CACHE TABLE的能力
使用此语法,可以由用户自定义要缓存的结果集,实际上就是一个临时表,不过数据存储在Spark集群内部,由Application所分配的executors管理。
一旦定义了一个缓存表,就可以在SQL脚本中随处引用这个表名,提高数据检索速度,同时也会资源不必要的资源开销。
用户可以通过UNCACHE TABLE语法,显示地将这个结果集从缓存中移除。
CACHE TABLE的功能示例
示例SQL
SELECT b.id, a.country, b.city, b.tag
FROM default.tmp_tbl a
JOIN default.tmp_tbl b
ON a.city IS NOT NULL AND a.id = b.id AND a.id > 0 AND a.country = 'China'
优化前的物理执行计划
+- Project [id#153, country#152, city#155, tag#154]
+- BroadcastHashJoin [id#149], [id#153], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [plan_id=196]
: +- Project [id#149, country#152]
: +- Filter (isnotnull(id#149) AND (id#149 > 0))
: +- Scan odps du_all.tmp_tbl[id#149,city#151,country#152] Batched: true, DataFilters: [isnotnull(id#149), (id#149 > 0)], Format: Odps, PartitionFilters: [isnotnull(country#152), isnotnull(city#151), (country#152 = China)], PushedFilters: [IsNotNull(id), GreaterThan(id,0)], ReadSchema: struct<id:int,city:string,country:string>
+- Project [id#153, tag#154, city#155]
+- Filter ((id#153 > 0) AND isnotnull(id#153))
+- Scan odps du_all.tmp_tbl[id#153,tag#154,city#155,country#156] Batched: true, DataFilters: [(id#153 > 0), isnotnull(id#153)], Format: Odps, PartitionFilters: [], PushedFilters: [GreaterThan(id,0), IsNotNull(id)], ReadSchema: struct<id:int,tag:string,city:string,country:string
优化后的物理执行计划
优化后的SQL
CACHE TABLE cached_tbl AS (
SELECT * FROM default.tmp_tbl WHERE id > 0;
);
SELECT b.id, a.country, b.city, b.tag
FROM cached_tbl a
JOIN cached_tbl b
ON a.city IS NOT NULL AND a.id = b.id AND a.country = 'China'
物理执行计划
从如下的计划可以看到,BroadcastHashJoin的左、右子查询的数据都来自同一个
In-memory table,因此只会读源表一次。
+- Project [id#153, country#152, city#155, tag#154]
+- BroadcastHashJoin [id#149], [id#153], Inner, BuildLeft, false
:- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, true] as bigint)),false), [plan_id=196]
: +- Project [id#149, country#152]
: +- Filter (isnotnull(id#149) AND (id#149 > 0) AND isnotnull(country#152) AND isnotnull(city#151) AND (country#152 = China))
: +- Scan In-memory table
: +- InMemoryRelation [id#149,city#151,country#152], StorageLevel(disk, 1 replicas)
: +- ColumnarToRow
: +- Scan hive default.tmp_tbl[id#149,city#151,country#152] Batched: true, DataFilters: [isnotnull(id#149), (id#149 > 0)], Format: Hive, PartitionFilters: [], PushedFilters: [IsNotNull(id), GreaterThan(id,0)], ReadSchema: struct<id:int,city:string,country:string>
