并查集
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。这一类问题近几年来反复出现在信息学的国际国内赛题中。其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受;即使在空间上勉强通过,运行的时间复杂度也极高,根本就不可能在比赛规定的运行时间(1~3秒)内计算出试题需要的结果,只能用并查集来描述。
以上释义来自:百度百科
并查集是一种树型的数据结构,用于处理一些不相交集合(disjoint sets)的合并及查询问题

- 根节点的编号就代表该集合的编号
- 树中每一个节点存储着它的父亲节点
基本原理
- 如何判断树根
if(p[x]==x)
- 如何求X的集合编号
while(p[x]!=x) x = p[x];
- 如何合并两个集合(本质上就是合并两棵树)
方法:将集合1或者2插入到集合1或者2的某个位置即可【根节点之下的某个位置】
** 设Px是x的集合编号,Py是y的集合编号,则合并操作**:p[x] = y;
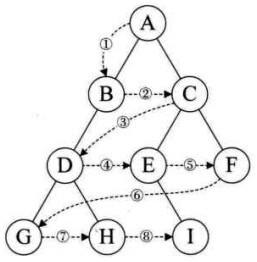
画解合并/插入
初始时每个集合都是一个独立的集合且集合的编号等于自己下标数。
:)例:p[2]=2,p[6]=6将两个集合进行合并

- 1.找到p[2]【该集合的根就是该集合的编号】集合的父节点
- 2.找到p[6]集合父亲节点
- 3.p[2]集合的父节点指向p[6]集合即可。
合并后:p[2] = p[6] = 6;
因为p[2]=2,p[6]=6
所以合并后的集合{6,2},一个以6为祖宗节点的集合
插入
将以
p[6]为根的集合{4,7,10}插入到以p[5]为根的集合{5,3,9}中
显然p[3]=5,p[9]=5,p[5]=5,p[4]=6,p[7]=6,p[10]=6,p[6]=6。
那么只要找到集合p[6]中的祖宗节点【6】指向集合p[5]即可【不一定直接作为其第一个儿子,指向其孙子【比如指向p[3]】也是可以的,因为p[3]的父亲也是5】。
所以有:p[6] = find(3) or p[6] = find(9)【find(x)为寻找x节点的祖宗节点】

路径压缩
可以看到,在计算x的集合编号的时候还是比较耗时的,所以介入了一个优化算法 【路径压缩】
由于每次都要将x指向它的父亲节点,x = p[x]。
因此只要搜索一次成功后将该路径上所有的节点x都指向其祖宗节点。这样再一次查询之后,之后的每一次都是近乎O(1)的操作了。

这也是并查集NB的一个地方。
代码模板
int p[N]; //存储每个点的祖宗节点
// 返回x的祖宗节点
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
// 初始化,假定节点编号是1~n
for (int i = 1; i <= n; i ++ ) p[i] = i;
// 合并a和b所在的两个集合:
p[find(a)] = find(b);
模板练习


// Problem: 合并集合
// Contest: AcWing
// URL: https://www.acwing.com/problem/content/description/838/
// Memory Limit: 64 MB
// Time Limit: 1000 ms
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 100010;
int p[N];
int find(int x)
{
if(p[x]!=x) p[x] = find(p[x]);
//返回祖宗节点
return p[x];
}
int main()
{
int n,m;
scanf("%d%d",&n,&m);
for(int i=1;i<=n;i++)
{
p[i] = i;
}
while(m--)
{
char op[2];
int a,b;
scanf("%s%d%d",op,&a,&b);
//合并集合
if(*op=='M') p[find(a)]=find(b);
else if(find(a)==find(b))
printf("Yes\n");
else
printf("No\n");
}
return 0;
}