前面这个写过,但觉得写的不是很好,这次是参考命令运行脚本,讲解各个参数含义。后续尽可能会更新,可以关注一下专栏!!
*这是个人写的参数解读,我并非该领域的人如果那个大佬看到有参数解读不对或者有补充的请请反馈!谢谢(后续该文章可能会持续更新) *
LLaMA-Factory项目的地址:https://github.com/hiyouga/LLaMA-Factory/blob/main/README_zh.md

在LLaMA-Factory项目中,单显卡可以用命令或web页面训练,多显卡只能用用命令的方式,此文章以命令和单显卡为主讲解*(我就一个菜鸡,目前只掌握了单显卡,也是多显卡买不起) *
命令运行的脚本地址:https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/README_zh.md
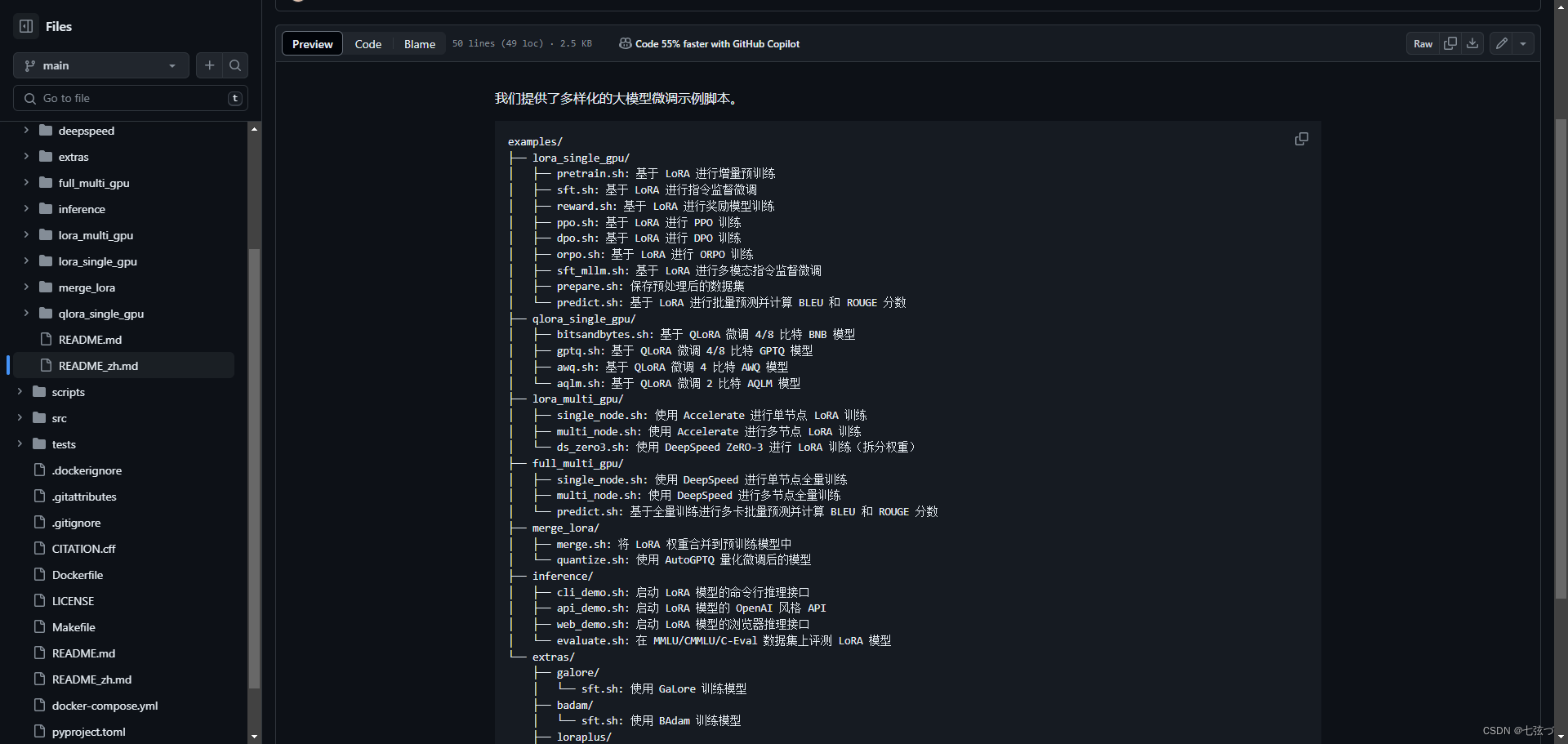
下面是预训练运行脚本的解读
预训练的简单解释
“预训练”这个训练模式,其实就是先在大量的通用数据上训练模型,让它学到一些基础的知识和处理能力,然后再用特定的较小数据集来进行进一步训练,使模型更适应特定的任务。这个过程有点像人先上小学到大学学习通识教育,然后再通过专业课程或者工作经验来精专某个领域。
使用情况
预训练模式特别适用于以下几种情况:
- 数据稀缺:对于一些特定任务,可能没有足够的标注数据来从头开始训练一个复杂的模型
这时,可以利用预训练模型作为起点,它已经学习了大量的通用知识,能够更好地处理数据稀缺的情况。- 提高效率:从预训练模型开始,可以显著减少训练时间和计算资源,因为模型已经有了一个很好的知识基础。
- 提升性能:在许多任务中,预训练模型通常能达到比从零开始训练更好的性能,尤其是在自然语言处理和图像识别领域。
优点
- 效率高:使用预训练模型可以节省大量的训练时间和计算资源。
- 性能好:预训练模型通常能提供更好的泛化能力,尤其是在数据较少的情况下。
- 灵活性强:预训练模型可以适用于多种不同的任务,只需要针对特定任务进行少量的调整和微调。
缺点
- 可能存在过拟合问题:如果微调的数据很少,模型可能会过度适应这些数据,导致泛化能力下降。
- 迁移学习的局限性:预训练模型是在特定的数据集上训练的,可能会带有这些数据集的偏见,迁移到完全不同的任务时可能效果不佳。
- 资源消耗:虽然预训练模型可以节省训练时间,但是预训练一个模型本身需要大量的数据和计算资源。
命令解读
- CUDA_VISIBLE_DEVICES=0 python …/…/src/train_bash.py
CUDA_VISIBLE_DEVICES=0:
这是一个环境变量设置,用于指定哪些GPU设备可被CUDA应用程序(如基于TensorFlow或PyTorch的深度学习训练脚本)使用。
CUDA_VISIBLE_DEVICES=0 表示只有编号为0的GPU设备可被使用。如果有多个GPU,可以设置为 CUDA_VISIBLE_DEVICES=0,1,2 来使用编号为0、1、2的GPU。
这个设置对于在多GPU环境中管理资源非常有用,尤其是当多个用户或多个进程需要独立使用特定GPU时。
- stage pt
指定训练阶段为预训练(pre-training)。
- do_train
启动训练过程。
- model_name_or_path meta-llama/Llama-2-7b-hf
指定模型名称或路径。
到时候根据自己项目部署修改这部分meta-llama/Llama-2-7b-hf
- dataset c4_demo
使用的数据集名称。(数据集就自己研究吧,如果不忙也会写先挖个坑)
根据自己需求修改这部分c4_demo的数据集名字
- dataset_dir …/…/data