+- Project [id#153, tag#154, city#155]
+- Filter ((id#153 > 0) AND isnotnull(id#153))
+- Project [id#149 AS id#153, city#151 AS city#154, country#152 AS country#155]
+- Scan In-memory table
+- InMemoryRelation [id#149,city#151,country#152], StorageLevel(disk, 1 replicas)
+- ColumnarToRow
+- Scan hive default.tmp_tbl[id#149,city#151,country#152] Batched: true, DataFilters: [isnotnull(id#149), (id#149 > 0)], Format: Hive, PartitionFilters: [], PushedFilters: [IsNotNull(id), GreaterThan(id,0)], ReadSchema: struct<id:int,city:string,country:string>
CACHE TABLE的执行流程
CACHE TABLE语法定义了一个带有别名的,可以在Session层级共享的临时数据集,同时可以指定这些临时数据的存储模式(Memory or Disk or Mixed),简单说就是这些数据被缓存在了集群中,并被BlockManager管理。
一旦定义了这样一个临时表,就可以在任意的SQL中通过别名引用,同时可以被引用任意次,而不用担心数据的重复读取,以及从来源拉取数据的开销。
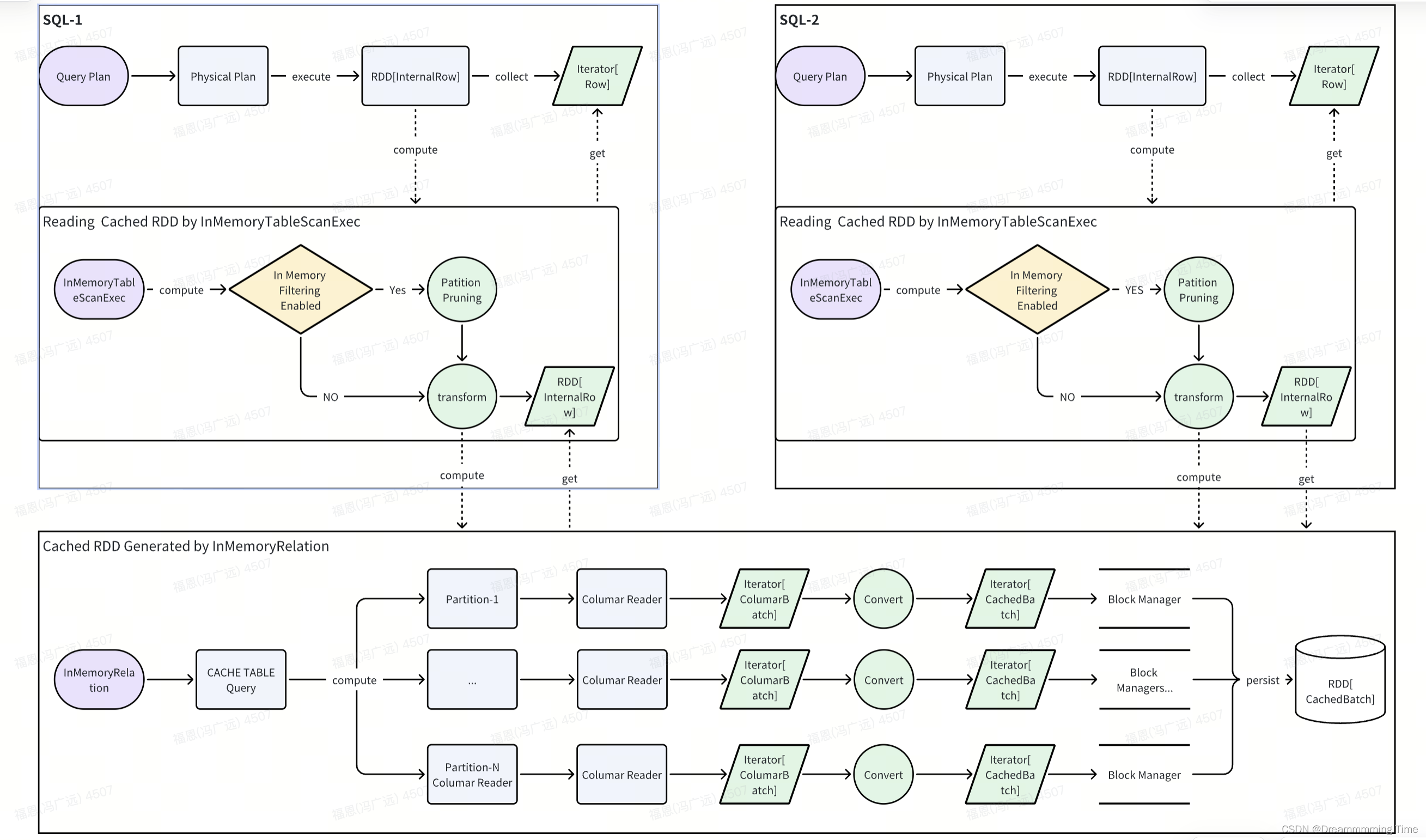
图1. 两条SQL读取同一个CACHE TABLE的结果集
*为什么不使用CTE?与CACHE TABLE有什么区别?
Spark中的CTE(Common Table Expression)语法,仅仅用于替换相同的子查询,更像是一种Query Scope的视图(View),而不能像Hive那样可以通过配置属性hive.optimize.cte.materialize.threshold=1实现物化子查询的能力,因此Spark只能通过CACHE TABLE语句,显示地(不难想到,可以hacking成隐式)缓存数据。
Spark不是可以共享Stage吗?为什么还要再在提供CACHE TABLE?
没错,Spark提供plan优化器,提供了ReuseExchangeAndSubquery优化规则,旨在共享相同的stage(必须带有exchange算子),但很不幸的是,相同的子查询在不同的Query Scope中经过优化器优化后,往往是不相同的,例如不同的过滤条件、不同的投影剪裁等,因此也就无法共享了。
在实际上的使用场景中,不论是CTE还是其它带有子查询的场景,我们都可以人工地合并底层stage/table scan的逻辑,然后通过CACHE TABLE定义成一张临时表,达到共享数据的目的,自然且肯定地可以增强spark以自动化这个过程(我就做了这样的优化并在实际场景中应用了)。
缓存RDD的代码流程分析(基于Columnar)
下图(引自中的截图)描述了RDD缓存的核心流程,不难看到Spark中RDD的缓存策略是很灵活的,不仅可以支持指定存储等级,还可以选择是否序列化存储(在序列化之前,还可以修改属性spark.sql.inMemoryColumnarStorage.compressed=true,选择要不要对列进行压缩)。
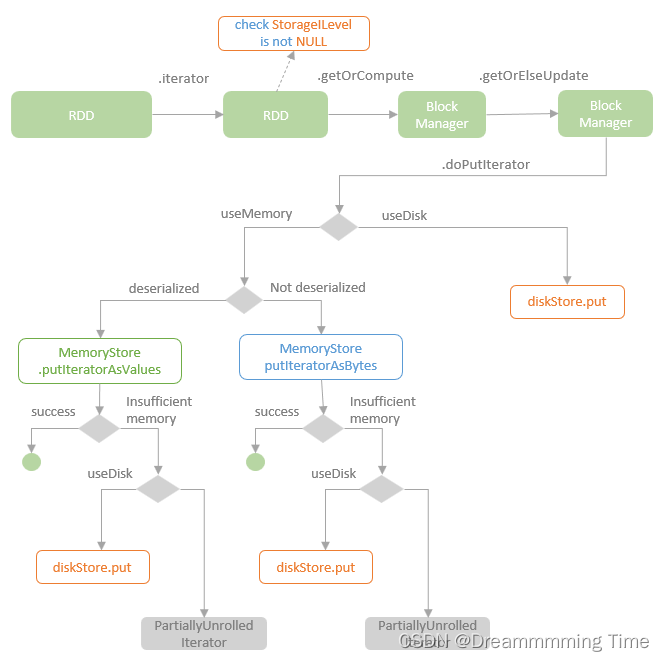
从上图可以很清楚地看到,Spark中的RDD缓存模式是很灵活的,可以同时使用内存和磁盘,能够最大程度地保证存储性能(得益于Spark Tungsten统一内存管理模型)。
生成RDD[ColumnarBatch]
Table Scan任务,如果要读取的字段是支持列式读写的,那么Spark默认生成一个RDD[ColumnarBatch]的实例,直接以列式格式从数据源加载数据。
生成RDD[InternalRow]
插入ColumarToRowExec/RowToColumnarExec算子
自底向上在optimizedPlan的合适位置插入行转列、列转行的物理计划结点。
由于InMemoryTableScanExec结点是不支持RDD[ColumnarBatch]作为其输入RDD的,假如child是支持列式的,那么就会在它们之间插入一个ColumarToRowExec实例,以保证InMemoryTableScanExec结点能够正常读取数据。
/**
* Apply any user defined [[ColumnarRule]]s and find the correct place to insert transitions
* to/from columnar formatted data.
