🔥个人主页:Quitecoder
🔥专栏:c++笔记仓

朋友们大家好,本篇文章我们来到STL新的内容,stack和queue
目录
- 1. stack的介绍与使用
- `函数介绍`
- `例题一:最小栈`
- `例题二:栈的压入、弹出队列`
- `栈的模拟实现`
- 2.queue的介绍和使用
- `deque的介绍`
- `deque的缺陷`
- `queue的模拟实现`
1. stack的介绍与使用

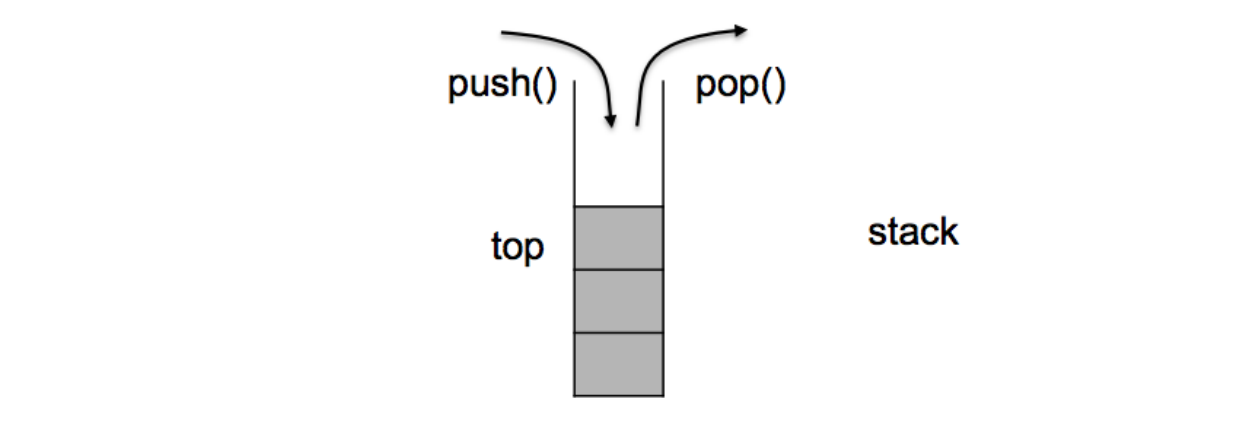
- stack是一种容器适配器,专门用在具有后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入与提取操作。
- stack是作为容器适配器被实现的,容器适配器即是对特定类封装作为其底层的容器,并提供一组特定的成员函数来访问其元素,将特定类作为其底层的,元素特定容器的尾部(即栈顶)被压入和弹出。
- stack的底层容器可以是任何标准的容器类模板或者一些其他特定的容器类,这些容器类应该支持以下操作:
empty:判空操作back:获取尾部元素操作push_back:尾部插入元素操作pop_back:尾部删除元素操作
- 标准容器vector、deque、list均符合这些需求,默认情况下,如果没有为stack指定特定的底层容器,默认情况下使用
deque。
函数介绍
🔥构造函数

explicit stack (const container_type& ctnr = container_type());
这个构造函数定义的是 std::stack 类模板的一个构造函数,它接受一个参数,类型是 container_type。这里的 container_type 是 std::stack 的成员类型,它表示用于内部存储的容器类型,通常是某种顺序容器比如 std::deque、std::list 或 std::vector。
关键字 explicit 表示这个构造函数禁止隐式类型转换。换句话说,你不能隐式地从 container_type 赋值给 std::stack 对象,而必须显式地调用构造函数:
std::deque<int> mydeque(3,100); // deque with 3 elements
