文章目录
- 前言
- Transformer 整体结构
- Transformer 的输入
- 单词 Embedding
- 原理
- CBOW 模型
- one-hot
- 构建 CBOW 训练数据集
- 构建 CBOW 神经网络
- 训练 CBOW 神经网络
- Skip-gram 模型
- one-hot
- 构建 Skip-gram训练数据集
- 训练 Skip-gram神经网络
- Word2Vec实例
- 数据训练
- 保存和加载
前言
Transformer由论文《Attention is All You Need》提出,现在是谷歌云TPU推荐的参考模型。论文相关的Tensorflow的代码可以从GitHub获取,其作为Tensor2Tensor包的一部分。哈佛的NLP团队也实现了一个基于PyTorch的版本,并注释该论文。
在本文中,我们将试图把模型简化一点,并逐一介绍里面的核心概念,希望让普通读者也能轻易理解。
Attention is All You Need:Attention Is All You Need
Transformer 整体结构
首先介绍 Transformer 的整体结构,下图是 Transformer 用于中英文翻译的整体结构:
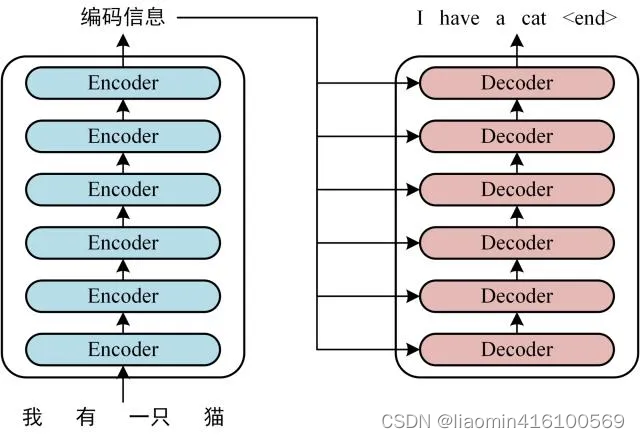
可以看到 Transformer 由 Encoder 和 Decoder 两个部分组成,Encoder 和 Decoder 都包含 6 个 block。Transformer 的工作流程大体如下:
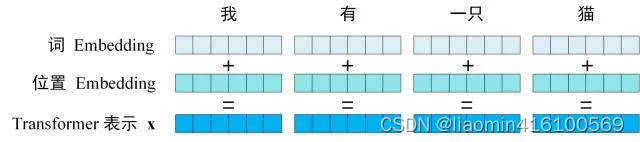
第一步:获取输入句子的每一个单词的表示向量 X,X由单词的 Embedding(Embedding就是从原始数据提取出来的Feature) 和单词位置的 Embedding 相加得到。

第二步:将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C,如下图。单词向量矩阵用
X
n
×
d
X_{n\times d}
Xn×d
表示, n 是句子中单词个数,d 是表示向量的维度 (论文中 d=512)。每一个 Encoder block 输出的矩阵维度与输入完全一致。
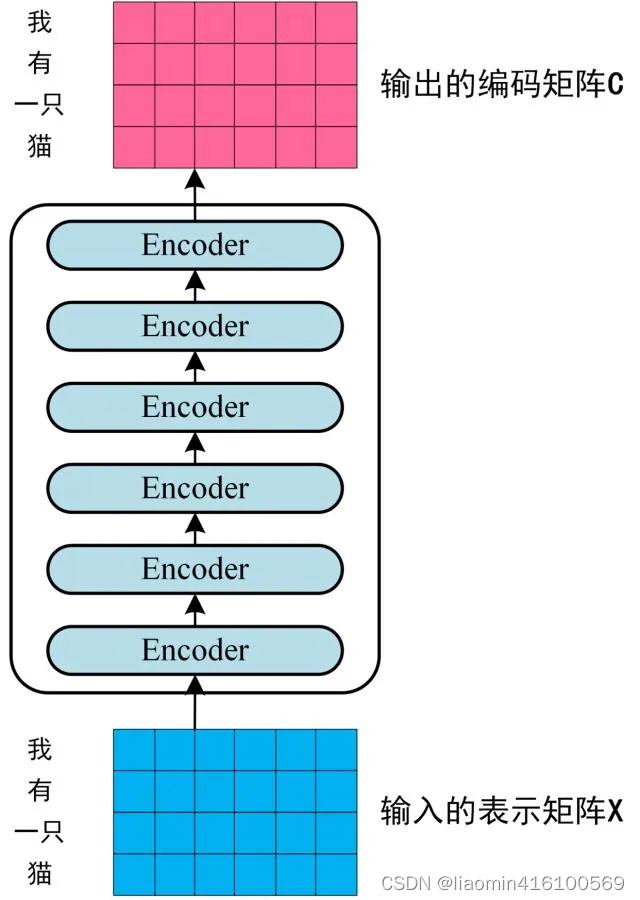
第三步:将 Encoder 输出的编码信息矩阵 C传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1,如下图所示。在使用的过程中,翻译到单词 i+1 的时候需要通过 Mask (掩盖) 操作遮盖住 i+1 之后的单词。
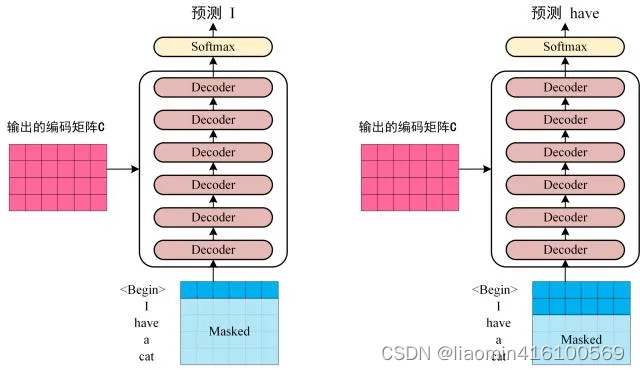
上图 Decoder 接收了 Encoder 的编码矩阵 C,然后首先输入一个翻译开始符 “”,预测第一个单词 “I”;然后输入翻译开始符 “” 和单词 “I”,预测单词 “have”,以此类推。这是 Transformer 使用时候的大致流程,接下来是里面各个部分的细节。
