参考论文: low rank adaption of llm
背景介绍:
自然语言处理的一个重要范式包括对一般领域数据的大规模预训练和对特定任务或领域的适应处理。在自然语言处理中的许多应用依赖于将一个大规模的预训练语言模型适配到多个下游应用上。这种适配通常是通过更新预训练模型所有参数的微调来进行的。
部署完整独立的微调模型实例每次都将花费高昂的代价。所以我们提出了低秩自适应的方法,即LoRA。它冻结了预训练模型的权重值,并给Transformer架构的每一层都注入了可训练的秩分解矩阵,从而极大的减少了下游任务需要训练的参数数量。虽然使用了更少的训练参数,提供了更高的训练吞吐量。
Pytorch架构集成了LoRA模型并提供了我们针对RoBERTa, DeBERTa, and GPT-2的应用集成和相关模型,链接为 https://github.com/microsoft/LoRA。
很多时候人们通过只调整部分参数,或者给新任务添加外部模块的方式来解决这个问题。这样,在每个任务中,除预训练模型外,我们只需要额外存储和加载少量特定任务所需的参数即可,从而极大地提高了部署时的操作效率。但是现有技术在扩展模型深度或减少模型可用序列长度(Li et al. (2018a))时,通常会引入推理时延。更重要的是,这些方法往往无法与微调基线相匹配,从而在效率和模型质量之间产生权衡。
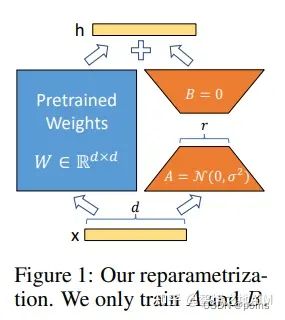
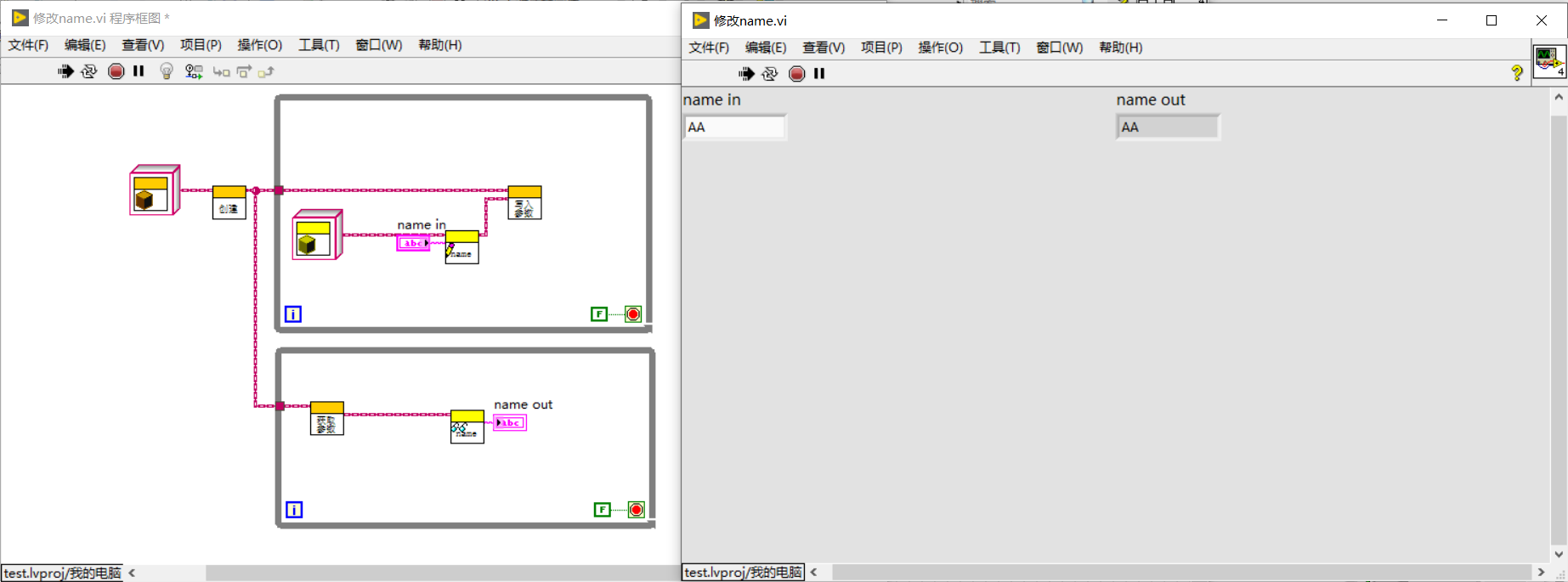
图1
我们受到Li et al. (2018a); Aghajanyan et al. (2020)等工作的启发,他们发现学习到的过参数化模型实际上存在于一个低内在维度上。我们假设模型自适应过程中权重的变化也具有较低的“内在秩”,这帮助我们提出的低秩自适应(LoRA)方法。LoRA允许我们在适配过程中,通过优化密集层变化的秩分解矩阵的方式来间接的训练神经网络的密集层,同时保持预训练权重不变。如图1所示。以GPT-3 175B 模型为例,我们发现即便全秩达到了12288,一个非常低的秩(图1中r为1或者2)也足够了。这使得LoRA在存储和计算方面都很高效。
LoRA具备以下几个关键优势:
- 一个预训练模型可以用来针对不同任务建立为很多小的LoRA模块。我们可以冻结共享模型,仅仅通过更换图1中的A,B矩阵来快速地切换任务,从而显著降低存储需求和任务切换开销。
- 当使用自适应优化器时,LoRA使训练更加高效,并将硬件门槛降低了3倍,因为对于大多数参数,我们不需要计算梯度或维护的优化器状态。相反,我们只优化注入的、小得多的低秩矩阵。
- 在构造上,我们简单的线性设计允许我们在部署时将可训练矩阵与冻结的权重合并,同时保证了相较于全微调模型的性能并不产生推理时延。
- LoRA与许多现有方法不冲突,并且可以与其中许多方法相结合,比如前缀调整法。我们在附录E中提供了一个这样的例子。