数据集的存储目录。
- finetuning_type lora
使用LoRA(Low-Rank Adaptation)作为微调类型。
其他参数
1.Full:这种方式就是从头到尾完全训练一个模型。想象一下,你有一块白纸,你要在上面画出一幅完整的画作,这就是Full Training。你从零开始,逐步训练模型,直到它能够完成你想要的任务。
2.Freeze:这种方式有点像是在一幅半完成的画上继续作画。在模型中,有些部分(通常是模型的初级部分,如输入层或底层特征提取部分)是已经训练好的,这部分会被“冻结”,不再在训练过程中更新。你只更新模型的其他部分,这样可以节省训练时间和资源。
3.LoRA:这是一种比较新的技术,全称是“Low-Rank Adaptation”。可以理解为一种轻量级的模型调整方式。它主要是在模型的某些核心部分插入小的、低秩的矩阵,通过调整这些小矩阵来实现对整个模型的微调。这种方法不需要对原始模型的大部分参数进行重训练,从而可以在不牺牲太多性能的情况下,快速适应新的任务或数据。
4.QLoRA:这是在LoRA的基础上进一步发展的一种方法。它使用量化技术(也就是用更少的比特来表示每个数字),来进一步减少模型调整过程中需要的计算资源和存储空间。这样做可以使得模型更加高效,尤其是在资源有限的设备上运行时。
- lora_target q_proj,v_proj
指定LoRA调整的目标层,这里是q_proj和v_proj。
在使用LoRA(Low-Rank Adaptation,低秩适应)技术进行模型微调时,我们通常会选择模型中的特定层(或部分)进行调整。这些层被称为“目标层”。
具体来说:
1.q_proj:通常指的是在自注意力机制中,用于生成查询(Query)向量的投影层。
2.v_proj:指的是在自注意力机制中,用于生成值(Value)向量的投影层。
自注意力机制是很多现代深度学习模型,特别是Transformer模型的核心组成部分。在这种机制中,输入数据会被转换成三种类型的向量:查询(Query)、键(Key)、值(Value)。这些转换通常通过线性投影实现,即通过乘以一个权重矩阵。
在使用LoRA进行微调时,我们不直接修改这些投影层的权重矩阵,而是在这些层插入低秩矩阵。通过优化这些低秩矩阵,我们可以在不显著改变原始模型结构的情况下,有效地调整模型的行为,使其更好地适应新的任务或数据。
这种方法的优点是,它可以在保持大部分预训练模型权重不变的情况下,通过调整相对较少的参数来实现快速有效的微调。这样不仅可以节省计算资源,还可以减少过拟合的风险,特别是在数据较少的情况下。
- output_dir …/…/saves/LLaMA2-7B/lora/pretrain
指定输出目录,训练完成后的模型和相关文件将保存在这里。
到时候根据需求修改这部分就可以…/…/saves/LLaMA2-7B/lora/pretrain
- overwrite_cache
如果设置参数为true,将覆盖加载数据时的缓存。
- overwrite_output_dir
如果设置参数为true,将覆盖输出目录中已存在的文件。
- cutoff_len 1024
指定处理数据时的截断长度。
- preprocessing_num_workers 16
指定预处理数据时使用的工作进程数量。
- per_device_train_batch_size 1
每个设备上的训练批次大小。
- per_device_eval_batch_size 1
每个设备上的评估批次大小。
- gradient_accumulation_steps 8
梯度累积步数,用于在更新模型前累积更多的梯度,有助于使用较小的批次大小训练大模型
梯度累积的工作原理:
在每个批次的前向和反向传播过程中,不是立即更新模型权重,而是将梯度累积多个批次。当累积到一定数量的步骤后,再统一更新模型权重。这样可以模拟更大批量大小的效果。