std::stack<int> first (mydeque); // stack initialized to copy of deque
上面的代码中,我们创建了一个 std::deque<int> 对象 mydeque,然后使用它显式地构造一个 std::stack<int> 对象 first。如果没有 explicit 关键字,下面的代码也是有效的:
std::stack<int> myStack = mydeque; // 这一行在 explicit 关键字存在时是不合法的
但有 explicit 关键字时,这种隐式转换就会产生编译错误。
构造函数的参数 ctnr 还有一个默认值 container_type()。这表示如果在构造 std::stack 对象时没有提供参数,将会使用 container_type 的默认构造函数创建一个新的空容器作为 std::stack 的内部存储。这允许你像下面这样简单地创建一个空栈:
std::stack<int> myStack; // 空栈,使用默认的底层容器(通常是 std::deque)
在这种情况下,myStack 是空的,因为没有向构造函数传递任何参数,它会使用底层容器类型的默认构造函数创建一个空的内部容器
🔥empty()

检测stack是否为空
🔥size()
返回stack中元素的个数
🔥top()
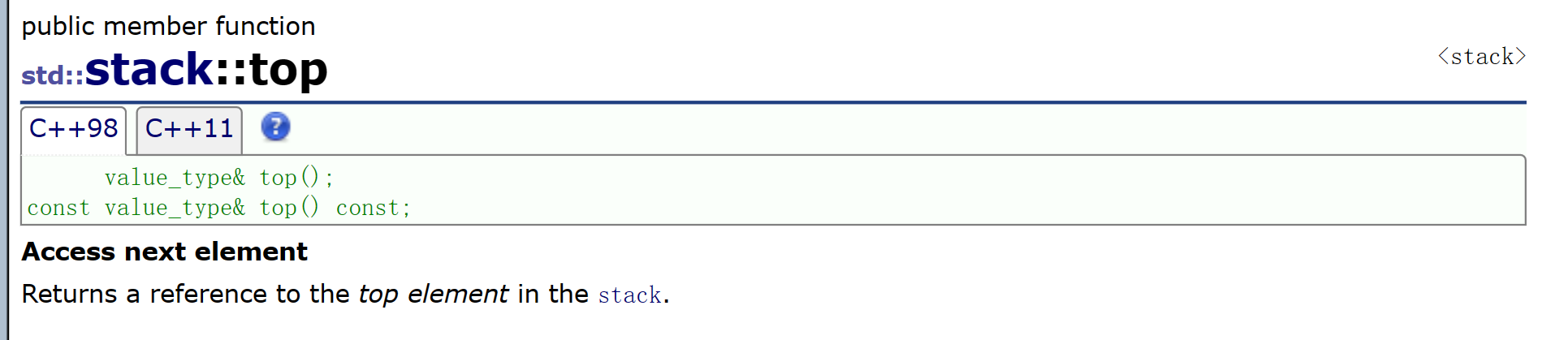
返回栈顶元素的引用
🔥push()

将元素val压入stack中
🔥pop()

将stack中尾部的元素弹出
例题一:最小栈
题目链接:155.最小栈
题目描述:

为了实现上面这个栈,我们需要使用两个栈
stack<int> s1;
stack<int> s2;
s1是一个标准的栈,它用于按照后进先出的顺序存储所有推入的元素s2是一个辅助栈,它用于跟踪s1中所有元素的最小值
-
MinStack():构造函数,初始化两个空栈s1和s2 -
void push(int val):在s1中推入val。如果s2为空或者val小于等于s2的栈顶元素,也将val推入s2。这保证s2的栈顶元素始终是s1中当前所有元素的最小值 -