*
* @param columnarRules custom columnar rules
* @param outputsColumnar whether or not the produced plan should output columnar format.
*/
case class ApplyColumnarRulesAndInsertTransitions(
columnarRules: Seq[ColumnarRule],
outputsColumnar: Boolean)
extends Rule[SparkPlan] {
/**
* Inserts an transition to columnar formatted data.
*/
private def insertRowToColumnar(plan: SparkPlan): SparkPlan = {
if (!plan.supportsColumnar) {
// The tree feels kind of backwards
// Columnar Processing will start here, so transition from row to columnar
RowToColumnarExec(insertTransitions(plan, outputsColumnar = false))
} else if (!plan.isInstanceOf[RowToColumnarTransition]) {
plan.withNewChildren(plan.children.map(insertRowToColumnar))
} else {
plan
}
}
/**
* Inserts RowToColumnarExecs and ColumnarToRowExecs where needed.
*/
private def insertTransitions(plan: SparkPlan, outputsColumnar: Boolean): SparkPlan = {
if (outputsColumnar) {
insertRowToColumnar(plan)
} else if (plan.supportsColumnar && !plan.supportsRowBased) {
// `outputsColumnar` is false but the plan only outputs columnar format, so add a
// to-row transition here.
ColumnarToRowExec(insertRowToColumnar(plan))
} else if (!plan.isInstanceOf[ColumnarToRowTransition]) {
plan.withNewChildren(plan.children.map(insertTransitions(_, outputsColumnar = false)))
} else {
plan
}
}
def apply(plan: SparkPlan): SparkPlan = {
var preInsertPlan: SparkPlan = plan
columnarRules.foreach(r => preInsertPlan = r.preColumnarTransitions(preInsertPlan))
var postInsertPlan = insertTransitions(preInsertPlan, outputsColumnar)
columnarRules.reverse.foreach(r => postInsertPlan = r.postColumnarTransitions(postInsertPlan))
postInsertPlan
}
}
执行ColumarToRowExec生成RDD[InternalRow]
生成RDD[CachedBatch]
InMemoryTableScanExec
从internal Relation获取数据,并根据数据源的schema信息,选择如何生成CachedBatch,作为缓存数据时的数据结构。
case class InMemoryTableScanExec(
attributes: Seq[Attribute],
predicates: Seq[Expression],
@transient relation: InMemoryRelation)
extends LeafExecNode {
override lazy val metrics = Map(
"numOutputRows" -> SQLMetrics.createMetric(sparkContext, "number of output rows"))
override val nodeName: String = {
relation.cacheBuilder.tableName match {
case Some(_) =>
"Scan " + relation.cacheBuilder.cachedName
case _ =>
super.nodeName
}
}
override def vectorTypes: Option[Seq[String]] =
relation.cacheBuilder.serializer.vectorTypes(attributes, conf)
override def supportsRowBased: Boolean = true
/**
* If true, get data from ColumnVector in ColumnarBatch, which are generally faster.
* If false, get data from UnsafeRow build from CachedBatch
*/
override val supportsColumnar: Boolean = {
conf.cacheVectorizedReaderEnabled &&
!WholeStageCodegenExec.isTooManyFields(conf, relation.schema) &&
relation.cacheBuilder.serializer.supportsColumnarOutput(relation.schema)
}
private lazy val columnarInputRDD: RDD[ColumnarBatch] = {
val numOutputRows = longMetric("numOutputRows")
val buffers = filteredCachedBatches()
relation.cacheBuilder.serializer.convertCachedBatchToColumnarBatch(
buffers,
relation.output,
attributes,
conf).map { cb =>
numOutputRows += cb.numRows()
cb
}
}
private lazy val inputRDD: RDD[InternalRow] = {
if (enableAccumulatorsForTest) {
readPartitions.setValue(0)
readBatches.setValue(0)
}
val numOutputRows = longMetric("numOutputRows")
// Using these variables here to avoid serialization of entire objects (if referenced
// directly) within the map Partitions closure.
