首先对聚类分析作系统介绍。其次对聚类算法进行文献回顾,对其概况、基本思想、算法进行详细介绍,再是通过对微博数据分析具体来强化了解聚类算法,本文的数据是由所设计地软件在微博平台上获取的数据,最后得到相关结论和启示。
聚类算法的研究有着相当长的历史,早在1975年 Hartigan就在其专著 Clustering Algorithms[5]中对聚类算法进行了系统的论述。聚类分析算法作为一种有效的数据分析方法被广泛应用于数据挖掘、机器学习、图像分割、语音识别、生物信息处理等。
聚类方法是无监督模式识别的一种方法,同时也是一种很重要的统计分析方法。聚类分析已经被广泛的研究了很多年,研究领域涵盖数据挖掘、统计学、机器学习和空间数据库等众多领域。聚类是基于数据的相似性将数据集合划分成组,然后给这些划分好的组指定标号。目前文献中存在着大量的聚类算法,大体上,聚类分析算法主要分成如下几种[6],图2-1显示了一些主要的聚类算法的分类。
为了进一步验证K-means算法,本文将采集一批微博数据,通过根据微博用户特征属性对其进行聚类,并得出结论。
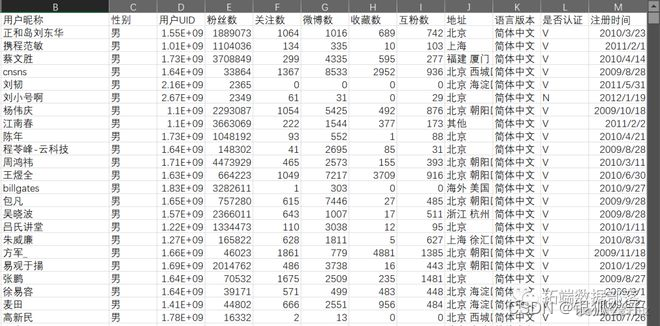