Transformer 的输入
Transformer 中单词的输入表示 x由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到。
单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
原理
什么是Word Embedding(词嵌入)?
- 词嵌入是自然语言处理中语言模型与表征技术技术的统称。讲人话就是: 就是把词语(字符串类型)这一文本数据转换成 计算机能认识 的数字表征的数据(一般为浮点型数据)。因为我们的机器学习模型或者深度学习模型,需要的数据都是数字类型的,无法处理文本类型的数据,所以我们需要把单词转换成数字类型。
- 词嵌入为 文本AI系统的上游任务,只有通过词嵌入模型才能得到文本AI系统才能得到数字类型的输入数据。
- 现有的词嵌入模型有:word2vec,GloVe,ELMo,BERT等
以下使用word2vec的原理来解释下词embedding实现逻辑
word2vec是词向量化技术的一种,通过神经网络来实现。其在表面上看起来是一种无监督学习技术,但本质上仍然是有监督学习。
利用文本的上下文信息构造有监督数据集,通过这一数据集来训练神经网络,最后取得训练好的神经网络两个网络层之间的权重
矩阵作为的词向量表(每个单词对应其中一行数据)。
word2vec 有两个模型:
- Skip-gram模型:其特点为,根据当前单词预测上下文单词,使用中心词来预测上下文词。
- CBOW模型:全称为 Continuous Bag-of-Word,连续词袋模型,该模型的特点是,输入已知的上下文,输出对当前单词的预测,其实就是利用中心两侧的词来预测中心的词。
以下两幅图展现了CBOW模型和Skip-gram模型。
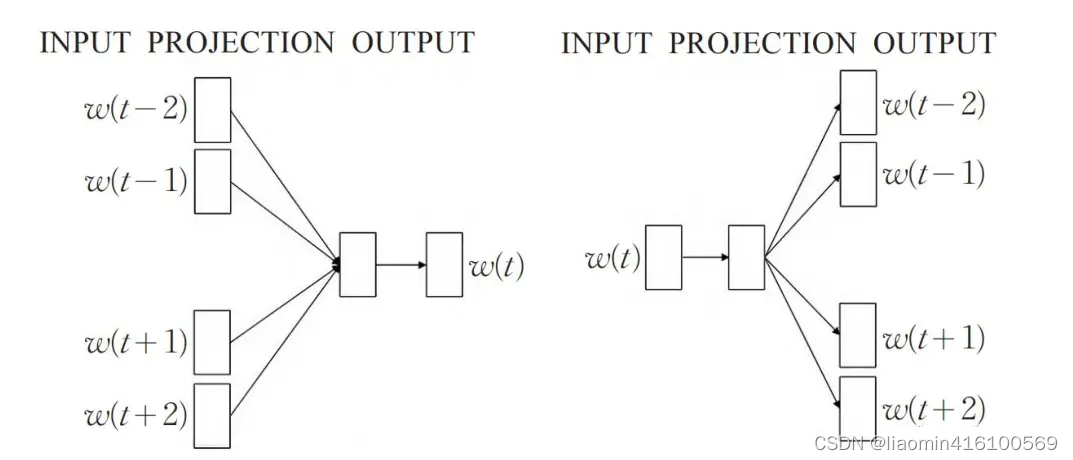
CBOW 模型
如果对以下神经网络连接不太清楚的,可以先去看看:https://blog.csdn.net/liaomin416100569/article/details/130572559?spm=1001.2014.3001.5501
one-hot
参考:rnn中关于one-hot和nn.embedding章节
One-hot编码又称一位有效编码,是将文字数字化的过程。假如我们有一个语料库:”I drink coffee everyday“。我们对其以” “(空格)进行分词,则我们会得到4个单词,假设这4个单词是我们所有的单词种类(也就是说,我们的字典中只有这四个单词),这样我们对其进行one-hot编码后,可以得到如下编码结果: 表1
| 单词 | One-hot编码 |
|---|---|
| I | [1, 0, 0, 0] |
| drink | [0, 1, 0, 0] |