val relOutput = relation.output
val serializer = relation.cacheBuilder.serializer
// update SQL metrics
val withMetrics =
filteredCachedBatches().mapPartitionsInternal { iter =>
if (enableAccumulatorsForTest && iter.hasNext) {
readPartitions.add(1)
}
iter.map { batch =>
if (enableAccumulatorsForTest) {
readBatches.add(1)
}
numOutputRows += batch.numRows
batch
}
}
serializer.convertCachedBatchToInternalRow(withMetrics, relOutput, attributes, conf)
}
override def output: Seq[Attribute] = attributes
private def updateAttribute(expr: Expression): Expression = {
// attributes can be pruned so using relation's output.
// E.g., relation.output is [id, item] but this scan's output can be [item] only.
val attrMap = AttributeMap(relation.cachedPlan.output.zip(relation.output))
expr.transform {
case attr: Attribute => attrMap.getOrElse(attr, attr)
}
}
// The cached version does not change the outputPartitioning of the original SparkPlan.
// But the cached version could alias output, so we need to replace output.
override def outputPartitioning: Partitioning = {
relation.cachedPlan.outputPartitioning match {
case e: Expression => updateAttribute(e).asInstanceOf[Partitioning]
case other => other
}
}
// The cached version does not change the outputOrdering of the original SparkPlan.
// But the cached version could alias output, so we need to replace output.
override def outputOrdering: Seq[SortOrder] =
relation.cachedPlan.outputOrdering.map(updateAttribute(_).asInstanceOf[SortOrder])
lazy val enableAccumulatorsForTest: Boolean = conf.inMemoryTableScanStatisticsEnabled
// Accumulators used for testing purposes
lazy val readPartitions = sparkContext.longAccumulator
lazy val readBatches = sparkContext.longAccumulator
private val inMemoryPartitionPruningEnabled = conf.inMemoryPartitionPruning
private def filteredCachedBatches(): RDD[CachedBatch] = {
val buffers = relation.cacheBuilder.cachedColumnBuffers
if (inMemoryPartitionPruningEnabled) {
val filterFunc = relation.cacheBuilder.serializer.buildFilter(predicates, relation.output)
buffers.mapPartitionsWithIndexInternal(filterFunc)
} else {
buffers
}
}
protected override def doExecute(): RDD[InternalRow] = {
inputRDD
}
protected override def doExecuteColumnar(): RDD[ColumnarBatch] = {
columnarInputRDD
}
}
通过InMemoryRelation加载并转换RDD
当执行InMemoryTableScanExec算子时,会在compute RDD的过程中,调用InMemoryRelation::CachedRDDBuilder::cachedColumnBuffers,同时会显示地通过
RDD::persist()方法指定持久等级,以便在触发此RDD的compute时能够正确缓存数据。
private[sql]
case class CachedRDDBuilder(
serializer: CachedBatchSerializer,
storageLevel: StorageLevel,
@transient cachedPlan: SparkPlan,
tableName: Option[String]) {
@transient @volatile private var _cachedColumnBuffers: RDD[CachedBatch] = null
@transient @volatile private var _cachedColumnBuffersAreLoaded: Boolean = false
val sizeInBytesStats: LongAccumulator = cachedPlan.session.sparkContext.longAccumulator
val rowCountStats: LongAccumulator = cachedPlan.session.sparkContext.longAccumulator
val cachedName = tableName.map(n => s"In-memory table $n")
.getOrElse(StringUtils.abbreviate(cachedPlan.toString, 1024))
def cachedColumnBuffers: RDD[CachedBatch] = {
if (_cachedColumnBuffers == null) {
synchronized {
if (_cachedColumnBuffers == null) {
_cachedColumnBuffers = buildBuffers()
}
}
}
_cachedColumnBuffers
}
def clearCache(blocking: Boolean = false): Unit = {
if (_cachedColumnBuffers != null) {
synchronized {
if (_cachedColumnBuffers != null) {
_cachedColumnBuffers.unpersist(blocking)
_cachedColumnBuffers = null
}
}
}
}
def isCachedColumnBuffersLoaded: Boolean = {
if (_cachedColumnBuffers != null) {
synchronized {
return _cachedColumnBuffers != null && isCachedRDDLoaded
}
}
false
}
private def isCachedRDDLoaded: Boolean = {
_cachedColumnBuffersAreLoaded || {
val bmMaster = SparkEnv.get.blockManager.master
val rddLoaded = _cachedColumnBuffers.partitions.forall { partition =>
bmMaster.getBlockStatus(RDDBlockId(_cachedColumnBuffers.id, partition.index), false)
.exists { case(_, blockStatus) => blockStatus.isCached }
}
if (rddLoaded) {
_cachedColumnBuffersAreLoaded = rddLoaded
}
rddLoaded
}
}
private def buildBuffers(): RDD[CachedBatch] = {
val cb = if (cachedPlan.supportsColumnar &&
serializer.supportsColumnarInput(cachedPlan.output)) {
// serializer默认是一个DefaultCachedBatchSerializer实例,它是不支持将ColumnarBatch转换成CachedBatch的,因此代码是不会执行到这里的
serializer.convertColumnarBatchToCachedBatch(
cachedPlan.executeColumnar(),
cachedPlan.output,
storageLevel,
cachedPlan.conf)
} else {
// 在前面有提到,cachedPlan通常会被插入一个ColumarToRowExec算子,以使RDD[ColumnarBatch]转换成RDD[InternalRow],因此代码会最终经过这里
serializer.convertInternalRowToCachedBatch(
cachedPlan.execute(),
cachedPlan.output,
storageLevel,
cachedPlan.conf)
}
// 持久化RDD[CachedBatch]
val cached = cb.map { batch =>
sizeInBytesStats.add(batch.sizeInBytes)
rowCountStats.add(batch.numRows)
batch
}.persist(storageLevel) // 在这里显示地标识这个RDD的持久化等级,注意必须要对某一个设置合适的值,否则默认的持久化等级是NONE即不持久化,也就不会缓存了
cached.setName(cachedName)
cached
}
}
生成RDD[CachedBatch]
实则调用DefaultCachedBatchSerializer::convertInternalRowToCachedBatch方法,将RDD[InternalRow]转换成RDD[CachedBatch]。
/**
* The default implementation of CachedBatchSerializer.