void pop():从s1中弹出一个元素。如果s1的栈顶元素与s2的栈顶元素相等,说明s1弹出的元素是当前的最小值,因此也需要在s2中弹出栈顶元素 -
int top():返回s1的栈顶元素,即MinStack的栈顶元素 -
int getMin():返回s2的栈顶元素,即s1中当前所有元素的最小值
代码实现如下:
class MinStack {
public:
MinStack() {
}
void push(int val) {
s1.push(val);
if(s2.empty()||s2.top()>=val)
{
s2.push(val);
}
}
void pop() {
if(s1.top()==s2.top())
{
s2.pop();
}
s1.pop();
}
int top() {
return s1.top();
}
int getMin() {
return s2.top();
}
private:
stack<int> s1;
stack<int> s2;
};
例题二:栈的压入、弹出队列
题目链接:牛客
题目描述:

该函数的目的是检查给定的出栈顺序 popV 是否能由相应的入栈顺序 pushV 实现。换句话说,函数判断是否存在某种方式,使得按 pushV 指定的顺序入栈后,能够按 popV 指定的顺序出栈
代码实现如下:
class Solution {
public:
bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {
int pushi=0,popi=0;
stack<int> s;
while(pushi<pushV.size())
{
s.push(pushV[pushi]);
while(!s.empty()&&s.top()==popV[popi])
{
s.pop();
popi++;
}
pushi++;
}
return s.empty();
}
};
函数的实现逻辑如下:
-
初始化两个整型指针
pushi和popi分别为 0,表示入栈和出栈序列的开始索引 -
创建一个辅助的栈
s用于模拟入栈和出栈的过程 -
使用一个
while循环开始模拟入栈的过程,只要pushi没有指向pushV结尾就继续循环 -