| coffee | [0, 0, 1, 0] |
| everyday | [0, 0, 0, 1] |
这里使用one-hot的原因是列的个数就是单词的格式,最后使用隐藏层的w作为嵌入结果,刚好是(列数,隐藏层神经元个数)
构建 CBOW 训练数据集
cbow是使用两侧的词语,预测中心的词语,预测窗口大小为 2,输入就是左侧和右侧的两个单词,预测的单词就是中心的单词。
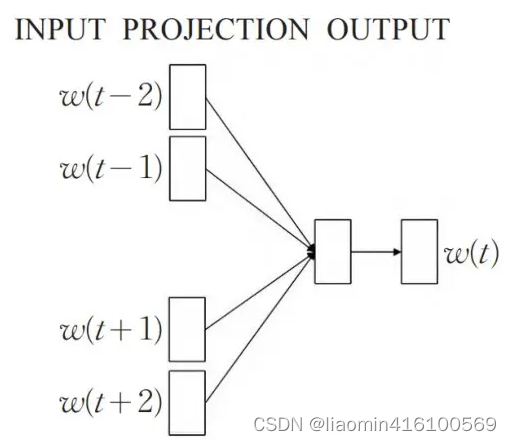
我们语料库仍然为:”I drink coffee everyday“,假设我们的预测窗口大小为 2,通过语料库我们可以构建以下训练集,表2
| 输入词 | 预测词 |
|---|---|
| [drink, coffee] | I |
| [I, coffee, everyday] | drink |
| [I, drink, everyday] | coffee |
| [drink, coffee] | everyday |
构建 CBOW 神经网络
从上可知,我们的输入层有4个输入单元(one-hot的4列,因为one-hot所以就是原始单词个数),输出层神经元的个数应该跟输入层保持一致,输出层也是4个神经元,加入我们想要每个单词为一个五维的向量表示,那么我们的隐藏层则为五个神经元。由此,我们可以构建一个输入层为4,隐藏层为5,输出层为4的全连接神经网络,如下图所示,训练好的模型的权重矩阵w1可以作为我们的词向量化表。
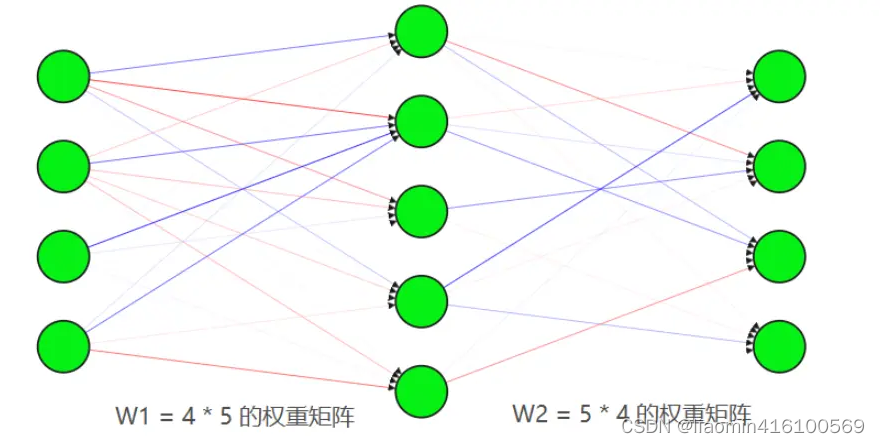
训练 CBOW 神经网络
这时我们可以根据构建的CBOW数据集对模型进行训练了,假设我们要预测的词是coffee,那么由表2可知,我们输入词为[I, drink, everyday],我们可以得到如下训练过程。
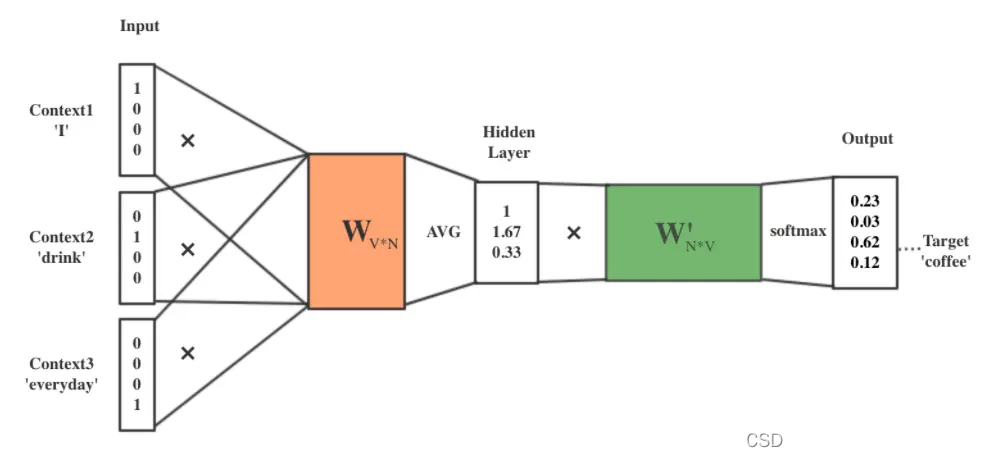
首先,我们将输入词[I, drink, everyday]转换为对应的one-hot编码向量。假设我们的词汇表中有四个词(I, drink, coffee, everyday),则输入词的one-hot编码分别为:
I: [1, 0, 0, 0]
drink: [0, 1, 0, 0]
everyday: [0, 0, 0, 1]
接下来,我们将每个one-hot编码向量乘以词嵌入矩阵,以获取词嵌入向量。假设我们已经有了每个词的词嵌入矩阵(这些矩阵在实际应用中是通过训练得到的),这也是我们经过多次训练之后,最终得到的嵌入矩阵,因为初始化肯定是一个初始值,经过训练反向传播得到一个最佳值,这里假设它们分别为:
W
=
[
0.1
0.2
0.3
0.4
0.5
0.2
0.3
0.4
0.5
0.6
0.3
0.4
0.5
0.6
0.7
0.4
0.5
0.6
0.7
0.8
]
