranking)策略来得到最终的检索列表。
3.3 Main Result
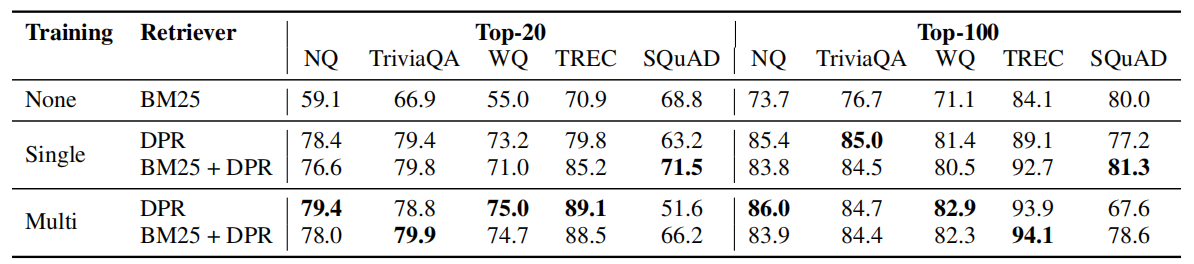
可以看到,除了 SQuAD 数据集,DPR 模型都表现比 BM25 效果好。
作者还给出了 DPR 在 SQuAD 数据集上表现不如 BM25 的原因,是认为这个数据集是注释者在看到文章后写下问题。因此,段落和问题之间有很高的词汇重叠,这给 BM25 带来了明显的优势。其次,数据仅从500多篇维基百科文章中收集,因此训练示例的分布极有偏见。
3.4 模型训练的消融实验
分别针对以下部分做了消融实验,这里仅列出一些结论,具体可以参考原论文:
- Sample efficiency:作者发现,少量的训练样本就可以让 DPR 的表现超过 BM25,并且随着样本的增多,DPR 的表现也在变得更好。
- In-batch negative training:作者发现负样本的选择方式(前面介绍了三种)对模型表现影响不大
- Impact of gold passages:作者将 gold positive passage 作为正样本和将 BM25 选出来的最靠前的 passage 作为正样本继续了对比,发现前者表现更好。
- Similarity and loss:选择 L2 distance 作为相似性函数并相应的修改 loss func 后,并不会太影响模型的结果
- Cross-dataset generalization:将模型在 NQ 上训练后直接用于其他 QA Dataset 的实验,发现效果还不错,说明了 DPR 的检索能力具备通用性。
3.5 DPR 对比 BM25
这篇论文虽然实验说明 DPR 在数据集上表现比 BM25 要好,但在实际中,两者有着不同的适用场景:
- BM25 这样的术语匹配方法对高度选择性的关键词和短语很敏感
- DPR 更好地捕捉词汇变化或语义关系
两者的效率也有明显的区别:
- 在运行时,有 FAISS 的帮助下,DPR 的吞吐量比 BM25 明显要高
- 但在预先构建索引阶段,DPR 向量化所有 passages 需要花费大量的时间(论文使用了 8.5h
- ),而 BM25 的工业实现 Lucene 可以很快完成(论文使用了 30min)
这里的具体数据可以参考原论文。
四、总结
DPR 是密集向量检索的经典实现方式之一,目前也还有大量基于它的思路来实现的,对这个模型进行认真学习很有必要。