在每次循环中,将
pushV中当前位置pushi的元素推入栈s -
然后,使用一个内部
while循环检查此时栈顶元素是否等于popV中相应位置popi的元素:- 如果相等,则从栈
s中弹出栈顶元素,并将popi指针后移一位以检查下一个出栈元素 - 如果不相等或栈已空,则中断内部
while循环
- 如果相等,则从栈
-
在外部
while循环结束一次循环之后,将pushi指针后移一位继续下一轮入栈操作 -
最后,当外部
while循环结束时,检查栈s是否为空:- 如果栈为空,表示所有入栈的元素都能按
popV指定的顺序出栈,返回true。 - 如果栈不为空,表示存在无法按给定出栈顺序出栈的元素,返回
false。
- 如果栈为空,表示所有入栈的元素都能按
栈的模拟实现
namespace own
{
// 设计模式
// 适配器模式 -- 转换
// stack<int, vector<int>> st1;
// stack<int, list<int>> st2;
template<class T, class Container = vector<T>>
class stack
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
const T& top()
{
return _con.back();
}
private:
Container _con;
};
}
上面的实现是简单地展示了如何用C++模板和通用编程的原则来定义一个通用的栈类,这个栈类被称为适配器。在这种上下文中,“适配器模式”是一种设计模式的用词。
在面向对象的设计模式中,适配器模式(Adapter Pattern)通常用来将一个类的接口转换成客户期望的另一个接口。适配器让那些由于接口不兼容而不能一起工作的类可以一起工作
在容器类库设计中(如标准模板库 STL 中的容器),适配器模式通常用于通过已有的容器类型(如vector, deque, list等),来实现某种特定的抽象数据类型(如栈、队列等)的接口。这样的做法使我们能够重用现有代码,并提供更丰富的操作
在上面的代码段中:
- 定义了
stack模板类,它接收两个模板参数:T: 栈中元素的类型。Container: 底层容器的类型,默认是vector<T>
