YOLOv9最新改进系列:完美融合即插即用的涨点模块之注意力机制(SEAttention)。
YOLOv9原文链接戳这里,原文全文翻译请关注B站Ai学术叫叫首er
B站全文戳这里!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
YOLOv9最新改进系列:完美融合即插即用的涨点模块之注意力机制(SEAttention)!
- YOLOv9最新改进系列:完美融合即插即用的涨点模块之注意力机制(SEAttention)。
- 摘要
- 1 SENet结构
- 2 SENet计算流程
- 3 SENet参数
- 4 代码讲解
- 5 结论
- 6 修改步骤!
- 6.1 修改YAML文件
- 6.2 新建.py
- 6.3 修改tasks.py
- 7、验证是否成功即可
SE(提出原文戳这)
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
截止到发稿时,B站YOLOv9最新改进系列的源码包,已更新了11种的改进!自己排列组合2-4种后,考虑位置不同后可排列组合上千种!!专注AI学术,关注B站博主:Ai学术叫叫兽er!
摘要
什么是通道特征?通道特征(Channel Features)是指卷积神经网络(CNN)中每个卷积核产生的输出。一个通道对应于网络中的一个卷积核,而每个通道的输出表示该卷积核在输入上的响应。通道特征捕捉了输入数据中不同方面的抽象信息。每个通道对应于某种特定的抽象特征,例如纹理、颜色、边缘等。通道特征在整个网络中负责提取和表示不同层次的信息。
什么是通道注意力机制?通道注意力机制(Channel Attention Mechanism)是深度学习中一种用于增强通道特征捕捉能力的注意力机制。它主要应用于卷积神经网络(CNN)中,以提高模型对不同通道(channel)的特征的关注度,从而使网络更加有效地学习和利用输入数据的信息。在通道注意力机制中,通过学习每个通道的权重,模型可以在处理特定通道的特征时给予更多的注意力。这有助于网络在学习过程中更好地区分不同通道的重要性,从而提高模型对输入数据的表示能力。
1 SENet结构
SENet是一种通道注意力机制,结构如图1所示。SE注意力模块,由Squeeze操作、Excitation操作、Scale操作三部分组成。Squeeze操作:对输入的特征图进行全局平均池化,将每个通道的特征值降维为一个全局向量。这一步旨在捕捉每个通道的全局信息。Excitation操作:由两个全连接和一个ReLU激活函数、一个Softmax激活函数组成,先进行降维在升维,最后通过sigmoid函数生成权重向量,确保它们的总和为1。Scale操作:将上一步得到的通道注意力权重乘以输入的原始特征图。这一步用于调整每个通道的特征值,强调重要通道的信息,抑制不重要通道的信息。SE注意力模块与Inception、ResNet的结合,分别如图2、图3所示。
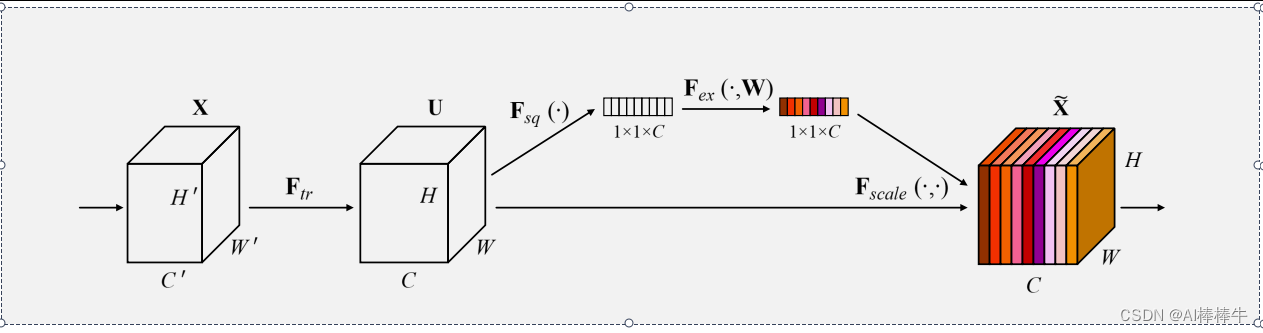

2 SENet计算流程
如图1所示,给定一个输入X∈H’×W’×C’ ,通过一个卷积变化Ftr 得到 U∈H×W×C 。将特征U 经过Squeeze操作Fsq 在空间维度H×W 上聚合特征得到Z∈1×1×C 。接下来进行Excitation操作,得到s。其中W1 、W2 为全连接层后的权重,δ 为ReLU函数,σ 为Sigmoid函数。
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
最后进行Scale操作,将特征U和特征s相乘得到x,通过相乘,注意力机制可以对每个通道进行更细粒度的权重调整,将更多的注意力集中在对任务更为关键的通道上。从而调整该特征值的重要性。这个过程使得网络更加关注那些在给定任务中对应通道上重要的特征。
x=Fscale (U,s)=U⋅s
3 SENet参数
利用thop库的profile函数计算FLOPs和Param。Input:(512,7,7)。

4 代码讲解
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
def __init__(self, channel=512, reduction=16):
super().__init__()
# 在空间维度上,将H×W压缩为1×1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 包含两层全连接,先降维,后升维。最后接一个sigmoid函数
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
# (B,C,H,W)
B, C, H, W = x.size()
# Squeeze: (B,C,H,W)-->avg_pool-->(B,C,1,1)-->view-->(B,C)
y = self.avg_pool(x).view(B, C)
# Excitation: (B,C)-->fc-->(B,C)-->(B, C, 1, 1)
y = self.fc(y).view(B, C, 1, 1)
# scale: (B,C,H,W) * (B, C, 1, 1) == (B,C,H,W)
out = x * y
return out
if __name__ == '__main__':
from torchsummary import summary
from thop import profile
model = SEAttention(channel=512, reduction=8)
summary(model, (512, 7, 7), device='cpu')
flops, params = profile(model, inputs=(torch.randn(1, 512, 7, 7),))
print(f"FLOPs: {flops}, Params: {params}")
…详情见原文!
5 结论
在本文中,我们提出了 SE 块,这是一种架构单元,旨在通过使其能够执行动态通道特征重新校准来提高网络的表示能力。 广泛的实验证明了 SENet 的有效性,它在多个数据集和任务中实现了最先进的性能。 此外,SE 模块揭示了以前的架构无法充分模拟通道特征依赖性的问题。 我们希望这种见解对于需要强区分性特征的其他任务可能有用。 最后,SE 块生成的特征重要性值可能可用于其他任务,例如用于模型压缩的网络修剪。
6 修改步骤!
6.1 修改YAML文件
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
6.2 新建.py
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽er 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
6.3 修改tasks.py
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽er 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
7、验证是否成功即可
执行命令
python train.py
改完收工!
关注B站:Ai学术叫叫兽er
从此走上科研快速路
遥遥领先同行!!!!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽er 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!