W = \begin{bmatrix} 0.1 & 0.2 & 0.3 & 0.4 & 0.5 \\ 0.2 & 0.3 & 0.4 & 0.5 & 0.6 \\ 0.3 & 0.4 & 0.5 & 0.6 & 0.7 \\ 0.4 & 0.5 & 0.6 & 0.7 & 0.8 \\ \end{bmatrix}
W=
0.10.20.30.40.20.30.40.50.30.40.50.60.40.50.60.70.50.60.70.8
接下来,我们将每个one-hot编码向量乘以词嵌入矩阵,以获取词嵌入向量。例如:
- 输入词I的词嵌入向量: [ 1 , 0 , 0 , 0 ] × W = [ 0.1 , 0.2 , 0.3 , 0.4 , 0.5 ] [1, 0, 0, 0] \times W = [0.1, 0.2, 0.3, 0.4, 0.5] [1,0,0,0]×W=[0.1,0.2,0.3,0.4,0.5]
- 输入词drink的词嵌入向量: [ 0 , 1 , 0 , 0 ] × W = [ 0.2 , 0.3 , 0.4 , 0.5 , 0.6 ] [0, 1, 0, 0] \times W = [0.2, 0.3, 0.4, 0.5, 0.6] [0,1,0,0]×W=[0.2,0.3,0.4,0.5,0.6]
- 输入词everyday的词嵌入向量: [ 0 , 0 , 0 , 1 ] × W = [ 0.4 , 0.5 , 0.6 , 0.7 , 0.8 ] [0, 0, 0, 1] \times W = [0.4, 0.5, 0.6, 0.7, 0.8] [0,0,0,1]×W=[0.4,0.5,0.6,0.7,0.8]
接下来,我们将上下文单词的词嵌入向量加起来或求平均以获取一个特征向量。在这个例子中,我们将对它们求平均。
平均特征向量 =
平均特征向量
=
(
词嵌入向量(I)
+
词嵌入向量(drink)
+
词嵌入向量(everyday)
)
3
\text{平均特征向量} = \frac{( \text{词嵌入向量(I)} + \text{词嵌入向量(drink)} + \text{词嵌入向量(everyday)} )}{3}
平均特征向量=3(词嵌入向量(I)+词嵌入向量(drink)+词嵌入向量(everyday))
=
(
[
0.1
,
0.2
,
0.3
,
0.4
,
0.5
]
+
[
0.2
,
0.3
,
0.4
,
0.5
,
0.6
]
+
[
0.4
,
0.5
,
0.6
,
0.7
,
0.8
]
)
3
= \frac{( [0.1, 0.2, 0.3, 0.4, 0.5] + [0.2, 0.3, 0.4, 0.5, 0.6] + [0.4, 0.5, 0.6, 0.7, 0.8] )}{3}
=3([0.1,0.2,0.3,0.4,0.5]+[0.2,0.3,0.4,0.5,0.6]+[0.4,0.5,0.6,0.7,0.8])
=
[
(
0.1
+
0.2
+
0.4
)
3
,
(
0.2
+
0.3
+
0.5
)
3
,
(
0.3
+
0.4
+
0.6
)
3
,
(
0.4
+
0.5
+