Container是一个模板参数,它允许我们定义底层数据结构。默认使用std::vector<T>作为底层容器,但我们可以指定std::deque<T>、std::list<T>等容器,这是适配器模式的应用之一,我们可以切换不同的底层实现,不改变栈的接口
-
stack类包含如下成员函数:push: 向栈中添加元素pop: 从栈中移除顶部元素size: 返回栈中元素的数量empty: 检查栈是否为空top: 返回栈顶元素的引用
-
这些成员函数中的每一个都直接调用了底层容器
Container实例_con的相应操作函数,这样stack就提供了类似栈的接口
这个适配器堆栈类可以看作是对底层容器的一个封装,它只暴露了限定的一组操作(栈操作),提供了符合 LIFO(后进先出)原则的栈
总结来说,这个
stack类是一个栈适配器,它利用模板为不同的底层容器提供了统一的栈接口。可以选择使用vector、deque或list等容器作为存储机制,并且无需修改外部代码
2.queue的介绍和使用

- 队列是一种容器适配器,专门用于在FIFO上下文(先进先出)中操作,其中从容器一端插入元素,另一端提取元素
- 队列作为容器适配器实现,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从队尾入队列,从队头出队列。
- 底层容器可以是标准容器类模板之一,也可以是其他专门设计的容器类。该底层容器应至少支持以下操作:
empty:检测队列是否为空size:返回队列中有效元素的个数front:返回队头元素的引用back:返回队尾元素的引用push_back:在队列尾部入队列pop_front:在队列头部出队列
- 标准容器类deque和list满足了这些要求。默认情况下,如果没有为queue实例化指定容器类,则使用标准容器deque
| 函数声明 | 接口说明 |
|---|---|
queue() | 构造空的队列 |
empty() | 检测队列是否为空,是返回true,否则返回false |
size() | 返回队列中有效元素的个数 |
front() | 返回队头元素的引用 |
back() | 返回队尾元素的引用 |