*/
class DefaultCachedBatchSerializer extends SimpleMetricsCachedBatchSerializer {
override def supportsColumnarInput(schema: Seq[Attribute]): Boolean = false
override def convertColumnarBatchToCachedBatch(
input: RDD[ColumnarBatch],
schema: Seq[Attribute],
storageLevel: StorageLevel,
conf: SQLConf): RDD[CachedBatch] =
throw new IllegalStateException("Columnar input is not supported")
override def convertInternalRowToCachedBatch(
input: RDD[InternalRow],
schema: Seq[Attribute],
storageLevel: StorageLevel,
conf: SQLConf): RDD[CachedBatch] = {
// 指定待缓存的数据,以多少行为一个Batch,与scan split生成的batch大小是不同的,对应如下属性:
// spark.sql.inMemoryColumnarStorage.batchSize=10000
val batchSize = conf.columnBatchSize
// 待缓存的数据,可以支持压缩
val useCompression = conf.useCompression
// 将输入的RDD[InternalRow]转换成RDD[CachedBatch]
convertForCacheInternal(input, schema, batchSize, useCompression)
}
def convertForCacheInternal(
input: RDD[InternalRow],
output: Seq[Attribute],
batchSize: Int,
useCompression: Boolean): RDD[CachedBatch] = {
input.mapPartitionsInternal { rowIterator =>
new Iterator[DefaultCachedBatch] {
def next(): DefaultCachedBatch = {
// 按输出的atttributes属性,创建ColumnBuilder实例,以构建列式数据
val columnBuilders = output.map { attribute =>
ColumnBuilder(attribute.dataType, batchSize, attribute.name, useCompression)
}.toArray
var rowCount = 0
var totalSize = 0L
// 遍历上游RDD的产出数据,并控制生成的CachedBatch大小,默认配置下有如下的限制:
// batchSize = 1000
// ColumnBuilder.MAX_BATCH_SIZE_IN_BYTE = 4 * 1024 * 1024
while (rowIterator.hasNext && rowCount < batchSize
&& totalSize < ColumnBuilder.MAX_BATCH_SIZE_IN_BYTE) {
val row = rowIterator.next()
// Added for SPARK-6082. This assertion can be useful for scenarios when something
// like Hive TRANSFORM is used. The external data generation script used in TRANSFORM
// may result malformed rows, causing ArrayIndexOutOfBoundsException, which is somewhat
// hard to decipher.
assert(
row.numFields == columnBuilders.length,
s"Row column number mismatch, expected ${output.size} columns, " +
s"but got ${row.numFields}." +
s"\nRow content: $row")
var i = 0
totalSize = 0 // 累加所有列的最新字节总和
// 遍历所有的输入RDD的每一个列,将期追加到对应的ColumnBuilder中
while (i < row.numFields) {
columnBuilders(i).appendFrom(row, i)
// 向第i列新追加了一行,
totalSize += columnBuilders(i).columnStats.sizeInBytes
i += 1
}
rowCount += 1
}
// 统计当前Batch的静态统计信息,例如batch/列压缩前后的字节大小、总行数等
// 而stats会包含每一个列更加详情的统计指标:
// 例如对于Int列有(其中最大最小值即Batch内当前列的所有整数的最值):
// Array[Any](lower, upper, nullCount, count, sizeInBytes)
// 对于String列有(其中最大最小值即Batch内当前列的所有UTF8String值按字节大小排序后的最值):
// Array[Any](lower, upper, nullCount, count, sizeInBytes)
// 因此我们可以基于stats信息,在经过InMemoryTableScanExec算子时,执行更多的过滤
val stats = InternalRow.fromSeq(
columnBuilders.flatMap(_.columnStats.collectedStatistics).toSeq)
// 生成DefaultCachedBatch实例
DefaultCachedBatch(rowCount, columnBuilders.map { builder =>
JavaUtils.bufferToArray(builder.build())
}, stats)
}
def hasNext: Boolean = rowIterator.hasNext
}
}
}
}
缓存RDD[CachedBatch]
从前文知道,InMemoryRelation::buildBuffers()方法返回的RDD被显示指定了持久化等级,默认是
MEMORY_AND_DISK,因此当下游RDD触发compute时,RDD[CachedBatch]::iterator(split: Partition, context: TaskContext)的方法会被递归调用(Table Scan组成CachedBatch),而后缓存结果集(就是CACHE TABLE生成的临时表数据)。
RDD[CachedBatch]持久化
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging {
/**
* Set this RDD's storage level to persist its values across operations after the first time
* it is computed. This can only be used to assign a new storage level if the RDD does not
* have a storage level set yet. Local checkpointing is an exception.