0.7
)
3
,
(
0.5
+
0.6
+
0.8
)
3
]
= \left[ \frac{(0.1 + 0.2 + 0.4)}{3}, \frac{(0.2 + 0.3 + 0.5)}{3}, \frac{(0.3 + 0.4 + 0.6)}{3}, \frac{(0.4 + 0.5 + 0.7)}{3}, \frac{(0.5 + 0.6 + 0.8)}{3} \right]
=[3(0.1+0.2+0.4),3(0.2+0.3+0.5),3(0.3+0.4+0.6),3(0.4+0.5+0.7),3(0.5+0.6+0.8)]
=
[
0.233
,
0.333
,
0.433
,
0.533
,
0.633
]
= [0.233, 0.333, 0.433, 0.533, 0.633]
=[0.233,0.333,0.433,0.533,0.633]
现在,我们得到了一个特征向量
[
0.233
,
0.333
,
0.433
,
0.533
,
0.633
]
[0.233, 0.333, 0.433, 0.533, 0.633]
[0.233,0.333,0.433,0.533,0.633]它表示了上下文单词[I, drink, everyday]的语义信息。
理解CBOW模型中将上下文单词的词嵌入向量加起来或求平均的原因需要考虑两个方面:
1.上下文信息的整合:CBOW模型的目标是通过上下文单词来预测目标词。因此,对于一个给定的目标词,在预测时需要综合考虑其周围的上下文信息。将上下文单词的词嵌入向量加起来或求平均,可以将这些单词的语义信息整合到一个特征向量中,使得该特征向量更全面地表示了整个句子的语境信息,而不仅仅是单个词的信息。这样可以帮助模型更准确地捕捉句子的语义信息,从而提高模型在目标词预测任务上的性能。
2.语义信息的提取:虽然CBOW模型是用来预测目标词的,但实际上,在训练过程中,模型会学习到每个词的词嵌入向量,这些词嵌入向量包含了每个单词的语义信息。当将上下文单词的词嵌入向量加起来或求平均时,实际上是在利用这些已经学习到的词嵌入向量来提取整个句子的语义信息。由于词嵌入向量是通过大规模语料库训练得到的,其中包含了丰富的语义信息,因此将它们加起来或求平均可以帮助提取句子的语义特征,而不仅仅是单个词的语义特征。
接下来,我们将特征向量输入到一个全连接层(也称为投影层),并应用softmax函数以获取预测概率。假设全连接层的权重矩阵为:
W
p
r
o
j
=
[
0.1
0.2
0.3
0.4
0.5
0.2
0.3
0.4
0.5
0.6
0.3
0.4
0.5
0.6
0.7
0.4
0.5
0.6
0.7
0.8
0.5
0.6
0.7
0.8
0.9
]
W_{proj} = \begin{bmatrix} 0.1 & 0.2 & 0.3 & 0.4 & 0.5 \\ 0.2 & 0.3 & 0.4 & 0.5 & 0.6 \\ 0.3 & 0.4 & 0.5 & 0.6 & 0.7 \\ 0.4 & 0.5 & 0.6 & 0.7 & 0.8 \\ 0.5 & 0.6 & 0.7 & 0.8 & 0.9 \\ \end{bmatrix}