push() | 在队尾将元素val入队列 |
pop() | 将队头元素出队列 |
deque的介绍
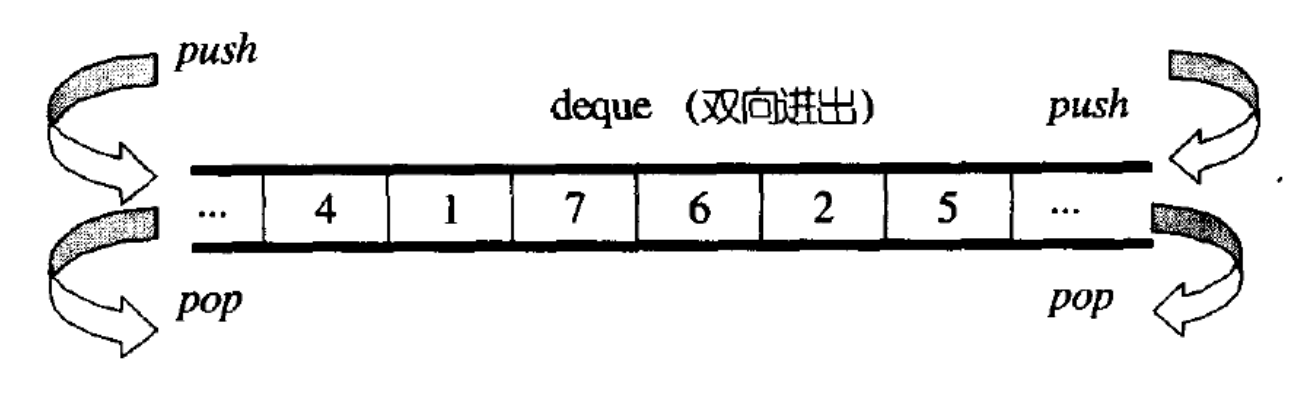
deque 成为双端队列,是一种序列容器,在两端都支持高效的元素插入和删除操作。
与 std::vector 相比,std::deque 提供类似的功能,但在许多实现中,deque 是由多个固定大小的数组(通常被称为块或段)组成的动态数组。这允许在两端进行快速的插入和删除操作,而不必像 std::vector 在插入(或删除)元素时将所有元素向前或向后移动。
deque 的主要特点和功能包括:
-
双端操作:可以在队列的前端和后端进行插入 (
push_front,emplace_front) 和删除 (pop_front) 操作
-
序列访问:可以使用下标操作符 (
operator[]) 或一系列迭代器访问deque中的元素 -
迭代器失效:在两端添加或删除元素通常不会使迭代器失效,但是在
deque中除了首尾外的任何位置插入或删除元素都可能使所有迭代器失效。这取决于具体的实现。 -
内存分配:
deque不保证所有元素都连续存储,因此不能依赖像std::vector那样的内存连续性 -
性能:在两端插入或删除元素通常是常数时间复杂度 O(1),但是在中间位置插入或删除元素的时间复杂度通常是线性的 O(n),这取决于插入位置与最近端点的距离
vector的优点在于能支持下标随机访问,缺点是头部或中间插入删除的效率低,扩容有消耗
list的优点在于任意位置插入删除的效率都不错,缺点就是不支持下标的随机访问
而deque可以看做vector和list的加强版,既支持下标访问,又支持头插头删
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组
std::deque 的常见实现方式是使用一系列的固定大小的数组(称为缓冲区或块),这些数组被指针所管理,这些指针通常保存在一个或多个中央数组中。这种实现允许在 deque 的两端都高效地添加或删除元素,而无需移动所有元素
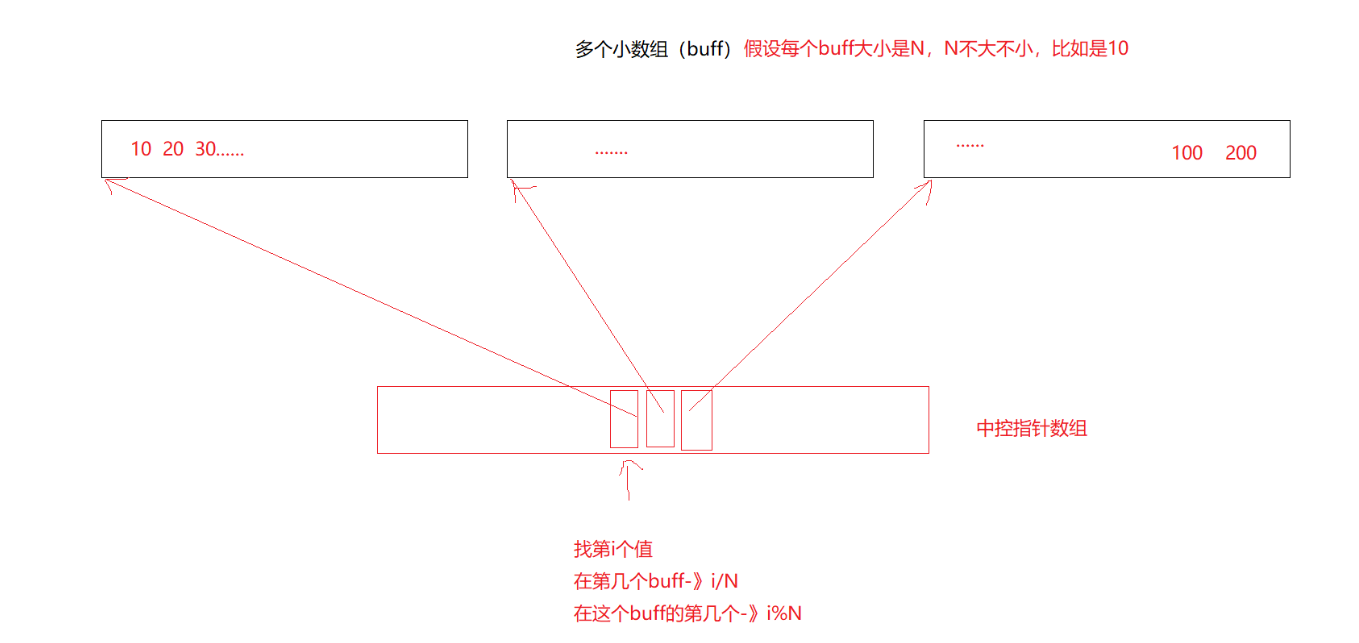