选择梯度累积步数:
选择多少步骤进行梯度累积取决于你的具体需求和硬件限制。一般来说,步数越多,模拟的批量大小就越大,但同时每次更新权重的间隔也更长,可能会影响训练速度和效率。
- 低资源环境:可以选择较高的累积步数,以减少硬件压力。
- 高资源环境:如果内存允许,可以减少累积步数,使训练更加频繁地更新,可能会加速收敛。
- lr_scheduler_type cosine
学习率调度器类型
其他学习率调度器类型:
linear(线性):
- 描述:学习率从一个较高的初始值开始,然后随着时间线性地减少到一个较低的值。
- 使用场景:当你想要让模型在训练早期快速学习,然后逐渐减慢学习速度以稳定收敛时使用。
cosine(余弦):
- 描述:学习率按照余弦曲线的形状进行周期性调整,这种周期性的起伏有助于模型在不同的训练阶段探索参数空间。
- 使用场景:在需要模型在训练过程中不断找到新解的复杂任务中使用,比如大规模的图像或文本处理。
cosine_with_restarts(带重启的余弦):
- 描述:这是余弦调整的一种变体,每当学习率达到一个周期的最低点时,会突然重置到最高点,然后再次减少。
- 使用场景:适用于需要模型从局部最优解中跳出来,尝试寻找更好全局解的情况。
polynomial(多项式):
- 描述:学习率按照一个多项式函数减少,通常是一个幂次递减的形式。
- 使用场景:当你需要更精细控制学习率减少速度时使用,适用于任务比较复杂,需要精细调优的模型。
constant(常数):
- 描述:学习率保持不变。
- 使用场景:简单任务或者小数据集,模型容易训练到足够好的性能时使用。
constant_with_warmup(带预热的常数):
- 描述:开始时使用较低的学习率“预热”模型,然后切换到一个固定的较高学习率。
- 使用场景:在训练大型模型或复杂任务时,帮助模型稳定地开始学习,避免一开始就进行大的权重调整。
inverse_sqrt(逆平方根):
- 描述:学习率随训练步数的增加按逆平方根递减。
- 使用场景:常用于自然语言处理中,特别是在训练Transformer模型时,帮助模型在训练后期进行细微的调整。
reduce_lr_on_plateau(在平台期降低学习率):
- 描述:当模型的验证性能不再提升时,自动减少学习率。
- 使用场景:适用于几乎所有类型的任务,特别是当模型很难进一步提高性能时,可以帮助模型继续优化和提升。
- logging_steps 10
每训练10步记录一次日志
- warmup_steps 20
学习率预热步数。
预热步数(Warmup Steps):
这是模型训练初期用于逐渐增加学习率的步骤数。在这个阶段,学习率从一个很小的值(或者接近于零)开始,逐渐增加到设定的初始学习率。这个过程可以帮助模型在训练初期避免因为学习率过高而导致的不稳定,比如参数更新过大,从而有助于模型更平滑地适应训练数据。
例如,如果设置
warmup_steps为20,那么在前20步训练中,学习率会从低到高逐步增加。预热步数的具体数值通常取决于几个因素:
- 训练数据的大小:数据集越大,可能需要更多的预热步骤来帮助模型逐步适应。
- 模型的复杂性:更复杂的模型可能需要更长时间的预热,以避免一开始就对复杂的参数空间进行过激的调整。
- 总训练步数:如果训练步数本身就很少,可能不需要很多的预热步骤;反之,如果训练步数很多,增加预热步骤可以帮助模型更好地启动。
- save_steps 100
每训练100步保存一次模型。
- eval_steps 100
每训练100步进行一次评估。
- evaluation_strategy steps
评估策略,这里设置为按步骤评估。
- load_best_model_at_end
