Towards Explainable Harmful Meme Detection through
Multimodal Debate between Large Language Models
https://arxiv.org/abs/2401.13298 https://arxiv.org/abs/2401.13298
https://arxiv.org/abs/2401.13298
1.概论
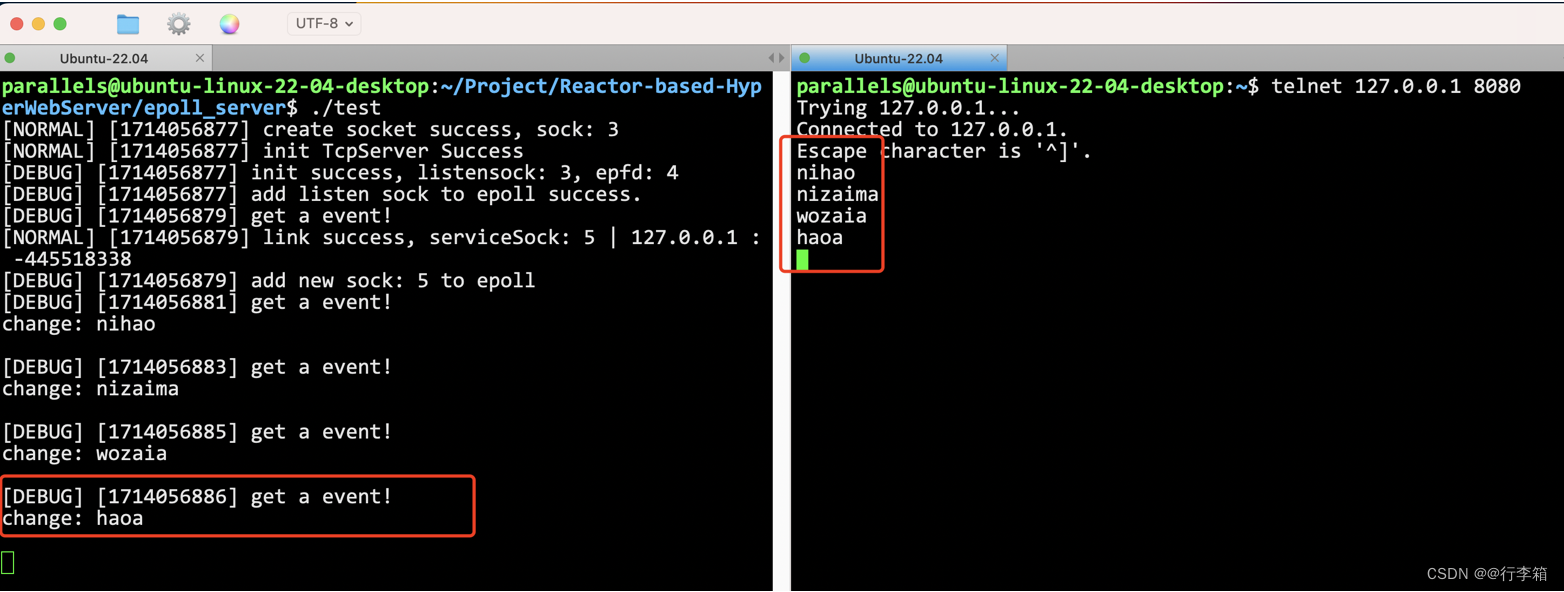
对于恶意表情包的识别,以往的研究方法没有能够深入表情包所隐含的复杂意义和文化背景,因此,他们往往不能充分解释某个表情包是有害的。这篇论文通过结合大型语言模型(LLMs)的推理能力,实现了一种可解释性的恶意表情包识别方法,其流程为:
- 第一步,使用两个LLMs进行多模态辩论来生成支持有害或无害立场的理由,
- 第二步&#