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂
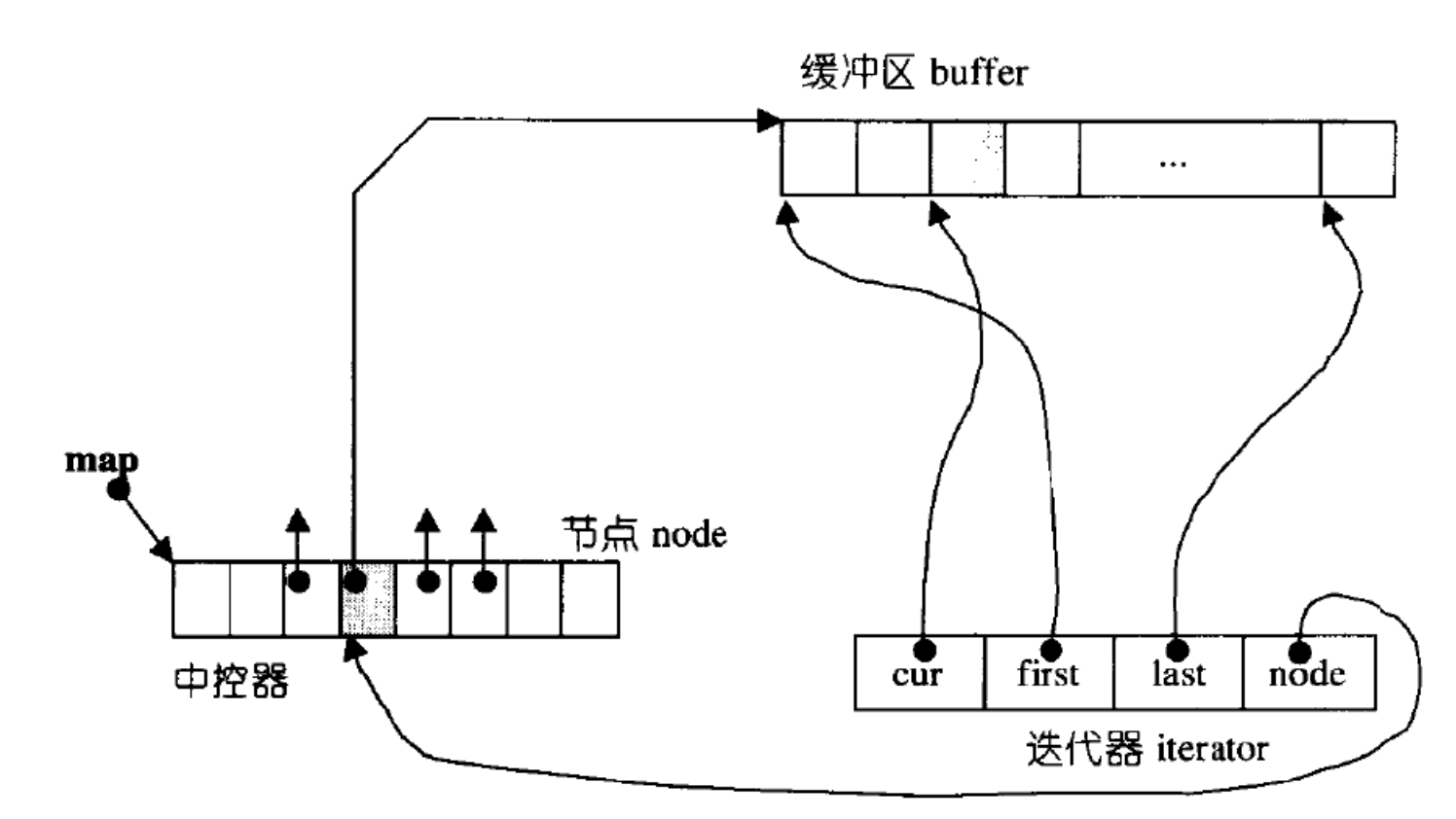
中控数组满了就扩容,它的消耗会小很多
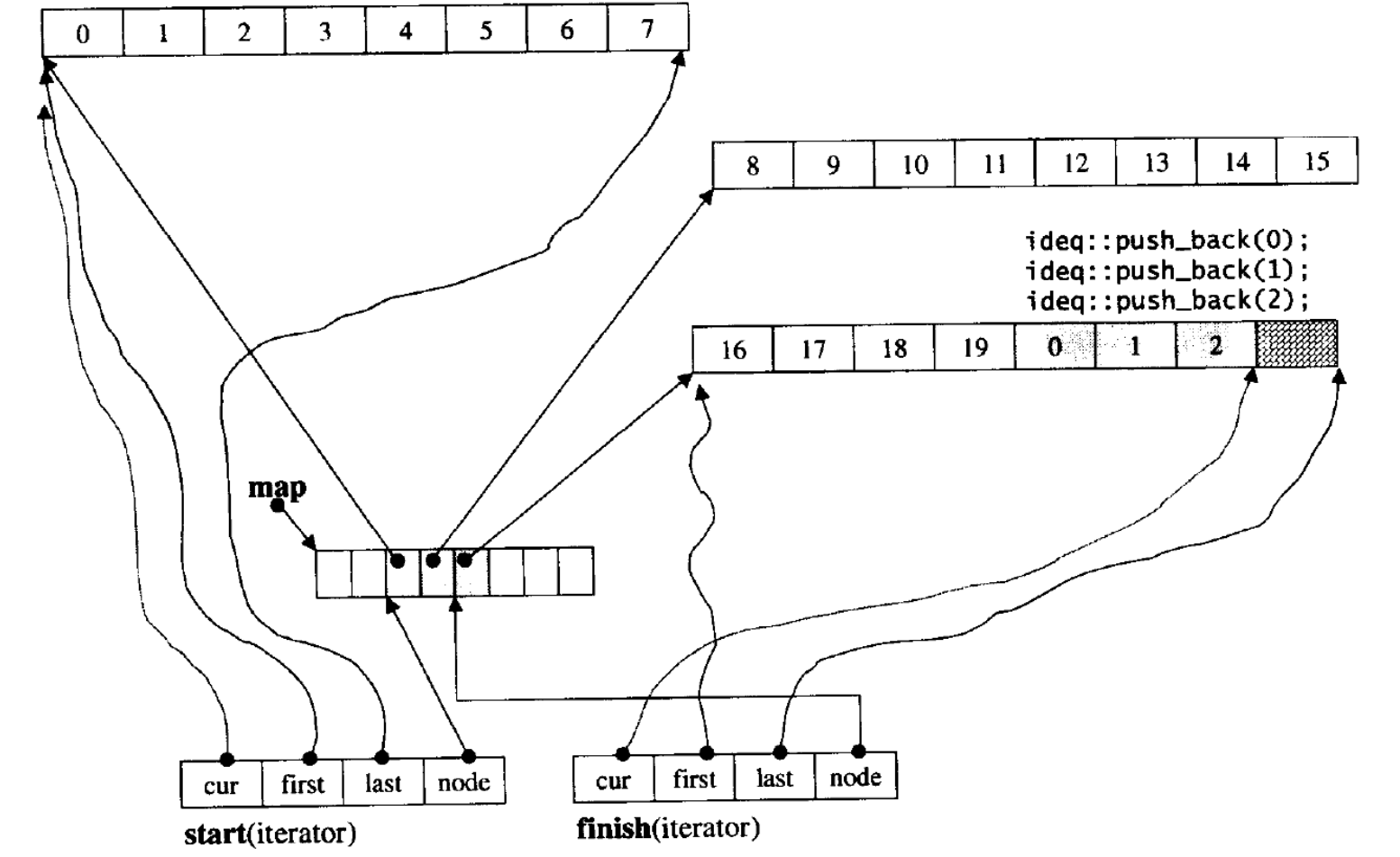
它的迭代器有四个指针
- start指向指向第一个buff的第一个数据
- finish指向最后一个buff的最后一个数据的下一个位置
deque的缺陷
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为
stack和queue的底层数据结构
为什么选择deque作为stack和queue的底层默认容器?
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和
queue默认选择deque作为其底层容器,主要是因为:
- stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高
结合了deque的优点,而完美的避开了其缺陷
queue的模拟实现
#include<deque>
#include<list>
namespace own
{
template<class T, class Con = deque<T>>
class queue
{
public:
queue() {}
void push(const T& x) { _c.push_back(x); }
void pop() { _c.pop_front(); }
T& back() { return _c.back(); }
const T& back()const { return _c.back(); }
T& front() { return _c.front(); }
const T& front()const { return _c.front(); }
size_t size()const { return _c.size(); }
bool empty()const { return _c.empty(); }
private:
Con _c;
};
}
本节内容到此结束!!感谢大家阅读