Wproj=
0.10.20.30.40.50.20.30.40.50.60.30.40.50.60.70.40.50.60.70.80.50.60.70.80.9
我们将特征向量乘以权重矩阵,并应用softmax函数,以获取每个词作为预测目标的概率。
z
=
[
0.233
,
0.333
,
0.433
,
0.533
,
0.633
]
×
W
p
r
o
j
z = [0.233, 0.333, 0.433, 0.533, 0.633] \times W_{proj}
z=[0.233,0.333,0.433,0.533,0.633]×Wproj
经过训练之后,我们拿 W1( 4*5 权重矩阵) 作为我们的词向量化表,我们可以得到**如下词向量化表(假设)。
| 单词索引 | 向量 |
|---|---|
| I | [0.11, 0.22, 0.23, 0.25, 0.31] |
| drink | [0.32, 0.22, 0.33, 0.11, 0.32] |
| coffee | [0.23, 0.03, 0.62, 0.12, 0.17] |
| everyday | [0.05, 0.25, 0.55, 0.17, 0.47 ] |
假如我们要词向量化”I drink coffee“这句话,我们便可以直接查询上表,拿到我们的词向量矩阵,即为 [ [ 0.11 , 0.22 , 0.23 , 0.25 , 0.31 ] , [ 0.32 , 0.22 , 0.33 , 0.11 , 0.32 ] , [ 0.23 , 0.03 , 0.62 , 0.12 , 0.17 ] ] [ [0.11, 0.22, 0.23, 0.25, 0.31],\\ [0.32, 0.22, 0.33, 0.11, 0.32], \\ [0.23, 0.03, 0.62, 0.12, 0.17] ] [[0.11,0.22,0.23,0.25,0.31],[0.32,0.22,0.33,0.11,0.32],[0.23,0.03,0.62,0.12,0.17]]
Skip-gram 模型
one-hot
参考:rnn中关于one-hot和nn.embedding章节
One-hot编码又称一位有效编码,是将文字数字化的过程。假如我们有一个语料库:”I drink coffee everyday“。我们对其以” “(空格)进行分词,则我们会得到4个单词,假设这4个单词是我们所有的单词种类(也就是说,我们的字典中只有这四个单词),这样我们对其进行one-hot编码后,可以得到如下编码结果: 表1
| 单词 | One-hot编码 |
|---|---|
| I | [1, 0, 0, 0] |
| drink | [0, 1, 0, 0] |
| coffee | [0, 0, 1, 0] |