* 在前文的InMemoryRelation构建RDD时,显示地调用此方法,指定了当前RDD的持久化等级。
* 从方法的实现看,RDD的持久化过程,不仅与storage level有关,还与checkpoint机制有关,因此可以在当前类中看到computeOrReadCheckpoint(...)这样的方法。
*/
def persist(newLevel: StorageLevel): this.type = {
if (isLocallyCheckpointed) {
// This means the user previously called localCheckpoint(), which should have already
// marked this RDD for persisting. Here we should override the old storage level with
// one that is explicitly requested by the user (after adapting it to use disk).
persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true)
} else {
persist(newLevel, allowOverride = false)
}
}
/**
* Internal method to this RDD; will read from cache if applicable, or otherwise compute it.
* This should ''not'' be called by users directly, but is available for implementers of custom
* subclasses of RDD.
* 获取RDD的结果集迭代器。
*/
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
// 当通过persist(...)方法设置新的持久化等级时,会走这里,缓存当前RDD的结果集,
// getOrCompute方法类似Cache.getOrLoad(...)
getOrCompute(split, context)
} else {
// 持久化等级为NONE,意味着不需要缓存当前的RDD,因此当前RDD的结果集直接基于父RDD现算得到。
// 注意到这里也会涉及spark中的checkpoint机制,当前RDD的结果集也可能由于checkpoint被持久化了,因此也会尝试从上一个检查点恢复数据。
computeOrReadCheckpoint(split, context)
}
}
/**
* Gets or computes an RDD partition. Used by RDD.iterator() when an RDD is cached.
*/
private[spark] def getOrCompute(partition: Partition, context: TaskContext): Iterator[T] = {
val blockId = RDDBlockId(id, partition.index)
var readCachedBlock = true
// This method is called on executors, so we need call SparkEnv.get instead of sc.env.
// 这里默认首先从blockManager加载已经缓存在集群的上游RDD数据,如果没有的话,就执行computeOrReadCheckpoint(partition, context)方法,计算出所需的RDD数据,实际上就是CACHE TABLE的结果集。
SparkEnv.get.blockManager.getOrElseUpdate(blockId, storageLevel, elementClassTag, () => {
readCachedBlock = false
computeOrReadCheckpoint(partition, context)
}) match {
// Block hit.
case Left(blockResult) =>
// 到这里,说明当前RDD的结果已经被缓存了,可以直接构建
if (readCachedBlock) {
// 如果读取的是缓存的数据,那么重新计算当前任务的metrics信息
val existingMetrics = context.taskMetrics().inputMetrics
existingMetrics.incBytesRead(blockResult.bytes)
new InterruptibleIterator[T](context, blockResult.data.asInstanceOf[Iterator[T]]) {
override def next(): T = {
existingMetrics.incRecordsRead(1)
delegate.next()
}
}
} else {
// 说明数据已经被计算了,同时被缓存了,当前任务的metrics信息已经正确更新了,因此只需要返回iterator即可
new InterruptibleIterator(context, blockResult.data.asInstanceOf[Iterator[T]])
}
// Need to compute the block.
case Right(iter) =>
// 到这里,意味着由于内存或磁盘问题,无法缓存RDD数据,
// 因此需要现场计算RDD的结果,而跳过cache过程,保证系统的可用性
new InterruptibleIterator(context, iter)
}
}
}
读取缓存RDD[CachedBatch]
一个RDD被显示缓存后,在SQL层面说就是生成了一个临时的物化视图;从API层面看,就是生成了一个临时的表,并新创建了一个DataFrame。
一旦当前RDD数据被缓存,所有下游RDD拉取数据时,都只会共享地读取这个被缓存的RDD,如果配置了缓存等级为MEMORY且内存充足时,此时RDD的计算就是完全基于内存,性能达到最高。
case class InMemoryTableScanExec(
attributes: Seq[Attribute],
predicates: Seq[Expression],
@transient relation: InMemoryRelation)
// 如果缓存的数据支持列式,那么就会调用此方法,以获取列式组织的数据块
protected override def doExecuteColumnar(): RDD[ColumnarBatch] = {
columnarInputRDD
}
private lazy val columnarInputRDD: RDD[ColumnarBatch] = {
val numOutputRows = longMetric("numOutputRows")
// 尝试将过滤条件下推到数据缓存层,尽可能地过滤掉不需要读取的数据
val buffers = filteredCachedBatches()
relation.cacheBuilder.serializer.convertCachedBatchToColumnarBatch(
buffers,
relation.output,
attributes,
conf).map { cb =>
numOutputRows += cb.numRows()
cb
}
}
}
private val inMemoryPartitionPruningEnabled = conf.inMemoryPartitionPruning
private def filteredCachedBatches(): RDD[CachedBatch] = {
// 获取缓存的RDD[CachedBatch]对象
val buffers = relation.cacheBuilder.cachedColumnBuffers
if (inMemoryPartitionPruningEnabled) {
// 如果开启了内存缓存数据上的分区裁剪功能,则走这里,从predicates构建过滤方法,以应用到缓存的RDD上
val filterFunc = relation.cacheBuilder.serializer.buildFilter(predicates, relation.output)
buffers.mapPartitionsWithIndexInternal(filterFunc)
} else {
buffers
}
}
过滤条件下推到RDD[CachedBatch]
我们知道,Spark优化器有过滤条件下推的优化,可以将SQL中的过滤条件下沉到Table Scan算子中,以减少读取到内存的数据量。
而此时RDD[CachedBatch]可以认为就是一张表,同时也是一个带有别名的子查询,自然地,当在SQL中的某几个子查询中引用了别名且每一个子查询都有自己的过滤条件时,那么这些过滤条件就可以被下推到读取RDD[CachedBatch]的算子中,即对应于InMemoryTableScanExec物理计算结点。
InMemoryTableScanExec在前面的章节有提到,它被插入到InMemoryRelation(逻辑上就是RDD[CachedBatch])之前,以便根据上下文生成不同的下游RDD,完成计算。因此Spark内部在创建InMemoryTableScanExec实例时,可以传入过滤条件,以便在计算数据时,就可以按CachedBatch,过滤掉不符合条件的缓存数据块。
过滤条件下推
由于
