介绍一篇大模型前沿论文,《Explanation Selection Using Unlabeled Data for Chain-of-Thought Prompting》。在这篇论文中,作者Xi Ye和Greg Durrett探讨了如何通过优化大语言模型(LLMs)的解释性提示来提升文本推理任务的性能。他们指出,不同的解释对于模型的下游任务准确性有显著影响,因此需要一种方法来选择或生成最佳的解释。
为了解决这个问题,作者提出了一种两阶段的框架,该框架首先使用留一法(leave-one-out scheme)生成每个示例的候选解释集,然后通过一个两阶段的搜索过程找到一个在开发集上表现良好的解释组合。
在第一阶段,他们使用两个代理指标——对数似然和新例子上的准确性——来评估每个候选解释的表现。这些代理指标的得分被用来估计解释组合的性能,从而指导搜索过程优先考虑更有潜力的组合。在第二阶段,作者使用银标(silver-labeled)开发集来评估和选择最终的解释组合。
他们的方法在四个不同的文本推理数据集上进行了测试,包括小学数学问题、常识问答、自然语言推理和策略问答,实验结果表明,他们的方法能够在这些任务上找到比初始种子解释平均准确度高出4%的解释。
此外,作者还展示了他们的方法在不同语言模型上的适用性,并探讨了优化解释的泛化能力。尽管他们的方法需要在训练阶段付出一定的计算开销,但在推理时的成本与标准少数样本提示相同。总体而言,这篇论文提出了一种有效的方法来优化LLMs的解释性提示,并通过实验验证了其在多个文本推理任务上的有效性。
这篇论文体现了大型语言模型(LLMs)在文本推理任务中的一些最新进展和研究趋势:
-
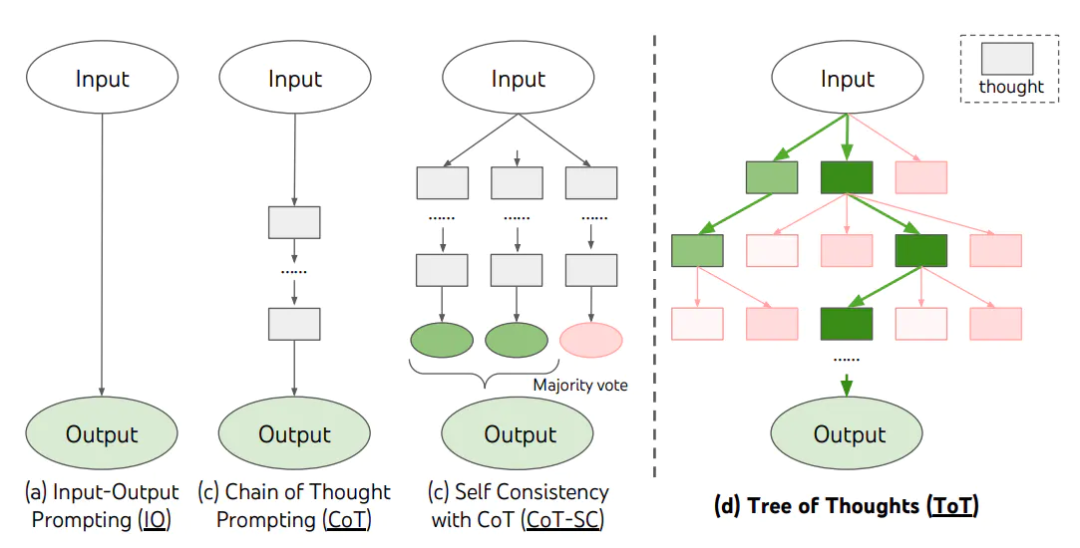
思维链推理(Chain-of-Thought Reasoning): 思维链推理是一种提示技术,它要求语言模型在给出最终答案前先生成一个逐步的推理过程。这种方法模仿了人类解决问题的方式,即通过一系列逻辑推理步骤来到达结论。
 在论文中,作者发现,当LLMs被提示生成这样的推理链时,它们在多步推理任务上的表现得到了显著提升。这不仅提高了答案的准确性,还增加了模型决策的可解释性。
在论文中,作者发现,当LLMs被提示生成这样的推理链时,它们在多步推理任务上的表现得到了显著提升。这不仅提高了答案的准确性,还增加了模型决策的可解释性。 -
未标记数据的有效利用: 在缺乏大量标记数据的情况下,作者提出了一种利用未标记数据的方法。通过伪标记(pseudo-labeling),即利用模型自身的预测来为未标记的数据生成标签,研究者能够扩充训练数据集。这一策略使得模型能够从更多的数据中学习,从而提高其在推理任务上的性能。
-
代理指标(Surrogate Metrics): 为了在有限的计算资源下有效地搜索和评估大量的候选解释,作者提出了使用代理指标来近似模型在下游任务上的性能。这些代理指标,如对数似然(log likelihood)和新例子上的准确性,可以快速估计一个解释或解释组合的潜在性能。通过这种方式,研究者可以优先考虑那些根据代理指标评估可能性能较好的解释组合,从而更高效地找到最优解释。
-
两阶段优化框架: 作者提出的两阶段优化框架是为了在保持计算效率的同时寻找最优的解释组合。在第一阶段,框架单独评估每个候选解释的性能,使用代理指标来缩小潜在的高性能解释集合。在第二阶段,框架在这些精选的候选解释中进一步搜索,通过直接在银标数据集上评估来找到最终的最优解释组合。这种分阶段的方法平衡了搜索空间的广度和评估的准确性,使得在有限的计算资源下也能有效地找到性能更优的解释组合。
-
自动化的提示工程(Automated Prompt Engineering): 自动化的提示工程是指使用算法和模型来自动生成或优化提示,而不是手动设计。这包括通过机器学习技术来探索和改进提示的结构和内容,以提高模型在特定任务上的表现。自动化提示工程可以大幅减少手动调整提示的工作量,并可能发现人类专家未能注意到的高效提示。
-
大型模型的黑盒优化(Black-Box Optimization): 黑盒优化是指在不直接修改模型参数的情况下,通过改变输入(如提示)来提升模型性能的方法。这种方法特别适用于大型预训练模型,因为它们的规模和复杂性使得直接优化参数变得计算成本高昂。通过黑盒优化,研究者可以在不重新训练模型的情况下,调整模型的行为以适应新任务。
-
成本效益分析: 在优化提示的过程中,研究者需要考虑成本效益。这包括计算资源的消耗、优化过程的时间长度以及最终提示的性能提升。一个好的优化策略应该能够在合理的成本下,显著提高模型的性能,使得投入的资源能够得到最大的回报。
-
关于提示的分析: 对提示的分析是指研究提示的不同属性如何影响模型性能。这包括分析提示的长度、复杂度、语言风格等对模型输出的影响。通过这种分析,研究者可以更好地理解提示的作用机制,从而设计出更有效的提示策略。此外,这种分析还可以揭示模型对提示的敏感度,帮助研究者避免生成导致性能下降的提示。
这些进展展示了LLMs在自动推理和问题解决领域的潜力,同时也指出了未来研究的方向,如改进代理指标以更好地预测下游性能,以及探索在更广泛的任务和语言上的适用性。
论文链接:https://arxiv.org/abs/2310.14623
作者:Hoang H. Nguyen, Ye Liu, Chenwei Zhang, Tao Zhang, Philip S. Yu