| everyday | [0, 0, 0, 1] |
这里使用one-hot的原因是列的个数就是单词的格式,最后使用隐藏层的w作为嵌入结果,刚好是(列数,隐藏层神经元个数)
构建 Skip-gram训练数据集
cbow是使用两侧的词语,预测中心的词语,预测窗口大小为 2,输入就是左侧和右侧的两个单词,预测的单词就是中心的单词。
skip-gram是使用中心的词语,预测两侧的词语,预测窗口大小为 2,输入就是中心词语,预测的单词就是左侧和右侧的两个单词。
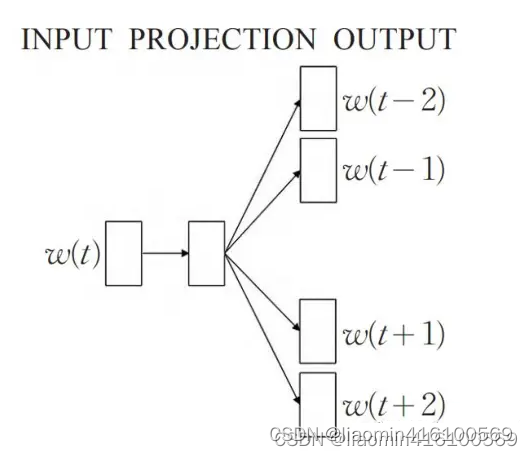
我们语料库仍然为:”I drink coffee everyday“,假设我们的预测窗口大小为 2,通过语料库我们可以构建以下训练集,表2
| 预测词 | 输入词 |
|---|---|
| I | drink |
| I | coffee |
| drink | I |
| drink | coffee |
| drink | everyday |
| coffee | I |
| coffee | drink |
| coffee | everyday |
| everyday | drink |
| everyday | coffee |
注意输入是一个词,输出是一个词
训练 Skip-gram神经网络
这时我们可以根据构建的Skip-gram数据集对模型进行训练了,假设我们要预测的词是coffee,那么由表2可知,我们输入词为[I, drink, everyday]中的任何一个,由表2可知,对其进行one-hot编码后的结果为 [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 0, 1]], **我们选择其中一个就可以得到一个 1*4 的输入向量,那么我们可以得到如下训练过程。
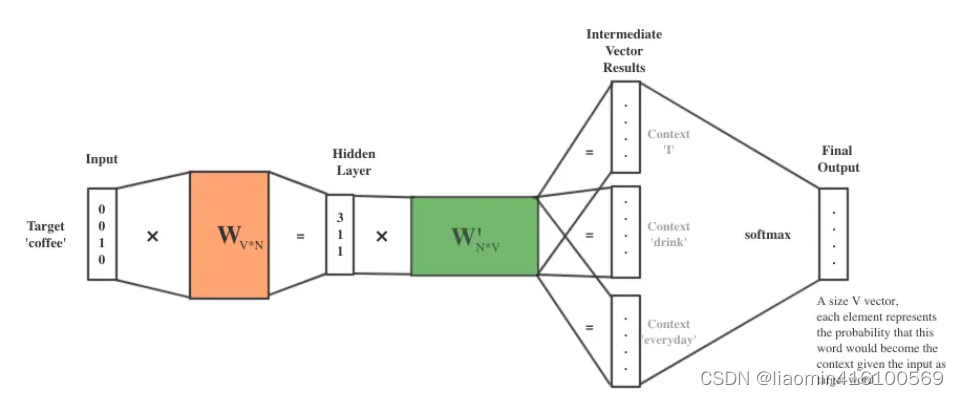
经过训练之后,我们拿 W1( 4*5 权重矩阵) 作为我们的词向量化表。
训练过程不表,类似于CBOW 。
Word2Vec实例
数据训练
- 导入必要的库:
#安装 pip install gensim jieba
from gensim.models import Word2Vec
import logging # 用来设置日志输出
import jieba
- 准备文本数据:
context = ["word2vec是监督学习算法,其会通过句子中词的前后顺序构建有标签数据集,通过数据集 训练神经网络模型 得到这一数据集的 词向量 表(可以理解成我们的新华字典)。"
,"word2vec是用来进行 对词语进行向量化 的模型,也就是对文本类型的数据进行 特征提取"
,"word2vec一般为一个3层(输入层、隐藏层、输出层) 的 全连接神经网络。"
,"本文主要从原理、代码实现 理论结合实战两个角度来剖析word2vec算法"
,"理论部分主要是关于 什么是 word2vec,其两种常见的模型"