InMemoryTableScanExec物理执行结点,可以接收过滤谓词,且直接读取RDD[CachedBatch],因此只能按Batch块应用过滤谓词,剔除不需要读取的数据块,就像过滤条件下推到Parquet、ORC文件的读取器。
这里的过滤的工作流程类似一个bloom filter,一旦认定某个batch不满足条件,就可以丢弃;否则认定这个batch包含有效数据行,但也可能存在不满足条件的行。
/**
* Provides basic filtering for [[CachedBatchSerializer]] implementations.
* The requirement to extend this is that all of the batches produced by your serializer are
* instances of [[SimpleMetricsCachedBatch]].
* This does not calculate the metrics needed to be stored in the batches. That is up to each
* implementation. The metrics required are really just min and max values and those are optional
* especially for complex types. Because those metrics are simple and it is likely that compression
* will also be done on the data we thought it best to let each implementation decide on the most
* efficient way to calculate the metrics, possibly combining them with compression passes that
* might also be done across the data.
*/
@DeveloperApi
@Since("3.1.0")
abstract class SimpleMetricsCachedBatchSerializer extends CachedBatchSerializer with Logging {
// 构建数据过滤器
// predicates: 创建InMemoryTableScanExec结点时,传入的过滤谓词
// cachedAttributes: 绑定的缓存子查询的输出字段,即InMemoryRelation::output
override def buildFilter(
predicates: Seq[Expression],
cachedAttributes: Seq[Attribute]): (Int, Iterator[CachedBatch]) => Iterator[CachedBatch] = {
// 基于缓存结果集的字段信息,构建用于过滤分区数据的统计数据结构
val stats = new PartitionStatistics(cachedAttributes)
val statsSchema = stats.schema
def statsFor(a: Attribute): ColumnStatisticsSchema = {
stats.forAttribute(a)
}
// Returned filter predicate should return false iff it is impossible for the input expression
// to evaluate to `true` based on statistics collected about this partition batch.
// 从predicates构建可以应用到分区数据的过滤器
// 从生成逻辑可以看出,返回的buildFilter只能包含那些右值是常量过滤表达式
@transient lazy val buildFilter: PartialFunction[Expression, Expression] = {
case And(lhs: Expression, rhs: Expression)
if buildFilter.isDefinedAt(lhs) || buildFilter.isDefinedAt(rhs) =>
(buildFilter.lift(lhs) ++ buildFilter.lift(rhs)).reduce(_ && _)
case Or(lhs: Expression, rhs: Expression)
if buildFilter.isDefinedAt(lhs) && buildFilter.isDefinedAt(rhs) =>
buildFilter(lhs) || buildFilter(rhs)
case EqualTo(a: AttributeReference, ExtractableLiteral(l)) =>
statsFor(a).lowerBound <= l && l <= statsFor(a).upperBound
case EqualTo(ExtractableLiteral(l), a: AttributeReference) =>
statsFor(a).lowerBound <= l && l <= statsFor(a).upperBound
case EqualNullSafe(a: AttributeReference, ExtractableLiteral(l)) =>
statsFor(a).lowerBound <= l && l <= statsFor(a).upperBound
case EqualNullSafe(ExtractableLiteral(l), a: AttributeReference) =>
statsFor(a).lowerBound <= l && l <= statsFor(a).upperBound
case LessThan(a: AttributeReference, ExtractableLiteral(l)) => statsFor(a).lowerBound < l
case LessThan(ExtractableLiteral(l), a: AttributeReference) => l < statsFor(a).upperBound
case LessThanOrEqual(a: AttributeReference, ExtractableLiteral(l)) =>
statsFor(a).lowerBound <= l
case LessThanOrEqual(ExtractableLiteral(l), a: AttributeReference) =>
l <= statsFor(a).upperBound
case GreaterThan(a: AttributeReference, ExtractableLiteral(l)) => l < statsFor(a).upperBound
case GreaterThan(ExtractableLiteral(l), a: AttributeReference) => statsFor(a).lowerBound < l
case GreaterThanOrEqual(a: AttributeReference, ExtractableLiteral(l)) =>
l <= statsFor(a).upperBound
case GreaterThanOrEqual(ExtractableLiteral(l), a: AttributeReference) =>
statsFor(a).lowerBound <= l
case IsNull(a: Attribute) => statsFor(a).nullCount > 0
case IsNotNull(a: Attribute) => statsFor(a).count - statsFor(a).nullCount > 0
case In(a: AttributeReference, list: Seq[Expression])
if list.forall(ExtractableLiteral.unapply(_).isDefined) && list.nonEmpty =>
list.map(l => statsFor(a).lowerBound <= l.asInstanceOf[Literal] &&
l.asInstanceOf[Literal] <= statsFor(a).upperBound).reduce(_ || _)
// This is an example to explain how it works, imagine that the id column stored as follows:
// __________________________________________
// | Partition ID | lowerBound | upperBound |
// |--------------|------------|------------|
// | p1 | '1' | '9' |
// | p2 | '10' | '19' |
// | p3 | '20' | '29' |
// | p4 | '30' | '39' |
// | p5 | '40' | '49' |
// |______________|____________|____________|
//
// A filter: df.filter($"id".startsWith("2")).