训练结束时加载表现最好的模型。
- learning_rate 5e-5
设置学习率。
学习率是机器学习和深度学习中控制模型学习速度的一个参数。你可以把它想象成你调节自行车踏板力度的旋钮:旋钮转得越多,踏板动得越快,自行车就跑得越快;但如果转得太快,可能会导致自行车失控。同理,学习率太高,模型学习过快,可能会导致学习过程不稳定;学习率太低,模型学习缓慢,训练时间长,效率低。
常见的学习率参数包括但不限于:
- 1e-1(0.1):相对较大的学习率,用于初期快速探索。
- 1e-2(0.01):中等大小的学习率,常用于许多标准模型的初始学习率。
- 1e-3(0.001):较小的学习率,适用于接近优化目标时的细致调整。
- 1e-4(0.0001):更小的学习率,用于当模型接近收敛时的微调。
- 5e-5(0.00005):非常小的学习率,常见于预训练模型的微调阶段,例如在自然语言处理中微调BERT模型。
选择学习率的情况:
- 快速探索:在模型训练初期或者当你不确定最佳参数时,可以使用较大的学习率(例如0.1或0.01),快速找到一个合理的解。
- 细致调整:当你发现模型的性能开始稳定,但还需要进一步优化时,可以减小学习率(例如0.001或0.0001),帮助模型更精确地找到最优解。
- 微调预训练模型:当使用已经预训练好的模型(如在特定任务上微调BERT)时,通常使用非常小的学习率(例如5e-5或更小),这是因为预训练模型已经非常接近优化目标,我们只需要做一些轻微的调整。
- num_train_epochs 3.0
训练的轮次。
- max_samples 10000
最大样本数。
- val_size 0.1
验证集大小,这里设置为10%。
- plot_loss
如果设置参数为true 将绘制损失图。
- fp16
如果设置,将使用16位浮点数进行训练,可以减少内存使用并可能加速训练。
在深度学习中,我们可以选择不同的数值精度来进行模型的训练和计算。不同的精度会影响计算资源的使用、训练速度和模型的精确度。下面我用更通俗的语言解释一下这些术语:
- FP16 (Half Precision,半精度):
- 这种方式使用16位的浮点数来保存和计算数据。想象一下,如果你有一个非常精细的秤,但现在只用这个秤的一半精度来称重,这就是FP16。它不如32位精度精确,但计算速度更快,占用的内存也更少。
- BF16 (BFloat16):
- BF16也是16位的,但它在表示数的方式上和FP16不同,特别是它用更多的位来表示数的大小(指数部分),这让它在处理大范围数值时更加稳定。你可以把它想象成一个专为机器学习优化的“半精度”秤,尤其是在使用特殊的硬件加速器时。
- FP32 (Single Precision,单精度):
- 这是使用32位浮点数进行计算的方式,可以想象为一个标准的、全功能的精细秤。它在深度学习中非常常见,因为它提供了足够的精确度,适合大多数任务。
- Pure BF16:
- 在表示数的方式上和FP16不同,特别是它用更多的位来表示数的大小(指数部分),这让它在处理大范围数值时更加稳定。你可以把它想象成一个专为机器学习优化的“半精度”秤,尤其是在使用特殊的硬件加速器时。
- FP32 (Single Precision,单精度):
- 这是使用32位浮点数进行计算的方式,可以想象为一个标准的、全功能的精细秤。它在深度学习中非常常见,因为它提供了足够的精确度,适合大多数任务。
- Pure BF16:
- 这种模式下,所有计算都仅使用BF16格式。这意味着整个模型训练过程中,从输入到输出,都在使用为机器学习优化的半精度计算。





](https://img-blog.csdnimg.cn/direct/a7d48a857ddf42ae92055a4c737b6e6d.png)