,"实战部分主要是通过Gensim库中的word2vec模型,实现文本特征提取"]
- 中文分词:
使用jieba库对文本进行中文分词,并将分词结果保存在context列表中。
for i in range(len(context)):
split_s = context[i]
context[i] = " ".join(jieba.cut(split_s, HMM=True))
context = [e.split(" ") for e in context]

-
配置日志:
配置日志输出格式和级别。
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
-
训练Word2Vec模型:
使用
Word2Vec类来训练模型,传入分词后的文本数据以及一些参数:sentences: 分词后的文本数据。workers: 训练时使用的线程数。window: 上下文窗口大小,表示一个词周围的上下文词数量。vector_size: 词向量的维度大小。epochs: 训练轮数。min_count: 忽略词频低于此值的词语。
model = Word2Vec(sentences=context, workers=8, window=4, vector_size=10, epochs=30, min_count=3)
- 查看词汇表和词向量:
print(model.wv.key_to_index) # 打印词汇表
print(model.wv["word2vec"])
model.wv.key_to_index用于查看词汇表,而model.wv["word2vec"]则用于查看特定词的词向量,这里是查询单词word2vec的词向量。
输出结果
{'': 0, '的': 1, 'word2vec': 2, ',': 3, '是': 4, '层': 5, '模型': 6, '数据': 7, '主要': 8, '、': 9, '进行': 10, '集': 11, '通过': 12}
[ 0.07315318 0.05167933 0.06995787 0.00852275 0.0644208 -0.03653978
-0.00503093 0.06105096 -0.081814 -0.04047652]
可以使用Gensim提供的save()方法将训练好的Word2Vec模型保存到文件。这样可以在之后加载模型并重用它。以下是保存模型的示例代码:
注意:词汇表里单词都是词频次数超过min_count的词。
保存和加载
保存模型
model.save("word2vec_model.bin")
这将把训练好的模型保存到名为"word2vec_model.bin"的文件中。然后,您可以使用以下代码加载保存的模型:
from gensim.models import Word2Vec
# 加载模型
loaded_model = Word2Vec.load("word2vec_model.bin")