// In this case it substr lowerBound and upperBound:
// ________________________________________________________________________________________
// | Partition ID | lowerBound.substr(0, Length("2")) | upperBound.substr(0, Length("2")) |
// |--------------|-----------------------------------|-----------------------------------|
// | p1 | '1' | '9' |
// | p2 | '1' | '1' |
// | p3 | '2' | '2' |
// | p4 | '3' | '3' |
// | p5 | '4' | '4' |
// |______________|___________________________________|___________________________________|
//
// We can see that we only need to read p1 and p3.
case StartsWith(a: AttributeReference, ExtractableLiteral(l)) =>
statsFor(a).lowerBound.substr(0, Length(l)) <= l &&
l <= statsFor(a).upperBound.substr(0, Length(l))
}
// When we bind the filters we need to do it against the stats schema
// 结合statsSchema,替换搜集所有以应用到分区数据上的表达式中,
// 并根据InMemoryRelation的输出layout,替换表达式中的Attributes,
// 就是normalize 表达式。
val partitionFilters: Seq[Expression] = {
predicates.flatMap { p =>
val filter = buildFilter.lift(p)
val boundFilter =
filter.map(
BindReferences.bindReference(
_,
statsSchema,
allowFailures = true))
boundFilter.foreach(_ =>
filter.foreach(f => logInfo(s"Predicate $p generates partition filter: $f")))
// If the filter can't be resolved then we are missing required statistics.
boundFilter.filter(_.resolved)
}
}
// 定义一个function,其参数为分区ID、分区数据集的迭代器,返回结果为过滤后的结果集的迭代器
def ret(index: Int, cachedBatchIterator: Iterator[CachedBatch]): Iterator[CachedBatch] = {
// 创建谓谓词过滤器
val partitionFilter = Predicate.create(
partitionFilters.reduceOption(And).getOrElse(Literal(true)),
cachedAttributes)
// 根据传入的分区ID,初始化过滤器中的非确定表达式的统计信息,
// 以便能够正确评估输入数据行(即每一个CachedBatch的统计信息stats)
partitionFilter.initialize(index)
val schemaIndex = cachedAttributes.zipWithIndex
cachedBatchIterator.filter { cb =>
val cachedBatch = cb.asInstanceOf[SimpleMetricsCachedBatch]
if (!partitionFilter.eval(cachedBatch.stats)) {
// 不满足条件,意味着这个batch中的数据行都需要被剔除。
// 注意到这里打印的debug日志说昌跳过partition,不是对应的是Spark Partition的概念,
// 而cachedBatchIterator才表示一个完整的Partition,这里的日志描述大概是为了对齐处理裁剪逻辑
logDebug {
val statsString = schemaIndex.map { case (a, i) =>
val value = cachedBatch.stats.get(i, a.dataType)
s"${a.name}: $value"
}.mkString(", ")
s"Skipping partition based on stats $statsString"
}
false
} else {
// 如果当前的CachedBatch数据块存在有效的数据行,即当前batch可能包含有效数据,也可能
// 无效数据行,因此返回true,留待后续row by row过滤
true
}
}
}
ret
}
}
思考与改进
CACHE TABLE为用户提供了Session层级共享数据集的方法,可以通过此方法避免重复读表,并把读取的数据缓存在集群中,大加节约资源并减少整体耗时。但要想写好CACHE TABLE,需要用户事先分析每一个SQL对于相同表的依赖字段,把共同的信息归总成一个缓存表,才能达到预期的效果。
那我们是否是可以自动化地完成抽象CACHE TABLE的工作?
答案是肯定的。从内核看,Spark优化器现在已经帮我们分析好了每一个子查询的Scan算子的依赖信息,这些分析的信息不正是我们手工定义CACHE TABLE时需要梳理的信息吗!?因此我们可以较容易地通过改写现有的优化规则,或是增加新的优化规则,并基于优化后的plan,自动合并相同表上的Scan算子并注册缓存表,达到自动化共享临时数据集(子查询)目的。










![[C++ QT项目实战]----C++ QT系统实现多线程通信](https://img-blog.csdnimg.cn/direct/b36e7982a93248a8bd9df00b1e5c5c3c.png)