新浪微博,作为中国的较大的用户使用较受欢迎的微博使用平台之一,从其平台上抽取的微博一定程度上可以反映国内微博平台的传播情况。鉴于新浪微博在国内具有较大影响力,故本文选取有影响力的新浪微博用户为研究对象,包括大V、电商平台、明星、网红等,从微博用户特征出发,来探索基于用户特征的聚类分析。本研究总共获取了50359条微博数据。
登录。
数据展现。

词云图展示

微博数据分析

微博聚类,情感分析可视化

爬虫界面
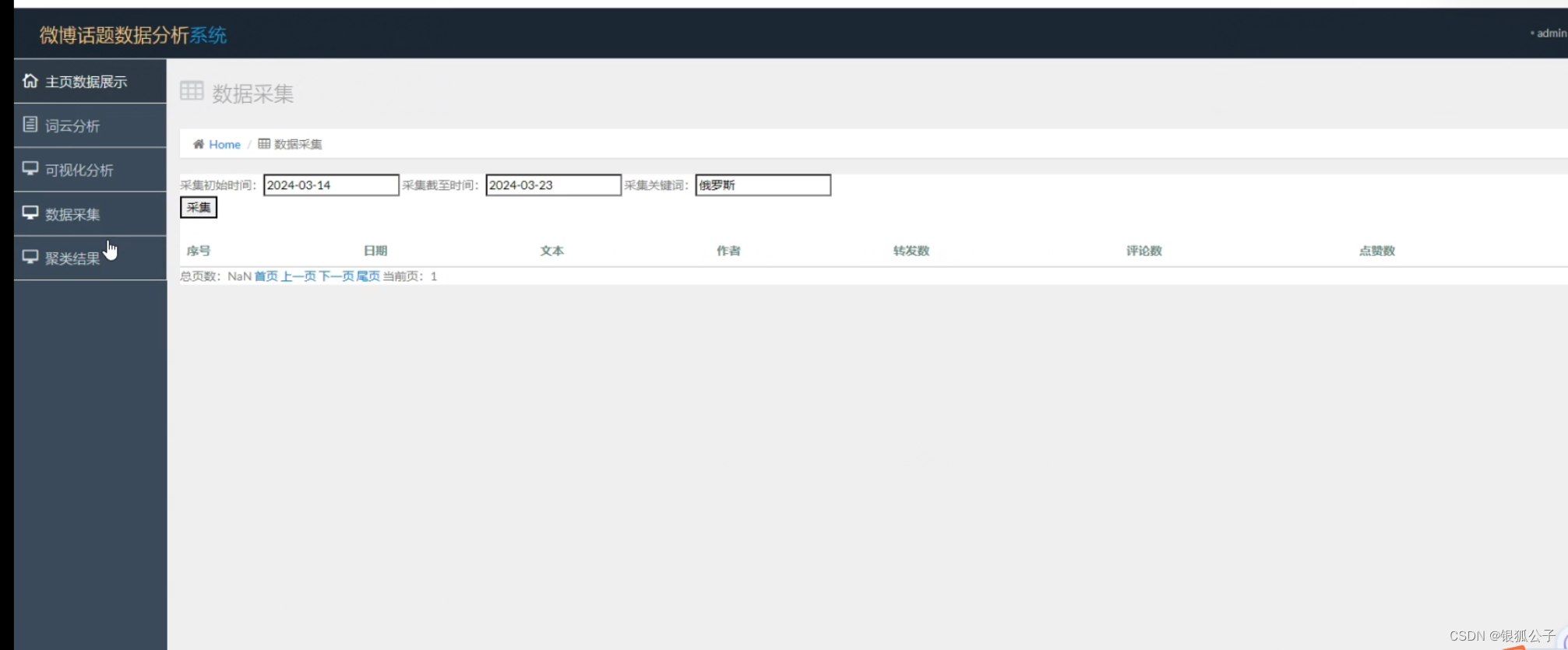
聚类结果
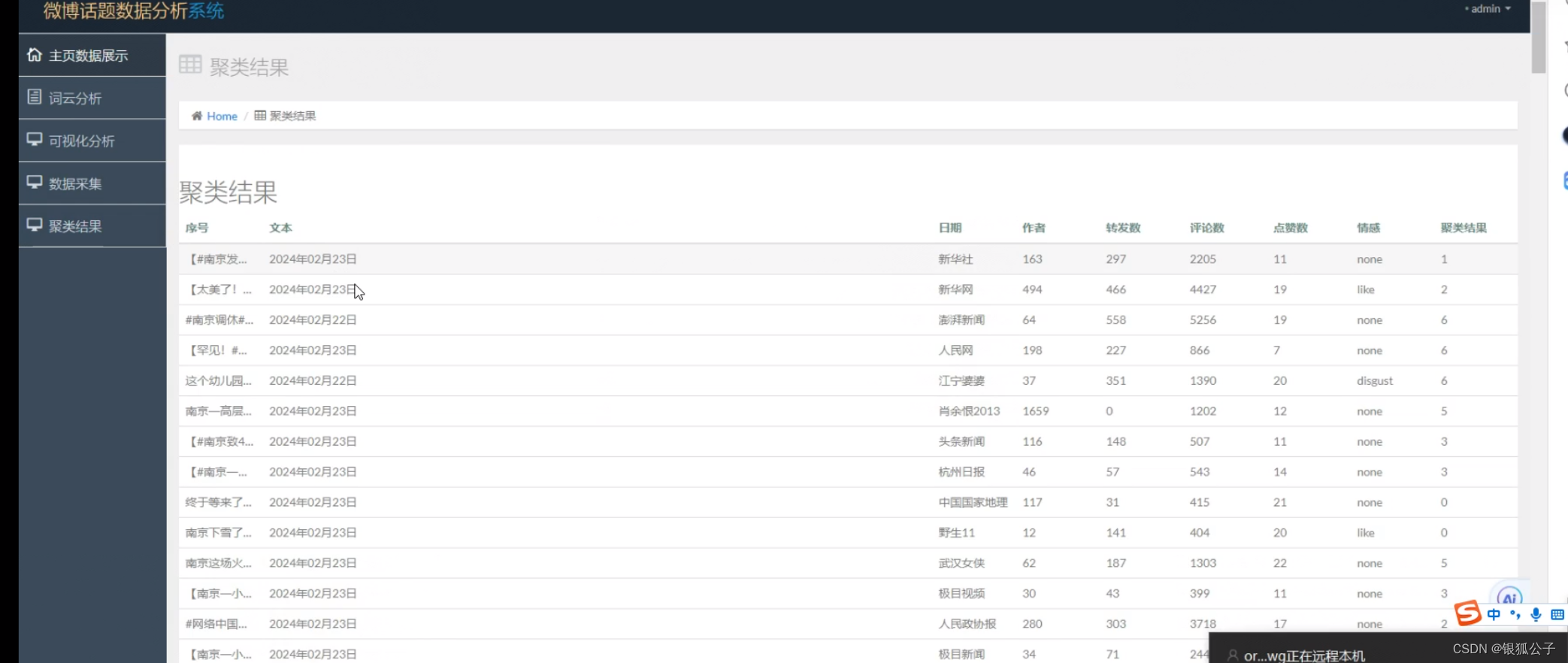
代码结构
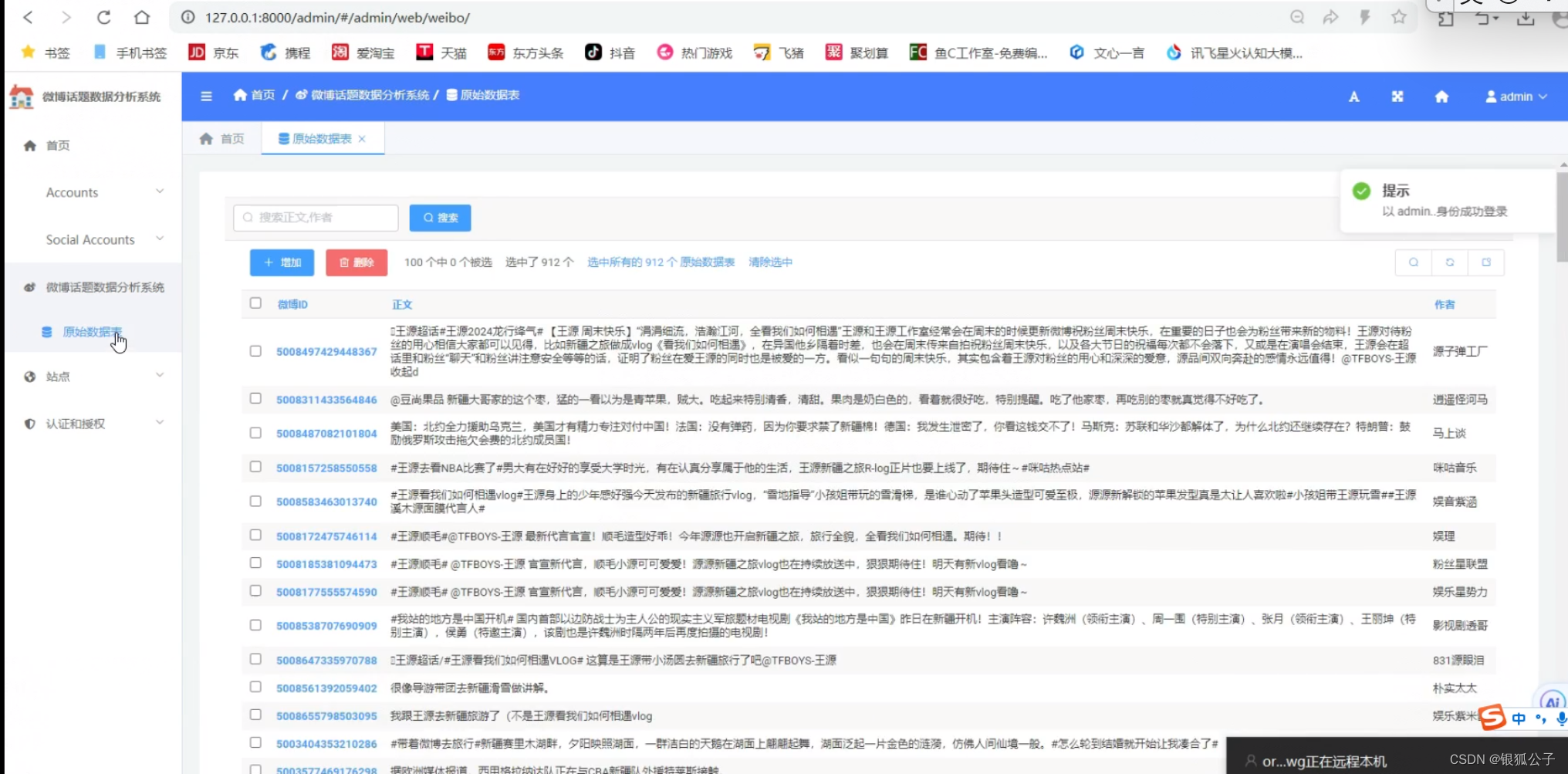
微博数据管理
从层次聚类的结果来看,将该数据划分成4个类别是相对合理的,因此上述认证有理有据。
结论
本文研究了数据挖掘的研究背景与意义,讨论了聚类算法的各种基本理论包括聚类的形式化描述和定义,聚类中的数据类型和数据结果,聚类的相似性度量和准则函数等。同时也探讨学习了基于划分的聚类方法的典型的聚类方法。本文重点集中学习了研究了 K-Means聚类算法的思想、原理以及该算法的优缺点。并运用K-means算法对所采集的数据进行聚类分析,深化了对该算法的理解。
参考文献
[1] 中国互联网络信息中心(CNNIC).第33次中国互联网络发展状况统计报告[EB/OL].
[2] 郭宇红,童云海,唐世渭等.数据库中的知识隐藏 [ J ].软件学报,2007, 11 (18) : 278222797.
[3] hehroz S.Khan,Amir Ahmad.Cluster center initialization algorithm for K-Means clustering[J].Pattern Recognition Letters 25(2004): 1293-1302.
[4] 王春风,唐拥政.结合近邻和密度思想的K-均值算法的研究[J] 计算机工程应用.2011 年,47(19).147-149.
[5] 杨小兵.聚类分析中若干关键技术的研究[D].杭州:浙江大学,2005年:24-25.
[6] Hartigan J A. Clustering Algorithms[M].New York: John Wiley&Sons Inc.,1975.
[7] Tony Bain 等著.邵勇译.SQL Server2000 数据仓库与 Analysis Services[M]. 北京.中国电力出版社,2003.
[8] Handl Julia, Joshua Knowles, Douglas B. Kell. Computational cluster validation in post-genomic data